
基于NPE算法的语音特征提取应用研究*
2014-02-11 03:42仝一君
通信技术 2014年11期
仝一君,王 力
(贵州大学大数据与信息工程学院,贵州贵阳550025)
基于NPE算法的语音特征提取应用研究*
仝一君,王 力
(贵州大学大数据与信息工程学院,贵州贵阳550025)
语音作为传递信息的一种常用手段,在人们的日常生活中有着非常重要的地位。随着科学的发展,语音识别愈来愈受到人们的重视。本文提出一种基于流形学习的特征提取方法——邻域保持嵌入(NPE)算法用于语音识别领域。流形学习是近几十年发展起来的降维方法,在图像识别领域已有应用,但在语音识别领域的应用非常之少。实验结果表明该算法可取得较好的识别率,同时所提取的特征稳定,计算速度快。
流形学习 语音识别 特征提取 NPE算法
0 引 言
语音作为传递信息的一种常用手段,在人们日常生活中有着非常重要的地位。随着科技的发展和信息时代的到来,实现机器与人类通信的智能化成为一大热点。同时,语音识别作为该领域的一项重要技术,也越来越受到人们的关注。然而,现实中的语音信号通常都是高维的,难以被识别的。因此,在对语音信号处理的过程中,需要经过特征提取降低维数,获取特征参数矩阵。
语音识别技术开始于20世纪50年代。目前在语音识别过程中,最为常用的特征提取方法有梅尔倒谱系数[1](MFCC,Mel-Frequency Cepstral Coefficients)和线性预测倒谱系数(LPCC,Linear Prediction Cepstrum Coefficient)等。MFCC利用了听觉原理和倒谱的解相关特性,符合人类耳朵的听觉特性,抗噪声能力好。LPCC特征参数主要反映声道的响应,一般只需要少量的倒谱系数就能比较完整的描述语音的共振峰特性,进而反映声道的响应特性。但LPCC虽然实现简单,计算复杂度小,但其抗干扰能力差。
本文使用流形学习方法提取语音信号的特征参数。流形学习方法已经在图像识别领域得到了较好的应用,但在语音识别领域应用非常少[2]。本文尝试将流形学习应用于语音信号的特征提取中,针对特定人的语音信号进行分析,并将其与MFCC算法和LPCC算法进行对比分析。
1 流形学习方法
1.1 流形学习方法简介
1995年,流形学习的概念首次被提出。2000年SCIENCE上发表的三篇文章-ISOMAP,LLE和感知的流形假说,标志着流形学习研究热潮的开始[3]。
流行学习方法(Manifold Learning)[4-5]是近几十年发展起来的一种数据降维方法,是机器学习领域的一个新兴分支。流形学习方法的基本原理是假设高维欧式空间中存在某一低维流形,通过对该空间的数据进行均匀采样,恢复低维流形的内在几何规律,得到相应的嵌入映射关系[6]。
目前,流形学习算法在数据可视化、图像处理和模式识别等方面有较广泛应用。然而在语音识别领域中,因为噪声的存在、发音人的情况(包括性别、年龄、声带特征、地域以及身体条件)差异以及采样点的不同,都会影响最终的语音信号,这使得流形学习在该领域的应用非常少。但流形学习作为一种年轻的机器学习方法,理论日益成熟,应用范围愈加广泛,相信其在语音识别领域中也会大放光彩。
1.2 NPE算法
本文中主要通过流形学习中的保持邻域嵌入算法(NPE,Neighborhood Preserving Embedding)[7]来研究流形学习在语音识别领域中的应用。
NPE算法是继提出局部保持映射(LPP,Locality Preserving Projection)[8]算法之后,于2005年提出的一种新的降维技术。它是一种基于局部几何特性的线性降维技术,目的在于保存数据在流形上的局部邻域结构。NPE算法对于数据的整体结构敏感度低,相对于流形学习方法中的等距流形映射和局部线性嵌入方法,它的定义在空间中是任意的,解决了前面两种方法只能对训练数据产生映射,而不能对测试数据进行估计的问题。
NPE算法相对于非线性的降维技术,在计算时间和内存消耗上都相对要少,其计算步骤主要可以分为三步:
第一步:构造邻近图G。
G表示一个具有N个顶点的图,每个数据xi作为图的一个顶点,若xi与xj邻近,则将它们用一条边连接上。确定邻近点的方法主要有两种:ε近邻法和K近邻法。ε近邻法,其中ε<R,如果xi和xj满足

即两点是相近邻的,为它们创建一条边。K近邻法,其中K∈N。如果点xi也是点xj的K近邻,同时xj也是xi的K近邻,则为它们创建一条边。因为在实际工作中选择一个合适的ε是比较困难的,所以本文中NPE算法使用的K近邻方法构造邻近图G。
第二步:确定权值。
在建立的近邻图G中,用W表示权值矩阵,wij表示点xi到点xj的权值。构造该权重的目标函数为
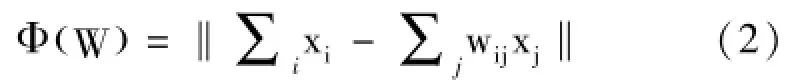
第三步:计算特征映射。
计算式(3)的特征值和特征向量
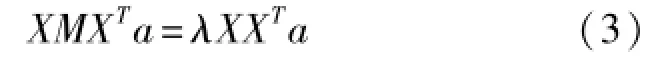
式中X=(x1,x2,…xm),M=(I-W)T(I-W),I是单位矩阵,M对称且正定。设a0,a1,…ad-1是该式所得的特征向量,并按照其对应的特征值从小到大排列,即λ0<λ1<…<λd-1排序,最后得到由高维空间映射到低维空间的坐标

式中A=(a0,a1,…ad-1)。
2 基于NPE算法特征提取
语音识别系统[9]通常主要包括预处理、特征提取、模型训练、模式匹配与识别这些步骤。由于本文中使用的语音信号时在实验室相对安静的环境下录制的,故而省略了去噪处理。
本文的工作主要在特征提取阶段,提出了基于流形学习NPE算法的语音特征提取方法,算法的基本流程如图1所示。
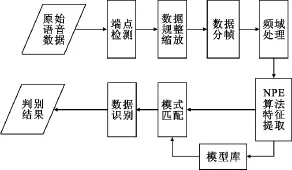
图1 基于NPE算法的语音识别流程Fig.1Speech recognition based on NPE algorithm flow chart
该识别过程具体过程如下:
1)端点检测。对于原始语音数据使用双门限检测法进行检测,判断出每个语音信号的起点与终点。如果语音信号是双声道的,则需要将其变成单声道信号[10]。
2)数据规整缩放。将通过端点检测的语音信号采用保持权重的方式进行规整缩放,使得所有的语音拥有相同的长度。
3)数据分帧。将得到的等长度的语音信号进行加窗分帧,得到短时时域信号。
4)频域处理。对于短时时域信号进行频域变换,得到每帧信号的频谱,并按帧进行数据组合。
5)NPE算法特征提取。将4)中得到的数据经过NPE算法进行数据降维,提取特征,得到映射矩阵。
6)模式匹配与识别。新的语音信号在识别时,按照以上步骤依次处理,通过映射矩阵得到提取的特征。
3 仿真实验数据分析
文中的实验所使用的数据是基于特定人的1000个语音信号。这组数据是在实验室相对安静的环境下录制的关于“0”到“9”的语音段,每段语音采样频率为8 kHz,16 bit量化,PCM编码,每个数字都是100个语音段。
3.1 NPE算法特征矩阵的稳定性
任意选取某个数字的某一帧的数据,通过对比其平均值和数据走向,观测该数字的某一帧的数据的稳定性,如图2和图3所示,图中“*”表示的是这十个信号对应点的平均值。
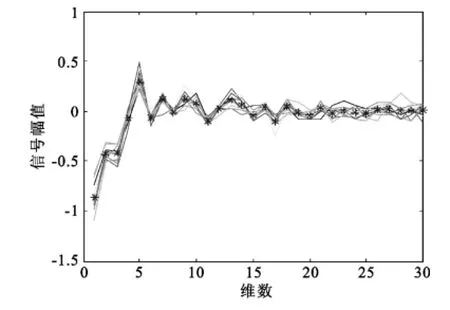
图2 数字“4”的第十帧数据Fig.2 The tenth frame data of the number"4"
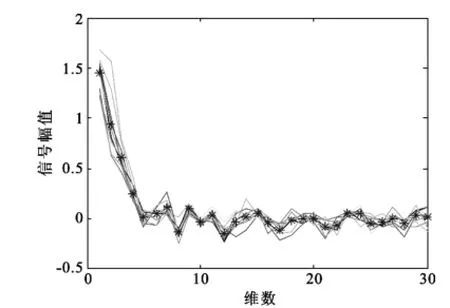
图3 数字“7”的第三十五帧数据Fig.3 The thirty-fifth frame data of the number"7"
通过对数据的分析,可得相同的信号,其走向的拟合度很高,均值基本都分布在数据线上。由此可知NPE算法提取的特征参数稳定性良好。
3.2 基于NPE算法特征提取参数影响对比
文中影响基于NPE算法进行特征提取的语音识别结果的主要参数有构造邻近图的K值和数据规整缩放数值。
对于构造邻近图的参数K,在数据规整值为3072时选取K=0,3,4,5,6,7,8等值进行实验,得出结果如表1所示。通过对结果的分析,得出当邻近值为4或5时,识别率最好,可达到95%左右。当K值继续增大时,会导致识别率的降低。
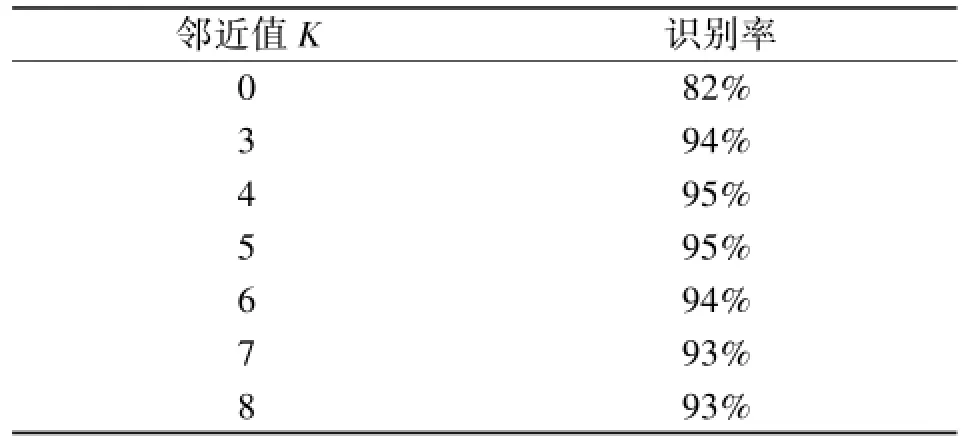
表1 参数K取值对算法识别率的影响对比Table 1The influence of parameter K value for recognition rate of the algorithm
对于数据规整缩放的数值,本文选取了1 024、2 048、3 072以及4 096这四个数据进行分析实验,结果如表2所示。表2中分别选取了当邻近值为4和5时的数据,这是因为通常在这两个值时语音的识别率最高。通过对于实验结果的分析,可得当语音信号规整值的点数不同时,其识别率在不同的K值下达到最大值。当数据规整值为3 072时,识别率最高且比较稳定。这可能是由于本文中所使用的原始数据长度通常在3 000~3 500点左右,因此在规整值点为3 072时带来的信息损失以及可能加入的噪声相对较少。但同时可由K=4,数据规整值为2 048时,其识别率可达到95%这一数据推知,NPE算法在数据维数相对较低时也能很好地表示出语音信号的特征值。
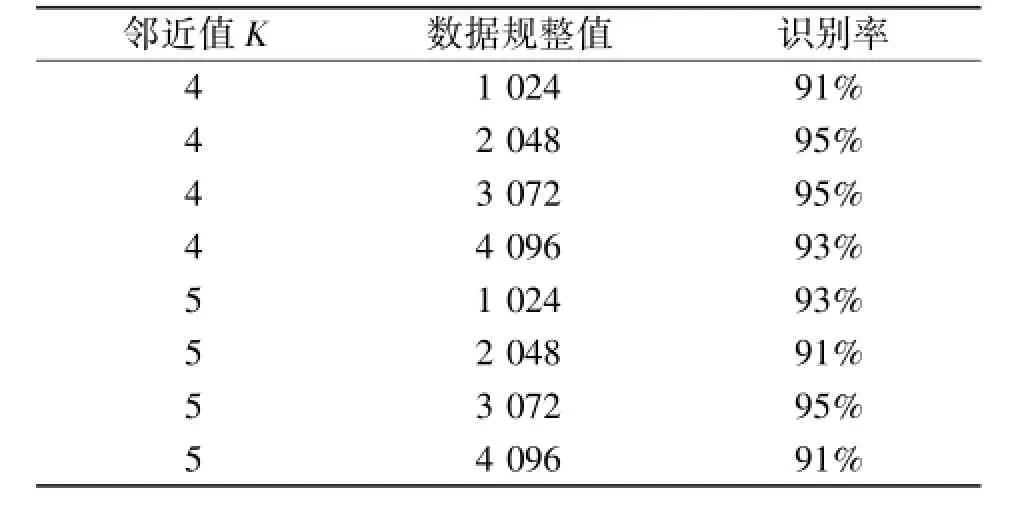
表2 特定人下的识别率数据Table 2 Recognition rate data for a specific person
3.3 不同特征提取算法识别率对比
本文中选取了传统的语音特征提取方法LPCC和MFCC与NPE算法进行对比,得到的对比结果如表3所示。
从表3中可以看到,本文提出的基于流形学习NPE算法的特征提取方法比传统的LPCC、MFCC方法的识别率略高或持平。

表3 三种特征提取算法识别率对比Table 3 Recognition-rate comparison of the three feature-extraction algorithms
虽然NPE算法与MFCC方法对语音信号的识别率非常接近,但是在NPE算法中,通过对数据的降维,其最终处理的数据比MFCC方法少了很多。例如当数据规整值为2 048时,NPE算法中的语音信号是23×30维的,而MFCC中某些语音信号是124× 24维的。故而基于NPE算法进行特征提取的数据处理量更少,计算速度更快,节省了大量的资源。
当将三种算法的维数统一为36×30维时,MFCC算法和LPCC算法的识别率明显下降,具体如表4所示。

表4 当数据为36×30时三种特征提取算法识别率对比Table 4 Recognition-rate comparison of the three feature-extraction algorithms when the data is 36×30
由上述实验结果分析可知,本文中将NPE算法用于语音识别系统中的特征提取部分是可行的,识别结果较好且计算量相对较少,特征稳定。
4 结 语
语音识别自从提出之后愈来愈受到各国学术界的广泛关注。但语音识别在实际生活中的应用还没有很好地普及。本文的研究重点在于语音识别中的特征提取部分,在该部分使用了一种新的特征提取方法——流形学习NPE算法。目前流形学习尚处于理论阶段,本文的研究对流形学习应用于语音识别领域是一次很有意义的尝试。通过实验表明基于NPE算法的特征提取有效地降低了语音数据的维数,减少了数据量,提高了计算速度,节约了资源,同时语音识别率较好,且特征稳定,有很好的研究价值。本文接下来的研究方向主要是改进NPE算法,并增加语音实验数据量,加入非特定人语音,尝试建立汉语语音库进行实验。
[1] 张旭博,周渊平.基于MFCC和VQ码书的说话人识别系统研究[J].通信技术,2009,42(09):162-164.
ZHANG Xu-bo,ZHOU Yuan-ping.Research on a Speaker Recognition System using MFCC Features and Vector Quantization[J].Communications Technology, 2009,42(09):162-164.
[2] 王海鹤.基于流形学习的语音情感识别方法研究[D].江苏:江苏大学,2011.
WANG Hai-he.Research Speech Emotion Recognition Method Based On Manifold Learning[D].Jiangsu:Jiangsu University,2011.
[3] 鲁春元.流形学习的统一框架及其在模式识别中的应用[D].广东:中山大学,2009.
LU Chun-yuan.Manifold Learning Unified Framework and its Application in Pattern Recognition[D].Guangdong:Sun Yat-sen University,2009.
[4] LI Ning,CAO Wen-ming.Face Recognition based on Manifold Learning and Rényi Entropy[J].Natural Science,2010,2(01):49-53
[5] Seung H S,Lee D D.The Manifold Ways of Perception [J].Science,2001,290(5500):2268-2269.
[6] 罗四维,赵连伟.基于谱图理论的流形学习算法[J].计算机研究与发展,2006,43(07):1173-1179.
LUO Si-wei,ZHAO Lian-wei.Manifold Learning Algorithms based on Spectral Graph Theory[J].Journal of Computer Research and Development,2006,43(07): 1173-1179.
[7] Xi CHEN,Jiashu Zhang.A Novel Maximum Margin Neighborhood Preserving Embedding for Face Recognition [J].Future Generation Computer Systems,2010,28 (01):212-217.
[8] ZHENG Zhong-long,YANG Fan,TAN We-nan,JIA Jiong,YANG Jie.Gabor Feature-Based Face Recognition Using Supervised Locality Preserving Projection[J]. Signal Processing,2007,87(10):2473-2483.
[9] Talton David.Perspectives on Speech Recognition Technology[J].Radiology Management,2005,27(01):38-43.
[10] DANIEL Yellin,EHUD Weinstein.Multichannel Signal Separation:Methods and Analysis[J].IEEE Transactions on Signal Processing,1996,44:106-118.
TONG Yi-jun(1989-),female,graduate student,mainly working at pattern recognition, signal processing and machine learning.
王力(1971—),男,教授,主要研究方向为模式识别、信号处理和机器学习。
WANG Li(1971-),male,professor,mainly engaged in pattern recognition,signal processing and machine learning.
Speech Feature Extraction based on NPE Algorithm
TONG Yi-jun,WANG Li
(College of Big Data and Information Engineering,Guizhou University,Guiyang Guizhou 550025,China)
Voice,as a common means of information transfer,plays a vital role in people's daily life.With the development of science,speech recognition attracts more and more attention.This paper proposes a feature extraction method based on manifold learning——NPE(Neighborhood Preserving Embedding)algorithm for the field of speech recognition.Manifold learning,as a dimension-reduction method developed in recent decades,is applied in the field of image recognition,but seldom in the field of speech recognition. Experimental results show that the algorithm can acquire a better recognition rate with stable characteristics and rapid calculation.
manifold learning;speech recognition;feature extraction;NPE algorithm
TN912.3
A
1002-0802(2014)11-1281-04
10.3969/j.issn.1002-0802.2014.11.009

仝一君(1989—),女,硕士研究生,主要研究方向为模式识别、信号处理和机器学习;
2014-08-26;
2014-10-15 Received date:2014-08-26;Revised date:2014-10-15
猜你喜欢
车主之友(2022年4期)2022-08-27
民族文汇(2022年24期)2022-06-09
海峡姐妹(2019年12期)2020-01-14
中国化工贸易·下旬刊(2019年5期)2019-10-21
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
科技风(2018年1期)2018-05-14
佛山陶瓷(2016年11期)2016-12-23
大观(2016年9期)2016-11-16
火控雷达技术(2016年1期)2016-02-06
