
改进的低时延语音增强算法*
2014-02-11 03:42张翼鹏
通信技术 2014年11期
庞 亮,陈 亮,张翼鹏
(1.解放军理工大学通信工程学院,江苏南京210007;2.解放军南京炮兵学院,江苏南京211132)
改进的低时延语音增强算法*
庞 亮1,陈 亮1,张翼鹏2
(1.解放军理工大学通信工程学院,江苏南京210007;2.解放军南京炮兵学院,江苏南京211132)
针对目前语音增强存在较大时延的问题,提出一种低时延语音增强算法。在传统的先验信噪比估计和噪声估计的基础上,对判决引导算法进行低时延的改进,并提出了一种基于语音存在概率和语音激活检测相结合的噪声估计方法,本文的算法采用对数MMSE估计器结合语音存在概率。采用ITU-T P.826 PESQ、分段信噪比、总信噪比和对数谱失真对该算法进行了测试,并与其他几种算法进行了对比,实验结果表明,该算法有效降低了时延,可以很好的跟踪非平稳噪声,在信噪比较低的情况小可以取得很好的增强效果,且音乐噪声和残留背景噪声也可以得到很好的抑制。
语音增强 判决引导 先验信噪比估计 噪声谱估计
0 引 言
在实际的语音通信过程中,语音不可避免的会受到外界的各种干扰,使得原始语音受到噪声的污染,导致许多语音处理系统性能的恶化。语音增强技术就是有效降低噪声干扰的一个重要手段,其目标是从带噪语音信号中提取出尽可能纯净的原始语音或原始语音参数来改善语音质量,使人们接受或者提高语音处理系统的性能。有效的语音增强技术可以大大提升系统的抗干扰能力,增加语音的可懂度。单通道语音增强技术目前应用广泛,且一直是国内外学者广泛研究的重要课题。
基于对数MMSE(Minimum Mean-Square Error,最小均方误差)估计器相比较于维纳滤波、小波变换、谱减法等方法[1]具有更加出色的降低音乐噪声的能力。对数MMSE估计器的关键是先验信噪比估计和噪声估计模块,传统的先验信噪比估计采用的是判决引导(DD)法,均采用前一帧的语音对该帧进行估计,存在一帧的时延,该算法后来也有很多学者对其进行了优化,主要是提高了估计的精度和收敛速度,但算法的时延并未做出改进,本文提出改进的低时延DD算法,可有效解决这一问题。
噪声的估计在语音增强系统中至关重要,如何能够准确的估计出噪声的功率谱,尤其是如何能够快速跟踪非平稳噪声的功率谱是目前国内外研究的一个重点和难点。传统的方法是采用VAD判决法,在非语音帧对噪声进行平滑更新,对于语音帧,则不进行噪声的更新。但是在低SNR的条件下,特别当环境噪声为非平稳噪声时,话音活动期间也必须持续的精确噪声估计,才能实现有效的语音增强。目前使用较多的主要是最小值控制的递归平均(MCRA)算法、改进的最小值控制的递归平均(IMCRA)算法[2]、MMSE算法[3]及利用语音存在概率[4]的噪声估计等算法,但这些算法大都复杂度较高。本文提出一种低复杂度的噪声估计方法,首先利用对数似然比进行VAD判决,对于非语音帧,采用传统的平滑估计算法,对于语音帧,则采用VAD联合语音存在概率进行噪声更新。
1 对数MMSE估计
分别用x(n)、r(n)、y(n)表示纯净语音、噪声和带噪语音,则:

算法在频域对语音信号进行处理,采用短时傅里叶变换(STFT):
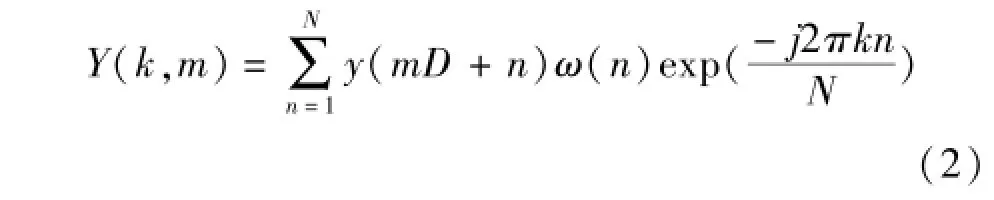
式中m表示帧编号,k表示频率点,D表示重叠的点数,ω(n)为窗函数,则纯净语音可以通过下式计算:
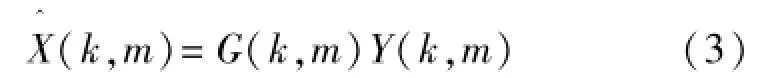
式中G(k,m)为对数MMSE估计器增益函数。其表达式为:
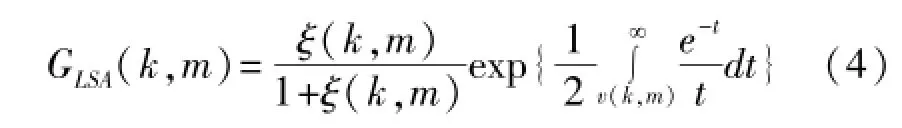

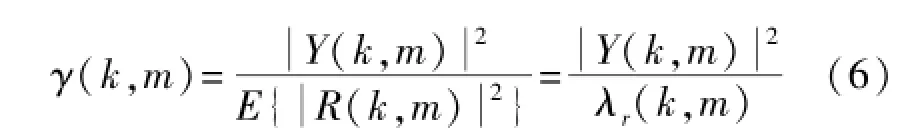
本文采用对数MMSE估计器结合语音存在概率,新的增益函数为:

式中p()表示在频点k给定带噪语音幅度Yk的条件下,存在语音的条件概率。Gmin为小值,具体推导过程参考文献[5]。
2 先验信噪比估计
传统的先验信噪比估计采用了判决引导(DD)法,它是基于先验信噪比的定义及其与后验信噪比的关系,通过递归得到:
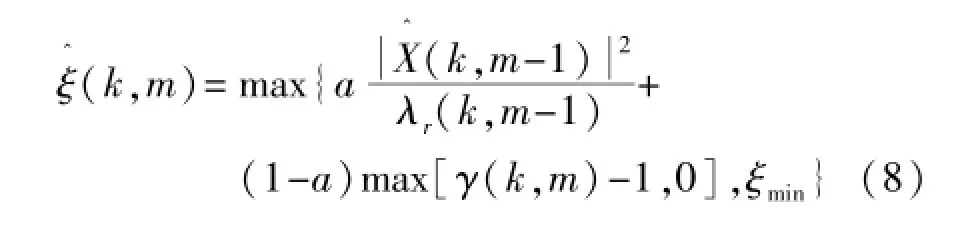
式中a=0.98为平滑因子,(k,m-1)为上一帧估计的纯净语音,λr(k,m-1)为上一帧估计的噪声功率谱,ξmin是ξ(k,m)所允许的最小值,用以限定(k,m)的下限来控制产生的音乐噪声。可见,DD算法存在一帧的时延,且依赖于上一帧所估计的纯净语音,因此在话音的起端和终点处,DD算法并不能很好地反映出当前帧状况,这些会对语音的质量产生较大影响[6]。针对此问题,本节提出了一种改进的低时延DD算法,使用当前帧的语音信号代替上一帧的纯净语音,增益函数仍然使用上一帧计算的增益函数,同时噪声采用当前帧所估计的噪声。具体表达式如下:
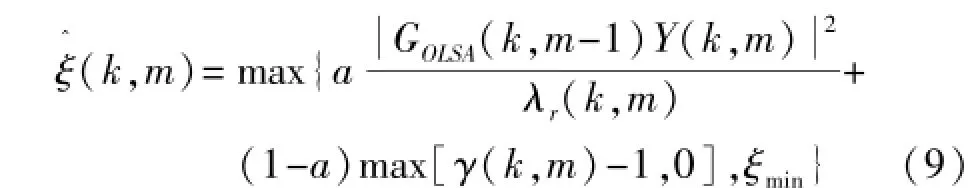
式中平滑因子和先验信噪比允许的最小值均与传统算法相同,ξmin=-25dB。
在公式(9)中,第一项没有采用上一帧的先验信噪比,因此不再是一个递归平滑的算法。这可能会导致对语音的突变会较敏感,从而产生一定的音乐噪声。为此本文对后验信噪比计算方法进行了改进,不再直接使用当前帧的带噪语音,而是对当前帧的带噪语音先进行平滑,再计算后验信噪比,具体表达式如下:

3 噪声估计
噪声估计的准确与否对语音增强的性能是至关重要,如果噪声的估计值偏大,就会造成语音信号的严重失真,导致语音的可懂度下降;反之,如果噪声的估计值偏小,就会产生大量的音乐噪声,影响语音的质量。传统的噪声估计使用语音激活检测(VAD)方法,在信号的无声段(即语音的间隙)进行噪声的估计和噪声谱的更新。尽管这种方法在平稳噪声(白噪声)环境下可以取得较好的效果,但是在更多的现实场景中(餐馆、车站等),因噪声谱特性不断变化,其效果变得不尽理想。近年提出的一些基于语音存在概率的MCRA,IMCRA等噪声估计算法,普遍复杂度较高。本节提出一种将VAD和语音存在概率相结合的改进算法,降低了噪声估计的复杂度。
VAD的判决采用对数似然比,计算公式为:

将每一帧的对数似然比求均值,小于阈值τ,则判定为非语音帧,噪声更新采用下式进行平滑:

式中μ=0.86是一个值固定的平滑因子。
对于语音帧,利用语音存在概率进行噪声更新。

则语音存在概率为:

噪声的更新方式同样采用平滑公式:
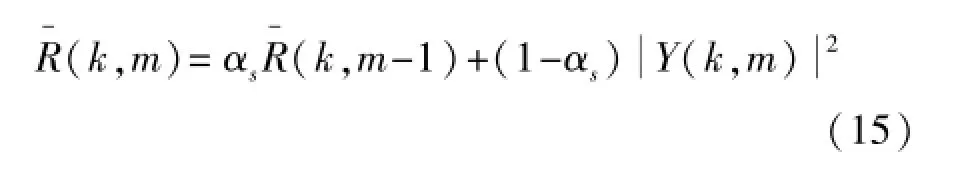
式中平滑因子:αs=αd+(1-αd)p(k,m),αd=0.9,αp=0.2,判决阈值τ的选取,需要综合考虑语音的缺损以及噪声的跟踪速度,如果阈值τ选取的过大,则噪声的跟踪速度快,但语音的缺损会增加;相反,如果阈值τ取值过小,则噪声跟踪速度就会变慢。本文通过大量的实验验证,选取阈值τ=0.11。
算法的流程图如图1所示。

图1 算法流程Fig.1 Flow chart of algorithm
4 实验结果与分析
下图为采用DD算法,改进的DD算法以及γ-1的对比图:

图2 信噪比时延对比Fig.2 SNR delay comparison diagram
从图中可以看出,原始DD算法相比较于γ-1均存在一帧的时延,而改进的DD算法有效的减小了时延。同时为了验证本算法的增强性能,对两种常见的非稳态噪声babble噪声和car噪声进行PESQ、对数谱失真、分段信噪比和总信噪比测试,测试语音采用NOIZEUS语音库语音。并将本算法与OMLSA算法、基于MMSE噪声估计的增强算法以及基于非因果信噪比估计的增强算法[7]进行对比,其中OMLSA算法中的噪声估计采用目前使用较为广泛的IMCRA噪声估计算法以及结合语音存在概率的对数MMSE估计器。图3、图4为性能测试对比结果。
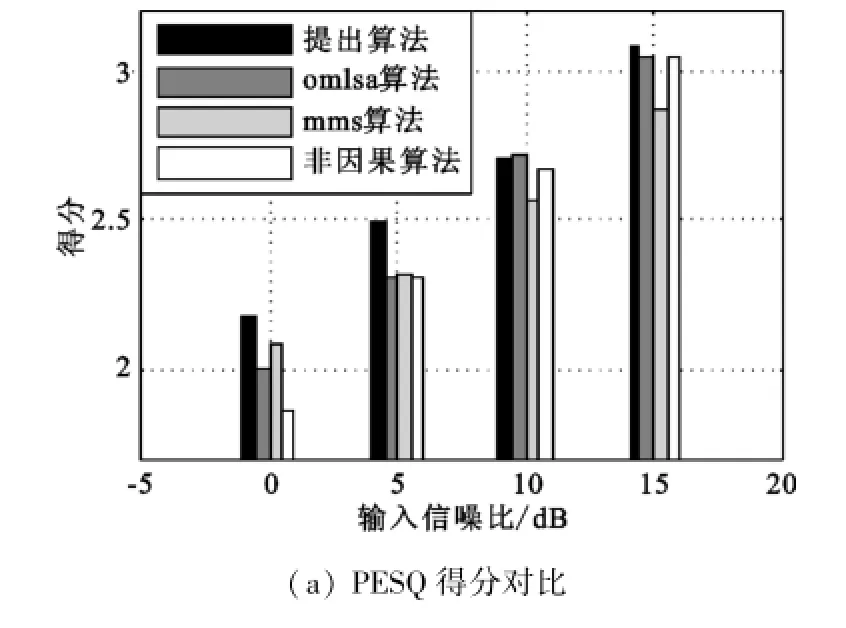

图3 car噪声环境下的对比Fig.3 Comparison diagram in car noise environment


图4 babble噪声环境下的对比Fig.4 Comparison diagram in babble noise environment
可以看出,本文提出的算法在0 dB噪声环境时PESQ得分与其他几种算法相当,但信噪比、分段信噪比和对数谱失真的综合效果要好于其他算法;在5 dB的噪声环境下,其性能优于其他算法,在信噪比较高的环境下,增强效果与其他算法相当。因此本文算法可以很好地在低信噪比非稳态噪声环境下实现语音增强,且在信噪比较高的环境下本算法依然适用。
图(5)为一段纯净语音,加入5 dB的babble噪声后的带噪语音以及增强后的语音波形对比图,从图中可以明显看出本算法在语音的间隙很好的抑制了音乐噪声。
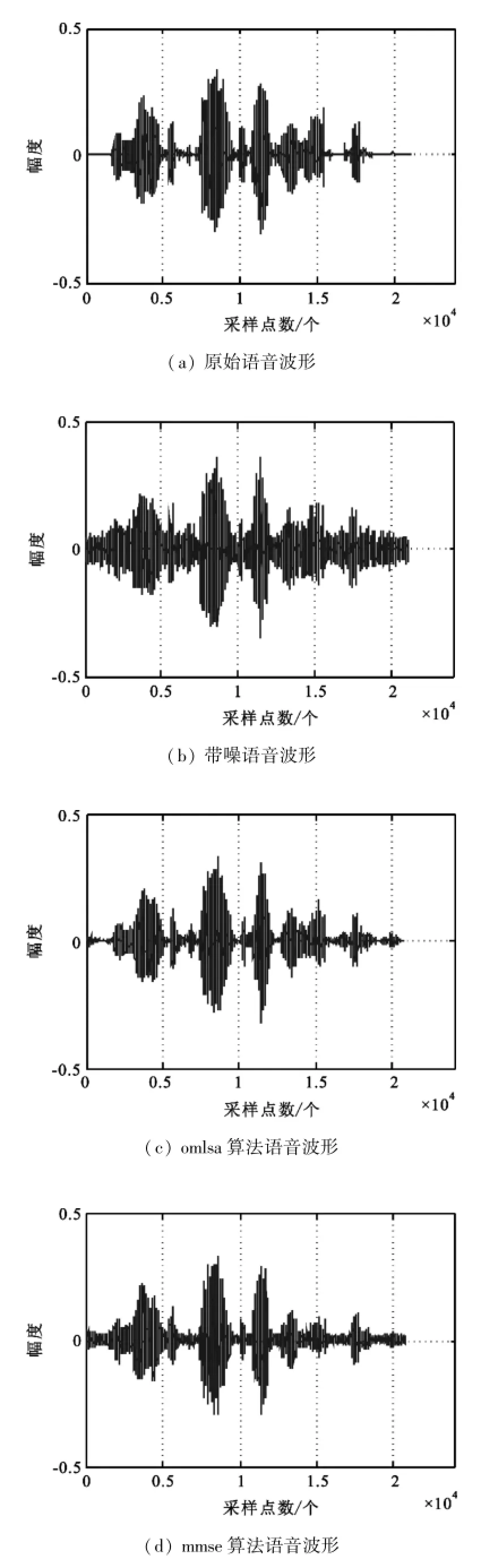
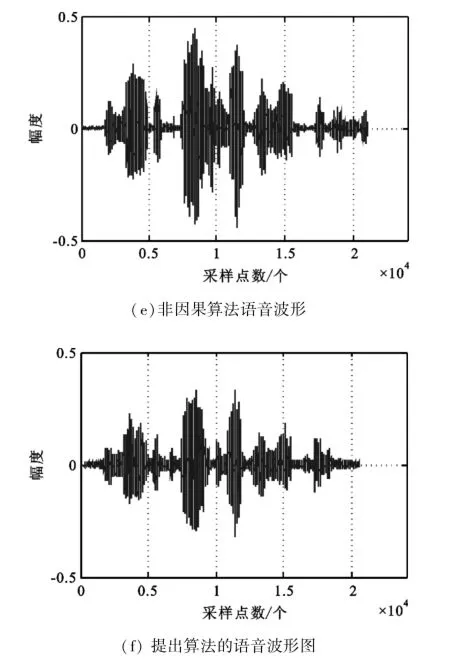
图5 增强前后算法语音波形图对比Fig.5 Waveform comparison before and after speech enhancement
5 结语
本文在研究了传统的判决引导法的基础上,针对其在话音的起始端和结束端存在时延问题,提出将本帧的带噪语音替代前一帧的纯净语音,并对其可能产生音乐噪声采用了带噪语音平滑。同时结合传统的VAD判决法和近年来基于语音存在概率的噪声估计算法,提出了一种低复杂度的噪声更新算法,并在噪声更新结束后依据更新的噪声重新估计了先验信噪比和后验信噪比,使得本帧的增益函数计算更加精确,延时更小。最后通过信噪比、分段信噪比和对数谱失真等多个指标将该算法与最新的几种语音增强算法进行了对比,在信噪比较低的非稳态噪声环境下增强的总体效果要优于另几种算法。该算法时延较低,且结构简单,易于实现,具有较好的实用价值。
[1] LOIZOU P C.Speech Enhancement Theory and Practice [M],CRC Press,2007:337-377.
[2] COHEN I.Noise Spectrum Estimation in Adverse Environments:Improved Minima Controlled Recursive Averaging[J].IEEE Transactions on Speech and Audio Processing,2003,11(05):466-475.
[3] GERKMANN T,HENDRIKS R C.Unbiased MMSE-based Noise Power Estimation with Low Complexity and Low Tracking Delay[J].IEEE Transaction on Speech and Language Processing,2012,20(04):1383-1393.
[4] GERKMANN T.Noise Power Estimation Based on The Probability of Speech Presence[C]//IEEE Workshop on Application of Signal Processing to Audio and Acoustics. New Paltz:USA,2011:145-148.
[5] Cohen I.Optimal Speech Enhancement Under Signal Presence Uncertainty Using Log-spectra Amplitude Estimation[J].IEEE Signal Processing Letters,2002,9 (04):113-116.
[6] YONG P C,NORDHOLM S,DAM H H.Trade-off E-valuation for Speech Enhancement Algorithms with Respect to The a Priori SNR Estimation[C]//IEEE International Conference on Speech and Signal Processing(ICASSP).Kyoto:Japan,2012:4657-4660.
[7] 张涛,李辉。基于非因果先验信噪比估计的语音增强方法[J].通信技术,2010,43(02):60-62.
ZHANG Tao,LI Hui.Speech Enhancement Based on Noncausal A Priori SNR Estimator[J].Communications Technology,2010,43(02):60-62.
Modified Low-Delay Speech Enhancement Algorithm
PANG Liang1,CHEN Liang1,ZHANG Yi-peng2
(1.Institute of Communication Engineering,PLAUST,Nanjing Jiangsu 210007,China; 2.Nanjing Artillery Academy of PLA,Nanjing Jiangsu 211132,China)
Aiming at current long-time delay of speech enhancement algorithms,this paper proposes a low -delay speech enhancement algorithm which improves the decision-directed algorithm with low delay based on the traditional prior SNR estimation and noise estimation,and introduces a noise estimation algorithm based on the combination of speech existence probability and VAD.This algorithm combines logarithmic MMSE estimator with speech existence probability.Meanwhile,ITU-T P.826 PESQ,segmental SNR,overall SNR,and logarithmic spectrum distortion are adopted to test the proposed algorithm,and comparisons with other speech enhancement algorithms also done.Experimental results show that the new algorithm can yield good performance in reducing time-delay and tracking non-stationary noise,particularly in the case of low SNR,and can also effectively suppress musical noise and residual noise.
speech enhancement;decision-directed;priori SNR estimation;noise spectrum estimation
TN912.35
A
1002-0802(2014)11-1276-05
10.3969/j.issn.1002-0802.2014.11.008
2014-09-09;
2014-10-19 Received date:2014-09-09;Revised date:2014-10-19
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
数学物理学报(2022年2期)2022-04-26
新世纪智能(数学备考)(2021年9期)2021-11-24
陕西理工大学学报(自然科学版)(2021年3期)2021-06-23
新世纪智能(数学备考)(2020年9期)2021-01-04
中国惯性技术学报(2019年6期)2019-03-04
中学生数理化·高一版(2018年10期)2018-11-08
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
自动化学报(2017年5期)2017-05-14
火控雷达技术(2016年3期)2016-02-06
