
基于动态规划的简单语义单元词义消歧
2014-02-09 07:46:42刘运通
计算机工程与设计 2014年4期
刘运通,孙 华
(安阳师范学院计算机与信息工程学院,河南安阳455000)
0 引 言
当前,在自然语言处理领域,语义信息的作用越来越被重视,学者们对利用语义来进行词义消岐,做了许多有益的探索性研究。文献[1]研究了基于利用How Net语义相关度进行词汇语义消岐方法;文献[2]研究了基于Word Net语义相关度的词汇语义消岐方法;文献[3]研究了基于维基的两阶段语义消歧方法;文献[4]研究了基于词语距离的网络图的语义消歧;文献[5]研究了基于知网的中文信息结构消歧研究;文献[6]研究了基于知网词汇语义相关度计算的消歧方法;文献[7]研究了基于语义相关度的语义模型求解;文献[8]研究了基于Word Net的词汇语义消岐模型;文献[9]研究了基于Word Net语义树的语义消岐方法;文献[10]研究了基于Word Net语义关系网的信息处理。
这些研究虽然取得很多成果,但并没有形成一个比较成熟、有效的计算方法,消岐效果依然有很大的提高余地。为了能够通过语义计算,实现高效、准确的语义消歧,我们提出了一种基于动态规划的简单语义单元词义消歧方法。先阐述了语义相关度计算模型,提出简单语义单元的概念,分析了简单语义单元的特点;采用动态规划的方法,依次求出每个词汇的所有义项的最大生成树变量;最后求出语义修饰关系完全图的最大生成树;可以很容易地将最大生成树转化为最佳的语法分析方案和实现词义消歧。
1 基本理论
1.1 语义相关度计算模型
假设一个语句(CS)中的任意实词Wi(除去谓语中心词)均语义修饰于另外一个实词WGi,称WGi是Wi语义修饰目标,用函数match(Wi,WGi)来表示其语义相关度。
假设语句CS有m种不同的语法分析方案,在其中第i种语法分析方案Ai的情况下:假设V为谓语中心词,S为V的施动者,O为V的承受者,Wi是语句中的一个实词且!(Wi∈{S,V,O}),WGi是Wi的语义修饰目标,那么,语句的语义相关度fAi(针对语法分析方案Ai)可以用式(1)来表示(如图1所示)

其中,S和O的语义修饰目标是V,n是实词的个数(不包括S、V、O),KSVO为权值系数(KSVO>1),KSVO应正比于语句的长度。
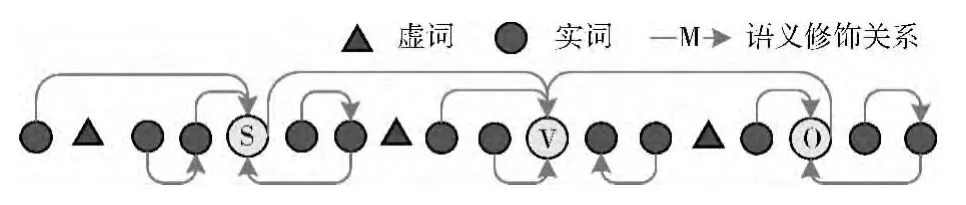
图1 语义相关度计算模型
值得注意的是:虚词不参与计算,副词、代词、数词、量词被按照实词计算。
最佳结果选择规则:假设一个语句具有m种语法分析方案,最符合语义逻辑的语法分析方案Ai满足式(2)的条件

即语义相关度最大的语法分析方案是最佳语法分析方案。
1.2 简单语义单元
假设语句CS的语义结构为:CS→LSLOLVL,S、V、O中间的段落为L(如图2所示);并假定分段L已经被划分到了“不包含从句”的程度,则可以根据L内各部分语义作用的不同,将L划分为:前置定语(用AB表示)、后置定语(用AA表示)、状语(用PD表示)。
定义1(简单语义单元) 在把S、V、O中间的“不包含从句”的分段L划分为AB、AA或PD的情况下,AB+S(或O)、AA+S(或O)、PD+V就是简单语义单元(如图2所示,假定L的语义结构为:L→AAPDAB)。
1.3 简单语义单元的语义特征
简单语义单元的特点:
(1)除了所附加的S、V、O外,其它任何词汇Wi的语义修饰目标WGi都在简单语义单元内部;
(2)在语义分析时,可以作为一个整体来处理,其内部语法结构对语句的其余部分没有影响;
(3)由于其中不包含从句,在语义计算时,每个词的权重相同,无需考虑S、V、O的影响。
本文的算法,正是针对这种特点而提出的。

图2 简单语义单元的语义特征
1.4 AA、PD、AB的最佳界限划分
假定一个分段L的语义结构为:L→AAPDAB,且L包含m个词汇;则AA、PD、AB的不同界限划分方案共有种;可以根据式(1)与式(2)的方法,分别计算出每一种界限划分方案的语义相关度值,然后选择具有最佳语义相关度值的界限划分方案作为AA、PD、AB的最佳界限划分方案。
1.5 多义词的语义相关度计算
针对两个词汇Wi和Wj(假设其为多义词),依据How Net计算其语义相关度时,有两种情况:
(1)按义项计算;
(2)词汇作为一个整体进行计算。
1.5.1 义项之间的语义相关度
针对一个树状词汇语义库(在本文的实验中,采用了How Net),两个词汇Wi与其语义修饰目标WGi之间的语义相关度可用式(3)计算

1.5.2 词汇之间的语义相关度
假如把词汇Wi和WGi当做一个整体,可根据式(4)来计算其语义相关度

其值为所有义项之间语义相似度的最大值。
2 简单语义单元的语义消歧
2.1 最佳语法分析方案的语义修饰关系图
在不考虑一词多义的情况下:假如把简单语义单元中的m个实词当做m个顶点,任意词汇Wi与其语义修目标WGi之间画一条边;由于Wi只有一个语义修饰目标(最后一个词汇没有语义修饰目标);所以,每种语法分析方案都对应于“m完全图中的一颗生成树”,如图3所示。

图3 每种语法分析方案都对应于完全图的一颗生成树
假如“把Wi和WGi之间的边的权值设置为Match(Wi,WGi)”,则最佳语法分析方案就对应于“完全图的最大生成树”。这可以很容易地求出。
但这种方法不能实现“多义词的语义消歧”,因此,也不能求出多义词的最佳语法分析方案。
2.2 多义词的语义修饰关系图
自然语言中,大多数词汇是多义词,对简单语义单元进行语法分析和语义消歧时,可以先画出其语义修饰关系图,其中,多义词的所有义项形成一个集合,每个义项是该义项集合中的一个点。假设其的词汇序列L=Wm…Wi…W…Wp…W…W0,如图4所示,在某个语法分析方案中,Wi的语义是其第j个义项,Wp的语义是其第q个义项,并且语义修饰于;则在语义修饰关系图中的和之间,画一条有向线段;在词汇序列L上也画一条有向线段。
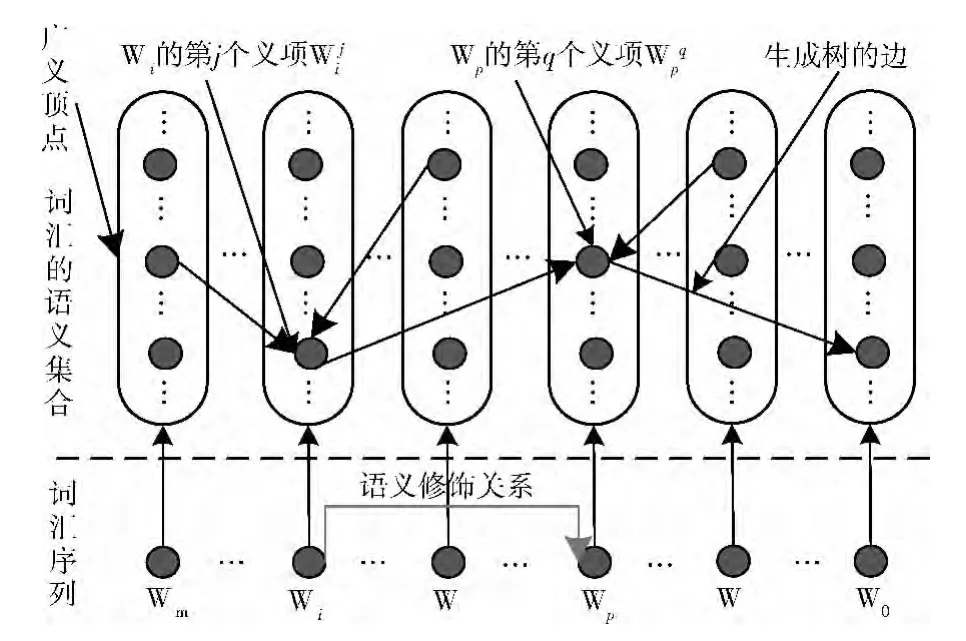
图4 多义词的语义修饰关系
在图4中,假如把每个词汇的“义项集合”看成一个“广义顶点”,义项看成一个“义项顶点”,则有以下特点:
(1)任意“广义顶点”只有一个语义修饰目标,其出度为1,最后一个“广义顶点”除外;
(2)每种语法分析方案,其语义修饰关系图必然为一个“广义顶点完全图”的一颗“生成树”;
(3)在每个“义项集合”中,“生成树”的所有边,必须关联同一个“义项顶点”;
(4)根据语义计算模型,具有最大语义相关度的语法分析方案,其语义修饰关系图是“广义顶点完全图”的“最大生成树”。
2.3 最大生成树变量
可以用穷举法直接求取“广义顶点完全图”的“最大生成树”,但其计算复杂度将是指数级别的,理论上不可行。
为了解决这个问题,我们采用了动态规划法,可以解决这个问题。首先,需要定义一个“最大生成树变量”(如图5所示),其含义为:针对词汇Wi,其第j个义项有多个生成树,其中各边权值之和最大的生成树,用MT()表示,MT()必须包含所对应的点。

图5 最大生成树变量
2.4 求最大生成树的动态规划算法
先将所有“广义顶点”划分为U、V两个集合:
U={所有未计算出MT的“广义顶点”}
V={已经计算出MT的“广义顶点”}
动态规划算法(算法1):
步骤1 初始化
设置V={W1,W0},其中的W0只有一个义项,就是简单语义单元中的S或V或O;由于只有两个“广义顶点”,因此很容易算出W1的任意义项的最大生成树:
MT()={到W0的边}
MT(W0)=max{WT()}所对应的生成树。
步骤2 计算U中词汇Wi的最大生成树变量
针对U中最后一个词汇Wi,其每个义项与V中的任意义项之间,都可以计算出一个语义相关度,按照式(5),选择能够使MT()达到最大的那个义项(如图6所示),更新的最大生成树变量MT()的值

步骤3 对Wi的所有生成树进行逆排序
在求Wi的最大生成树变量的过程中,需要穷举Wi的所有生成树,在穷举的时候,按照由大到小的顺序,保存Wi的所有生成树序列,用TList表示,则

图6 计算集合U中义项的最大生成树变量

步骤4 更新V中所有义项的最大生成树变量
当求出U中最后一个词汇Wi的每个义项的最大生成树变量后,可以考虑把Wi加入集合V;但这将致使V中每个义项的最大生成树变量发生极大的变化,因此,在将Wi加入集合V之前,必须更新V中所有义项的最大生成树变量。
更新算法的思路如图7所示,从TList中找到Wi的最大生成树(用粗线画出),其在V中所相关的6个义项,就是“第1次更新的义项集合”;接下来,从TList中找到W i的第2大生成树,其在V中所相关所有义项中,有4个义项没有更新过,这4个义项就是“第2次更新的义项集合”;以此类推,直至V中的所有义项都被更新过。其过程可以用算法2来描述。

图7 更新集合V中所有义项的最大生成树变量
算法2:

步骤5 将词汇Wi加入V
更新完V中的所有义项的最大生成树变量之后,就可以将Wi加入集合V了。
步骤6 循环处理,直至U为空
返回步骤2,进行循环,直至U为空。最后选出词汇Wm的最大生成树即可。
2.5 计算复杂度分析
假设简单语义单元包含m个词汇,每个词汇平均有t各义项。假如用穷举法求解:理论计算复杂度为O(m2*tm)。
假如用动态规划法求解:
(1)共有m个词汇;
(2)求Wi的最大生成树变量时,平均有t个义项;
因此,本方法的理论计算复杂度为:O(m*t*(m*t/2))=O((m*t)2)。
3 实验结果及分析
本文的实验中,以How Net作为词汇语义计算时所依据的资源。选取了100个语句进行实验,先人工对其分析,将其划分为406个简单语义单元,并得到语义消歧的正确结果,然后与算法计算所得到的结果进行对比。实验情况如下:
(1)不分义项计算:用Prim算法求最大生成树,得到最佳语法分析方案,不能实现语义消歧。
(2)分义项计算:分别使用穷举法、动态规划法进行计算,可以得到最佳语法分析方案,还可以确定多义词的义项,从而实现语义消歧。
3.1 语法分析实验情况
语法分析指的是“求出每个词汇W的语义修饰目标WG”的过程。实验环境为:Windows XP,Xeon E5-2403四核,主频2.2GHz,8G内存,实验情况见表1、图8与图9。
在表1中,穷举法、动态规划法的正确率计算标准有两个:

表1 每个简单语义单元平均计算时间(毫秒,语义消歧正确率阀值=0.5)

图8 正确率对比

图9 穷举法时间/动态规划法时间
(1)语法分析方案正确;
(2)语义消歧的正确率大于设定的阀值0.5。表1每个简单语义单元平均计算时间(毫秒,语义消歧正确率阀值=0.5)。
从实验结果可以看出:
(1)不分义项计算的情况下,由于它没有实现语义消歧,正确率最高。
(2)穷举法、动态规划法的计算结果一致,因为实现了语义消歧,其正确率有所降低。
(3)随着简单语义单元长度的增加,正确率逐渐下降。
(4)随着简单语义单元长度的增加,穷举法计算所需的时间急剧增加;而动态规划法所需时间一直保持在可以接受的范围内,实践上可行。
3.2 语义消歧实验情况
穷举法和动态规划法的计算结果一致,可以实现语义消歧。语义消歧的实验情况见表2与图10。

表2 语义消歧实验情况(总个数=406)
由实验结果可知,虽然本方法能实现语义消歧,但其正确率还不太高,有待进一步的提高。
4 结束语
本文研究了基于动态规划的简单语义单元词义消歧方法,先把语句划分、转化为简单语义单元,通过态规划的方法,求出其语义修饰关系完全图的最大生成树,并将其转化为最佳的语法分析方案,同时也实现了词义消歧。最后通过实验,对本文的方法进行验证,结果表明本文的方法具有一定的效果。从理论上讲,本方法可以较为有效地进行语义消歧,但实际的计算效果并不十分理想,其主要原因是所依据的How Net的语义准确度、多义词的语义细致程度等,有很多欠缺和不足。另外,本文研究的前提是“不考虑简单语义单元中的任何语法规则”;这是不符合实际情况的,至少有3种情况需要考虑:①具有连接、分段作用的虚词,其语法作用不容忽视;②后向修饰规则,这是汉语中最常见的默认语义规则;③不越界规则,即W1~WG1之间的词汇Wi的语义修饰目标WGi,应该位于W1~WG1之间。这些问题都有待在下一步研究中加以解决。
[1]WANG Guangzheng,WANG Xifeng.Word sense disambiguating method based on How Net semantic relevancy computation[J].Journal of Anhui University of Technology(Natural Science),2008,25(1):71-75(in Chinese).[王广正,王喜凤.基于知网语义相关度计算的词义消歧方法[J].安徽工业大学学报(自然科学版),2008,25(1):71-75.]
[2]Deepesh Kumar Kimtani,Jyotirmayee Choudhury,Alok Chakrabarty.Improvement in word sense disambiguation by introducing enhancements in English Word Net structure[J].International Journal on Computer Science and Engineering,2012,4(7):1366-1370.
[3]Chenliang Li,Aixin Sun,Anwitaman Datta.TSDW:Twostage word sense disambiguation using Wikipedia[J].Journal of the American Society for Information Science and Technology,2013,64(6):1203-1223.
[4]YANG Zhizhuo,HUANG Heyan.Graph based word sense disambiguation method using distance between words[J].Journal of Software,2012,23(4):776-785(in Chinese).[杨陟卓,黄河燕.基于词语距离的网络图词义消歧[J].软件学报,2012,23(4):776-785.]
[5]ZHANG Ruixia,ZHUANG Jinlin,YANG Guozeng.Chinese message structures disambiguation based on How Net[J].Journal of Chinese Information Processing,2012,26(4):43-60(in Chinese).[张瑞霞,庄晋林,杨国增.基于知网的中文信息结构消歧研究[J].中文信息学报,2012,26(4):43-60.]
[6]LI Shengqi,TIAN Qiaoyan,TANG Cheng.Disambiguating method for computing relevancy based on How Net semantic knowledge[J].Journal of the China Society for Scientific and Technical Information,2009,28(5):706-711(in Chinese).[李生琦,田巧燕,汤承.基于知网词汇语义相关度计算的消歧方法[J].情报学报,2009,28(5):706-711.]
[7]LIU Yuntong,LIANG Yanjun.The k-pruning algorithm for semantic relevancy calculating model of natural language[J].Computer Engineering and Design,2013,34(8):2939-2943(in Chinese).[刘运通,梁燕军.自然语言语义相关度计算模型的k枝剪求解法[J].计算机工程与设计,2013,34(8):2939-2943.]
[8]Kostas Fragos.Modeling Word Net glosses to perform word sense disambiguation[J].International Journal on Artificial Intelligence Tools,2013,22(2):1345-1352.
[9]Minca A,Diaconescu S.An approach to knowledge-based word sense disambiguation using semantic trees built on a Word Net lexicon network[C]//The 6th Conference on Speech Technology and Human-Computer Dialogue,2011:1-6.
[10]Suvitha D S,Janarthanan R.Enriched semantic information processing using Word Net based on semantic relation network[C]//International Conference on Computing,Electronics and Electrical Technologies,2012:846-851.
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
作文大王·低年级(2021年9期)2021-09-10 20:54:28
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
电脑与电信(2018年12期)2018-03-23 02:37:20
高中生·天天向上(2017年10期)2018-01-18 21:51:58
湖北经济学院学报·人文社科版(2015年10期)2015-12-29 05:53:16
陕西学前师范学院学报(2015年4期)2015-12-25 06:33:18
知识窗(2015年1期)2015-05-14 09:08:17
Beijing Review(2012年37期)2012-10-16 02:24:10
中文信息学报(2012年4期)2012-06-29 06:29:14
