
图像背景下的满文文字提取
2014-02-08 05:43朱满琼崔艳秋丛碧辉
大连民族大学学报 2014年1期
朱满琼,李 敏,许 爽,崔艳秋,丛碧辉
(1.北方民族大学数学与信息科学学院,宁夏银川 750021;2.大连民族学院a.理学院,b.信息与通信工程学院c.计算机科学与工程学院,辽宁大连 116605)
满族作为曾经的统治阶级,大量涉及政治、文 化、经济、军事、外交、天文等各个方面的资料都是用满文记载的,具有很高的史料价值。如果满语消失,那么这些史料也失去了它的价值。而现在全国会说满语的人很少,精通满语的人更是少之又少,因此,研究满文识别系统对保护清代文化遗产来说显得尤为重要。同时,对其他阿尔泰系语言的扫描识别,尤其对蒙古文和锡伯文的识别研究也有很大的贡献。而满文文字的提取又是满文识别系统的关键步骤,因此做好满文文字的提取工作显得尤为重要。
随着计算机技术、多媒体技术和通信技术的飞速发展,以图像、音频和视频为主的多媒体信息正在迅速成为信息交流与服务的主流。而图像中的文字也反映了该图像的部分重要内容[1]。要正确的识别图像中的文字,关键就是要准确的提取出图像中的文字。而对满文文字进行正确的提取是提高满文文字的识别率一个重要环节,本文主要研究采用笔画生长法进行图像背景下的满文文字的提取方法。
1 满文文字笔画提取系统结构
图1给出了图像背景下满文文字提取框图。
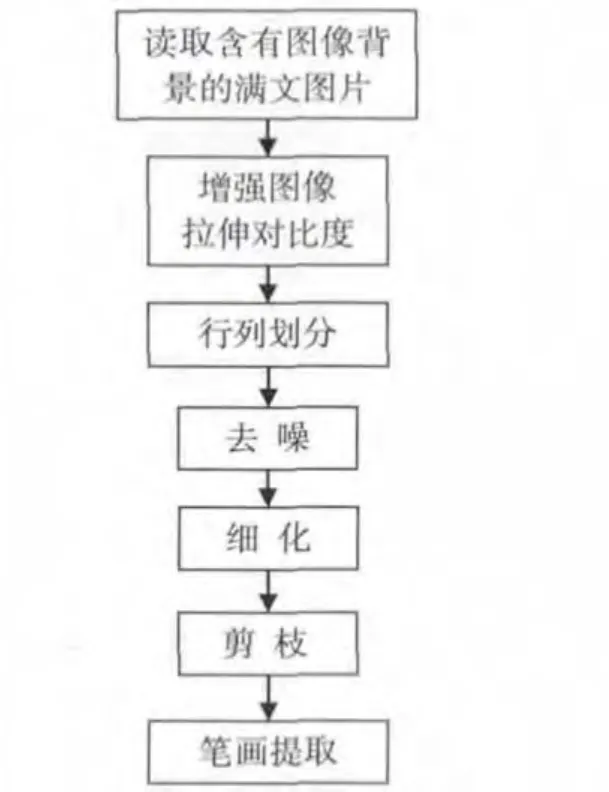
图1 满文文字笔画提取框架图
由图1可知,输入图像后,通过对像素点的灰度值分析进行行列划分提取满文单字。将提取到的满文单字二值化,然后进行包括去噪、细化、剪枝等预处理操作,最后对预处理后的单字进行笔画提取。
2 图像背景下满文文字的提取
首先读取满文文字图像,如图2(a)。由于图像是彩色图像,首先要进行灰度转化,将彩色图像转换为灰度图像,为了更好的进行分割,本文采用的办法是将图像增强[2],拉伸对比度,然后通过迭代法求出阈值,将图像进行行列分割,提取出单个满文文字,为下一步的预处理做准备。
2.1 预处理
预处理是整个系统中重要的一环,它把原始图像转换成识别器能够接受的形式,消除一些与类别无关的因素,从而更有利于笔画的提取。对比度拉伸后的单字图像如图2(b)。从图像中可以看出这个满文单字有阴影,因此首先应该将阴影去掉。本文的做法是先找到每一行中第一个像素值不为0的像素点和最后一个像素值不为0的像素点,然后将第一个不为0的像素点和最后一个不为0的像素点之间的像素值放在一个新的矩阵中,如图2(c)。然后将图像灰度值的算术平均值作为新的阈值,将灰度值大于阈值的像素值置为255,将灰度值小于阈值的像素值置为0,最后将图像二值化,如图2(d)。

接下来只需要对满文单字进行预处理,将字周围的噪声去掉即可。预处理主要完成去噪、细化和剪枝的工作。具体过程如下:
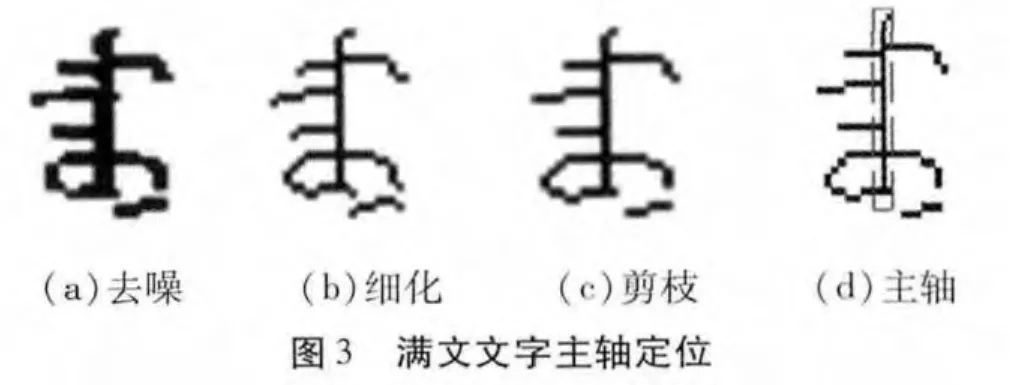
(1)去噪。由于满文文字在主轴左侧的细节特征较多,右侧细节特征较少,本文采用形态学图像处理滤去噪声[3-4]。首先设定一个结构元素,通过实验发现用1×2的矩形结构元素的效果最好。用该结构元素腐蚀满文单字,然后对腐蚀过的图像进行闭运算,但是从图像看没有达到理想的效果,因此针对不理想的地方再进行腐蚀处理,根据需要可以设定新的结构元素。经过形态学滤波处理将噪声去掉,如图3(a)。
(2)骨骼化。经过噪声处理之后需要将满文单字细化[5]。由于细化会将文字细化成环形,改变了原有的形状,因此本文采用骨骼化的方法,骨骼化后仍保留原始对象形状的重要信息,如图3(b)。
(3)修剪。由于骨骼化通常会产生无关的“毛刺”或寄生成分,修剪就可以去掉这些“毛刺”,在这里进行一次修剪即可,如图3(c)。
尽管满文也是由字母组成,但它不像英文单词的字母之间界限的很清晰,满文文字的字母与字母之间没有空隙,而且不同的字母在不同的位置有不同的写法,这就使得满文笔画的划分十分的困难。
对此,本文采用基于笔画基元的划分方法,通过分析发现,满文大多为竖写体,字体结构为左右结构,因此每个满文文字都有一条主轴作为主干,所有的笔画都以主轴为中心向外扩展。在主轴左侧并与主轴相连的笔画称为左连接笔画,不相连的称主左游离笔画;在主轴右侧并与主轴相连的笔画称为右连接笔画,不相连的称为右游离笔画。这样,笔画就被分为四类,分别是左连接笔画、右连接笔画、左游离笔画和右游离笔画[6]。
2.2 提取主轴
预处理完成后,对提取到的文字进行行列扫描,找到有效像素点最多的一列作为主轴,如图3(d),中间最长的一列就是主轴。为了减少由于书写原因或者图像采集过程中导致的主轴位移,本文对主轴向左向右进行水平扩展,扩展宽度为提取文字宽度的十分之一。
2.3 笔画分类
文字细化后像素点可以分为以下类别:
(1)临界点。已经找到了主轴的边界,在边界上逐行扫描找到像素值不为零的点,然后将其储存起来就得到了临界点。根据相交边界的不同又分为左临界点和右临界点。
(2)内部点。对预处理后的单字逐行扫描,若该点的像素值为1并且其八邻域像素值的和为2,那么将该点存储起来,直到扫描完成为止,即Bx=2且Rx=1。根据边界所划分的区域,把内部点分为边界外的内部点和边界内的内部点。
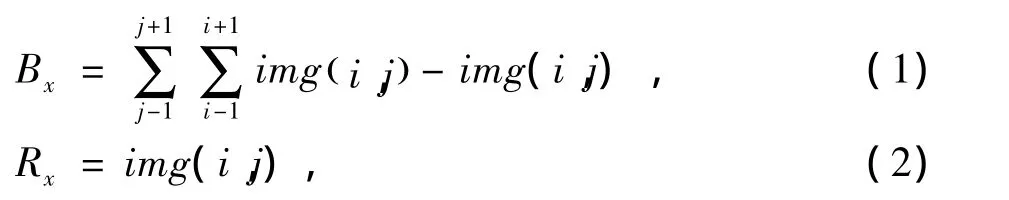
其中i,j为当前像素值所在位置,img为预处理后的图像,Bx表示当前像素值的八邻域像素和,Rx为当前像素值。
(3)交叉点。如果扫描到有效像素点并且该点的8邻域的有效像素值的和大于2,即Bx>2且Rx=1,那么该点即为交叉点。
(4)终止点。如果扫描到有效像素点并且该点的8邻域的有效像素值的和为1,即Bx=1且Rx=1,那么该点即为终止点。
2.4 笔画生长
在满文文字的像素点被分类后,采用笔画生长法进行文字笔画提取[7]。在运用笔画生长法的时候要注意种子像素、生长准则和生长停止准则的确定。具体步骤如下:
(1)首先生成一个与原图像同样大小的零矩阵,并在其中生成主轴,然后对其进行反色处理。先将左临界点中第一个边界点作为种子点进行生长。
(2)根据左临界点周围像素值的大小设定一个阈值,由于图像已经被二值化处理,因此本文设定的阈值为0。将符合区域生长条件的点的初始个数设为1,对与临界点邻接的左边的有效像素点进行跟踪,如果跟踪得到的像素点的像素值与该临界点的像素值的差小于设定的阈值,那么将该跟踪点列为有效点,以新得到的像素点为种子继续生长;若大于该阈值,则生长停止。
(3)跟踪结束后,将得到的所有有效像素点进行集合就得到了由生长构成的笔画。
(4)然后依次扫描左边界上的其它临界点就得到了相应的连接笔画。同样的方法对右临界点扫描。由左临界点生长得到的笔画为左连接笔画,由右临界点生长得到的笔画称为右连接笔画。如果不同临界点在边界外有重合的像素,那么合并这两个临界点生长的笔画集合。
这样,脱机手写满文文字的笔画就被提取了出来,提取过程如图4(a)—(i)。
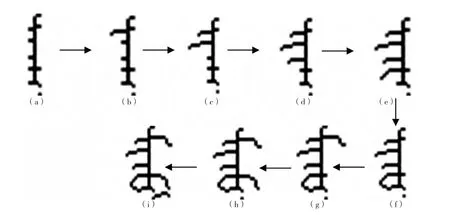
图4 满文文字笔画生长提取过程
2.5 实验
为了验证笔画生长法在文字提取上的效果,本文对含有手写体满文的图像进行文字提取。图像中一共有500个不含游离笔画的手写体满文,经过预处理后采用笔画生长法进行文字提取,可以将这500个满文都提取出来,提取率达到100%,如图5中,(a)为手写体原图像,(b)为手写体满文主轴定位,(c)为经过笔画生长提取到的文字,可以看出准确率较高;用笔画生长法对一幅含有300个印刷体满文文字的图像进行文字提取,同样提取率达到100%。如图6,(a)为印刷体原图像,(b)为定位主轴定位,(c)为经笔画生长提取的文字。从实验结果可以看出笔画生长法对于满文文字的提取是有效的。

图5 手写体满文提取
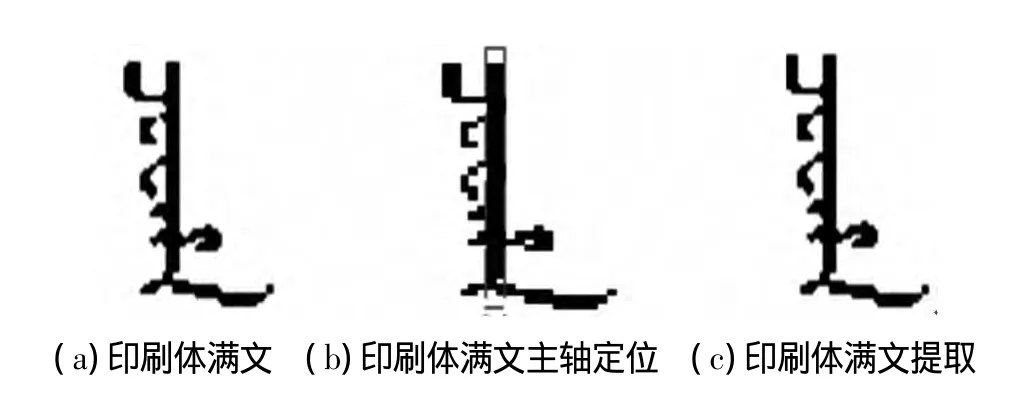
图6 印刷体满文提取
3 结语
本文采用笔画生长法对手写体满文、印刷体满文和彩色图像背景下的满文文字进行提取,采用数字图像处理的方法对图像进行预处理,通过膨胀和腐蚀达到去噪的效果,对去噪后的图像进行细化和剪枝。然后提取文字的主轴,在主轴上找到笔画生长的种子点即临界点,最后根据笔画生长法提取笔画,从而达到文字提取的目的。实验证明该方法能够准确的将彩色图像中的满文文字提取出来,是一个很好的文字提取方法,从而为满文文字的识别打好基础。
[1]闻京,张凌,袁华.一种复杂背景图像中文字区域提取算法[J].中山大学学报:自然科学版,2008,47(Z1):5-10.
[2]王志瑞,闫彩良.图像特征提取方法综述[J].吉首大学学报:自然科学版,2011(05):43-47.
[3]武瑛.形态学图像处理中的应用[J].计算机与现代化,2013(5):90-94.
[4]GONZALEZ R C,WOODS R E,EDDINS S L.数字图像处理[M].阮秋琦,译.北京:电子工业出版社,2005.
[5]王嘉梅,文永华,李燕青,等.基于图像分割的古彝文字识别系统研究[J].云南民族大学学报:自然科学版,2008(01):76-79.
[6]张广渊,李晶皎,王爱侠.脱机手写满文笔画基元的提取与识别[J].计算机工程,2007(22):200-202.
[7]陈方昕.基于区域生长法的图像分割技术[J].科技信息:科学教研,2008(15):58 -59.
(责任编辑 刘敏)
猜你喜欢
海洋通报(2022年4期)2022-10-10
现代电子技术(2021年1期)2021-01-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
政工学刊(2017年2期)2017-02-20
民族古籍研究(2014年0期)2014-10-27
民族古籍研究(2014年0期)2014-10-27
中国边疆民族研究(2014年0期)2014-02-13
民族古籍研究(2012年0期)2012-10-27
