
基于HBase的输电线路综合数据存储方案设计
2014-01-28 07:26于恒友彭子平
电力科学与技术学报 2014年2期
于恒友,刘 波,彭子平
(1.广东电网公司 中山供电局,广东 中山 528400;2.广州运维电力科技有限公司,广东 广州 510600)
信息和能源始终是世界关注的两大焦点话题。随着电网智能化、信息化、集成化程度的不断加深和提高,由此产生的大量数据为电网的发展带来了新的挑战和机遇[1-6]。在电力系统的整个生产过程中,包括发、输、变、配、用、调度、协调等各个环节都伴随着各种各样的信息流。输电线路作为保障电网安全可靠运行的重要组成部分,在实际运行中会产生种类繁多、数量巨大的各类数据,包括线路自身的属性信息、各种状态监测数据、投运前离线实验数据、电网运行数据、地理信息数据、公共安全信息数据、线路自身的运维记录数据等结构化和非结构化数据。并且随着测量采集点越来越多,电网运行和设备检/监测产生的数据量呈指数增长,构成了当今信息学界所关注的大数据[6-7]。
早在2011年全球知名的咨询公司Mckinsey发布了一份关于大数据的详尽报告[7],就大数据的影响、关键技术和应用领域等都做了详尽的分析,阐明了大数据研究的地位以及蕴含的巨大的社会价值。中国电机工程学会信息化专委会于2013年3月出版发布了《中国电力大数据发展白皮书》[8],该书对电力大数据的起源、内涵、特征、价值分析、应用前景、发展挑战、关机技术以及发展策略给出了详细的解释和说明。
Hadoop[9]是Apache开源组织的一个分布式计算框架,支持在大量廉价的硬件设备组成的集群上运行数据密集型应用。HBase[10]是能够提供高可靠性、高性能、列存储、可伸缩的数据库系统。笔者结合中山供电局的现状,提出基于Hadoop和HBase的输电线路综合数据存储方案,解决了原有数据信息共享性差、信息呈孤岛、非结构化数据难以处理等问题。
1 大数据概念
大数据是指无法在一定时间内用传统数据库软件工具对其内容进行抓取、管理和处理的数据集合[8]。与传统数据相比,大数据在数据量上由以前的GB级别提升到TB甚至PB级别,增长速度方面也由以前的稳定增长变为年增长量在60%以上,数据结构也从单一的结构化数据转变为结构化和非结构化数据。
在电力领域内,电网业务数据可分为3类:电网运行和设备检测或监测数据、电力企业营销数据及电力企业管理数据[11]。电力行业的大数据具有数据体量巨大、数据类型繁多、价值密度低及处理速度快等特点[8,12-13]。
2 输电线路的综合数据
2.1 输电线路综合数据的复杂性和多源性
输电线路分为架空线和电力电缆2种。输电线路分布地域广、跨度大,与其相关的数据既分散又类型繁杂,如:架空线和电缆的生产日期、规格型号、离线实验、家族缺陷等属性信息类数据;架空线杆塔坐标、电缆标识球位置坐标、电缆某段敷设方式等地理信息类数据;微气象、雷击、覆冰、外力破坏、塔基滑坡等公共安全类数据;导线温度、弧垂、架空线绝缘子泄漏电流、架空线视频监测、电缆护层环流等在线监测类数据;线路运行电流值等电网运行类数据;线路的运行维护记录等运维数据等。输电线路综合数据种类繁多并呈现多样化,数据对实时性的要求也不一致,如线路的运行电流值对于系统的调度影响重大,要求数据实时、一致、准确;而其他类型的数据的如状态检测类数据对实时性的要求则较低。因此,有区别地对数据进行规范化采集、管理和科学有效地处理是非常必要的。
另一方面,架空线和电缆的架设方式、结构特性、环境影响差别大,导致两者的数据类型和数据源不尽相同,如:覆冰数据、微气象、弧垂、视频监测、绝缘子泄漏电流是架空线才有的数据,而电缆护层环流、电缆敷设方式则是电缆独有的数据,因此,在数据的采集、清洗、转换和存储过程中要区别对待。数据的多源性体现为数据来源于不同的子系统。中山供电局的输电线路管理水平走在全国的前列,目前,在输电管理所装有电缆环流在线检测系统、电缆可视化子系统、绝缘子泄露电流在线检测系统、架空线路视频检测系统、输电线路智能故障诊断系统、塔基滑坡灾害监测系统、线路弧垂在线监测系统、生产管理信息系统等等,各类型的数据大部分来源于以上各系统。小部分数据如线路的属性信息是来自生产厂家,线路运行电流值则来自EMS系统。笔者以中山供电局为例,给出了输电线路综合数据的详细数据信息,如表1所示。

表1 输电线路综合数据(以中山供电局为例)Table 1 Comprehensive data of transmission lines(A case of Zhongshan power supply bureau)
2.2 输电线路数据的异构性和规模性
输电线路数据的异构性是建立在其复杂性和多源性的基础之上。复杂性和多源性一定程度上决定了数据内在结构的不同,这些复杂的、多源的数据可以进一步细分为结构化数据和非结构化数据。输电线路综合数据中结构化数据与非结构化数据的构成与划分如图1所示。结构化数据是指存储在关系数据库中的数据,输电线路综合数据中的大部分数据是这种形式,如:微气象、弧垂、绝缘子泄漏电流、电缆护层环流等,随着信息技术的发展和智能电网建设的逐步推进,测量采集装置的增多以及采样频率的提高,这部分数据将会很快地增长。
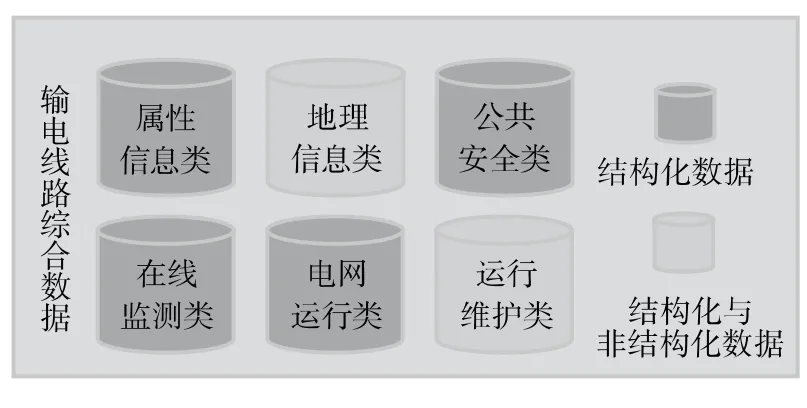
图1 输电线路综合数据Figure 1 Comprehensive data of transmission lines
相对于结构化数据而言,不方便用数据库二维逻辑表来存储和展示的数据即称为非结构化数据。这部分数据增长非常迅速,互联网数据中心的一项调查报告指出:企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%[11]。在输电线路综合数据中,电缆可视化子系统中的图片图像数据、架空线路视频监测的视频图像数据都是属于非结构化数据。目前,大多数的电缆可视化系统均为“静态”系统,在敷设电缆时,对电缆的名称、敷设类型(电缆槽、电缆沟、埋管、顶管)、与该段电缆相连的标识球编号等静态数据进行记录并存储,只在显示时进行调用。在电缆可视化系统中重要的是标识球位置图,在敷设和更新时对标识球位置现场的环境拍摄图片,当电缆发生故障需要维护检修时,就要借助电缆可视化系统中的标识球位置图帮助检修人员快速、准确地找到电缆实际的位置。
现在较为常用的架空线视频监控方法是通过终端摄像头采集图像并编码后经MESH无线网络将数据接入供电企业的电力光纤通信网络,通过TCP/IP协议将数据传输到线路监测中心[14]。以中山供电局架空线路视频监测为例,说明该部分非结构化数据的规模和体量问题。中山局供电局输电管理所现下辖38个视频监测点,这些监测点安装在比较重要的和易受外力破坏的杆塔上,若摄像机采用8路、512Kbps定码率录像,每天采集视频图像12h,则每小时产生的数据量为512×3600/8/1024=225MB,每年所有的摄像头采集到的数据量为38×365×12×225MB=36 571.29GB=35.71TB,数据体量巨大,具有电网大数据中规模大(Volume)的特点,并且随着监测点的增多,数据量会越来越大。
3 现有关系数据库的不足
现有的关系数据库已经无法满足大数据的存储需求,表现在以下4个方面:
1)大数据的数据体量为TB或PB级,关系数据库已无法处理;
2)数据访问时输入输出耗时,数据响应速度受到关系数据库的制约,导致大数据快速访问能力较低;
3)针对视频图像、图片、文档等非结构化数据缺乏处理能力;
4)对海量数据处理的可扩展性差。
4 存储方案设计
4.1 Hadoop
Hadoop文件系统[15-17]即HDFS(Hadoop Distributed File System),与现有的分布式文件系统有很多共同点。但HDFS与其他分布式文件系统也有明显的区别,其具有高容错性、可部署在低成本硬件上的特点,并且能够提供高吞吐量的数据访问,适合于大规模数据集(large data set)的应用程序。HDFS放宽了对一部分POSIX的约束,可以实现流的形式访问文件系统中的数据,并具有高可靠性、经济性、有效性、高可扩展性以及负载均衡等能力。
HDFS的结构体系如图2所示,在该体系中名称节点(NameNode)上存有控制数据节点(DataNode)信息的元数据。客户端Client可以通过NameNode对元数据进行操作,也可以直接对DataNode进行读和写操作。HDFS是一种主从结构,通常一个HDFS集群由一个名称节点(NameNode)和多个数据节点(DataNode)组成,NameNode主要负责管理包括名字空间、文件到文件块的映射、文件块到数据节点的映射三部分元数据信息,管理文件系统的命名空间,任何对文件系统元数据产生修改的操作NameNode都会记录下来存储在EditLog中。此外NameNode负责监听客户端事件和DataNode事件。DataNode的主要功能是对数据块的读写,向NameNode报告状态以便NameNode获取到工作集群中DataNode节点状态的全局视图,从而掌握其状态。

图2 HDFS结构体系Figure 2 The HDFS architecture
4.2 HBase
HBase[18]是一个面向列的分布式数据库,介于“NoSQL”和“RDBMS”之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务,主要用来存储非结构化和半结构化的松散数据。由于HBase不具有关系数据库的列、辅助索引、高级查询语言等特征,严格意义上讲HBase只能称为一种数据存储的方式而并不是数据库,其设计目标是用来解决关系型数据库在处理海量数据时的理论和实现上的局限性。传统关系型数据库设计时以数据一致性为目标,但是在扩展性、可靠性方面极度欠缺。而HBase从一开始就是为海量数据(TB或PB级别)的存储和高速读写而设计,这些数据要求能够被大量并发用户高速访问,同时分布在数千台普通服务器上。
4.3 方案的提出
针对输电线路综合数据的复杂性、多源异构性以及体量巨大等特点,笔者提出基于Hadoop平台和HBase数据库的输电线路综合数据的存储方案[18-21]。由于HBase底层数据都是以Bytes数组来存储,对于非结构化的对象可以较为容易的转化为Bytes数组存入HBase数据库。而对于结构化的数据也可通过转化为Bytes数组进行存储。输电线路综合数据的具体存储流程如图3所示。

图3 输电线路综合数据存储流程Figure 3 Storage flow chart of transmission lines comprehensive data

图4 基于Hadoop和HBase的存储方案架构Figure 4 The architecture of storage solution based on Hadoop and HBase
基于Hadoop和HBase的输电线路综合数据存储方案架构如图4所示。Zookeeper作为集群协调工具,在其中存储了-ROOT-表的地址和Master的地址,RegionServer也会注册到Zookeeper中,使得Master可随时感知到各RegionServer的健康状态。Client包含着访问HBase的接口并且维护着一些cache来加快对HBase的访问,如Region的位置信息等。Master负责region server的负载均衡,为Region server分配region;并且能够发现失效的region server并重新分配其上的region。Region server维护Master分配给它的region,处理对这些region的I/O请求,负责切分在运行过程中变得过大的region。
作为HBase的存储核心部分,Store由内存存储区域(MemSotre)和存储在HDFS上的StoreFile两部分组成。MemStore是排序内存缓冲区(Sorted Memory Buffer),数据在存入HBase时先存入MemStore,当MemStore数据满了以后会形成一个StoreFile,而StoreFile文件数量增长到一定阈值会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除。
随着数据的存入,会逐渐形成越来越大的StoreFile,当单个StoreFile文件的大小超过某一阈值后,会触发分裂(Split)操作[15],同时把当前Region分裂为2个Region,父Region会下线,新形成的2个子Region会被Master分配到相应的RegionServer上,使得原有1个Region的压力得以分流到2个Region上。某一StoreFile的分裂过程如图5所示。

图5 StoreFile的分裂过程Figure 5 Division process of StoreFile
在每一个RegionServer中都有一个实现预写日志(WAL)的对象HLog,在数据存入MemStore的同时会写一份数据到HLog中,HLog文件会定期删除已持久化到StoreFile中的数据对应的旧文件并滚动出新的文件。当RegionServer意外终止后,Master则通过HLog完成不同Region的Log数据的拆分、重新分配,最终完成数据的恢复。
HDFS适用于大文件的存储但并不是一个通用的文件系统,不能够提供文件单条记录的快速查询。而HBase建立在HDFS之上并且能够提供对大数据表的快速查询。HBase将数据存储在分布式文件系统HDFS的索引StoreFiles上,以便高速查询。
实际的数据文件存储是通过HFile类来实现的,主要是为了高效存储HBase数据,模仿了Google的Bigtable架构中使用的SSTable格式,每个Family的数据存储在同一个HFile之中,HFile的格式如图6所示,Trailer包含了指向File Info、Data Index和Meta Index的指针,被写入到文件的末尾。Data Index和Meta Index分别记录了Data和Meta块的偏移。

图6 HFile结构组成Figure 6 The HFile structures
5 结语
在电网的实际运行中会产生大量的与输电线路有关的综合数据,这些数据体量巨大、种类繁多、来源多元,存在结构化和非结构化数据,并且增长快速。现有的关系数据库对体量相对较小的结构化数据能够提供快速有效的存储、查询服务,但对于体量巨大的结构化数据及非结构化数据处理能力不足。针对大规模数据HDFS具有高容错性和高吞吐量的特点,而HBase可以提供大数据量结构化和非结构化数据高速存储操作,笔者提出基于Hadoop和HBase的大数据存储方案,适合于输电线路综合数据的存储,并且给出了存储方案具体的系统架构及存储原理。将结构化数据和非结构化均转化为Bytes数组存入建立在Hadoop之上的HBase数据库,有效地解决了非结构化数据难以存储的问题,结构灵活、可扩展性强,有利于数据信息的存储共享。
[1]张文亮,刘壮志,王明俊,等.智能电网的研究进展及发展趋势[J].电网技术,2009,33(13):1-11.ZHANG Wen-liang,LIU Zhuang-zhi,WANG Ming-jun,et al.Research status and development trend of smart grid[J].Power System Technology,2009,33(13):1-11.
[2]李振元,李宝聚,王泽一.大数据技术对我国电网未来发展的影响研究[J].吉林电力,2014,42(1):10-13.LI Zhen-yuan,LI Bao-ju,WANG Ze-yi.Research on influence of big data technology for the future development of the power grid[J].Jilin Electric Power,2014,42(1):10-13.
[3]闫龙川,李雅西,李斌臣,等.电力大数据面临的机遇与挑战[J].电力信息化,2013,11(4):1-4.YAN Long-chuan,LI Ya-xi,LI Bin-chen,et al.Opportunity and challenge of big data for the power industry[J].Electric Power Information Technology,2013,11(4):1-4.
[4]曹孝元,胡威,陈亮,等.建设大数据时代的透明电力通信网[J].电力信息化,2012,10(10):105-108.CAO Xiao-yuan,HU Wei,CHEN Liang,et al.Construction of transparent power communication networks in the age of big data[J].Electric Power Information Technology,2012,10(10):105-108.
[5]王珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011,34(10):1741-1752.WANG Shan,WANG Hui-Ju,QIN Xiong-Pai,et al.Architecting big data:challenges,studies and forecasts[J].Chinese Journal of Computers,2011,34(10):1741-1752.
[6]孙柏林.“大数据”技术及其在电力行业中的应用[J].电气时代,2013(8):18-23.SUN Bo-lin."Big data"technology and its application in the power industry applications[J].Electric Age,2013(8):18-23.
[7]McKinsey Global Institute.Big data:the next frontier for innovation,competition,and productivity[M].[s.l.]:McKinsey Global Institute,2011.
[8]中国电机工程学会信息化专委会.中国电力大数据发展白皮书[M].北京:中国电力出版社,2013.
[9]Apache.Apache Hadoop core[EB/OL].http://hadoop.apache.org/core/,2014—04—25.
[10]Apache.Apache HBase core[EB/OL].http://HBase.apache.org/core/,2014—04—25.
[11]宋亚奇,周国亮,朱永利.智能电网大数据处理技术与挑战[J].电网技术,2013,37(4):927-935.SONG Ya-qi,ZHOU Guo-liang,ZHU Yong-li.Present status and challenges of big data processing in smart grid[J].Power System Technology,2013,37(4):927-935.
[12]刘树仁,宋亚奇,朱永利,等.基于Hadoop的智能电网状态监测数据存储研究[J].计算机科学,2013,40(1):81-84.LIU Shu-ren,SONG Ya-qi,ZHU Yong-li,et al.Research on data storage for smart grid condition monitoring using Hadoop[J].Computer Science,2013,40(1):81-84.
[13]宋亚奇,刘树仁,朱永利,等.电力设备状态高速采样数据的云储存技术方案[J].电力自动化设备,2013,33(10):150-156.SONG Ya-qi,LIU Shu-ren,ZHU Yong-li,et al.Cloud storage of power equipment state data sampled with high speed[J].Power System Technology,2013,33(10):150-156.
[14]周伟才,谭卫成.高压架空输电线路视频在线监测系统研究[J].广东电力,2011,24(7):41-44.ZHOU Wei-cai,TAN Wei-cheng.Research on on-line video surveillance system of overhead HV transmission lines[J].Guangdong Electric Power,2011,24(7):41-44.
[15]杨锋,吴华瑞,朱华吉,等.基于Hadoop的海量农业数据资源管理平台[J].计算机工程,2011,37(12):242-244.YANG Feng,WU Hua-rui,ZHU Hua-ji,et al.Massive agricultural data resource management platform based on Hadoop[J].Computer Engineering,2011,37(12):242-244.
[16]朱珠.基于Hadoop的海量数据处理模型研究和应用[D].北京:北京邮电大学,2010.
[17]黄晓云.基于HDFS的云存储服务系统研究[D].大连:大连海事大学,2013.
[18]康毅.HBase大对象存储方案的设计与实现[D].南京:南京大学,2013.
[19]韩晶.大数据服务若干关键技术研究[D].北京:北京邮电大学,2013.
[20]王德文.基于云计算的电力数据中心基础架构及其关键技术[J].电力系统自动化,2012,36(11):67-72.WANG De-wen.Basic framework and key technology for new generation of data center in electric power corporation based on cloud computation[J].Automation of Electric Power Systems,2012,36(11):67-72.
[21]王德文,宋亚奇,朱永利.基于云计算的智能电网信息平台[J].电力系统自动化,2010,34(22):7-12.WANG De-wen,SONG Ya-qi,ZHU Yong-li.Information platform of smart grid based on cloud computing[J].Automation of Electric Power Systems,2010,34(22):7-12.
猜你喜欢
数学大王·趣味逻辑(2021年11期)2021-12-03
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
趣味(数学)(2019年12期)2019-04-13
中国科技信息(2016年6期)2016-08-31
河南电力(2016年5期)2016-02-06
中国科技信息(2015年23期)2015-11-07
河南电力(2015年5期)2015-06-08
