
面向服务的数据集成技术研究*
2014-01-16 15:56
舰船电子工程 2014年4期
(中国电子科技集团公司第二十八研究所 南京 210007)
1 引言
军事信息化在未来网络化和服务化体系结构下,数据集成将面临分布式异构、海量数据资源共享等诸多挑战。数据的网络化部署,不断扩展和变化,一般通过服务发布和共享;随着网络的建设和数字化发展,数据的规模越来越庞大;数据类型更为广泛,包括半结构/非结构化文档、流媒体、各类专用格式报文等。传统的数据集中(实体化方法)或逻辑(虚拟化方法)上集中存储的方法不再可行,而如何利用各类新技术如大规模分布是数据挖掘、流式数据处理等,来解决网络化的异构数据库的数据、网络化的非结构化数据信息集成问题,为网络化服务化的各类信息系统提供数据和信息支撑。
2 服务化架构数据集成框架
为实现网络化数据的集成,从数据和网络化技术两个层面相关技术来实现。在数据层面主要通过元数据技术提高信息的可见性;应用层面主要通过信息目录技术对各类资源进行整合、通过信息搜索技术进行搜索和发现、通过信息聚合及挖掘技术实现信息的二次开发和利用。
基于相关技术和原理提出网络化基于发现元数据的数据集成框架,见图1。主要分为两层:数据及模型支撑层,数据集成服务支撑层。
在数据及模型支撑层,最底层为将进行网络化共享的原始数据,包括各类多媒体数据、结构化数据、非结构化数据等;在其之上,存储对结构化数据进行描述的结构元数据,对结构化数据、半结构化/非结构化数据、流媒体等多媒体数据等进行统一的描述发现元数据;以及支撑数据集成服务的各类数据,包括支持信息目录的目录库,支持信息搜素的索引文件和词库,支持信息聚合的聚合库和挖掘库;在模型方面主要是基于Lucene的搜索引擎模型和Weka模型库。
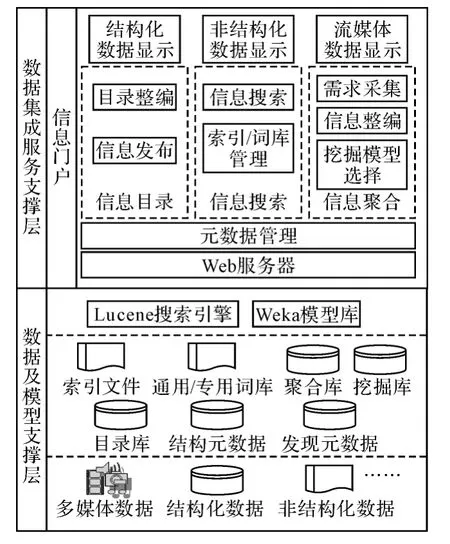
图1 基于发现元数据的数据集成框架图
数据集成服务支撑层主要建立在Web服务体制上,统一通过信息门户作为用户操作的入口;应用软件主要分为面向直接使用的用户的应用和面向信息管理的应用;面向信息管理的应用主要包括信息目录的目录整编和目录发布,对元数据的管理,对各类结构化和非结构化数据的信息搜索及索引/词库的管理,对信息聚合的需求采集、信息整编及数据挖掘的确定等。
3 关键技术原理及方法
3.1 发现元数据技术
信息发现元数据和领域结构元数据是元数据的主要组成,其中信息发现元数据着眼于资源基本属性的描述,其目的是提高资源的可见性,增强信息的能力,而具体领域内的结构元数据是针对不同业务的数据命名、数据类型、数据结构和数据间基本关系的规范性描述,为数据的重用提供结构信息的参考[1]。
发现元数据是目前网络上广泛采用的用于描述信息的技术方法,提高信息资源网络发现能力和可见性,相关领域的标准较多,较为著名的包括用于网络化图书资源的都柏林核心元数据标准和美国国防部的发现元数据标准DDMS(Dod Discovery Metadata Standard)等。
都柏林核心元数据(Dublin Core Metadata)(简写DC),1995年3月,由OCLC与国家超级计算应用照哦功能性(NCSA)联合发起,52位来自图书馆界、电脑网络界专家公同研究产生。目的是希望建立一套描述网络电子文献的方法,以便网上信息检索。DC的15项著录项目[2]包括:Title(题名)、Creator(创建者)、Subject(主题)、Description(说明)、Publisher(出版者)、Contributor(其他责任者)、Date(制作日期)、Type(类型)、Format(格式)、Identifier(标识符)、Source(来源)、Language(语种)、Relation(关联)、Coverage(覆盖范围)、Rights(权限)。
元数据在军事领域也得到了应用,是军事信息共享和发现的基础,其中发现元数据成为元数据建设的重要内容,美军的国防部发现元数据标准DDMS(Dod Discovery Metadata Standard)就是旨在提高数据的可见性,使得用户能够更方便的获得所需的信息,有效的实现数据的共享。美军2011年DDMS(《Department of Defense Discovery Metadata Specification(DDMS)Version 4.0.1》)[3]主要定义了核心层和扩展层,如图2所示。
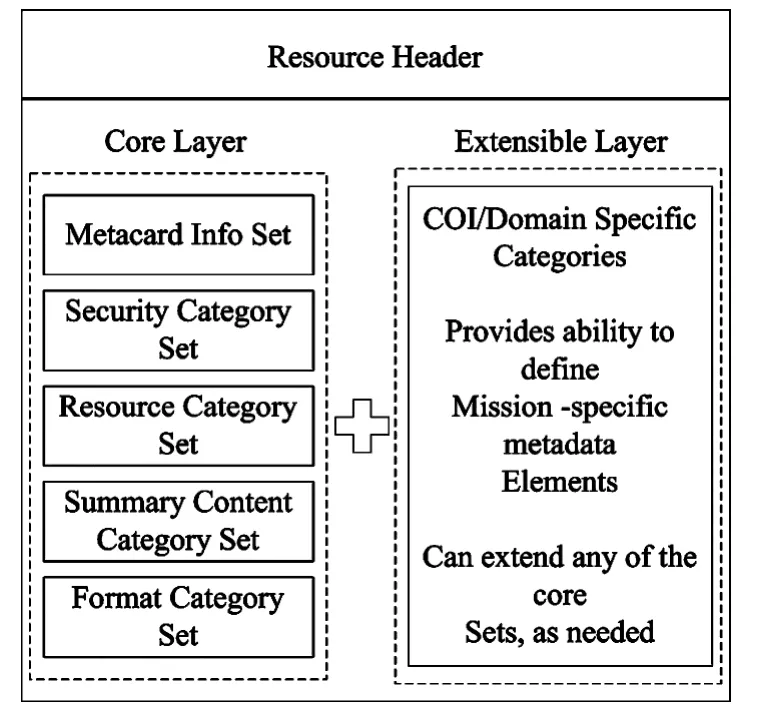
图2 DDMS的逻辑模型
建设信息发现元数据标准将为军事信息的一体化奠定基础,对提高信息共享水平和信息发现能力具有重要的意义。
3.2 信息目录技术
信息目录是网络化信息登记、造册、发布、发现、定位、实现交换的关键组成[4]。发现元数据用于一般性资源描述,特别是互联网语义信息的描述。通过信息目录可进一步对信息进行整理,提高信息的可用性和友好性。
其实现步骤包括两步:元数据目录部分负责将访问数据的请求映射为访问数据载体的请求,实现第一次映射的功能;资源信息目录负责将访问数据载体的请求映射到具体的数据载体上,实现第二次映射的功能。
在技术实现方案,主要包括信息目录的集中存储或分布存储;分布存储涉及信息目录信息的同步策略及相关技术;存储方式包括数据库存储或基于LDAP的技术实现。
3.3 信息检索技术
通常,信息检索需要具备建立索引和提供查询的基本功能[5],此外还需提供用户接口、面向互联网的开发接口、二次应用开发接口等。因此,信息检索系统应包括索引引擎、查询引擎、文本分析引擎、对外接口以及各种外围应用系统。图3展示了信息检索系统的基本功能结构[6]。
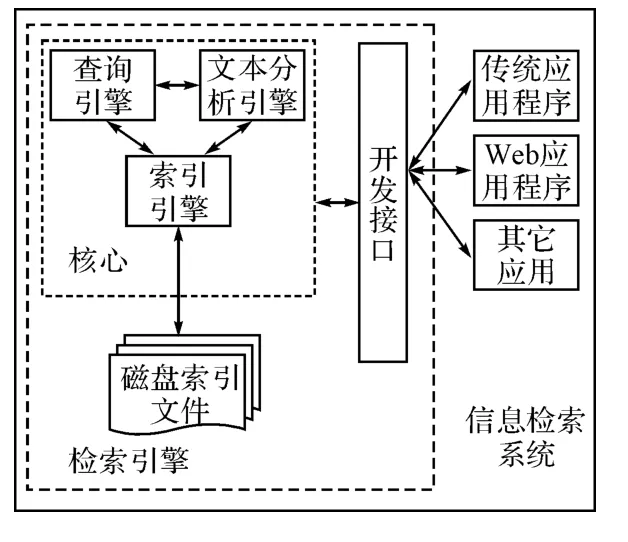
图3 信息检索系统基本功能结构图
信息检索系统比较常用的检索引擎是基于Lucene的搜索引擎模型。它能够为任何可以转换成文本格式的数据进行索引和搜索,具有访问索引时间快,多用户访问,跨平台使用的特点[5]。
对于中文系统来说,文本分析引擎最关键的技术之一是中文分词法。中文分词算法可分为三类:基于字符串匹配的分词法、基于理解的分词法和基于统计的分词法。目前,基于字符串匹配的正向最大匹配算法是最常使用的中文分词方法,它由词典和切分规则构成,遵循“长词优先”的原则,即从左向右与词典匹配,要求每一句分词结果中词汇量最少。比如,“中”是一个词,其还可以构成“中国”、“中国人”等一系列词,当需要分词的语句中出现“中国人”时,正向最大匹配的分词结果为“中国人”,而不是“中国”和“人”等其它结果。
3.4 信息聚合技术
信息聚合,指将来自于多个分布的、异构的信息资源中的内容整合在一起。信息聚合技术有面向万维网,有面向语义网(基于关联数据Mashup)[7]。
面向万维网的信息聚合就是通过客户端软件或网络应用程序将诸如新闻头条、博客、播客等网络信息聚合到单一地点以方便用户浏览[8]。目前基于RSS的信息聚合服务,发展为社会化聚合服务,如Twitter Feed,Facebook等。其有效解决了网络信息资源的有序组织、有效传播,是用户、技术和服务三者间互动模型的建立与变化过程。
面向语义网的关联数据技术,是一种用来发布和联接各类数据、信息和知识的标准,采用RDF(资源描述框架)数据模型,利用URI命名数据实体,并在网上发布,或形成数据网络。
3.5 数据挖掘技术
完整的数据挖掘过程,是一个不断调整、修改与循环的过程,包括三大步骤:数据预处理、数据挖掘以及评估与表示,如图4所示。数据预处理步骤,依次包括数据清洗、数据集成、数据选择和数据变换四个过程。数据挖掘步骤,主要是通过一系列的数据挖掘算法,对经过处理的数据进行知识发现的过程。评估与表示步骤主要包括模式评估阶段和知识表示阶段,模式评估是指根据某种兴趣度量来识别表示知识的真正有趣的模式;知识表示是指使用可视化和知识表示技术,向用户展现挖掘的知识。三大步骤之间反复循环、调整,直到得到满意结果为止。
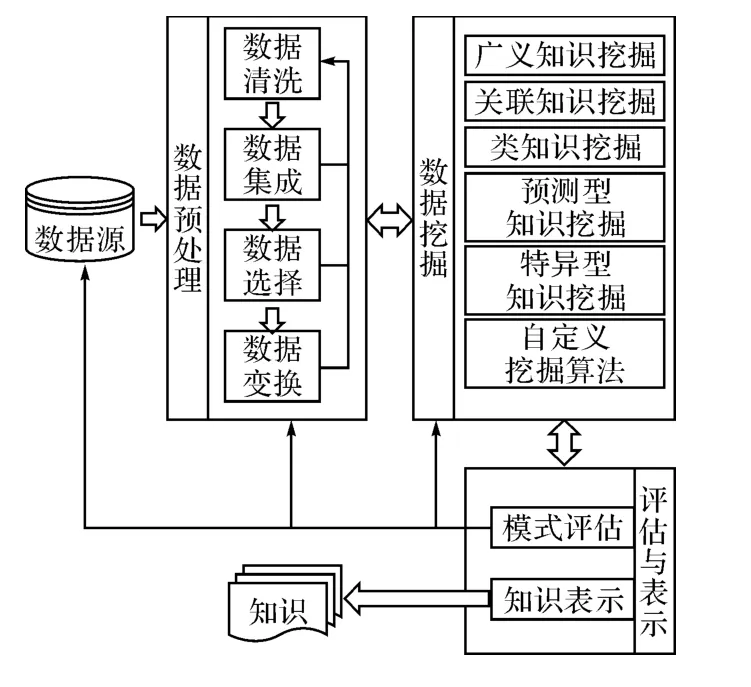
图4 数据挖掘的过程
数据挖掘方法可以分为六大类别[9]:
·广义知识挖掘:被挖掘出的广义知识可以结合可视化技术以直观的图表形式展示给用户。
·关联知识挖掘:找出数据库中隐藏的关联信息,最著名的是Agrawal提出的Apriori及其改进算法。
·类知识挖掘:主要包括分类和聚类两类。分类常用的方法有决策树、贝叶斯分类、神经网络、遗传算法与进化理论、支持向量机、关联分类、类比学习(近邻学习)、粗糙集、模糊集等。聚类算法主要分为基于划分、层次、密度、网格及模型的聚类方法五大类别。
·预测型知识挖掘:主要的方法有经典的统计方法、神经网络和机器学习等技术。
·特异型知识挖掘:揭示了事物偏离常规的异常规律。主要分为孤立点分析、序列异常分析和特异规则发现三类。
·自定义数据挖掘:用户可以通过此接口将自己编写的算法保存在平台上,供日后使用或出售等。此接口使得平台具有更强的开放性和扩展性。
其中,关联知识挖掘和类知识挖掘是较为广泛应用的方法。关联规则是数据中蕴含的一类重要规律,对关联规则进行挖掘是数据挖掘中的一项根本任务,甚至可以说是数据库和数据挖掘领域中所发明并被广泛研究的最为重要的模型。简言之,关联规则挖掘是发现大量数据中项集之间的关系或相关联系[10]。聚类分析就是按照某种相似性度量,具有相似特征的样本归为一类,使得类内差异相似度较小,而类间差异较大[11]。迄今为止。聚类还没有一个学术界公认的定义,其主要方法包括:基于划分的聚类方法、基于层次的聚类方法、基于网格的聚类方法、基于密度的聚类方法、基于模型的聚类方法等。
数据挖掘常用方法的开源产品较多,Weka是其中较为优秀的产品。它是由新西兰怀卡托大学开发的开源项目,具有以下特点:跨平台、支持结构化文本、支持数据挖掘格式的文件、提供数据库接口;能完成预处理、分类、聚类、关联、可视化等任务;提供算法组合、用户算法嵌入、算法参数设置;能生成基本报告,实现模型解释;实现数据、挖掘过程、挖掘结果的可视化[12]。
4 结语
传统的基于实体化(数据仓库等)和虚拟化(全局视图等)的数据集成方法越来越不能满足未来网络化的海量异构,特别是用户对大量非结构化、流媒体数据的需求,本文结合各类服务化新技术,提出网络化数据集成框架和相关关键技术,对适应未来不断发展的服务化架构网络化的大数据支持进行有意的探讨。
[1]伯琼,赵小燕,等.自动抓取元数据标签中DC元数据的模块设计[J].重庆教育学院学报,2010,23(3):9-13.
[2]徐险峰.网络信息资源的Dublin Core元数据编目[J].农业图书情报学刊,2009,21(2):52-54.
[3][美]Defense Information Systems Agency.Department of Defense Discovery Metadata Specification(DDMS)Version 4.0.1[M].2011,11:18-21.
[4]陈明文,朱勤东,等.省级政府信息目录编制实践与探索[J].电子政务,2010(1):104-110.
[5]刘静.浅析Lucene的查询技术[J].电脑知识与技术,2012,11(8):24-25.
[6]葛振国.基于Lucene的数据库全文检索研究与应用[D].成都:西南石油大学硕士学位论文,2010:4-8.
[7]丁楠,潘有能.基于关联数据的图书馆信息聚合研究[J].图书与情报,2011(6):50-53.
[8]邓胜利.信息聚合服务的发展和演变研究[J].情报资料工作,2012(1):79-83.
[9]黄章树,刘晴晴.基于云计算服务模式的数据挖掘应用平台的构建[J].电信科学,2012:53-57.
[10]欧阳林,谭骏珊,等.经典关联算法分析和Weka数据挖掘应用[J].探索与观察,2012(5):8-10.
[11]周涛,陆惠玲.数据挖掘中聚类算法研究进展[J].计算机工程与应用,2012,48(12):100-111.
[12]郑世明,苗壮,等.Weka环境下基于模糊理论的聚类算法[J].解放军理工大学学报(自然科学版),2012(1):22-26.
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
理财·市场版(2022年5期)2022-05-30
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
军事运筹与系统工程(2017年4期)2017-08-29
电子技术与软件工程(2016年24期)2017-02-23
