
基于子空间映射和得分规整的GSV-SVM方言识别
2013-11-30 05:01李弼程
计算机工程与设计 2013年1期
王 烨,屈 丹,李弼程,刘 崧
(1.信息工程大学 信息工程学院,河南 郑州450002;2.杭州恒生数字有限公司,浙江 杭州310000)
0 引 言
语种识别方法:基于并行音素识别器与语言模型和统计模型两种方法[1]。基于并行音素识别器的方法是将用于区分不同语种的典型音素经过标注后训练建模,这些音素的排列方式体现该语种的结构。该方法的缺点是需要专业的语言学知识建立音素集合,并且大量的语料需要人工标注。基于统计模型的方法是根据参数向量空间的概率统计分布构建不同语言的模型,不需要语言学知识,实验语料也无需标注。由于该方法良好的移植性,使其得到了广泛的应用。基于统计模型的方法主要有高斯混合模型-全局背景模型(Gaussian mixture model-universal background model,GMM-UBM)[2],支持向量机(support vector machine,SVM)[3]和高斯超矢量支持向量机(GMM-Supervector SVM,GSV-SVM)[4]3种。其中GSV-SVM 方法结合GMM较好的鲁棒性和SVM优越的区分性,比单独使用GMM或SVM取得了更好的识别效果,应用最为广泛,而且成为NIST评测的主要方法。
本文设计了一套完整的基于GSV-SVM的方言识别系统。主要针对普通话、青海方言和藏语中的安多方言进行识别。由于汉语和藏语同属汉藏语系,且青海方言与普通话的差异更小,因此对于这3种方言的区分难度相比于不同语系语言的区分难度要大得多。为提高系统的识别能力,又增加子空间映射和得分规整。实验结果表明,采用本文设计的系统,对各种方言的识别率均能达到90%以上。
1 GSV-SVM语种识别系统
产生式模型GMM是通过大量的训练数据以及较高的模型混元数对语种的统计特征分布进行较好的描述,因而具有较好的鲁棒性。区分式模型SVM的优势在于其优越的分类能力,但是SVM的鲁棒性较差,在有噪声的情况下,系统性能下降很快。GSV-SVM模型结合GMM和SVM的优点,是当前语种识别的主流模型。本文描述的语种识别系统如图1所示。该系统分为训练和测试两部分。训练部分,首先对语音文件提取声学特征,通过训练特征文件得到语种无关的全局背景模型UBM,再利用最大后验概率(maximum a posteriori,MAP)准则自适应得到GSV,然后在超矢量空间进行低维映射,然后训练多组识别分类器;在训练阶段,对开发数据的多组分类器生成的分数域进行LDA变换,并训练得分规整模型;测试部分,对待测的语音文件采用相同的步骤得到GSV,再通过多分类器进行识别,然后进行分数域的映射最终输出识别结果。
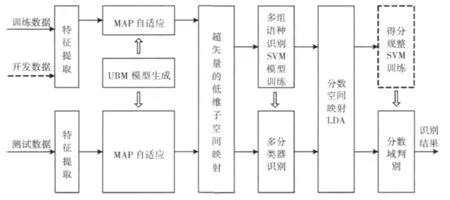
图1 GSV-SVM语种识别系统处理流程
1.1 特征提取
特征提取是对语音信号进行变换,尽量去除冗余信息,保留能够较好区分不同语种的特征,并对噪声和信道有很好的鲁棒性。本文的特征提取流程如图2所示。首先对语音文件提取梅尔频率倒谱系数(mel frequency cepstrum coefficient,MFCC)[5],考虑语言的长时特性对于语种识别更为重要,对MFCC再进行移位差分倒谱(shifted delta cepstrum,SDC)扩展[6],最后对特征参数进行鲁棒性处理——倒谱均值减(cepstrum mean subtraction,CMS)[7]和高斯化[8]。

图2 特征处理过程
MFCC是将频谱转化为基于Mel频标的非线性频域。由于考虑了人耳对低频敏感而对高频不敏感的非线性特性,MFCC取得了较好的识别效果。
SDC参数是在原有MFCC特征参数基础上衍生出来的,用一组四维参数表示(N,d,P,K)。N表示倒谱参数的维数,d表示差分时移,P表示差分倒谱块的转移量,K表示倒谱块的个数。若MFCC为7维,图3为一维MFCC对应的SDC参数,参数的取值为(7,1,3,7)。
CMS是一种广泛应用于语种识别的去信道卷积噪声的方法。将语音信号由于调制带来的噪声,通过变换将时域上相卷积的噪声变换到倒谱域上相加的关系,在倒谱域上将调制噪声减去。
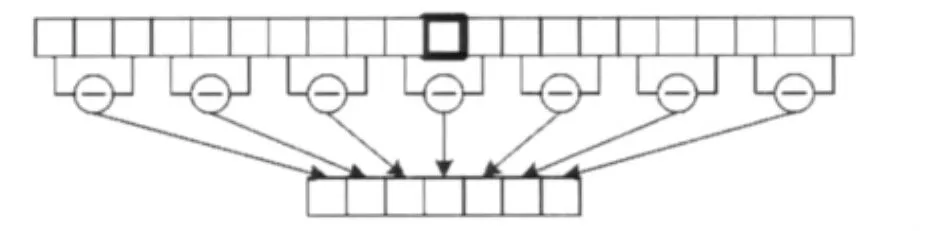
图3 一维MFCC对应的SDC参数
高斯化是一种特征参数的规整方法。语种识别中使用的特征参数是随机矢量,其概率分布往往受到实际环境的影响,高斯化就是对特征参数进行规整,使其即使受到环境影响也能近似相同分布,将特征参数都变换到事先给定的标准高斯分布上。
1.2 GSV-SVM 模型
1.2.1 GSV的生成
全局背景模型(UBM)是通过训练大量数据得到的一个语种无关的高斯混合模型。训练数据的选择要覆盖各种信道情况、不同质量的话音和不同语言。GMM可表示为
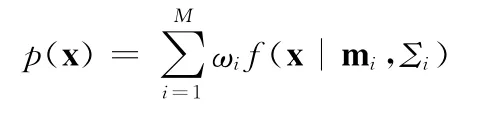
式中:x——F维的特征矢量,M——高斯混合数,mi,Σi,ωi——第i个混元的均值、协方差、权重。f(·)——F维高斯分布,即
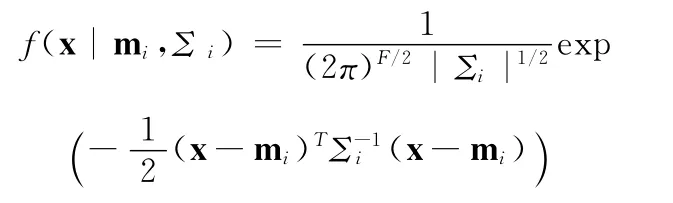
对于任意一段语音,从UBM中通过MAP自适应准则得到表征该语音段的GMM
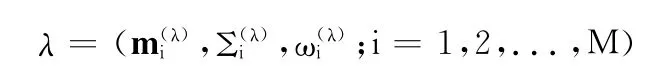
然后将每个高斯混元的均值矢量(或还包括协方差矢量、权重)按顺序拼接成一个超矢量输入SVM训练和测试,GSV的产生过程如图4所示。
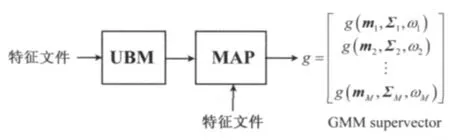
图4 GMM超矢量产生过程
1.2.2 GSV子空间映射
在超矢量的运算过程中,由于数据之间不可避免的存在相关、冗余和噪声等多方面的影响,造成超矢量维数巨大,必然造成判决结果的不准确且计算量庞大,因此如何学习超矢量的低维子空间结构是一个值得考虑的问题。研究发现,一段语音信号由于长度有限,超矢量中只有少数的中心对此有区分性。因此可以采用主分量分析(principal component analysis,PCA)方法进行映射,即通过特征变换寻找并保留数据中最有效、最重要的成分,舍去一些冗余的、包含信息量较少的成分,实质是一个降维的过程。这里主要采用奇异值分解的方法获得映射矩阵。即将原始数据的N维矢量x映射为M维矢量c(M<N),尽可能地保存x包含的信息。既可以有效的减少运算量,又可以提高判决的精度。
1.2.3 基于KL核的多组语种识别支持向量机模型
支持向量机(SVM)是一种当今较常用的机器学习方法,SVM的判决函数可表示为
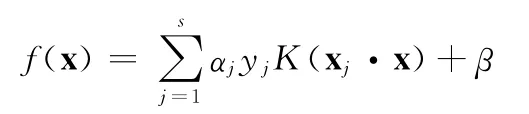
其中,yj取值+1或-1,分别代表目标语种或非目标语种,xj为第j个支持向量,αj为该支持向量对应的权重,x为测试语音段生成的超矢量,β是与测试语音段无关的偏移参数。
核函数的选取使用Campbell等[9]提出的KL核,该核函数的提出是从采用KL距离来衡量两个GMM模型出发,后来引入超矢量这一概念,并将其作为SVM的核函数。
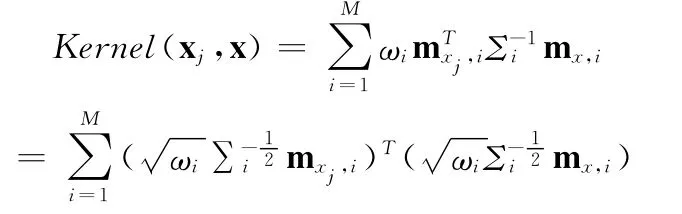
式中:x——F维的特征矢量,M——高斯混合数,mxi——xi第i个混元的均值,Σi、ωi——UBM第i个混元的协方差、权重。
由于KL核是一个线性核函数,SVM的判决函数可以表示为
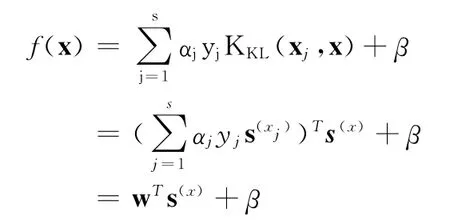
采用KL核函数映射后,多组语种识别SVM模型训练流程如图5所示,假设对N种语言进行识别,每两种语言要计算得分模型,即C2N个二分类模型,且对于任意一种语言要计算该语言与非该语言的得分模型,即N个得分模型。因此N个语种计算得分归一化需要计算个得分模型。
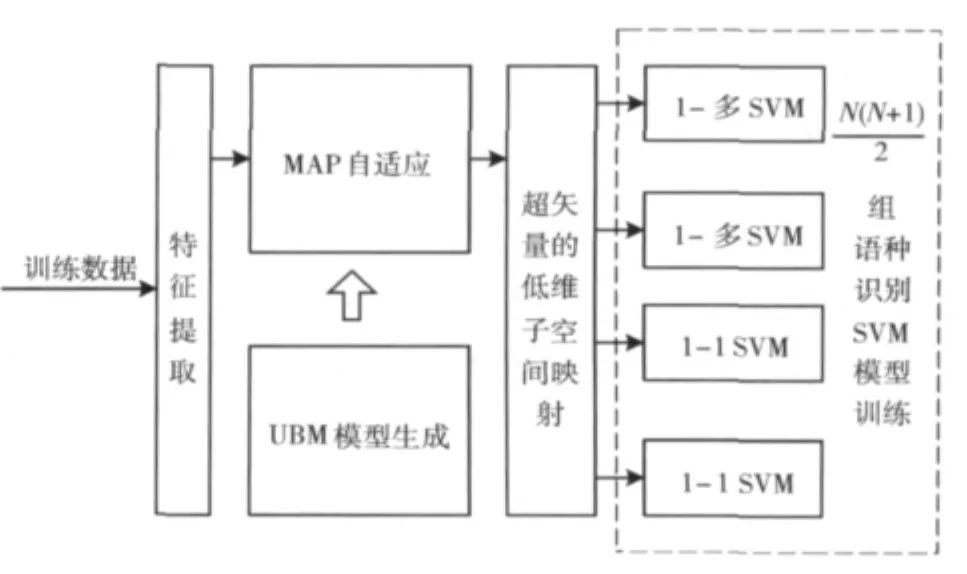
图5 多组语种识别SVM模型训练流程
1.3 得分规整模型
在识别时,由于模型之间的得分相关,不同语句对于不同模型的得分波动不同,得分模型的分布也不一致,导致整体识别结果的不可靠,因此需要建立得分规整模型进行处理[10]。由于采用了N(N+1)/2组语种识别分类器进行判别,所以对于每段语音,都可以构成一个N(N+1)/2维的得分矢量。首先,使用线性区分性分析(lineardiscriminativeanalysis,LDA)对得分矢量降维,降低相关性,然后对开发数据集不同语言种类建立SVM模型。得分模型的产生如图6所示。
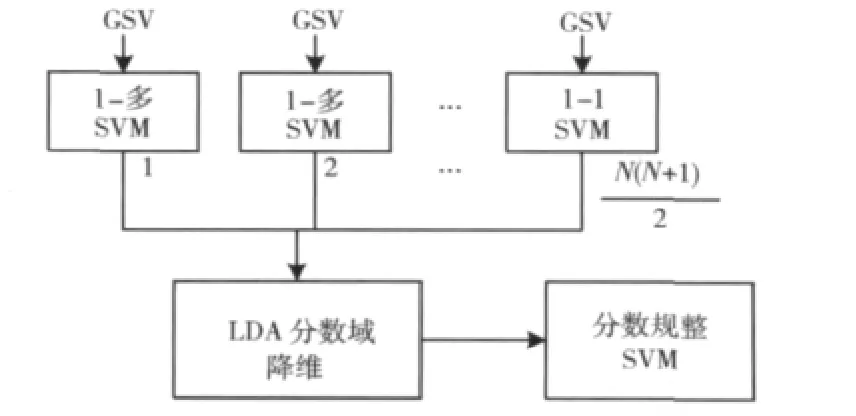
图6 得分模型
2 方言识别实验
2.1 实验语料及系统配置
2.1.1 实验语料库
本文采用的实验语料为汉语普通话、汉语青海方言、藏语安多方言的电话信道单声道语音。每种语言数据无重叠切分成30秒的语音段,其中训练集每种语言各1734段,开发集每种语言各216段,测试集汉语普通话1170段,藏语安多方言3900段,青海方言218段。使用闭集识别率作为测试评价指标。
2.1.2 系统参数配置
特征参数采用7维MFCC及其SDC扩展共形成56维特征,其中SDC的参数(N,d,P,K)为(7,1,3,7)。GMM-UBM混元数为2048,迭 代30次。PCA降 维 将114688维超矢量降至800维。SVM核函数选用KL核,得分归一化的模型为6维,经过LDA去相关降至3维。
2.2 实验结果及性能分析
2.2.1 实验1:相关系数τ对识别率的影响
通过MAP准则从UBM模型自适应得到GSV时,参数τ的取值对系统识别效果是有影响的,它描述当前GMM与UBM之间的相关程度。表1为测试相关系数τ取不同值时GSV-SVM系统的识别效果。GMM混元为2048,特征参数的维数为56,因此GSV的维数为114688。采用如此高维的参数训练SVM无论是对硬件设备的要求和计算量都是存在一定困难的。而采用PCA降维可以保留数据中最重要的成分,去除冗余部分,提高运算效率。因此后续实验均是将GSV通过PCA降维至800维的实验结果。实验结果表明,随着τ值的变化,各数据集的识别效果略有变化,训练集和开发集数据随着τ值的增加有所下降,而测试集在τ=8时取得最佳的识别效果。根据实验结果综合考虑,后续实验均采用τ=8。

表1 相关系数τ取不同值的识别率
2.2.2 实验2:SVM二分类实验
为了对后端得分规整实验做准备,对所有的SVM二分类模型进行计算。表2为6个SVM二分类模型的识别效果。实验结果表明,与藏语相关的二分类实验效果均较好,所有数据集的识别率均在90%以上,训练集的甚至达到99以上,因为藏语的安多方言是藏语主要的3种方言中唯一一种无调方言,与有调的普通话和青海方言差异较大;而汉语普通话和汉语青海方言区分度相对较小,识别率相对较低。
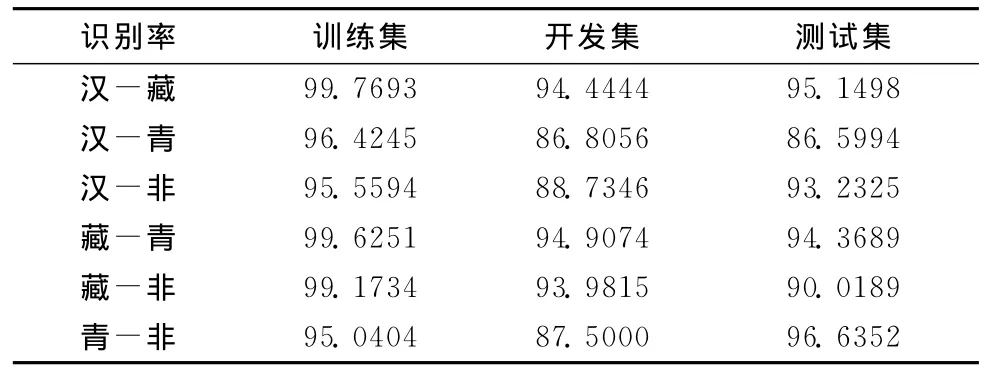
表2 SVM二分类实验
2.2.3 实验3:得分规整实验
后端得分规整是将每个语种的均值超矢量通过得分归一化模型拼接成一个得分矢量,再对得分矢量进行SVM训练。该得分归一化模型是在开发集数据上进行的。得分规整起到归一化的作用,并且在得分域上进一步增加了得分的区分性。表3为得分规整实验,实验结果表明,对GSVSVM(PCA)系统进行后端规整,训练集的识别效果略有下降,但开发集和测试集的识别率均有提高。

表3 得分规整实验
2.2.4 实验4:LDA实验
由于6维得分矢量维数较低,容易造成矢量空间的实验样本分布集中,影响SVM的分类效果。为进一步提高实验样本的区分性,增加LDA实验,使同一类的样本尽量集中,不同类的样本尽可能分开。表4为LDA实验的结果。实验结果表明,增加LDA实验对识别率均有提高。
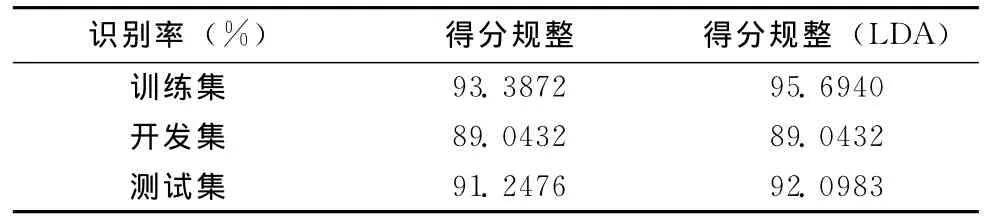
表4 LDA实验
2.2.5 实验5:3种语言的测试实验
采用本文的实验系统,对3种实验语料的测试集数据分别进行测试。表5为单独测试3种语言的测试实验。实验结果表明,单独测试3种语言的测试集,识别率均能达到90%以上。

表5 3种语言测试集测试效果
3 结束语
对于方言识别中存在的混淆度较大导致识别率较低的问题,本文针对汉语普通话、青海方言和藏语安多方言设计实现一个基于GSV-SVM的方言识别系统。在模型建立部分通过子空间映射去除冗余信息,提高不同方言之间的区分度;并在后端得分域将各模型之间的得分进行规整,减小得分的波动,提高判决的精度。实验结果表明,采用本文的系统对方言进行识别,3种方言的识别率均能达到90%以上,而藏语的识别效果最佳。
[1]Burget L,Matejka P,Schwarz P,et al.Analysis of feature extraction and channel compensation in a GMM speaker recognition system[J].IEEE Transactions on Audio,Speech,and Language Processing,2007,15(7):1979-1986.
[2]Matejka P.Phonotactic and acoustic language recognition[D].Brno:Brno University of Technology,2008.
[3]Campbell W M,Campbell J P,Reynolds D A,et al.Support vector machines for speaker and language recognition[J].Computer Speech and Language,2006,20(2-3):210-229.
[4]Campbell W M,Sturim D E,Reynolds D A.Support vector machines using GMM supervectors for speaker verification[J].IEEE Signal Processing Letters,2006,13(5):308-311.
[5]Zhang Weiqiang,He Liang,Deng Yan,et al.Time frequency cepstral features and heteroscedastic linear discriminant analysis of language recognition[J].IEEE Transactions on Acoustics,Speech and Signal Processing,2011,19(2):266-276.
[6]Torres-carrasquillo P A,Singer E,Campbell W,et al.The MITLL NIST LRE 2007Language Recognition System[C]//Brisbane,Australia:Proc of Interspeech,2008:719-722.
[7]Matejka P,Burget L,Glembek O,et al.BUT language recognition system for NIST 2007evaluations[C]//Brisbane,Australia:Proc of Interspeech,2008:739-742.
[8]FU Qiang.The study of GMM-based language identification[D]//Hefei:University of Science and Technology of China,2009(in Chinese).[付强.基于高斯混合模型的语种识别的研究[D].合肥:中国科技大学,2009]
[9]Campbell W M,Sturim D E,Reynolds D A.Support vector machines using GMM supervectors for speaker verification[J].IEEE Signal Processing Letters,2006,13(5):308-311.
[10]LEI Wenhui.Support vector machine based language recognition[D].Hefei:University of Science and Technology of China,2009(in Chinese).[雷文辉.基于支持向量机的语种识别研究[D].合肥.中国科技大学,2009.]
猜你喜欢
民族文汇(2022年24期)2022-06-09
时代邮刊(2021年8期)2021-07-21
中国化工贸易·下旬刊(2019年5期)2019-10-21
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
佛山陶瓷(2016年11期)2016-12-23
大观(2016年9期)2016-11-16
中国交通信息化(2016年2期)2016-06-06
高中生·天天向上(2009年11期)2009-12-17
