
基于模糊理论的GIS 空间数据处理应用
2013-11-25 14:00:26杜文举郭豫宾
石家庄铁路职业技术学院学报 2013年2期
杜文举 郭豫宾
(四川建筑职业技术学院 四川德阳 618000)
1 引言
GIS 是将计算机硬件、软件、地理数据以及系统管理人员组织而成的对任意形式的地理空间信息进行高效获取、存储、更新、操作、分析及显示的集成系统。地理信息系统以及其他信息系统对表达地理信息的空间数据的利用是通过地理信息处理模型来完成。在GIS 中,我们通常分别采用对象模型和场模型来描述这些自然现象。对象模型是用一组离散的点、线、面来表达空间分布,它适合用于表达具有明确定义的地理实体;而场模型则是用定义在连续空间上的单值函数来表示[1]。它一般用于表示在空间中连续分布的定义不明确或模糊的地理实体。出于简化问题的考虑,传统的GIS 在处理模糊信息时多是将其当作确定信息来处理,这种简化很大程度上推动了GIS 的发展,但随着应用的深入,其弊病也日益显露。这种简化有时会导致所获得的结果不具有完全的可靠性,甚至是错误的,最终将导致决策失误或失败[2]。而模糊集合论就是这样一种方法,它可以用在空间数据建模和数据处理中,降低数据的不准确性,从而提高数据质量,保证空间数据分析和决策的正确进行。
2 空间数据的不确定性
空间数据的不确定性属于一般不确定性的组成部分,它包含了不确定性的基本概念、原理、原则等相关的空间科学技术,包含了地球信息科学、大地测量、测绘与制图、遥感、卫星定位系统、地理信息系统、数据库及其在管理中的应用[3]。要完整地描速空间实体或现象的状态,一般需要同时有空间数据和属性数据,如果要描述空间实体或现象的变化,则需要记录空间实体或现象在某一时刻的状态。所以,一般认为空间数据具有三个基本特征:空间特征、属性特征和时间特征。从空间数据的形式表达到空间数据的生成,从空间数据的处理变换到空间数据的应用,在这两个过程中都会有数据质量问题的发生[4],下面按照空间数据自身存在的规律性来阐述空间数据质量问题的来源:
(1)空间现象自身存在的不稳定性,包括空间现象在空间,属性和时间上的不确定性;
(2)空间现象表达的不准确性或引入的误差;
(3)空间数据处理中的误差;
(4)空间数据使用中的误差。
在空间数据处理过程中容易产生的误差有以下几种:投影变换-地图数字化和扫描后的矢量化处理;数据格式转换;数据抽象;建立拓扑关系;数据叠加操作和更新等数据集成处理;数据的町视化表达;数据处理过程中误差的传递和扩散等[5]。
空间数据不确定性形成的原因是多种多样的,有的是客观世界引起的,有的是由于人为的因素造成的。把形成空间信息不确定性的原因归结为三点:
①不确定性在一定程度上代表了获得的数据与真实世界之间明显的质量差别;
②不确定性与专门需求与数据之间的兼容性与协调性有关;
③不确定性和用户专门要求与数据之间的匹配有关[6]。
3 空间数据模型的建立
空间数据的不精确性或不确定性所致的据拓扑关系的不确定性引起了国内外GIS 领域的重视,而且已有了一些零散的研究成果,多数都集中于模糊对象之间的拓扑关系上,一个模糊对象是在分布状态下连续变化的地理现象,表示边界和外部的一个形式化的定义,而地理数据的不确定性、认知的不确定性以及空间关系分析处理的不确定性等导致了空间关系不确定性。当空间数据库中的地理数据不可避免地具有模糊性必然导致空间数据处理模型的不确定性[7]。
3.1 空间数据处理模型的不确定性
由于空间数据不确定性来源的复杂性以及地理信息很难重复采样,使得空间数据不确定性既有空间位置的不确定性和空间属性数据的不确定性,传统的针对数据本身进行的不确定性研究已经很难满足现行的需要。通过对空间数据产生的不确定性进行概念建模,以及对概念模型进行分析,能有效的减弱不确定性的传播,从而提高空间数据的精度和质量。空间数据不确定性的模型由于其采用框图形式或图解形式,即概念模型来表达,能全面的反映空间数据之间的关系,对空间数据的不确定性的研究有着重要作用。
由于模型是对客观世界的一种抽象,它就不可能是现实问题的一种拷贝。因此,在空间数据处理模型中必然存在有不确定性。模型只能是接近事实,在其所表达的情况和地理现实之间存在有差距,总体来讲,模型不确定性可以表示为:
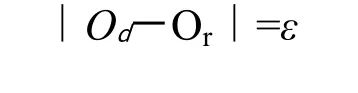
其中,Qd是期望的结果;Or是真实的输出结果;ε是两者之间的误差。为了减少误差,可以通过提高模型的设计水平。利用两种方法来进行模型的不确定性处理:即模型不确定性减少和模型不确定性吸收。模型减少是指减少和模型不确定性相关的所有因素的不确定性,或者提高这些因素的精度和准确度;不确定性吸收是指用户或模型设计者容忍这些不确定性的存在。不管如何进行不确定性减少,不确定性是客观存在的,为了让用户对不确定性了解,必须分析模型不确定性因素,之后对其传播进行研究和跟踪,从而全面把握模型的不确定性[7]。
3.2 空间数据模型的构建
空间数据模型是地理信息系统的基础,它不仅决定了系统数据管理的有效性,而且是系统灵活性的关键。空间数据模型是在实体概念的基础上发展起来的,它包含两个基本内容,即实体组和它们之间的相关关系。实体和相关关系可以通过性质和属性来说明,空间数据模型可以被定义为一组由相关关系联系在一起的实体集。
结合空间数据的具体特点进行空间数据模型的设计是建立地理信息系统的关键,空间数据模型的设计主要是构建一个能够用真实世界的抽象提取来代表该真实世界的模型。由于空间数据模型的设计与计算机硬件、系统软件和工具软件的发展现状密切相关,所以,就目前的发展现状而言,很难用一个统一的数据模型来表达复杂多变的地理空间实体。
(1)模型初步建立:把地理世界中问题的关键因素经过量化后成为数学实体或对象,并将这些实体或对象之间内在关系或规律用数学语言进行刻画,从而建立了问题的数学结构,得到了数学模型。
(2)模型评价和检验:建立模型的主要目的在于解决现实问题,因此,必须通过多种途径来检验所建立的模型,即检验有无逻辑上的矛盾、结果是否和实际问题相符合。评价模型的根本指标也是它是否能够准确地解决现实问题,但模型是否容易求解也是评价模型优劣的一个重要指标。
(3)模型的改进模型:是在不断修正中走向完善,在实际应用过程中一旦发现问题,必须考察在建模时所作的假设和简化是否合理,并针对发现的问题相应地修改模型,然后再次重复检查、修改过程。
(4)模型的求解:模型若能得到封闭式解的表达式固然是很好的,但多数场合模型的求解是复杂的,在建立模型的过程中,模型的求解还要考虑实际问题的应用。
4 模糊集方法在空间数据处理中的应用
4.1 模糊集方法的原理
模糊集合是对模糊现象或模糊概念的刻划,所谓模糊现象就是没有严格的界限划分而使得很难用精确的尺度来刻划的现象,而反映模糊现象的种种概念就称为模糊概念。模糊理论是指用到了模糊集合的基本概念或连续隶属度函数的理论,它是以模糊集合为基础,其基本精神是接受模糊性现象存在的事实,而以处理概念模糊不确定的事物为其研究目标,并积极的将其严密的量化成计算机可以处理的讯息,不主张用繁杂的数学分析即模型来解决模型[8]。
4.2 模糊函数的建立
模糊集理论也称为模糊集合论,或简单地称为模糊集,它为处理复杂系统中的模糊性提供了一种定量的方法。在经典集合论中,一个元素只能完全属于或完全不属于一个集合,只有“是”“非”两种可能性。而在模糊集理论中则允许一个元素对集合有部分或多种隶属关系,即对于空间论域X和模糊集合A,某一元素χ(χ∈X)与A 的关系可描述为:
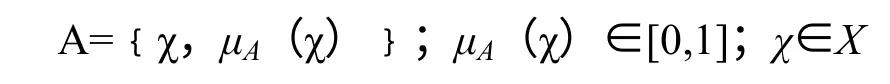
其中μA称为A 的隶属函数,μA(χ)称为元素χ 相对于A 的隶属度。
4.3 模糊集方法在GIS 数据处理中的应用
模糊地理对象的定义是由精确(exact)地理对象引申而来的,由于地理现象和过程的复杂性,许多现象没有明显的边界或者说边界上的元素既可能属于对象A,也可能属于对象B,尽管他们属于A 和B 的程度不同(隶属度)当研究和分析自然现象时,我们常常用自然语言来描述它们,这些语言表达了某种现象的通用特征,也就是说,它们拥有明确内涵,并涵盖了某种现象的大部分。模糊地理对象就是具有不确定边界的地理对象、这里的“边界”不仅是指对象几何体的边界,而且也指对象概念定义中的边界,也就是说,概念本身就是模糊的[9]。
(1)对GIS 数据误差的度量:知识误差的度量也有三种基本方式,以概率为基础的知识误差度量;以模糊关系为基础的知识误差度量:以主观可信度因子为基础的知识误差度量。具有概率性质的不确定性知识,用先验概率和条件概率来度量;具有模糊性质的不确定性知识用证据与假设或假设与证据间的模糊关系度量;而具有主观性质的不确定性知识则是用证据与假设间因果关系的可信度因素来度量的。
(2)对GIS 属性数据不确定性描述:在近似表达地学实体的理论和方法中,模糊集把确定集合中的二值隶属关系{0,1}扩展为一个模糊里数度区间[0,1]。具有类型混合或简便不确定性的实体可以用多个隶属度共同表示,模糊理论较传统集合理论更适于研究非匀质分布和模糊类别及其空间数据不确定性。
(3)GIS 数据质量评定:空间数据的不确定性,影响着GIS 信息的准确表达。其模糊性反映在位置精度,属性精度、逻辑一致性、完整性和时间精度等空间质量内容中。由于数据采集等过程中的误差存在使得对位置精度的影响是必然的,对属性精度的影响主要反映在知识推理操作过程中属性信息的推理误差,对逻辑一致性的影响反映在知识推理操作过程中模糊逻辑推理结果的模糊性。在模糊数学概念引入GIS 数据质量评价中,用模糊数学理论建立GIS 数字化产品质量评估模型。通过模型中评判因子、评价集、权重确定和模糊集合隶属函数的建立,有效地解决了GIS 数据质量优劣的客观定性问题,使矢量化数据产一品的评判简便、直观,保证了数据质量[10]。
(4)在土地适宜性评价中,土壤类型在空间是连续分布的,属性之间的转变是也渐变的,利用模糊集方法来进行土壤分类和土地评价,主要利用隶属度权重和为联合隶属函数进行土地评价,即而在专题地图各专题要素的面积估算和遥感影像信息的提取以及地理数据库的设计中均具有较为广泛的应用。
模糊理论为解决复杂系统中的不确定性问题提供了一种定量分析方法,因而在GIS 的许多领域中有着重要的应用。
5 结语
随着地理信息系统应用的深入,对地理信息系统的处理模型的输入或输出数据更加关注,而空间数据本身不可避免存在有不确定性,模糊理论作为一种数据分析方法,它为GIS的数据不确定性的表达和分析提供了有力的工具,同时它在利用自然语言进行有关空间查询方面具有较强的应用潜能。随着对空间数据处理智能化要求的进一步提高,模糊集方法将更多地用于各种空间运算,同时也将促进未来地理信息处理技术的发展,特别是空间决策支持系统的发展。
[1]郑贵洲,莫澜.GIS 图层在空间数据处理管理与分析中的作用[J].测绘科学,2003.9, 28(3):71~73
[2]杨海军,邵全琴.GIS 空间分析技术在地理数据处理中的应用研究[J].地球信息科学,2007.10, 9(5)
[3]张明,周世健,黄长军.浅析GIS 空间数据不确定性概念模型[J].东华理工学院学报,2005. 28(4)
[4]张菊清,杨元喜.空间数据不确定性研究现状分析[J].地理空间信息,2009.7(3)
[5]刘伯红.GIS 中不确定性研究及其进展[J].重庆邮电学院学报(自然科学版),2006.6
[6]李德仁.对空间数据不确定性研究的思考[J].测绘科学技术学报,2006. 10,23(6)
[7]孙庆辉等.空间数据处理模型误差和不确定性分析[J].测绘科学技术学报,2007.2,24(1)
[8]刘文宝.GIS 空间数据的不确定性理论[D].武汉:武汉测绘科技大学,1995
[9]张晓祥,姚静,李满春.模糊集方法在空间数据处理中的应用综述[J].遥感信息,2005. 2.47~51
[10]杜国宁.基于Ⅱ-型模糊集的不确定空间数据挖掘理论研究与应用[D].上海:上海交通大学,2005
猜你喜欢
数学大世界(2021年4期)2021-03-30 00:44:24
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:48
电子测试(2017年12期)2017-12-18 06:35:36
华中师范大学学报(自然科学版)(2016年1期)2016-11-30 03:42:14
测绘科学与工程(2016年4期)2016-04-17 06:51:13
佳木斯大学学报(自然科学版)(2014年4期)2014-07-09 01:59:58
测绘科学与工程(2014年2期)2014-02-27 07:05:49
测绘科学与工程(2013年1期)2013-03-11 15:07:25
测绘科学与工程(2013年1期)2013-03-11 15:07:24
测绘科学与工程(2013年1期)2013-03-11 15:07:23
