
基于谱聚类的社团发现算法
2013-11-18 13:23徐步东
潍坊工程职业学院学报 2013年4期
徐步东
(山东师范大学 信息技术管理处,济南 250014)
引言
现实世界中有大量的系统可以用由一些点和连接各个节点的边组成的网络来表示,如万维网、食物链网络。节点是表示复杂系统的基本单元,节点间的边表示各个单元的相互作用。系统中的每个节点以及每条边的性质都可以用称为“权重”和“强度”的更多信息来描述。
随着复杂网络研究的深入,人们注意到大量的实际网络都具有社团结构性质,即一个完整的实际网络通常是由若干个“社团”构成。我们着力研究实际网络的社团结构,从而有利于人们更加深入地了解网络结构以及分析网络的特性,使人们更加有效地理解和利用这些网络。例如,在发现社团以及社团的边界后我们可以根据结点的拓扑位置对结点进行分类,处于社团边界上的结点成为社团之间联系的桥梁,整个社团中心结点则控制着整个社团的稳定性。
1 复杂网络中社团发现算法研究现状
复杂网络中社团发现算法的一个主要目标是根据整个网络的拓扑结构来寻找网络中所存在的社团。社团发现与复杂网络的层次聚类和计算机科学图论中图分割的思想密切相关。层次聚类方法主要分为两类:凝聚方法(Agglomerative Method)和分裂方法(Divisive Method)。图分割主要包括两个算法:基于Laplacian 图特征值的谱平分法(Spectral Bisection Method)和Kernighan-Lin 算法。
Girvan 和Newman 提出了一类优化模块度Q 的算法,其中主要有极值优化算法以及模拟退火算法等,优化模块度算法的时间复杂度较高。Newman 还利用网络中一个新的特征矩阵的特征向量来重新定义了模块度Q,我们称这个特征矩阵为模块度矩阵(modularity matrix)。这是一种新的谱方法,并且这种算法与直接优化Q 的算法相比时间复杂度较小。
图分割方法很难将网络划分成有效数目的社团,不适用于结构未知的网络。Girvan 和Newman 提出了模块度,它可以有效地衡量社团划分结果。本文提出了一种基于谱聚类的社团发现算法。实验结果表明,通过与现有的社团发现算法比较,本文提出的算法效率更高,而且在处理结构未知的大型网络时,得到的结果令人满意。
2 基于谱聚类的社团发现算法
假设有一个无向加权图G(V,E,W),对称矩阵W=[wij]nxn,其中n 代表图G 中所含的节点数,wij代表连接顶点i 与j 的权值。模块度用于判定从网络的拓扑结构中得出的社团是否具有实际网络的社团结构。模块度定义表述为:假定把整个网络划分成g 个社团,构建一个g×g 维的矩阵b=[bij],其中元素bij表示两个顶点i、j 之间的边数占总边数中的比例,令ai=∑jbij表示与第i 个节点相连接的边的数目占整个网络的总边数的比例。模块度Q 如下式所示:

若社团内部的边所占的比例不大于所得出的期望值,则Q=0。令Q 上限为1,Q 越接近于这个值,则网络中的社团结构就越明显。在现实世界的网络中,该值通常介于0.3~0.7 之间。
本文提出了一种基于谱聚类的社团发现算法。算法描述如下:
输入:复杂网络G(V,E,W),kmax和kmin(kmax设为n/3,kmin设为2)
输出:聚类结果{V1,V2,…,Vk}
Step1:将网络G 初始化为包含所有节点的一个整簇,同时令Q=0;
Step2:对于G 中各簇Vc
1:构造权值矩阵W=Rnxn及对角矩阵D=∑jwij;
2:计算概率转移矩阵M=D-1W;
3:计算矩阵M 的前kmax个最大特征值及其对应的特征向量u1,u2,…,ukmax,构造矩阵Uk=[u1,u2,…,ukmax]∈RnxK,并将Uk的行向量转变为单位向量;
4:for(k=kmin;k≤kmax;k++){
(1)将Ck中的每一行看作GK空间中的一个点,应用k-means 算法来获得k 个新子簇,VC1,VC2,…,VCi;
(2)令G’=G,并将G'中的Vc设置为VC1,VC2,…,VCk;
(3)计算Q(G’);}
5:选取能够使Q(G’)值达到最大的k*,即k*=argmaxkQ(G’);
6:若Q(G’)>Q(G),则G 中各个簇的结构不变;否则,计算step2,对G 中其他簇计算。
该算法的时间复杂度为O(nk2
maxlogkmaxK)。若复杂网络为稀疏网络,则算法的时间复杂度为O(nkmaxlogkmaxK)。
3 实验结果及分析
为了测试本文算法的效率,选用2000 年美国大学足球赛网络、Zachary 网络、2008 年4 月人民网的强国论坛“深入讨论”板块的数据(其中共有95,247 条数据)以及爵士乐队,将本文基于谱聚类的社团发现算法同经典的GN、NM、MS 算法进行比较,主要比较算法的执行时间及模块度值,结果见表1 和表2。

表1 几种算法的模块度值比较
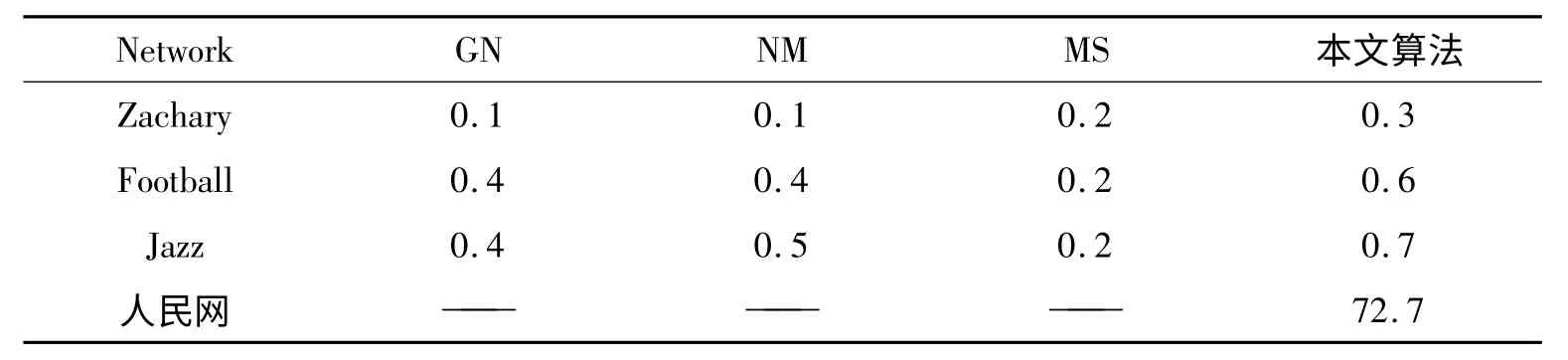
表2 算法执行时间比较T/s
从表1 可以看出,本算法在四种复杂网络中得到的社团结构均具有最高Q 值,该结果表明运用本文算法得到的社团结构更加令人满意。从表2 我们可以看出,GN、NM 和MS 三种算法在包含几百个节点的小网络中能有效进行社团划分,但节点数达到上万后,这三种算法无法计算Q 值。本文的算法可以在相对较短的时间内处理具有上万个节点的大型网络。
结束语
本文针对以往社团发现算法中时间复杂度较高这一问题,提出了基于谱聚类的社团发现算法,重新定义了模块度的衡量标准。将整个网络看作是一个社团,通过求解模块度矩阵的最大特征值及其对应的特征向量,借助k-means 算法,将整个网络划分为若干子簇,直到每个子簇不能再细分,然后输出结果。因此,得到的社团结构具有较高的质量。实验结果表明,本文提出的算法,能够在相对较短的时间内,处理节点数相对较多的大型网络并且对大型网络的结构实现了较好的划分,能够有效地对社团内部结构进行发掘。
[1]Shen-Orr S,Milo R,Mangan S,Alon U.Network motifs in the transcriptional regulation network of Escherichia coli[J].Nature Genetics,2002,(31):64.
[2]汪小帆,李翔,陈关荣.复杂网络理论及其应用[M].北京:清华大学出版社,2006:162-198.
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
中国惯性技术学报(2019年6期)2019-03-04
军事文摘(2017年16期)2018-01-19
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
中学生(2016年13期)2016-12-01
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
高中生·青春励志(2009年4期)2009-04-21
