
基于粗糙集的车险潜在客户数据挖掘方法
2013-10-21 00:57陈立杰
沈阳航空航天大学学报 2013年3期
陈立杰,程 菁
(1.沈阳航空航天大学 安全工程学院,沈阳 110136;2.南京财经大学 金融学院,南京 210003)
随着我国保险业的发展和对外开放,市场逐渐规范,竞争日趋激烈。多年来保险公司积累了大量的历史数据,如何更好地利用这些数据,从中挖掘出有价值的内在规律和潜在客户,成为保险公司生存和发展的重要手段。通过数据挖掘,可以发现购买某一保险险种客户的群体特征,从而向那些具有同样特征却没有购买该保险险种的客户进行有针对的推销;也可从流失客户中总结出群体特征,在那些具有相似特征的客户流失之前,采取针对性的措施避免客户的流失[1-2]。
数据挖掘就是从大量的数据中挖掘那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识。
粗糙集(Rough set)理论由波兰数学家Z.Pawlak 在1982年提出[3]。其基本思想认为知识是一种分类能力,对对象的认知程度取决于所拥有的知识的多少,知识越多,则分类能力越强。知识越少,则对象间的区分越模糊。
在保险历史数据中蕴含着大量的知识,我们可以利用这些知识发现客户的群体特征,利用粗糙集理论的分类能力,挖掘出潜在的车险购买客户。采用粗糙集进行数据挖掘与其他挖掘工具比较具有许多优点,针对一个大型的数据库系统,利用粗糙集理论比其它理论更容易建立数学模型。采用粗糙集理论进行数据挖掘时,可将其用于数据预处理、数据简约及实现决策算法等[4-5]。
1 粗糙集模型及分类规则
1.1 数据空间中知识的表达
协调近似表示空间是粗糙集理论的重要研究内容。可以证明信息系统、决策系统、不协调决策信息系统都可以转化为协调近似表示空间[6-8]。
一个知识系统S 可以表达为有序的四元组

其中,U={x1,x2,…,xn}为论域,即全体样本的集合;
R=C∪D 是U 上的一族等价关系。其中子集C 是条件属性集,反映样本的属性特征,D 为决策属性集[9],反映样本的类别;
f:U×R→V 为一个信息函数,用于确定U 中每一个对象x 的属性值。
当上述系统用于对象分类时,可以简化成下面的形式

A={a1,a2,…,an}是属性集。
1.2 分类模型与实现方法
按照知识的表达模式,可以将对象按下列步骤进行分类
(1)由D 将U 划分成不同的等价类,得到
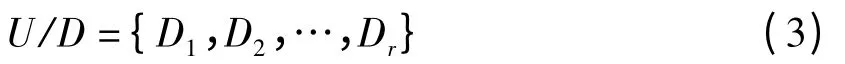
(2)对于Dj(j≤r),将对象属性按类分组
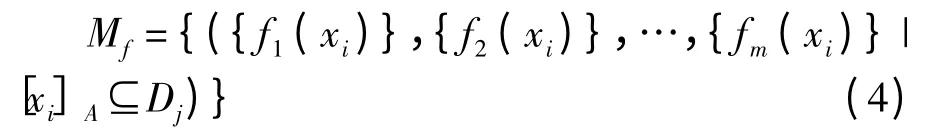
(3)对Mj中的向量进行并运算,即对每个属性合并分量,得到

(4)对于任意的取值E
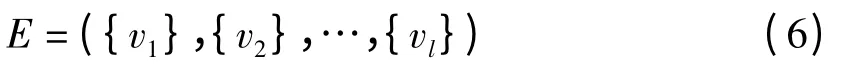
其中:vl∈Vl(l≤m)
计算分类的包含度
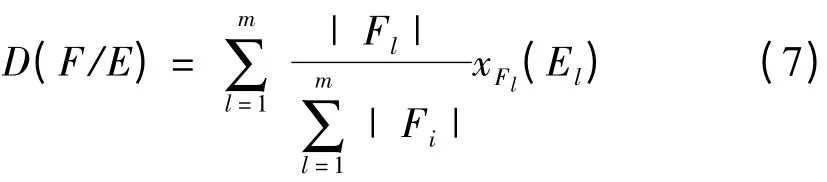
当EL⊆Fl时,xFl(El)=1;当El⊄Fl时,xFl(El)=0。
(5)最终按包含度最大决定分类
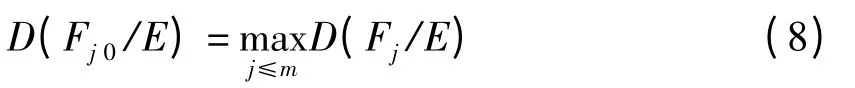
1.3 算例说明
因原数据集属性过多,故选取其中的47、59、80、40 列部分数据如表1 所示,说明计算过程如下:
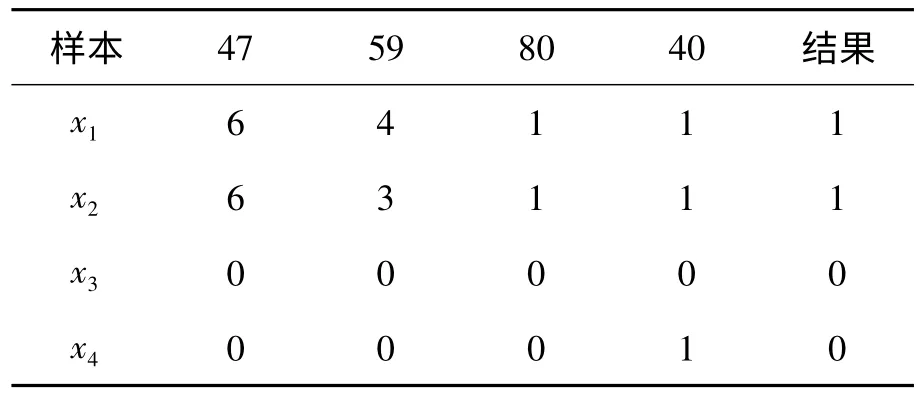
表1 部分样本的属性值及结果
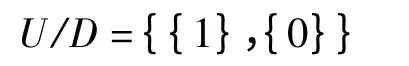
按结果集分类对属性进行分类
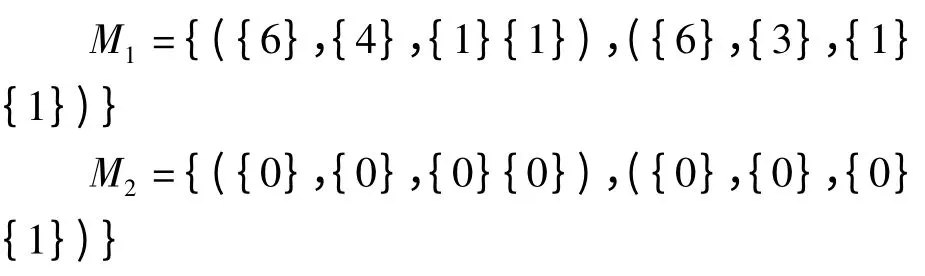
合并属性向量
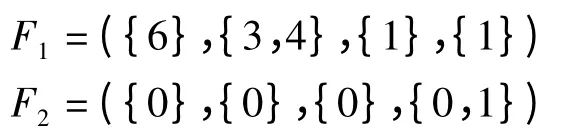
对给定的任意客户信息样本
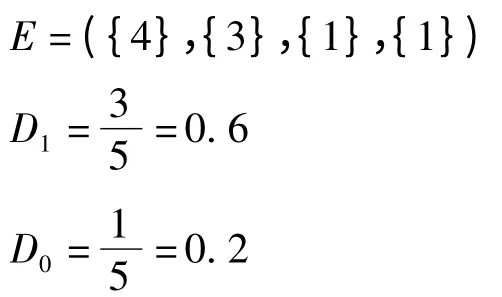
即该客户购买房车险的包含度为0.6,不购买的包含度为0.2。
2 结果与分析
2.1 样本数据
CoIL 2000 数据集中包含了一个保险公司的客户的资料。每个样本包括86 个属性,分为保单属性和社会属性两部分。数据集由荷兰的数据挖掘公司Sentient Machine Research 提供,数据来源于真实的业务积累。这些数据用于测试挖掘对购买房车保险感兴趣的客户。数据集中训练集包含5000 多个客户的资料,包括他们是否有房车保险的信息。测试集中包含4000 个客户资料,但隐藏了客户是否已买房车保险的属性。
2.2 数据预处理
经测试发现,训练数据集是不平衡的。其中只有约6%的正面样本。此外,他们中约有50 个是矛盾的,即完全一样的属性值同时出现在正负面的样本中。
为了便于挖掘计算,对数据做如下处理:
(1)将所有矛盾样本的负面样本改为正面样本。
(2)在数据集中为每个取值可能大于1 的属性(44 到85 属性列范围内)添加一个布尔属性。并做如下数据处理:如果原始属性值大于0 将对应的布尔属性值设为1,否则为0。
(3)添加两个求和属性Sum_of_contributions和Sum_of_policies,分别对应于业绩(属性列44-64)和保单(属性列65-85)。Sum_of_policies 中包含了客户购买的各种类型的保单(如车辆险,第三者保险等)。
2.3 数据挖掘结果
通过编程实现了基于粗糙集的数据挖掘程序,具体挖掘结果简述如下:
(1)关于负面样本的识别经对样本数据进行挖掘分析,我们成功找到了如下规则,这些规则可以用于识别不会购买房车保险的客户。
(I)如果助力车保单数大于0,而机动车保单的数量为0,那么该样本属于否(准确率100%);
(II)如果房产的数量大于2,则样本归类为否(准确率100%);
(III)如果收入大于123.000,那么这个类为否(准确率100%)。
(2)关于正面样本的属性权重
经挖掘分析得到了样本中不同属性对客户购买房车保险的权重贡献,按从大到小排列,前4 位如表2 所示。

表2 样本属性对购买房车保险的权重排序
3 结论
经对数据集的预处理,修正了数据集中存在矛盾的样本。采用粗糙集对知识的分类特性,对样本数据进行了挖掘计算,经验证得到如下结论:
(1)采用粗糙集理论,可以将客户保险数据看成一个知识系统,利用协调近似表示空间的分类功能发现数据中蕴含的知识和规则,并可以给出分类的可信度。因此,该方法可以用于各种保险数据的知识挖掘。
(2)由于数据集中普遍存在不完备问题,而传统的数据挖掘方法只能依赖于精确知识,这样就限制了它们的应用范围,因此粗糙集理论在数据挖掘中具有更广泛的应用前景。
(3)在采用粗糙集进行数据挖掘前,应进行必要的数据预处理,去除矛盾的样本,对属性值不全的样本应采用必要的措施进行修正或特征化处理。
(4)粗糙集理论适合处理离散数据,这与保险历史数据的状态一致,从而省去了数据离散化过程。
(References):
[1]管兴亮.数据挖掘在机动车辆保险中的应用[D].西安:西安电子科技大学,2008.
[2]王伟辉,耿国华.数据挖掘技术在保险业务中的应用[J].计算机应用与软件,2008,25(3):123-125 +207.
[3]Pawlak Z.Rough sets[J].International of Journal Information and Computer Science,1982,11(5):342-356.
[4]王勇军.基于ROUGH 集数据挖掘技术在保险中的应用.[D].广州:中山大学,2005.
[5]印勇.粗糙集理论及其在数据挖掘中的应用[J].重庆大学学报,2004,27(2):44-46 +50.
[6]张文修,仇国芳.基于粗糙集的不确定决策[M].北京:清华大学出版社,2005.
[7]张文修,吴伟志,梁吉业.粗糙集理论和方法[M].北京:科学出版社,2001.
[8]张博钊.基于粗糙集理论的安全评价方法研究.[D].沈阳:沈阳航空工业学院,2004.
[9]程乃伟.基于协调近似表示空间的安全评价方法研究[J].东北大学学报,2009,30,(Z1):180-182.
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06
大众投资指南(2021年35期)2021-02-16
小学生(看图说画)(2020年12期)2020-11-24
成都信息工程大学学报(2019年2期)2019-08-28
汽车观察(2018年11期)2018-12-05
当代旅游(下旬)(2018年5期)2018-10-21
现代装饰(2018年4期)2018-05-22
电力与能源(2017年6期)2017-05-14
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
