
改进的FP-tree算法在动车组故障诊断中的应用研究
2013-09-25 13:13:24马海漫赵怀昕
交通运输系统工程与信息 2013年6期
钟 雁,马海漫,张 春,赵怀昕
(1.北京交通大学城市交通复杂系统理论与技术教育部重点实验室,高速铁路网络管理教育部工程研究中心,北京 100044;2.天津铁路职业技术学院,天津 300240)
1 引 言
列车故障检测诊断系统作为保证高速铁路运行安全可靠的基础之一,国外高速铁路的安全监控系统正向系统化、信息化和综合化方向发展,日本新干线、法国TGV、德国ICE等都实现了故障检测诊断的微机化[1].为实现高效的检修作业,提出了在维修基地远程指导维修工作人员进行列车的维修工作或通过专家系统提供维修建议[2].国内学者应用新的理论、方法和技术对动车组的故障进行探索,如将专家系统、小波变换、神经网络、遗传算法等应用于动车组故障诊断方法的研究中[3,4].
然而,在动车组车载信息系统与地面信息系统的信息共享方面还存在很多不足.目前,对高速铁路的运行安全进行针对性的研究还不多,利用动车组状态数据对其维修工作的指导作用也不够.随着铁路信息技术深入应用,现已积累了在线运行动车组的海量运维状态数据,如何从中挖掘出有效的信息和知识,为动车组运营安全、故障诊断、维修等工作提供决策支持,是一个亟待解决的问题.
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程[5].关联规则是数据挖掘的一个重要的研究领域,所谓关联是指两种或两种以上的事务内在的联系[6].动车组检修是保障列车运行安全的重要手段[7],把动车组工作状态和故障之间的关联关系作为故障诊断的知识和规则,用于判断当前动车组是否处于故障状态.本文通过挖掘这些海量的动车组状态数据,用于动车组的故障诊断,并指导其维修工作,从而保障动车组正常的运营管理和动车组健康安全的运行状态,具有十分重要的应用价值.
2 频繁模式增长算法
动车组故障诊断主要是指对现实情况与理想情况偏差的判定,即对当前的状态信息予以判定,确定其是否处于正常状态.基于规则的故障诊断具有知识表述直观、形式统一、易理解和解释方便等优点[8].支持度和置信度是规则的两个兴趣度度量[9],其中,支持度反映了发现规则的有用性,是指模式为真的任务相关的元组(或事务)所占的百分比;置信度表示的是每个发现模式的有效性或“值得信赖性”的确定性度量.频繁模式增长算法简称FP-tree算法,是关联规则挖掘的经典算法之一.它将数据压缩到一棵频繁模式树(FP-树),但保留其数据项集关联信息;然后,把这种压缩后的数据组成一组条件数据库,每个条件关联一个频繁项,并分别挖掘每个数据库[10,11].
设有事务数据库D,FP-tree算法的主要过程如下:
第1步 按照Apriori[12]算法第一次扫描数据库,生成频繁项(1-项集)的集合,通过统计每一个项的个数,得到它们的支持度计数,然后把它们按支持度计数的降序排列,放入表中,记作排序表L.
第2步 构造FP-树.
(1)创建树的根节点,用“null”标记.
(2)再次扫描数据库,每个事务当中的项按L中的次序排列(即按递减支持度计数排序),并对每个事务创建一个树的分枝.当为一个事务考虑增加分枝时,沿共同前缀上的每个节点的计数增加1,为其跟随在前缀之后的项创建节点并链接.为方便树的遍历,创建一个项头表,记录相应频繁项的名称和支持度计数并按支持度计数递减的顺序排序.
第3步 按照项头表中频繁项的逆序,依次以每个频繁项所在节点开始沿树枝向上遍历,找到它的所有前缀路径,即得到它的条件模式基,并形成条件模式库.
第4步 对于条件模式库中的每个条件模式基,计算其中每个项的支持度计数,用条件模式库中的频繁项建立条件FP-树.
第5步 挖掘条件FP-树.即按照L中的项的逆序选择后缀项,寻找其前缀路径,选择支持度计数大于最小支持度计数的路径和后缀项组合生成所有的频繁项集,最后得到频繁模式库.
通过上述FP-tree算法实现步骤的分析,可知该算法具有如下特点:
(1)FP-tree算法采用压缩的结构存储数据库中的信息,且只进行2次数据库扫描.由于算法中某些项集前缀是一样的,FP-树可以通过共享这些重叠前缀来达到压缩保存的目的.
(2)FP-tree算法既不生成候选集[13],也不对候选项目集进行测试(即支持度计数).
(3)FP-tree算法良好的成长性.在生成FP-树的过程中,并未对数据信息进行任何删减,而是对其进行重新的排列,且没有对关联规则造成破坏,如果挖掘完又加入新数据,可在这棵树上继续加载新的数据,得到一棵更大的树,避免了前面挖掘的重复工作,节省了计算机的开销.
基于以上分析,虽然FP-tree算法具有较好的性能,但由于故障诊断知识要求抽取的每条规则中都必须含有故障信息,所以在动车组状态数据挖掘时考虑对FP-tree算法进行改进,以达到高效地得出故障诊断规则的目的.
3 算法改进
3.1 改进分析
在动车组上采集到的状态数据中包含了故障信息和相关的状态信息,包括(故障)状态信息名称、列车编号、车厢号、车厢类型、运行年月、速度、运行公里等字段.找到这些状态信息和故障信息之间的关联关系是动车组故障诊断的关键.频繁项是指某几个事务同时发生的次数大于最小支持计数的事务的集合.要把状态信息应用到故障诊断中,需要寻找一些“特殊的”频繁项,即其所包含的事务中,既有状态信息,又有故障信息.因为这些项是频繁的,那么某种状态和某些故障会“经常”一起发生,就表明在这种状态下,某些故障发生的概率要大一些.动车组在实际运行过程中,某些状态是连续的,此时状态A发生的次数并不是A真正发生的次数,只是数据库中记录的次数,这时考虑挖掘结果的置信度,就失去了其应有的意义,故在寻找动车组状态信息和故障信息之间的关联规则时,只需考虑支持度.支持度反映了动车组故障A与状态B同时发生的可能性大小,支持度越大,就表明在状态B下,故障A发生的可能性越大.当出现状态B时,就应进行相应的维护或检修工作,以免动车组发生故障A.
3.2 整枝FP-tree算法
设有事务数据库D,D={d1,d2,…,dk},其中d代表动车组历史数据中的状态数据,包括故障信息和状态信息.故障信息={制动及供风系统,牵引传动系统,…}为故障信息集合,状态信息={车厢,运行月份,…}为状态信息集合,显然故障信息集合∩状态信息集合=∅.改进算法的生成树流程如图1所示.
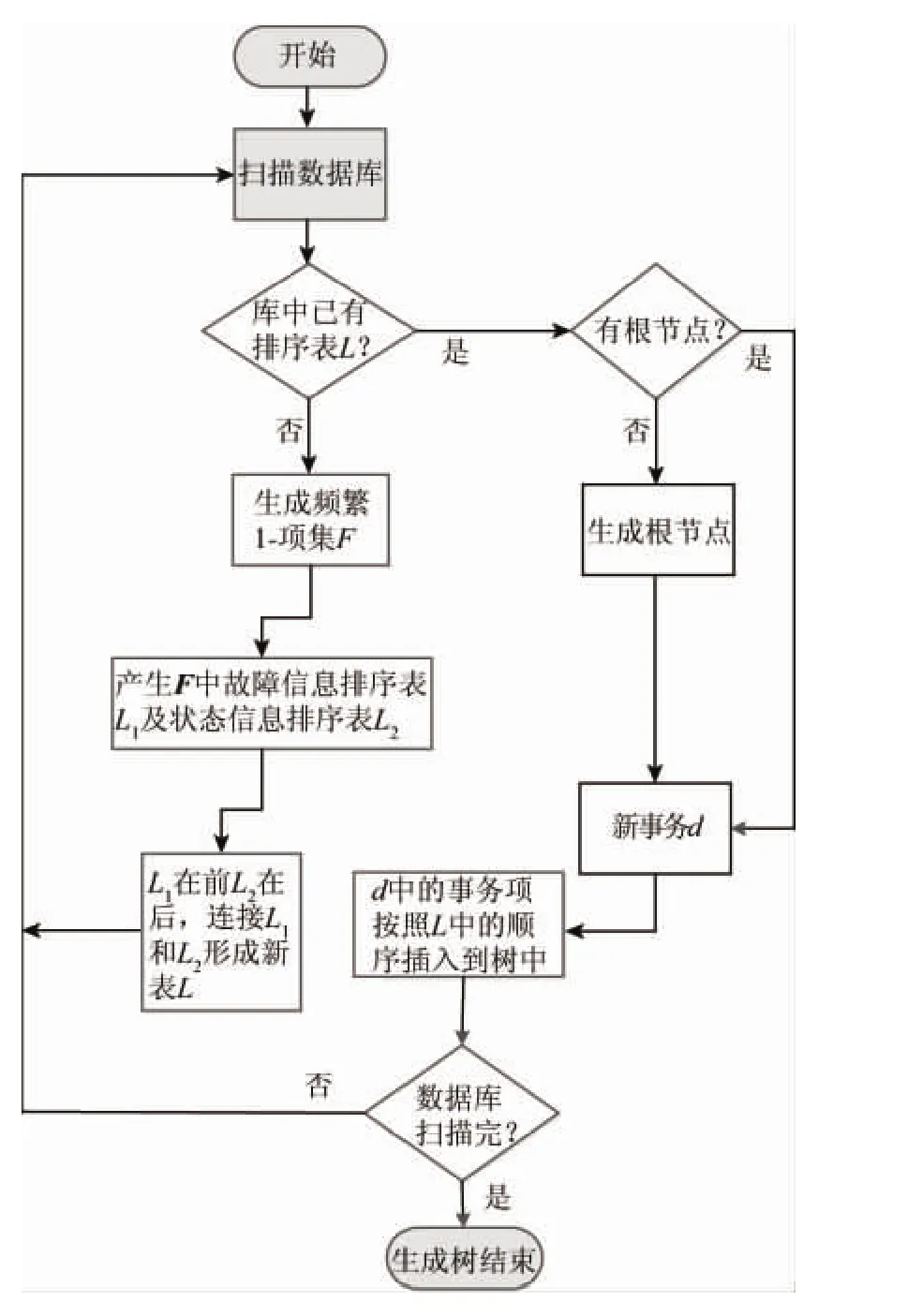
图1 改进的FP-tree生成树流程Fig.1 FP-tree’s generation of improved FP-tree
结合生成树的流程,改进算法的具体过程如下:
(1)扫描事务数据库D.
(2)若没有L,则产生频繁1-项集,得到它们的支持度计数.即先把故障信息项以支持度递减顺序排序,再将状态信息项按支持度的递减顺序排序,最后按故障信息项在前.状态信息项在后的顺序组合成排序表L.返回(1).
(3)若有L,则判定是否有根节点.
(4)若无根节点,则产生根节点,用“null”标记,并把扫描到的新事务di中的项按照L中的频繁项的顺序插入到树中,创建一个分枝,转(6).
(5)有根节点,则把扫描到的新事务di中的项按照L中的频繁项的顺序插入到树中,创建一个分枝,转(6).
(6)数据库是否扫描完毕.
(7)否,返回(1).
(8)是,生成树结束.
(9)搜索频繁模式.按照排序表L中项的逆序,以每一个状态信息项为后缀项,分别把枝上的所有节点和后缀项连接起来,得到频繁模式.
(10)计算支持度.支持度的计算公式如下:
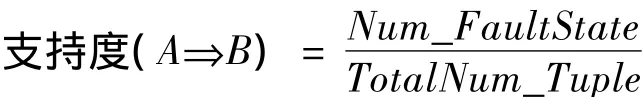
式中Num_FaultState——表示包含动车组故障信息A和状态信息B的元组数;
TotalNum_Tuple——表示元组总数.下面以动车组历史数据中的部分状态数据为例,具体说明该算法实现的详细步骤.设最小支持度计数为2,有如下故障信息和状态信息,如表1所示.其中,G1,G2表示故障信息,其余的I1-I5表示状态信息.

表1 故障信息举例Table 1 Examples of fault information
(1)扫描所有数据,得到频繁1-项集如表2.因为I5支持度计数为1,小于最小支持度计数2,所以频繁1-项集表中删除I5.
(2)将故障信息G1-G2排在前,状态信息I1-I4排在后,得出按照支持度降序的排序表L如表3所示.
(3)将每个事务中的项插入到树中.为方便树遍历,创建一个项头表,使得每个项通过一个节点链指向它在树中的出现,扫描所有的事务之后得到的树如图2所示,带有相关的链节点.
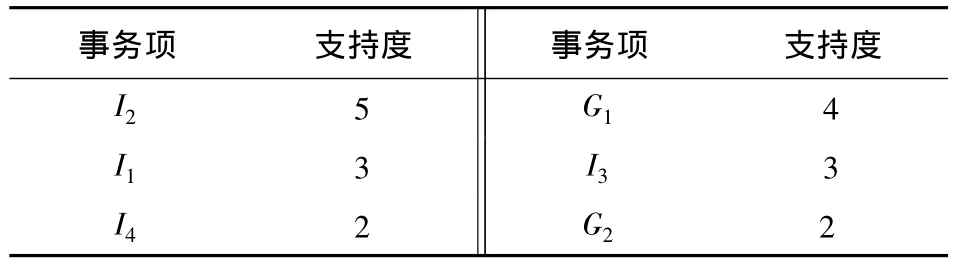
表2 频繁1-项集Table 2 Frequent 1-set
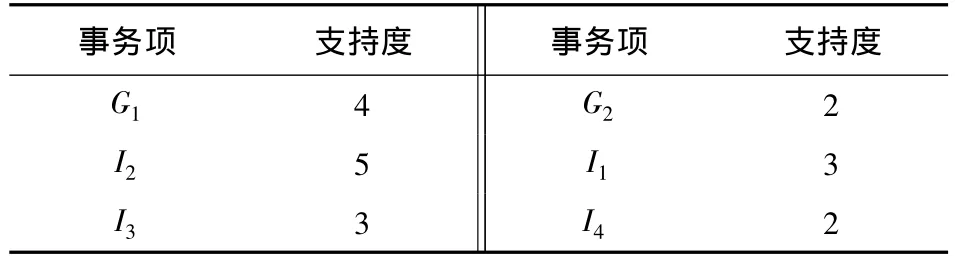
表3 排序表LTable 3 Sort table L
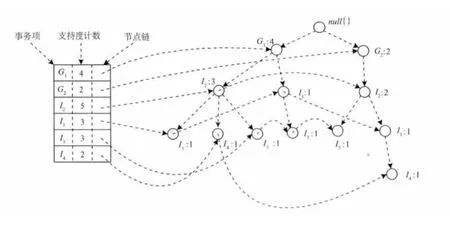
图2 存放压缩的频繁模式信息的FP-树Fig.2 The FP-tree
(4)搜索频繁模式.首先从L中支持度最少的I4开始,其包含两个路径 <(G1,I2,I4:1)>和<(G2,I2,I1,I4:1)>,由于G1和G2均小于最小支持计数,因此I4并未找到频繁模式.对于I3,其包含3 个路径 <(G1,I2,I3:1)> ,< (G1,I1,I3:1)>和 <(G2,I2,I3:1)>,因为G2的支持度计数为2,所以仅对 <(G1,I2,I3:1)> 和 <(G1,I1,I3:1)> 寻找频繁项,形成它们的条件模式基<(G1,I2:1)>,从<(G1,I1:1)>可知,仅含有G1这一个路径,因此有频繁模式<(G1,I3:2)>.其余各项类似,得到频繁模式如表4所示.

表4 通过创建条件(子)模式基挖掘FP-树Table 4 Search the FP-tree
由于所有的故障信息都处于FP-树的顶层(即再往上就是根节点),只需在FP-树搜索频繁项的过程中,令所有的搜索都搜索到树的顶层,这样搜索结果就必然含有故障信息.同时,由于并不需要计算相应的置信度,在递归地搜索频繁项时,也只需搜索到顶层,即搜索整个树枝.因此,本文将这种改进算法定义为整枝FP-tree算法.
整枝FP-tree算法与传统FP-tree算法主要有两点不同:
(1)整枝FP-tree算法不是直接按照其频繁性来排序,而是将故障信息前置,保证搜索结果都含有故障信息;
(2)递归地搜索频繁模式时,仅需要搜索完整的枝,不会产生许多较短模式的频繁项(这些频繁项仅含有状态信息),从而降低了搜索及产生频繁模式的计算开销.
3.3 改进算法的实例应用
下面以2010年10月到2011年8月实际数据为例来说明改进算法在动车组故障诊断中的应用.该数据来源于CRH2型动车组车载信息地面应用管理系统采集到的相关部分状态数据,总共20万余条.分别设置最小支持度为5%、10%、15%进行挖掘实验,经过比较,当最小支持度为15%时,仅可得出一条规则,最小支持度取得越高,得出的规则也越少.因此,选择10%作为最小支持度,设置其计数为20 000时,即为10%左右,可以得出数量适中且有一定参考价值的规则,其中得到的部分规则及其支持度如表5所示.
表5中的规则可为动车组的检修提供参考建议,辅助人工判断是否应该安排检修工作.例如:对于规则“故障信息(制动及供风系统),状态信息(2011-04)[支持度 =21.6%]”,该关联规则知识表示故障[制动及供风系统]在[4]月份频发,支持度为21.6%,建议在4月份安排制动及供风系统的专项检修工作.对于规则“故障信息(制动及供风系统),状态信息(T1)”[支持度=14.14%],该关联规则的知识表示故障[制动及供风系统]在[T1]车型中频发,支持度为14.14%,建议对T1车型安排专项检修工作.
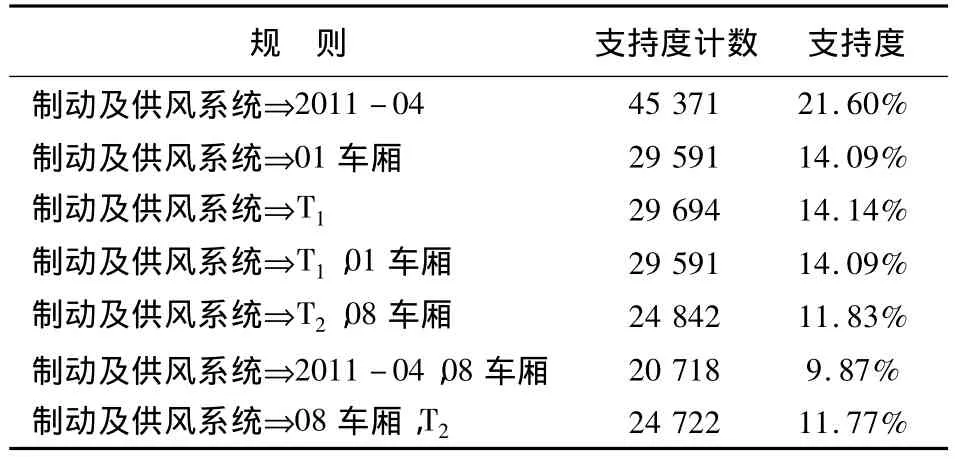
表5 部分存储的规则Table 5 Rules in KB(part)
4 改进算法的性能比较
下面基于同样的运行环境和硬件配置,在数据量分别为 2、4、6…18、20万条情况下,分别采用FP-tree算法和整枝FP-tree算法进行测试,两者的运行时间对比如图3所示.
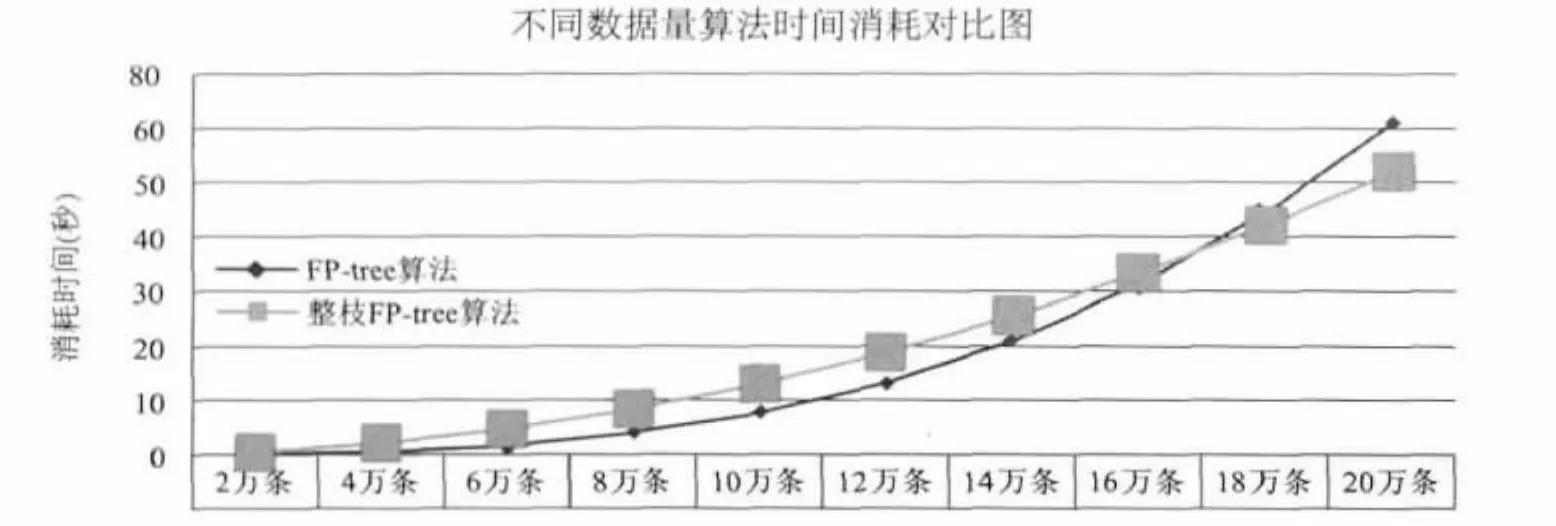
图3 两种算法时间效果图Fig.3 Time comparison of the two algorithms
从图3中可以看出,在数据量较小时两种算法性能相当,FP-tree略快于整枝FP-tree算法;当数据量较大时,本例中是17万条以上,整枝FP-tree算法的时间优势渐渐显现出来,从算法计算时间趋势上来看,数据量越大,节省的时间越多.
下面就两者的输出做一下对比,两种算法的输出结果如表6所示.
表6中,T和M代表车型,01~08代表1~8号车厢.从表6中可以看出,在同样的运行环境和硬件配置下,采用整枝FP-tree算法,程序运行时间比FP-tree算法减少了9 s,效率提高了约15%.对于输出结果,FP-tree中有一些仅含有状态信息的挖掘结果,但没有故障信息和状态信息之间的关联,例如:“"2011-04"61 463”等(输出框中下划线示出),这样无意义的输出结果造成了一定程度的空间浪费.
在采用整枝FP-tree算法后,不仅运行效率有了一定程度的提升,存储空间消耗也有所降低.CRH2型动车组车载信息地面应用管理系统每20 s就接收一次在线运行动车组的状态数据,每年都会产生海量运维数据.随着动车组状态数据的不断积累,使用整枝FP-tree算法进行数据挖掘的效率比FP-tree算法更高,并可及时提示动车组的故障状态及预警信息,因此该改进的算法有利于动车组的维护检修工作和运营调度的管理.
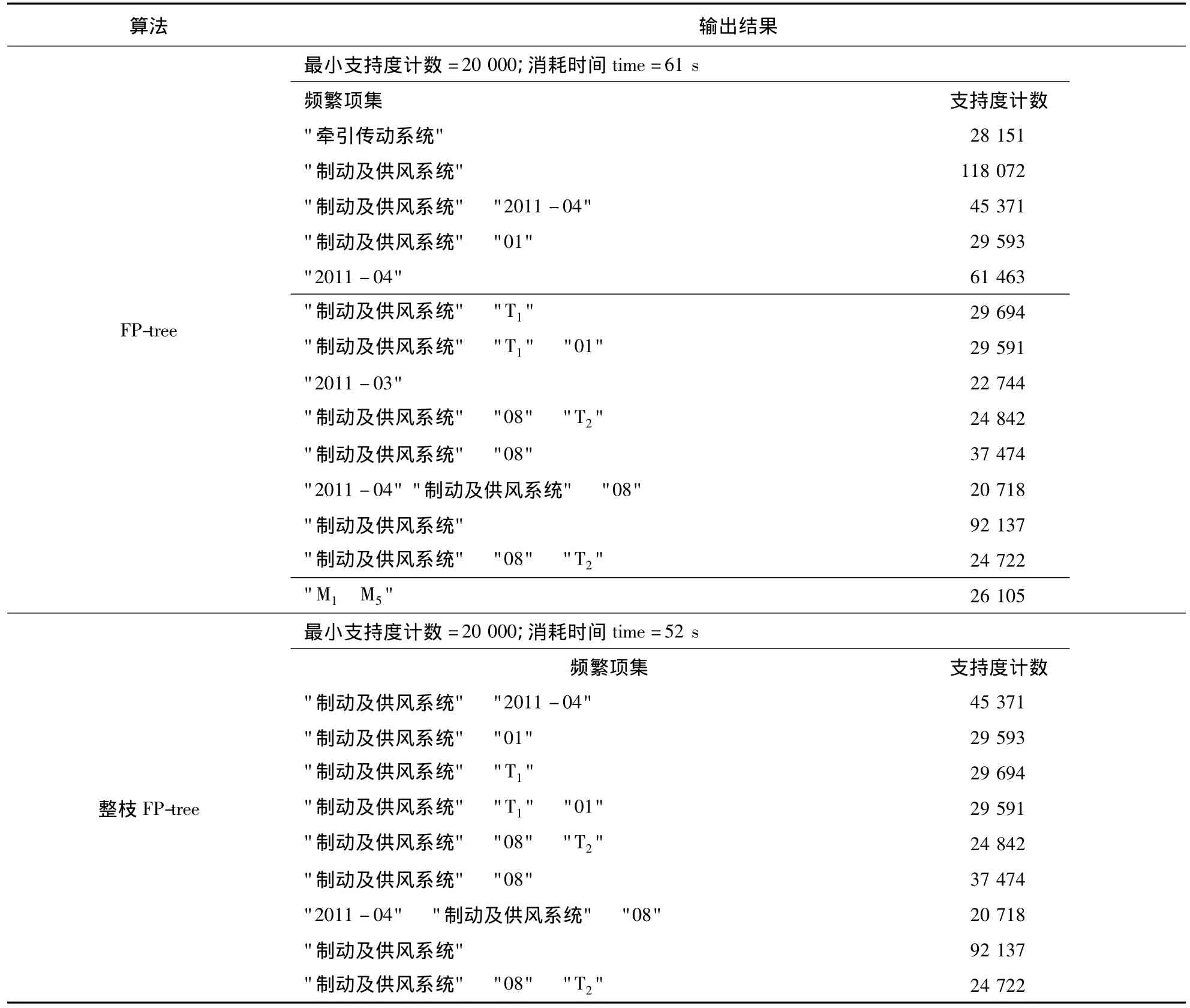
表6 两种算法输出结果Table 6 Output of the two algorithms
5 研究结论
本文改进了FP-tree算法,设计并实现了整枝FP-tree算法,挖掘结果符合挖掘目标的要求,能够为动车组实行状态修提供参考和建议.从运行时间上,当数据信息量很大时,本例是大于17万条以后,整枝FP-tree算法有较好的时间性能,而动车组在实际运营中产生的状态数据已超过17万条,所以改进算法可以提升数据挖掘的性能,节约时间成本.在存储空间上,改进算法也满足故障诊断的需求,不会产生无意义的关联规则,节约了数据挖掘所需的空间成本.
[1]张家栋,田宏萍.关于列车安全状态监测和诊断系统的研究[J].内燃机车,2000(11):22-24,28.[ZHANG J D,TIAN H P.Research on safe state monitoring and diagnosis system of train[J].Diesel Locomotives,2000(11):22-24,28.]
[2]Tim Smith,Alberto Diez Oliván,Nagore Barrena,et al.Remote maintenance support in the railway industry[C].Joint Virtual Reality Conference,2011:40-46.
[3]刘晶,季海鹏.基于神经网络的关联规则在故障诊断中的应用[J].工业工程,2011(02):118-121.[LIU J,JI H P.Neural network-based association rules for fault diagnosis[J].Industrial Engineering Journal,2011(02):118-121.]
[4]齐金平,宋薇,李宏亮,等.基于遗传算法的二元决策树方法在机车当量公里数学模型中的应用研究[J].内燃机车,2010(02):13-15,19.[QI J P,SONG W,LI H L,et al.Application of genetic algorithmbased binary decision tree method to mathematical model for equivalent locomotive running kilometers[J].Diesel locomotives,2010(02):13-15,19.]
[5]陈燕.数据仓库与数据挖掘[M].大连:大连海事大 学 出 版 社,2006:120-121.[CHEN Y.Data warehouse and data mining[M].Dalian:Dalian Maritime University Press,2006:120-121.]
[6]王晶,赵志强.关联规则算法的实现与优化[J].实验技术与管理,2012,29(8):111-112.[WANG J,ZHAO Z Q.Implementation and optimization of algorithm of data mining association rules of data mining[J]. Experimental Technology and Management,2012,29(8):111-112.]
[7]张才春,陈建华,花伟.基于不同检修能力的动车组运用计划研究[J].中国铁道科学,2010,31(5):130-133.[ZHANG C C,CHEN J H,HUA W.Research on the EMU operation plan based on different maintenance capacity[J].China Railway Science,2010,31(5):130-133.]
[8]吴明强,史慧,朱晓华,等.故障诊断专家系统研究的现状和展望[J].计算机测量与控制,2005,13(12):1301-1304.[WU M Q,SHI H,ZHU X H,et al.Research and prospect of fault diagnosis expert system[J].Computer Measure & Control,2005,13(12):1301-1304.]
[9]J Han,J Pei,B Mortazavi-Asl,et al.Freespan:Frequent pattern-projected sequential pattern mining[C]//Proceeding ofthe Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2000:355-359.
[10]H Mannila,H Toivonen,A Verkamo.Efficient algorithm for discovering association rules[C].AAAI Workshop on Knowledge Discovery in Databases,1994:181-192.
[11]蔡晓霞.关联规则中FP-tree算法的应用[J].福建电脑,2012,28(1):92-93.[CAI X X.Application of FP-tree algorithm in association rules[J].Fujian Computer,2012,28(1):92-93.]
[12]尹士闪,马增强,毛晚堆.基于频繁项目集链式存储方法的关联规则算法[J].计算机工程与设计,2012,33(03):1002-1007.[YIN S S,MA Z Q,MAO W D.Association rule algorithm based on chain storage method of frequent itemsets[J].Computer Engineering and Design,2012,33(03):1002-1007.]
[13]宋余庆,朱玉全,孙志挥,等.基于FP-tree的最大频繁项目集挖掘及更新算法[J].软件学报,2003,14(9):1586-1592.[SONG Y Q,ZHU Y Q,SUN Z H,et al.Algorithm for mining and updating maximal frequent itemsets based on FP-tree[J].Journal of Software,2003,14(9):1586-1592.]
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:20
中等数学(2020年8期)2020-11-26 08:05:58
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
海峡姐妹(2020年2期)2020-03-03 13:36:34
铁道通信信号(2018年11期)2019-01-19 01:14:54
中国种业(2018年11期)2018-11-16 08:16:42
今日农业(2018年5期)2018-03-24 05:53:12
现代园艺(2017年22期)2018-01-19 05:06:54
数学小灵通·3-4年级(2017年11期)2017-11-29 01:35:42
制造技术与机床(2017年12期)2017-02-02 07:05:03
