
可编程虚拟化路由器的转发表查找技术综述
2013-09-20 08:19罗腊咏葛敬国谢高岗
重庆邮电大学学报(自然科学版) 2013年1期
黄 昆,罗腊咏,葛敬国,谢高岗
(1.中国科学院计算技术研究所,北京 100190;2.中国科学院计算机网络信息中心,北京 100190)
0 引言
当前互联网采用基于TCP/IP协议的体系结构[1],即以IP协议为细腰的分层漏斗结构。随着物联网、云计算、移动计算等新技术新应用的不断涌现、以及网络规模的日益扩大,TCP/IP体系结构将面临可扩展性、移动性、安全性、可控可管等技术挑战。针对上述挑战,国内外研究者已开展未来互联网体系结构研究,例如:美国 GENI[2]和 FIND[3]项目、欧盟 FIRE[4]项目、AsiaFI[5]项目、日本 NWGN[6]项目、韩国FIF[7]项目和中国CENI项目等。这些研究主要采用网络虚拟化思想[8-10],即在一个实际物理网络基础设施上构建多个相互隔离的并行网络切片(slice)[11],每个网络切片运行一个具有不同体系结构的虚拟化网络。因此,基于网络虚拟化的未来互联网技术不仅兼容基于TCP/IP协议的互联网演进,而且支持新体系结构、新协议和新算法。
可编程虚拟化路由器(programmable virtual router)是实现网络虚拟化的关键部件,也是未来互联网的核心网络设备。可编程虚拟化路由器是在一个物理路由器平台上并行实现多个相互独立的虚拟路由器,且每个路由器采用自定义的路由协议和转发算法。与传统路由器不同,可编程虚拟化路由器采用数据平面与控制平面分离的思想[12],即利用虚拟机技术来实现可编程的多个数据平面和多个控制平面,从而在同一个物理设备上动态构建多个逻辑路由设备。例如,Cisco公司和Juniper公司的虚拟化路由器[13-14]分别采用虚拟机 VMWare和Xen,在通用路由器硬件平台上可实现128个虚拟路由器。可编程虚拟化路由器有利于ISP简化网络拓扑和流量管控、减少网络设备能耗和占地空间,从而降低网络设备投资和网络运维成本。因此,可编程虚拟化路由器已广泛应用于网络试验床[15]、网络管理[16]、用户自定义的路由协议、基于策略的路由协议、以及多拓扑的路由协议等。
转发表(forwarding table,FIB)查找技术是可编程虚拟化路由器性能的核心,即在一组路由规则中,查找出与输入数据包匹配的路由规则,转发到下一跳路由器。FIB查找技术可分为基于IP和基于非IP的查找技术。IP查找是当前互联网路由器的关键技术,即采用最长前缀匹配(longest prefix matching,LPM)算法[17],查找出与数据包的目的 IP地址匹配的最长前缀规则。以内容为中心的未来互联网体系结构,例如 NDN(named data networking)[18],提出基于内容名字的非IP查找技术,即采用最长名字前缀匹配(longest name prefix matching,LNPM)算法,查找出与内容名字匹配的最长前缀规则。
可编程虚拟化路由器的FIB查找技术面临性能与可伸缩性挑战。首先,FIB查找是计算密集型操作,运行在路由器的关键数据路径上,需要检查高速海量数据包,并与成千上万条路由规则进行匹配。其次,可编程虚拟化路由器需要并行运行成百上千个虚拟路由器,并确保每个虚拟路由器的转发性能,这将导致其存储空间和并行处理等需求迅猛增大,难以动态扩展支持更多虚拟路由器。最后,可编程虚拟化路由器要求支持非IP路由查找,灵活实现NDN等新型路由协议与转发算法。因此,灵活高效的FIB查找技术成为可编程虚拟化路由器研究热点。
1 可编程虚拟化路由器
近年来,研究者提出了多种支持未来互联网的可编程虚拟化路由器,可分为基于软件和基于硬件的虚拟化路由器。
在基于软件的可编程虚拟化路由器方面,Egi等人[19]提出了vRouter,在x86多核处理器平台上采用虚拟机Xen和OpenVZ,在数据平面实现并行软件路由器Click[20],其吞吐量可达7 Mbit/s;Dobrescu等人[21]提出了RouteBricks,在服务器集群和多核处理器平台上采用并行路由器体系结构实现Click,其吞吐量可达35 Gbit/s;Han等人[22]提出了Packet-Shader,利用GPU加速基于通用CPU的软件路由器Click,其吞吐量可达39 Gbit/s。
在基于硬件的可编程虚拟化路由器方面,Turner等人[23]提出了 Supercharging PlanetLab,采用网络处理器实现PlanetLab覆盖网的高性能节点;Carli等人[24]提出了PLUG,采用高速芯片实现灵活模块化路由查找模式,支持新路由协议的快速部署;Unnikrishnan等人[25]提出了基于FPGA的虚拟化路由器,利用可重构FPGA实现数据包转发,并采用虚拟机OpenVZ和软件路由器Click实现路由查找,可支持15个并行虚拟逻辑路由器;McKeown等人[12]提出了OpenFlow,采用NetFPGA实现数据平面与控制平面分离的软件定义路由器,多个虚拟化控制平面共享一个转发数据平面;Xie等人[26]提出了PEARL,利用FPGA的多根I/O虚拟化技术实现多个虚拟化数据平面,结合多核处理器实现复杂路由查找和控制平面管理。Anwer等人[27-28]提出了SwitchBlade,采用可编程NetFPGA实现多个并行数据平面,并确保每个数据平面的线速数据包路由查找。
为了实现目前互联网平滑过渡以及未来互联网快速部署,这些可编程虚拟化路由器要求达到商用路由器的高吞吐量等性能指标。一方面,网络带宽迅猛增长,例如互联网骨干带宽将增至100 Gbit/s;另一方面,YouTube,Facebook,Twitter和微博等新型网络业务,产生海量业务内容和网络流量。这些高速海量数据包给可编程虚拟化路由器的设计与实现带来巨大挑战。
2 性能与可伸缩性挑战
为了支持互联网演进与创新,可编程虚拟化路由器要求满足隔离性、性能和可编程性等需求[11]。隔离性要求同一物理设备上的多个虚拟路由器在CPU时间片、存储空间、链路带宽和路由规则等资源上相互独立且互不干扰,实现对共享资源的动态分配和透明管理。性能要求每个虚拟路由器高效利用共享资源,实现线速数据包路由查找与转发,并支持内容缓存管理和路由规则更新。可编程性要求提供从底层到高层的多层次可编程接口,从而灵活实现自定义的数据包处理流程,兼容IP和非IP等体系结构、路由协议和转发算法。
可编程虚拟化路由器的隔离性、性能和可编程性是相互制约的,其主要区别体现在路由器资源的管理策略上。隔离性是采用资源分割策略,即每个虚拟路由器静态占用设备资源;而性能和可编程性是采用资源共享策略,即每个虚拟路由器动态占用设备资源。性能要求紧耦合的高效数据包处理,而可编程性要求松耦合的灵活数据包处理。因此,为了实现未来互联网的灵活高效FIB查找,可编程虚拟化路由器需要折衷考虑隔离性、性能和可编程性,即在隔离性和可编程性等约束条件下,提升其性能和可伸缩性,达到商用路由器的高吞吐量等指标。
近年来,随着互联网带宽和流量的迅猛增长、路由规则的日益增多、新型路由协议的不断涌现,可编程虚拟化路由器的FIB查找技术面临性能和可伸缩性挑战,即如何满足多个FIB查找的吞吐量、存储空间和增量更新等需求。
1)高速网络及应用的迅猛发展要求可编程虚拟化路由器中的每个虚拟路由器实现线速FIB查找。未来互联网的骨干链路带宽将增至100 Gbit/s,每个数据包的平均FIB查找时间为3.2 ns。因此,FIB查找必须在高速存储器(片上SRAM)上执行,并减少慢速存储器(片外DRAM)访问次数,从而提高其吞吐量。
2)网络业务及其路由规则的日益增多要求可编程虚拟化路由器支持更多并行虚拟路由器。FIB大小随着网络规模的增大而迅猛增大。例如,目前IP核心路由器包含约40万条路由规则。每个虚拟路由器维护一个独立的FIB,导致可编程虚拟化路由器的存储空间开销呈爆炸性增长,转发表更新开销高,可伸缩性差。这将不仅限制并行虚拟路由器个数,而且限制每个虚拟路由器的FIB查找性能。
3)新型未来互联网体系结构NDN要求可编程虚拟化路由器灵活支持基于非IP的FIB查找。与IP地址不同,NDN名字采用URL方式命名内容,具有长度不确定且无限长等特点,采用LPNM算法查找最长名字匹配的前缀规则,导致存储开销高和查找效率低等问题。另外,为了减少请求数据包的响应时延和数据传输流量,NDN要求在转发路径上支持缓存请求数据包和内容,导致缓存查找和更新开销大。
3 FIB查找技术
针对上述性能和可伸缩性挑战,研究者主要从多FIB融合的IP查找算法和NDN名字查找算法等两个方面,实现可编程虚拟化路由器的灵活高效FIB查找。
3.1 多FIB融合的IP查找算法
IP查找是在FIB中,查找出与输入数据包的目的IP地址最长前缀匹配的转发规则。转发规则是由IP地址前缀和下一跳步信息(例如转发端口号、路由器MAC地址)等构成。在可编程虚拟化路由器中,每个虚拟路由器维护一个FIB,采用特里树(Trie)表示每个FIB的IP地址前缀集。图1给出了2个FIB及其二叉特里树Trie1和Trie2。其中,带阴影节点为前缀匹配节点。

图1 两个FIB及其二叉特里树Fig.1 Two FIB and their binary tries
可编程虚拟化路由器的IP查找算法可采用分离和融合2种方式。分离方式是为每个FIB构建一个独立特里树进行IP查找,且为每个虚拟路由器分配相互隔离的计算和存储资源。该方式的优点是虚拟路由器之间的隔离性好,确保其互不干扰;其缺点是多个独立特里树的存储空间需求高,且不同特里树的存储空间分配不均等。
针对分离方式中的单个FIB,研究者提出了许多IP查找算法,可分为基于TCAM、基于哈希和基于特里树的IP查找算法。基于TCAM的IP查找算法[29-31]利用TCAM硬件在1个时钟周期内完成一次IP查找,提供确定性和高速IP查找,但是存在能耗高、价格昂贵等问题。基于哈希的 IP查找算法[32-37]利用片上SRAM的哈希表来加速IP查找性能,但是存在存储器带宽需求大等问题。基于特里树的IP查找算法包括叶推特里树(leaf-pushed Trie)[38]、吕勒奥特里树(Lulea Trie)[39]、树位图特里树(tree bitmap Trie)[40]、形状图(shape graph)[41]和偏移编码特里树(offset encoded Trie)[42]等采用树型数据结构来实现存储高效的IP查找。为了提高该算法的吞吐量,研究者提出了流水线方法(pipelining)[45-49],即在片上SRAM 的1个时钟周期内完成一次IP查找。
与分离方式相反,融合方式是多个虚拟路由器共享计算和存储资源,将多个FIB融合表示成一个共享数据结构进行IP查找。该方式的优点是共享数据结构的存储空间需求低,可动态扩展支持更多虚拟路由器;其缺点是弱化虚拟路由器之间的隔离性,多个FIB融合后的更新开销高。近年来,研究者提出了针对多FIB融合的IP查找算法。这些算法解决的共性问题是如何将多个FIB融合表示成一个高效的共享数据结构,减少整个路由器的存储空间开销,以及如何支持多个FIB的快速增量更新。
Fu等人[50]提出了基于特里树重叠(Trie overlay)的IP查找算法。该算法是利用重叠机制将多个FIB的IP前缀集进行重叠融合,并采用一个融合特里树表示这些重叠后的IP前缀集,从而减少多个独立特里树的存储空间开销。为了确保查找正确,该算法在融合特里树的每个前缀匹配节点中增加一个位图(bitmap),用于指出匹配了哪个FIB的IP前缀。图2给出了特里树重叠方法示例,即将图1的2个特里树从根节点开始进行重叠,从而构建一个融合特里树。例如,在融合特里树中,根节点Aa是由Trie1和Trie2的根节点A和a重叠而成;类似地,其孩子节点Bb是由Trie1和Trie2的节点B和b重叠而成。当给定数据包的FIB标识符为Trie1和目的IP地址为1010,IP查找从根节点Aa开始,遍历节点Cc,E和F。由于节点F是最长匹配前缀节点,查找结果为下一跳步信息P4。如果多个FIB具有相似结构,该算法的存储空间压缩效果表现良好;否则,该算法无法减少多个FIB的存储空间开销。

图2 特里树重叠示例Fig.2 Trie overlay
Song等人[51]提出了基于特里树编织(Trie braiding)的IP查找算法,即在上述特里树重叠的基础上,利用孩子节点旋转机制来增加多个FIB的重叠度,进一步减少融合特里树的存储空间开销。该算法对每个特里树节点的左右孩子进行旋转,采用编织比特(braiding bit)指示该特里树的遍历方向,从而确保查找正确。图3给出了特里树编织示例,即将图1的2个特里树从根节点开始进行旋转和重叠,从而构建一个更加紧凑的融合特里树。其中,每个节点采用2个编织比特表示Trie1和Trie2的遍历方向。如果编织比特值为1,表示从其左分支遍历右孩子,从其右分支遍历左孩子。如果编织比特值为0,表示从其左分支遍历左孩子,从其右分支遍历右孩子。例如,节点Cc的编织比特为1,0,表示当Trie1读入字符0时遍历其左孩子节点Ee,当Trie2读入字符1时遍历其左孩子节点Ee。当给定数据包的FIB标识符为Trie1和目的IP地址为1010,IP查找从根节点Aa开始,遍历节点Cc,Ee和Fg。由于节点Fg是最长匹配前缀节点,查找结果为下一跳步信息P4。该算法采用启发式方法来最大化多个特里树的重叠度,从而最小化融合特里树的节点个数。但是,该算法仅减少融合特里树的节点个数,却不一定能减少其存储空间开销。其主要原因是特里树实现不必为叶子节点分配存储空间,因而由非叶子节点决定其存储空间开销。
上述研究主要关注可编程虚拟化路由器的存储高效IP查找。由于多FIB融合的更新开销高,如何在存储高效的条件下支持快速增量更新成为可编程虚拟化路由器的快速IP查找算法的关键问题。

图3 特里树编织示例Fig.3 Trie braiding
Le等人[52]提出了基于集合分割(set partitioning)的IP查找算法,即利用集合分割机制将一个融合FIB分割成2个子表,采用2-3树数据结构表示每个子集,并执行流水线并行IP地址查找。Luo等人[53]也提出了特里树分割思想,将一个融合FIB分割成不相交前缀集和重叠前缀集;对于不相交前缀集,采用TCAM进行快速查找,对于重叠前缀集,采用基于SRAM的流水线IP查找,从而实现快速查找和增量更新。图4给出了特里树分割示例,将图4a中的一个特里树分割成不相交前缀集(见图4b)和重叠前缀集(见图4c)。

图4 特里树分割示例Fig.4 Trie partitioning
Luo等人[54]提出了基于TCAM的存储高效FIB查找算法,减少多FIB融合的TCAM存储空间开销。该算法通过挖掘不同IP前缀之间的相似性,提出了TCAM中共享前缀的数据结构,如图5所示。当多个FIB共享相同的前缀时,在融合后的TCAM中仅保留一条表项,同时将多个下一跳步信息按照FIB的顺序存储在SRAM中。基于上述合并数据结构,可显著降低TCAM存储空间需求。但是,上述数据结构会带来前缀屏蔽问题,导致某些情况下不正确的最长前缀匹配。为了解决前缀屏蔽问题,该算法进一步提出了FIB填充和FIB分割2种方法。

图5 TCAM中共享前缀的数据结构Fig.5 Shared prefix data structure in TCAM
Luo等人[55]提出了支持快速增量更新的特里树合并方法。在已有特里树合并的基础上,该方法在特里树节点数据结构中引入前缀位图,将节点和下一跳步分离,如图6所示。当增加一个虚拟路由器时,特里树节点大小仅增加1比特,有效提高节点大小的可伸缩性;在特里树合并过程中,避免采用叶推技术,从而在增加可伸缩性的同时,支持快速增量更新。另外,该方法采用IP查找流水线,其更新开销为一次写气泡/每次更新,显著减少更快开销。
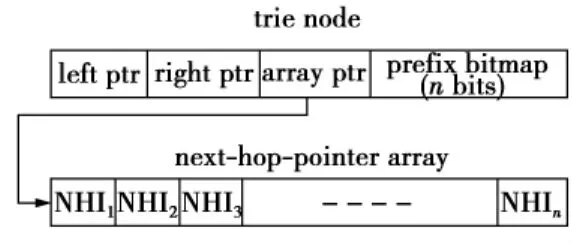
图6 包含前缀位图的特里树节点数据结构Fig.6 Trie node data structure with prefix bitmap
3.2 NDN名字查找算法
NDN是以内容为中心的未来互联网体系结构,解决目前互联网的地址空间爆炸、动态性、地址可扩展等问题。NDN利用地址和标识分离的思想,采用命名数据作为协议栈的细腰,并设计基于名字的路由协议和转发算法。NDN采用类似URL的方式命名数据[18],例如/cn/ac/ict/fi/index.html,表示网页fi.ict.ac.cn/index.html。为了优化流量和避免拥塞,NDN在路由器上缓存请求数据包及其响应内容,提升数据传输性能。
NDN路由器包含 FIB、兴趣数据包缓存表(pending interest table,PIT)和内容缓存表(content store,CS)[18]。图7给出了NDN数据包转发流程。客户主机发送兴趣(Interest)数据包,请求一个内容(例如文件、电影或音乐);当接收到兴趣数据包后,服务器响应数据(data)数据包给该客户主机。因此,PIT是用于缓存未响应的兴趣数据包,而CS是用于缓存响应的数据。
在NDN数据包转发流程图(见图7)中,当接收到一个兴趣数据包时,NDN路由器首先在CS中查找,如果缓存了相应的数据,直接返回该数据;否则,在PIT中查找,如果缓存了相应的兴趣数据包,增加输入端口到相应的PIT表项中;否则,继续在FIB中查找,如果查找成功,转发该数据包到下一跳路由器;否则,丢弃该数据包,并返回NACK。当接收到一个数据数据包时,NDN路由器在PIT中查找,从PIT表项中删除对应的兴趣数据包,并在CS中缓存该数据,返回该数据给相应的请求客户主机。

图7 NDN数据包转发流程Fig.7 NDN packet forwarding procedure
为了支持NDN新型路由协议,可编程虚拟化路由器要求实现高效NDN命名查找算法。由于NDN名字具有长度不确定且无限长等特点,NDN命名查找采用LPNM算法查找最长名字匹配的前缀规则,导致FIB存储开销高和名字查找效率低等问题。另外,由于每个兴趣数据包要求查找并更新PIT,NDN名字查找算法面临快速增量更新等挑战。
近年来,研究者提出了多种NDN命名查找算法,主要解决FIB/PIT/CS的存储空间缩减和快速查找等问题。Wang等人[56]提出了一种NDN名字子串编码方法来实现存储高效的名字特里树,以及提出了状态迁移数组来实现快速LPNM。图8给出NDN名字子串编码及其状态迁移数组。在图8a的NDN名字特里树中,每层为每个分支的名字子串依次分配整数编码,例如<yahoo,1>和<google,2>表示yahoo和google的编码分别为1和2。为了确保每层名字子串的编码唯一性,图8b合并了名字子串相同的编码,例如合并<google,2>和<google,3>为<google,4>,即选择每层编码的最大整数值加1为其编码。如图8c所示,采用状态迁移数组来查找子串特里树和名字特里树。由于采用特里树查找NDN名字及其子串,该算法的查找性能是由特里树的深度所决定,查找速率低且树型数据结构的更新开销高。另外,由于状态迁移数组采用指针来指示遍历的节点位置,导致该算法的存储空间开销高。

图8 NDN名字子串编码及其状态迁移数组Fig.8 NDN name component encoding and state transition arrays
Yuan等人[57]探讨了NDN软件实现CCNx的转发数据结构及其查找性能。图9给出了CCNx的转发数据结构。为了支持快速查找和增量更新,CCNx采用哈希表在软件上实现FIB,PIT和CS。如图9所示,FIB,PIT和CS分别采用NPHT,PHT和CHT进行查找,且这些哈希表采用链接方式来解决哈希冲突,即当元素插入发生冲突时,该元素插入到该存储桶的链接队列中。FIB是基于最长名字前缀匹配的查找,而PIT和CS是基于精确匹配的查找。虽然CCNx可实现快速更新和查找,但是难以处理高速海量数据包转发,特别是哈希表只适合PIT和CS的精确匹配,而难以有效支持FIB的最长名字前缀匹配。

图9 CCNx的转发数据结构Fig.9 CCNx forwarding data structures
4 结论与展望
可编程虚拟化路由器是实现互联网演进与创新的核心网络设备。本文综述了可编程虚拟化路由器的FIB查找技术。首先,分析了FIB查找的性能与可伸缩性挑战,要求解决多个FIB的吞吐量、存储空间和增量更新等问题。其次,讨论了多FIB融合的IP查找算法和基于NDN命名的非IP查找算法等研究进展。
为了支持新型路由协议与转发算法,可编程虚拟化路由器的FIB查找技术亟需解决以下问题。
1)多域 FIB查找。新型交换机 OpenFlow[1]采用多域FIB查找算法,灵活支持数据平面的转发创新。该算法采用用户自定义十元组定义FIB表项,并分割成多个子表进行基于包分类(packet classification)的流水线查找。由于OpenFlow采用带状态(stateful)的FIB查找,即每个新到达数据包需要动态加载FIB表项,因此多域FIB查找算法面临增量更新与快速查找之间折衷的问题。
2)NDN线速转发。已有研究工作主要集中于基于软件的NDN命名查找与转发算法,难以实现10~40 Gbit/s线速数据包处理。基于硬件的NDN命名查找与转发是提升数据包处理性能的有效途径,例如采用FPGA和TCAM相结合的实现方法。NDN名字长度不确定且无限长以及支持快速增量更新,因此基于硬件的算法面临存储空间缩减和快速更新等问题,即如何在存储资源受限的硬件上实现存储高效的NDN线速转发,并支持快速更新。
[1]LEINER B M,KAHN R E,POSTEL J,et al.A brief history of the internet[J].ACM SIGCOMM Computer Communication Review,2009,39(5):22-31.
[2]GENI[EB/OL].[2012-10-11].http://www.geni.org.
[3]FIND[EB/OL].[2012-10-12].http://www.nets-find.org.
[4]FIRE [EB/OL].[2012-10-12].http://www.ict-firworks.eu.
[5]AisaFI[EB/OL].[2012-10-12].http://www.asiafi.net.
[6]NWGN[EB/OL].[2012-10-12].http://akari-project.nict.go.jp.
[7]FIF [EB/OL].[2012-10-12].http://www.fif.kr.
[8]ANDERSON L,PETERSON L,SHENKER S,et al.Overcoming the internet impasse through virtualization[J].Computer,2005,38(4):34-41.
[9]TURNER J S,TAYLOR D E.Diversifying the internet[C]//Global Telecommunications Conference,2005.GLOBECOM’05.IEEE.ST.Louis,MO:IEEE Conference Publications,2005(2):755-760.
[10]FEAMSTER N,CAO L,REXFORD J.How to lease the internet in your spare time[J].ACM SIGCOMM Computer Communication Review,2007,37(1):61-64.
[11]CRHOWDHURY N,BOUTABA R.A survey of network virtualization[J].Computer Networks,2010,54(5):862-876.
[12]MCKEOWN N,ANDERSON T,BALAKRISHNAN H,et al.OpenFlow:Enabling innovation in campus networks[J].ACM SIGCOMM Computer Communication Review,2008,38(2):69-74.
[13]Cisco logical router[EB/OL].[2012-09-18].http://www.cisco.com.
[14]Juniper logical router[EB/OL].[2012-10-08].http://www.juniper.net.
[15]BAVIER A,FEAMSTER N,HUANG M,et al.In VINI veritas:Realistic and controlled network experimentation[J].ACM SIGCOMM Computer Communication Review,2006,36(4):3-14.
[16]WANG Y,KELER E,BISKEBORN B,et al.Virtual routers on the move:Live router migration as a network management primitive[J]ACM SIGCOMM Computer Communication Review,2008,38(4):231-242.
[17]RUIZ-SANCHEZ M A,BIERSACK E W,DABBOUS W.Survey and taxonomy of IP address lookup algorithms[J].IEEE Network,2001,15(2):8-23.
[18]ZHANG L,ESTRIN D,JACOBSON V,et al.Named data networking project[EB/OL].[2012-10-08].http://www.named-data.net/.
[19]EGI N,GREENHALGH A,HANDLEY M,et al.Towards high performance virtual routers on commodity hardware[C]//CoNEXT '08 Proceedings of the 2008 ACM CoNEXT Conference.New York,NY,USA:ACM,2008.
[20]KOHLER E,MORRIS R,CHEN B,et al.The click modular router[J].ACM Transactions on Computer Systems,2000,18(3):263-297.
[21]DOBRESCU M,EGI N,ARGYRAKI K,et al.Route-Bricks:Exploiting parallelism to scale software routers[C]//SOSP '09,Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles.New York,NY,USA:ACM,2009:15-28.
[22]HAN S,JANG K,PARK K S,et al.PacketShader:A GPU-accelerated software router[C]//Proceedings of the ACM SIGCOMM 2010 conference.New York,NY,USA:ACM,2010:195-206.
[23]TURNER J,CROWLEY P,DEHART J,et al.Supercharging planetlab:A High performance,multi-applica-tion,overlay network platform[C]//Proceedings of the 2007 conference on Applications,technologies,architectures,and protocols for computer communications.New York,NY,USA:ACM,2007:85-96.
[24]CARLI L D,PAN Y,KUMAR A,et al.PLUG:Flexible lookup modules for rapid deployment of new protocols in high-speed routers[C]//Proceedings of the ACM SIGCOMM 2009 conference on Data communication.New York,NY,USA:ACM,2009:207-218.
[25]UNNIKRISHNAN D,VADLAMANI R,LIAO Y,A.et al.Scalable network virtualization using FPGAs[C]//Proceedings of the 18th annual ACM/SIGDA international symposium on Field programmable gate arrays.New York,NY,USA:ACM,2010:219-228.
[26]XIE G,HE P,GUAN H,et al.PEARL:A programmable virtual router platform [J].IEEE Communication Magazine,Special Issue on Future Internet Architectures:Design and Deployment Perspectives,2011,49(7):71-77.
[27]ANWER M B,FEAMSTER N.Building a fast,virtualized data plane with programmable hardware[J].ACM SIGCOMM Computer Communication Review,2010,40(1):75-82.
[28]ANWER M B,MOTIWALA M,TARIQ M,et al.SwitchBlade:A platform for rapid deployment of network protocols on programmable hardware[C]//Proceedings of the ACM SIGCOMM 2010 conference.New York,NY,USA:ACM,2010:183-194.
[29]ZANE F,NARLIKAR G,BASU A.CoolCAMs:Powerefficient TCAMs for forwarding engines[C]//INFOCOM 2003.Twenty-Second Annual Joint Conference of the IEEE Computer and Communications.IEEE Societies.[s.l.]:IEEE Conference Publications,2003(2):42-52.
[30]ZHENG K,HU C,LU H,et al.A TCAM-based distributed parallel IP lookup scheme and performance analysis[J].IEEE/ACM Transactions on Networking,2006,14(4):863-875.
[31]LU W,SAHNI S.Low power TCAMs for very large forwarding tables [J].IEEE Transactions on Networking,2010,18(3):948-959.
[32]DHARMAPURIKAR S,KRISHNAMURTHY P,TAYLOR D E.Longest prefix matching using Bloom filters[C]//Proceedings of the 2003 conference on Applications,technologies,architectures,and protocols for computer communications.New York,NY,USA:ACM,2003:201-212.
[33]HASAN J,CADAMBI S,JAKKULA V,et al.Chisel:A storage-efficient collision-free hash-based network processing architecture[C]//Proceedings of the 33rd annual international symposium on Computer Architecture.New York,NY,USA:ACM,2006:203-215.
[34]YU H,MAHAPATRA R,BHUYAN L.A hash-based scalable IP lookup using Bloom and fingerprint filters[C]//Proceedings of the 17th annual IEEE International Conference on Network Protocols,2009.[s.l.]:IEEE Conference Publications,2009:264-273.
[35]BORDER A,MITZENMACHER M.Using multiple hash functions to improve IP lookups[C]//Proc INFOCOM.[s.l.]:IEEE Conference Publications,2001(3):1456-1463.
[36]SONG H,HAO F,KODIALAM M,et al.IPv6 lookups using distributed and load balanced bloom filters for 100Gbps core router line cards[C]//IEEE INFOCOM 2009 Proceeding.[s.l.]:IEEE Conference Publications,2009:2518-2526.
[37]BANDO M,CHAO H J.FlashTrie:hash-based prefixcompressed trie for IP route lookup beyond 100Gbps[C]//INFOCOM’01 Proceedings of the 29th conference on Information. Piscataway, NJ, USA:IEEE Press,2010:821-829.
[38]SRINIVASAN V,VARGHESE G.Fast address lookups using controlled prefix expansion[J].ACM Transactions on Computing Systems,1999,17:1–40.
[39]DEGERMARK M,BRODNIK A,CARLSSON S,et al.Small forwarding tables for fast routing lookups[C]//SIGCOMM '97 Proceedings of the ACM SIGCOMM '97 conference on Applications,technologies,architectures,and protocols for computer communication.New York,NY,USA:ACM,1997:3-14.
[40]EATHERTON W,VARGHESE G,DITTIA Z.Tree bitmap:Hardware/software IP lookups with incremental updates[J].ACM SIGCOMM Computer Communications.Review,2004,34(2):97-122.
[41]SONG H,TURNER J,LOCKWOOD J.Shape shifting tries for faster IP lookup[C]//ICNP’05 Proceeding of the 13th IEEE International Conference on Network Protocols.Woshington,DC,USA:IEEE Computer Society,2005:358-367.
[42]KUMAR S,TURNER J,CROWLEY P,et al.HEXA:Compact data structures for faster packet processing[C]//ICNP’07 Proceeding of the 15th IEEE International Conference on Network Protocol.Washington,DC,USA:IEEE Computer Society,2007:246-255.
[43]SONG H,KODIALAM M,HAO F,et al.Scalable IP lookups using shape graphs[C]//ICNP’09 Proceeding of the 17th IEEE International Conference on Network Protocol.Washington,DC,USA:IEEE Computer Socie-ty,2009:73-82.
[44]HUANG K,XIE G,LI Y,et al.Offset addressing approach to memory-efficient IP address lookup[C]//IEEE INFOCOM Mini-Conference.Shanghai:IEEE Conference Publications,2011:306-310.
[45]BASU A,NARLIKAR G.Fast incremental updates for pipelined forwarding engines[J].IEEE/ACM Transactions on Networking(TON),2005,13(3):690-703.
[46]HASAN J,VIJAYKUMAR T N.Dynamic pipelining:Making IP lookup truly scalable[C]//Proceedings of the 2005 conference on Applications,technologies,architectures,and protocols for computer communications.New York,NY,USA:ACM,2005:205-216.
[47]BABOESCU F,TULLSEN D M,ROSU G,et al.A tree based router search engine architecture with single port[C]//Proceedings of the 32nd annual international symposium on Computer Architecture. New York,NY,USA:ACM,2005:123-133.
[48]KUMAR S,BECCHI M,CROWLEY P,et al.CAMP:Fast and efficient IP lookup architecture[C]//Proceedings of the 2006 ACM/IEEE symposium on Architecture for networking and communications systems.New York,NY,USA:ACM,2006:51-60.
[49]JIANG W, WANG Q, PRASANNA V K.Beyond TCAMs:An SRAM-based Parallel multi-pipeline architecture for terabit IP lookup[C]//INFOCOM,2008.The 27th Conference on Computer Communications.IEEE.Phoenix,AX:IEEE Conference Publications,2008:1786-1794.
[50]FU J,REXFORD J.Efficient IP address lookup with a shared forwarding table for multiple virtual routers[C]//CoNEXT'08 Proceedings of the 2008 ACM CoNEXT Conference.New York,NY,USA:ACM,2008.
[51]SONG H,KODIALAM M,HAO F,et al.Building scalable virtual routers with trie braiding[C]//INFOCOM'10 Proceedings of the 29th conference on Information communications.Piscataway,NJ,USA:IEEE Press,2010:1442-1450.
[52]LE H,GANEGEDARA T,PRASANNA V K.Memoryefficient and scalable virtual routers using FPGA[C]//Proceedings of the 19th ACM/SIGDA international symposium on Field programmable gate array.New York,NY,USA:ACM,2011:257-266.
[53]LUO L,XIE G,XIE Y,et al.A hybrid IP lookup architecture with fast updates[C]//2012 Proceedings IEEE INFOCOM. Orland:IEEE ConferencePublications,2012:2435-2443.
[54]LUO L,XIE G,UHLIG S,et al.Towards TCAM-based scalable virtual routers[C]//Proceedings of the 8th international conference on Emerging networking experiments and technologies.New York,NY,USA:ACM,2012:73-84.
[55]LUO L,XIE G,SALAMATIAN K,et al.A trie merging approach with incremental updates for virtual routers[C]//IEEE INFOCOM,2013.(Accepted)
[56]WANG Y,HE K,DAI H,et al.Scalable name lookup in NDN using effective name component encoding[C]//Proceedings of the 2012 IEEE 32nd International Conference on Distributed Computing Systems.Washington,DC,USA:IEEE Computer Society,2012:688-697.
[57]YUAN H,SONG.T.CROWLEY P.Scalable NDN forwarding:Concepts,issues,and principles[C]//Computer Communications and Networks(ICCCN),2012 21st International Conference on.[s.l.]:IEEE Conference Publications,2012.
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
课程教育研究(2021年23期)2021-04-13
综艺报(2020年21期)2020-11-30
英语文摘(2020年1期)2020-08-13
作文小学高年级(2020年5期)2020-06-03
疯狂英语·新悦读(2019年12期)2020-01-06
电脑爱好者(2019年17期)2019-10-30
广东技术师范大学学报(2016年5期)2016-08-22
中国市场(2016年45期)2016-05-17
红领巾·成长(2016年7期)2016-05-14
