
互联网可扩展路由研究与分析
2013-09-20 08:19:38徐明伟
重庆邮电大学学报(自然科学版) 2013年1期
徐明伟,李 清
(1.清华大学计算机科学与技术系,北京 100084;2.清华信息科学与技术国家实验室(筹),北京 100084)
0 引言
自上个世纪70年代诞生之日起,互联网飞速发展,现已经成为全球性的商业网络平台。据统计,当前互联网终端数量已经从上个世纪80年代初的几百增长到2012的近10亿;而用户数量也从最初的几百增长到2012的近25亿[1]。此外,随着移动终端(手机、平板电脑等)的加入,互联网将得到进一步发展。然而随着规模的膨胀,互联网面临越来越多的问题:安全问题、节能问题、扩展问题等。其中,当前互联网路由系统面临严重的可扩展问题已经成为广泛的共识[2]。
互联网路由系统主要由2部分组成:域间路由和域内路由。当前主流的域间路由协议为边界网关协议(border gateway protocol,BGP);主流的域内路由协议为开放最短路径优先协议(open shortest path first,OSPF)和中间系统到中间系统路由协议(intermediate system to intermediate system routing protocol,ISIS)。BGP路由器通过路由通告完成域间路由的传播,通过屏蔽自治域的拓扑信息,BGP可以控制域间路由信息的规模。然而,由于多宿主(multihoming)、流量工程(traffic engineering,TE)等原因,越来越多不可聚合的提供商独立(provider independent,PI)地址通过BGP注入到全局网络中。这直接导致核心网路由表急剧增加,使互联网路由系统面临严重的可扩展性问题。图1显示了1994-2012年互联网骨干网络路由表的增长情况:1994年的骨干网路由表仅包含不到2万条表项;2012年这个数字已经超过40万[3]。随着IPv6的逐渐部署,被网络地址转换等技术抑制的地址会得到释放,可能会进一步加剧互联网路由可扩展性问题。

图1 互联网骨干网络路由表增长Fig.1 Growth of routing tables in the core internet
互联网路由可扩展性问题主要体现在两方面:控制平面的路由信息交换和数据层面的数据包转发[4]。如图2所示,核心网路由器一方面要处理全网的路由更新,另一方面需要存储全局转发表用以实现数据包的转发。首先,BGP路由器通过路由通告(更新)完成全局路由的传播。随着网络规模及路由条目(即目的前缀数量)的增加,控制平面的路由更新急剧增加。据相关资料显示,高峰时段路由器每秒可能收到上百条路由更新[3]。这给路由器带来巨大的处理负担。其次,路由表增大直接导致路由器的存储负担加重。转发信息表(forwarding information base,FIB)用于数据层面的数据包转发,对速度要求很高,因此,一般用昂贵的三态内容关联存储器(ternary content addressable memory,TCAM)存储,存储代价难以接受。此外,庞大的路由表会导致查询速度降低,从而影响数据转发速度。

图2 互联网路由器基本模型Fig.2 Basic model of internet routers
1 可扩展路由研究概述
1.1 路由可扩展性原因分析
针对互联网路由可扩展问题,学术界和工业界都展开了积极的研究。互联网架构委员会(internet architecture board,IAB),互联网工程任务组(internet engineering task force,IETF)及互联网研究任务组(internet research task force,IETF)等对该问题展开了深入的研究;网络设备巨头Cisco和Juniper也针对该问题提出了相关方案;JSAC(IEEE journal on selected areas in communications)在2010年出版了一期关于可扩展路由的专刊。经过近年的深入研究,学术界和工业界对导致路由可扩展问题的原因有了比较统一的认识。在文献[2]中,作者总结了几个原因:IP语义重载、多宿主、流量工程、不合理的地址分配等。
1)IP语义重载。IP语义重载是导致互联网路由可扩展性的根本原因之一。在当前的互联网中,IP地址既作为标识(identifier,ID)用来代表主机,又作为定位符(locator,Loc)用来标识位置并实现路由。这导致当前互联网对移动性、多宿主等需求缺乏灵活的应对方案。由于IP地址作为标识,当主机移动或实现多宿主时无法全部使用提供商指定(provider assigned,PA)地址,从而引入无法聚合的PI地址。虽然IP语义重载对路由可扩展的影响是间接的,但是同时这种影响也是根本的。如果能够打破IP语义重载,自然能够有效解决路由可扩展性问题。
2)多宿主。80年代网络规模很小,多宿主亦不常见。90年代多宿主兴起,那时采用的多宿主方法一直沿用至今,即每个多宿主网络(或主机)通过多个网络提供商(internet service provider,ISP)网络链接到互联网。对某些ISP而言,该多宿主网络的地址块是不可聚合的PI地址,会随着BGP路由通告扩散到全网,从而导致路由表的急剧增长。
3)流量工程。为了实现负载均衡等目的,有自治域(autonomous system,AS)网络会将前缀切分成更小的地址块通告出去,通过这种方式实现对流量的精确控制。这也导致更多的前缀被注入到网络中,加剧了路由可扩展性问题。
4)不合理的地址分配。由于历史原因,IPv4早期分配没有考虑到地址空间的不足。当前,有些企业无法获得足够大的连续地址块,只能申请多个不可聚合的地址块,这也导致了核心网路由表的增长。
在文献[5]中,作者针对导致路由表增长的几个因素做出相关研究和分析。结果表明,流量工程和多宿主导致路由表增长影响最大,分别贡献了路由增长的20% ~30%和20% ~25%。而且,这2个因素的对路由表增长的作用还在逐年加剧。
1.2 可扩展路由解决方案概述
下面对当前的研究现状进行简要的分类介绍,分类方式如图3所示。

图3 互联网可扩展路由研究方案分类Fig.3 Classification of internet routing scalability solutions
如前文所述,IP语义重载导致网络实现多宿主等需求时产生不可聚合的PI地址。因此,解决方案之一是通过消除IP地址语义重载来增强互联网路由的可扩展性。代表的解决方案包括Shim6[6],HIP(host identifier protocol)[7],INLP(identifier locator network protocol)[8]等。这些方案通过在主机端实现ID/Loc的分离,消除了IP语义重载,因此也被称为消除方案(elimination solutions)。此类方案大大增强了网络对多宿主、移动性等的支持,避免产生无法聚合的PI地址碎片。
从控制平面来看,无论是多宿主还是流量工程,都会通告更详细的前缀,并将相关路由扩散到核心网中。因此,解决路由可扩展性问题可以通过将边缘/核心网络地址隔离来实现。这类方案将边缘网络和核心网络彻底隔离,通过引入映射系统完成边缘网络地址到核心网络地址的映射。在数据包进入或离开核心网时,都需要进行地址转换。这类方案在2010年之前是可扩展路由研究的主流方向,有大量方案被提出,主要代表有 Encaps[9],LISP[10],APT[11],SIX/ONE[12],MILSA[13]等。
目前,路由的动态性,即控制层面的开销还是可以接受的,因为当前路由器的计算能力还是足够的;而且,路由表动态性的加剧速度远远不及路由表大小的增长速度。路由可扩展问题中亟待解决的一个问题是FIB膨胀的问题。原因如下:首先,转发表一般用昂贵的TCAM存储,按照路由表增长的速度来升级相关硬件会给网络服务提供商(internet service provider,ISP)带来巨大的运营成本;其次,为了实现线速转发,TCAM每次IP地址查询需要读取所有的存储单元,过大的路由表带来巨大的能量消耗。此外,上述的解决方案对网络改动较大,无法在短期内解决ISP降低运行成本的需求。因此,越来越多的研究人员开始关注路由聚合,代表方案包括ORTC[14],IFTA[15],SMALTA[16],Level 1-4 FIB 聚合[17],ViAggr[18],NSFIB 聚合[19-20],RIB 聚合[21]等。
以上所有方案都有一个基本前提:基于当前的IP网络。然而,当前的互联网路由体系结构,在设计之初并未考虑到当前可能出现的诸多问题(包括可扩展性),具有一定的局限性。因此,针对当前网络进行“修补”无法解决根本问题,需要用新的网络体系结构来解决当前面临的问题。基于这个目标,紧凑路由(compact routing)[22-23]和地理信息路由(geographic routing)[24-25]等非IP路由协议被提出用以替换当前互联网的路由系统。
在下文中,将主要针对前3个研究方向,即基于主机的ID/Loc分离、边缘/核心网络地址分离和路由聚合,进行详细讨论。
2 基于主机的ID/Loc分离
基于主机的ID/Loc分离方案是在主机端消除IP语义重载,因此也被称为消除方案。IP语义重载消除的直接效果是网络在实现多宿主时不再产生不可聚合的PI地址碎片,从而消除多宿主等对路由可扩展性的影响。本节,主要讨论此类方案中的3个典型方案:Shim6[6],HIP[7]和 ILNP[8]。
2.1 Shim6 协议
用户网络(主机)可以通过接入多个ISP以提高网络的可靠性和服务质量,但却造成ISP核心路由表的膨胀(PI地址);为了避免这个问题,用户网络(主机)必须维护多个ISP分配的PA地址,这又给用户造成了极大的不便。这就是多宿主在当前的互联网中面临的困境,为此IETF组织了Shim6工作组来解决这个问题。
2.1.1 Shim6 简介
Shim6协议是一个主机多宿主解决方案,其目标是在不产生PI地址的前提下更好地支持多宿主,从而消除多宿主对路由可扩展性的影响。Shim6的主要思想是:在主机网络层和传输层之间插入一个新的Shim6子层,该子层把IP地址的双重语义分割开来。在Shim6子层之上的应用层使用一个不变的上层协议标识符(upper layer identifier,ULID);在Shim6子层之下的网络层使用多个Loc,从而在不引入PI地址的情况下实现多宿主功能。Shim6不会为上层的ULID另外创造一个地址空间,而是在下层的Loc中选择一个作为ULID。上层协议初始化ULID之后,即便下层的Loc变化,ULID也不会再变(至少在会话期间)。Shim6负责将多个Loc映射到一个ULID,供上层协议和应用使用。Shim6子层维护ULID对状态,每一对ULID是上层应用公用的。而且,在通信的两端这种映射是一致的。这样,上层协议及应用看到的就是基于ULID间的端到端通信。图4描述了Shim6在协议栈中的位置。Shim子层扩展的部分(如图4所示的AH,ESP等)在此不再详细讨论。
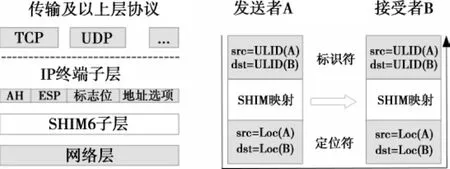
图4 Shim6协议示意图Fig.4 Sketch map of Shim6
2.1.2 Shim6 通信流程
以上讨论了 SHIM6的基本概念,下面介绍SHIM6的通信流程,主要通过以下8点予以概括。
1)主机A上的某个应用决定与主机B上的某个应用通讯(通过某个上层协议ULP)。主机A上的ULP发送数据包给B,完成通讯初始化过程。在这个过程中Shim子层并不参与。
2)主机A或B(或者二者都)通过探索决定要用Shim6,虽然引入一定的通讯开销,但是可以增强端到端通讯的可靠性(当Loc失效时)。例如,这个探索过程可能是已经收到或发送有50个数据包,或者发生了超时。Shim初始化是上下文建立的过程,这样做是为了避免2个主机间只有少量的数据包需要交换,那么Shim的代价就很高了。在这个过程中,A和B都会获得对方的多个Loc。如果这个过程失败了,那么至少有一方不支持Shim6,这个通讯就退化为标准的IP通信过程。
3)在接下来的通信过程中,ULP数据包不会变化,也就是说不会添加Shim6扩展头部(此时ULID=Loc)。当然,Shim6子层可能会通过交换消息检测可达性。
4)故障发生时(Shim6或ULP发现),主机A或主机B(或二者都)要探测另外一个可选的Loc,直到发现另外一个可用的Loc对。
5)此时,Shim6子层会给ULP数据包添加Shim扩展头部,其中包含对方的上下文标签。接受当可以利用上下文标签找到对应的上下文状态,从而按照正确的方式替换IPv6中的地址,并将处理后的数据包交给ULP。
6)Shim子层会监视新的Loc对。
7)除了扩展检测之外,某个主机也会通过某种方式发现自己的某个Loc失效,此外该主机可以通过Shim子层主动告知对方该故障。
8)当Shim认为某个上下文状态不会再被使用,它会负责回收该状态。
2.1.3 性能分析
以上描述主要是从多宿主支持的角度进行的。如果从可扩展性的角度讲,Shim6使每个多宿主主机可以使用多个PA地址(Loc)。这些地址可以被对应ISP的前缀聚合,因此,不会向核心网注入新的地址,从而增强了互联网路由的可扩展性。然而,获得此扩展性的代价是Shim6扩展带来的通信开销、Shim6子层的状态维护等。
此外,Shim6主机和不支持Shim6的主机通信会退化到没有Shim6的标准通信方式。Shim6具有很强的局限性,因为它只是对多宿主导致的可扩展性问题有效。其他因素,如主机移动带来的renumbering,仍然会导致路由可扩展性问题。而相比之下,ILNP[12]的解决就更加全面。
2.2 Host identifier protocol(HIP)
在传统的互联网协议体系中,IP地址承担双重角色:ID和Loc。这使得主机移动和应用多宿主时产生不可聚合的PI地址,导致路由可扩展性。另外,因为缺乏地址认证方式,当前互联网面临严重的安全问题(如地址欺骗)。
为了解决上述问题,主机标识协议(host identifier protocol,HIP)引进一个新的命名空间:主机标识(host identifier,HI)空间。网络层的任何变化(多宿主、移动等导致的IP地址变化)不会影响传输层。IP地址在HIP中,有2种主机标识表示方法:HI和HIT(host identifier tag)。HI是主机的一个公/私钥对的公钥。由于存在不同的加密算法,因此,HI可能具有不同的长度,不适合用作数据包标识或表索引。HIT,作为HI的128位定长哈希,被引入用来替代HI。
HIP协议层位于应用层和传输层之间,完成HI与IP地址之间的转换:传输层使用<HI,端口>,而不是<IP,端口>;网络层依然用IP地址进行路由。HI和IP地址通过动态绑定的方式实现,这样IP地址改变之后只需要通过HIP层进行重新绑定即可,不会对应用层产生影响。
从扩展性的角度讲,HIP协议和Shim6类似,都是通过逻辑上分离ID/Loc,使互联网对多宿主的支持不再需要产生不可聚合的PI地址。
2.3 Identifier locator network protocol
当前互联网面临诸多需求,移动性、多宿主、网络地址翻译是其中的3个需求。由于IP地址语义重载,导致当前的互联网对这些网络(用户网络)需求支持不好,从而导致互联网路由可扩展性。IP地址意义重载指的是IP地址既作为ID标识主机,又作为Loc标识位置,也就是说IP地址蕴含了拓扑信息。1)移动性。一个节点的移动就需要换个IP地址以反映这种位置的改变(renumbering)。但是IP本身还被当作主机ID,用在应用程序中。为了保证应用的延续性,IP地址无法改变,这样该主机就会向新的网络注入不可聚合的PI地址。2)多宿主。80年代网络规模很小,多宿主亦不常见。90年代多宿主兴起,那时采用的多宿主方法一直沿用至今,即每个多宿主的网络(或主机)需要其提供商为其通告一个PI前缀(地址)。这个前缀(地址)很难聚合,会随着BGP路由通告扩散到全网中,从而导致路由表的急剧增长。虽然转发速度通过引入基于ASIC的转发引擎得以解决,然而,大家依然担心路由表在大小方面的承受能力是很有限的。3)网络地址翻译。虽然NAT和路由可扩展性不是直接相关的,但是,NAT能够延长IPv4地址的寿命并将大量的主机地址从全局网络隔离,因此也间接地影响着互联网路由可扩展性。
ILNP目标是使互联网更好地支持移动性、多宿主及NAT,尤其是使前2个需求不再产生无法聚合的PI地址,从而增强互联网路由的可扩展性。在文献[12]中,作者以IPv6作为基础,提出了ILNPv6机制,并分析了该机制对移动性、多宿主及NAT的支持;同样的思想也可以用在IPv4网络中。
ILNPv6的关键思想是对IPv6地址进行重新编址,并借助DNS来完成地址查询和更新,而在这个过程中Identifier保持不变。在ILNPv6中,地址被分为两部分:64位的Loc和64位的Identifier。Identifier用来标识一台主机;Loc用来标识其位置。网络层路由协议几乎不用改动,最大的变动发生在主机端。这也是此类方案共同面临的问题:大批网络应用将无法在ILNP的框架下运行。
虽然ILNP宣称并未改变IP语义重载,即IP地址仍然既包含Loc又包含Identifier,但是,逻辑上ILNP还是打破了“重载”,因为ILNP中Loc和Identifier是相互独立的,不存在“重”的问题。此外,IPv6地址能够分为两部分:Identifier和Loc,而IPv4地址本身只有32位,因此无法拆分。所以,ILNPv4只能借助2套地址,这种情况下也打破了IP语义重载。
此外,IPv4下,DNS还能如IPv6下那样完成ILNP需要的功能吗?这一点很值得怀疑。
2.3.1 移动性支持
首先我们讨论一下ILNP对移动性的支持。当一台主机从一个子网移动到另一个子网时,该节点首先要向全网更新其新的Loc。在ILNPv6中,这一功能主要通过扩展DNS来实现。在MIP中,这一过程等价于移动后的主机通知家乡代理其当前位置。不同于MIP的是,新的连接可以直接被定位到当前的Loc,不需要家乡代理来做间接转发。在这个过程中,主机的Identifier不用改变,运行中的应用程序只要向对端发送一个经认证的Loc更新消息,这样可以在移动后保持通信状态。
2.3.2 多宿主支持
下面介绍ILNP对多宿主的支持。这一点类似于ILNP对移动性的支持:一个子网可以使用多个Loc。这种方法同样适用于站点、一组节点或单个节点的多宿主支持。但是,多个Loc仅仅用于标识位置和路由,应用层不会用到Loc相关的信息,因此不会破坏网络主机对保持统一Identifier的需求。
2.3.3 NAT 支持
在ILNP中,NAT功能仅仅改变Loc的值,对应用层而言,这个改变是不可见的。因此,在传统NAT中不可用的协议,如FTP,P2P等,在ILNP的NAT中可以实现完美支持。
3 边缘/核心网络分离
互联网面临的路由可扩展性问题主要是因为所有的网络都采用同一个地址空间,这样导致了边缘网络增长会传播到核心网络。因此,边缘/核心网络地址分离能够阻止边缘网络地址影响核心网络路由系统,从而增强路由可扩展性。在2010年之前,这类方案一直是路由可扩展性的主流研究方向。
R.Hinden[9]在 1996 年第一次提出了通过封装实现边缘/核心网络地址的分离,即ENCAPS机制。该机制基本确立了边缘/核心网络地址分离的基本方法,即通过映射机制及边界路由器实现这种转换。虽然只提出了简单的思想,并没有给出详细的工作机制,但是,ENCAPS的重大意义在于开创了边缘/核心网络地址分离的研究方向。紧随其后,有大量的方案被提出,包括 LISP[10],APT[11],SIX/ONE[12],MILSA[13]等。这些方案在原理上大同小异,因此在本节中,我们将忽略具体方案,而主要将该类方案的统一模型及当前的研究情况作出简单的介绍。
首先介绍一下该类方案涉及到的相关概念。核心网络和边缘网络两部分组成整个网络系统,对应的地址系统也分为两部分:边缘网络地址和核心网络地址。地址映射系统(mapping system)维护全局的边缘/核心地址映射关系。边缘网络地址虽然只出现在边缘网络中,但是一般也是全局唯一的。数据包在进入或离开核心网时都需要进行地址转换:进入核心网时由入口路由器完成转换;离开核心网时有出口路由器完成转换。图5是一个简单的例子。
当数据包进入核心网络时,入口路由器向映射系统查询源(边缘)地址和目的(边缘)地址对应的核心网络地址,然后通过封装(隧道)或翻译(地址重写)的方式将数据包发送到目的网络的出口路由器。如果采用的是封装的方式,当数据包到达出口路由器时,只需要解封装就可以还原该数据包。因此,数据包离开核心网时不需要查询映射系统。在这种情况下,一个核心网地址可以对应多个边缘网络地址,因为不需要用核心网络地址来查询对应的边缘网络地址。如果采用的是翻译的方式,一个核心网络只能映射到一个边缘网络地址。这样才能够保证出口路由器能够根据重写后的地址(核心网络地址)查询映射系统,从而还原目的(边缘)地址。

图5 边缘/核心网络地址分离方案模型Fig.5 Sketch map of edge/core network address separation solutions
边缘/核心网络地址分离实际上是将网络可扩展性从路由系统转移到了映射系统。因此,如何设计一个可扩展的映射系统是此类方案要解决的一个重要问题。因此,在这方面也有很多方案被提出,如LISP-DHT[26],LISP-ALT[27]等。但是,目前还没有被广泛接受的统一方案。
4 路由聚合
以上方案,包括基于主机的ID/Loc分离和边缘/核心网络地址分离方案,都有一个共同的问题:对当前互联网改动较大,因此,无法在短期内大范围部署。而当前网络服务提供商当前面临核心网路由表过大导致运营成本不断上升的问题,尤其是转发表(forwarding information base,FIB)存储在昂贵的TCAM中,给运营商带来巨大的负担。因此,ISP迫切需要立即可以投入使用的短期方案,在以上长期方案得到大范围部署之前,这些短期方案可以用来减轻ISP的负担。
在展开讨论之前,首先介绍本节涉及的基本符号。IP前缀用0/1串附加*表示,如前缀1101*表示覆盖所有起始4位为1101的IP地址。
4.1 虚拟聚合
为了迅速有效地减小路由表(尤其是FIB),2009 年,H.Ballani等[18]提出虚拟聚合方案(virtual aggregation,ViAggr)。VA有2个设计目标:1)不改变路由软件和路由协议;2)对外部网络透明。目的只有一个,提高ViAggr的可部署性。
传统互联网路由系统中,每个路由器都存储所有目的前缀的路由信息。这样,收到任意数据包,该路由器都知道准确的下一跳。在ViAggr中,每个路由器不需要保存全部前缀的路由信息。通过虚拟前缀的方式,如00*,01*,10*及11*。将整个路由空间分为少数子空间。对于每个虚拟前缀,都有相应的聚合点(aggregation point,AP)负责保存相关路由信息。下面,我们从两方面介绍ViAggr的原理。1)控制平面。当邻居自治域想本自治域通告路由时,通过路由反射的方法将路由发送给相应的AP。AP向域内其他路由器通告一条虚拟前缀路由即可。其他路由器只保存到AP的相关路由,总数为虚拟前缀的数量。2)数据平面。当数据包进入本自治域时,入口路由器I如果不是对应的AP,那么I通过隧道将该数据包发送到相关AP。该AP收到该数据包后,解封装,然后根据全局路由表查询出口路由器,同样通过隧道的方式将数据包发送到出口路由器。出口路由器收到该数据包,解封装后将该数据包发送到下一个自治域。图6是ViAggr数据转发实例。

图6 ViAggr数据包转发实例Fig.6 Instance of data transmission in ViAggr
虽然由于配置方面的代价,ViAggr还没有实现大规模部署,但是ViAggr的出现使可扩展路由的研究热点逐渐转移到短期的聚合方案。在ViAggr之后出现了大量的FIB聚合方案。
4.2 传统FIB聚合
ORTC(optimal routing table constructor)是最早系统研究FIB聚合的方案[14]。给定一个FIB,ORTC能够计算出具有等价转发行为的最小FIB。ORTC的计算过程包含3步。
1)“标准化”。将ORTC所有的非空内部节点分裂到叶子,同时保证转发行为不变。如图7a所示,根节点是唯一的非空内部节点,分裂后的结果如图7b所示。
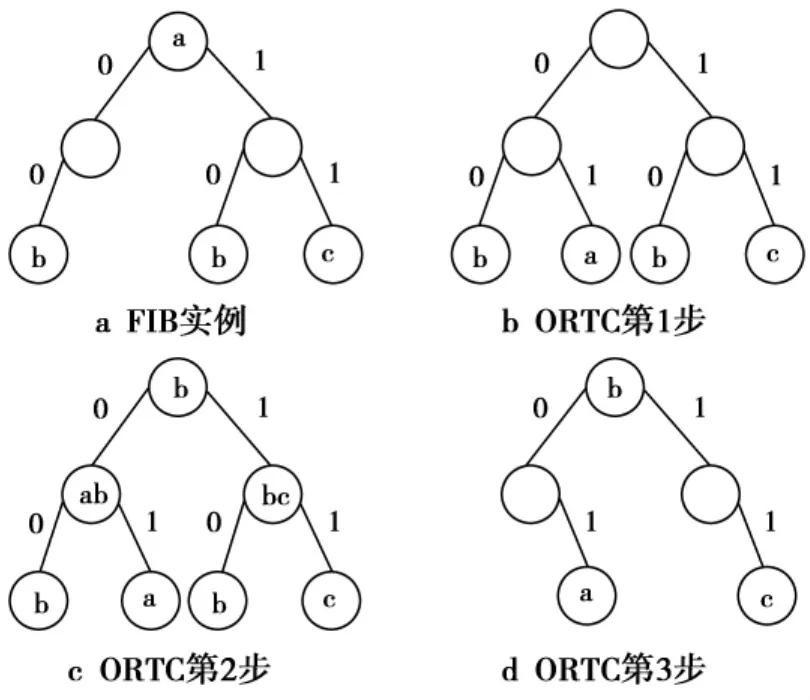
图7 ORTC计算步骤Fig.7 Steps of ORTC
2)自底向上计算最流行下一跳。图7c为计算的结果。
3)根据计算的结果从上到下实现聚合。图7d为聚合之后的结果。可以看出,根据最长前缀匹配原则,聚合之后的FIB和初始的FIB具有相同的转发行为。
ORTC虽然能够计算出最小的FIB,但是ORTC有2个问题:1)空间开销过大,其复杂度为O(WN),其中O为复杂度上限;N为FIB前缀数量;对IPv4而言,W=32;2)没有高效的在线更新算法。因此,IFTA[15]和 SMALTA[16]被提出用来弥补 ORTC 的不足。IFTA和SMALTA的基本思想是一致的:牺牲最优聚合换取算法效率的提高。IFAT和SMALTA都采用了非最优的算法来实现更新,每一次更新可能会使聚合结果偏离最小FIB。当结果偏离最小FIB一定程度或处理了一定数量的更新之后,重新调用ORTC恢复最小FIB。
另外,X.Zhao等[17]在 2010 年提出 Level 1-4 FIB聚合。从Level 1到Level 4,聚合效果逐渐增强,算法复杂度也逐渐提高。相比ORTC,Level 1-4 FIB聚合将聚合对象限制为Trie(一种树形结构,用于路由表存储)中的子树,子树最多3层。这样,路由更新的影响可以限制在很小的范围内,从而提高更新效率。Level 1 FIB聚合:将和父亲前缀下一跳一致的孩子前缀聚合;Level 2 FIB聚合:如果Trie中存在下一跳一致的兄弟前缀,那么通过插入其父亲前缀将这2个前缀聚合,如图8a所示;Level 3 FIB聚合:和Level 2类似,只是将范围扩大到3层子树中,如图8b所示;Level 3 FIB聚合:比Level 3更进一步,如图8c所示。

图8 Level 2-4 FIB聚合方案示例Fig.8 Sketch map of level 2-4 FIB aggregation
传统的FIB聚合方案具有2点重要特征:1)FIB聚合方案支持路由器级别的增量部署。也就是说,任何一个路由器可以根据需求部署FIB聚合方案,不需要任何其他路由器的配合。比如ViAggr在AS级别的可增量部署,这是一个巨大的进步;2)FIB聚合方案不改变路由和转发行为。这一点保证了部署FIB聚合方案的路由器不会对其他路由器或AS产生任何影响。在这两点中,尤其以第一点更为重要。
然后,FIB聚合也存在一些问题:1)FIB聚合定位为短期的解决方案,主要目标是为长期解决方案争取足够的时间,缓解路由表增大为ISP带来的巨大压力。因此,FIB聚合并不能从根本上解决路由可扩展性问题,只能起到缓解的作用;2)传统FIB聚合方案在大规模高密度的网络中,性能比较差。具体原因如下:随着邻居数量的增大,2个前缀具有相同下一跳的概率降低,聚合的概率也随之降低。而实际上,正是大规模的核心网络迫切需要压缩FIB表。
4.3 NSFIB 聚合
针对传统FIB聚合方案存在的问题,Q.Li等在文献[19-20]中提出了可选择下一跳FIB(nexthopselectable FIB,NSFIB)聚合方案。该方案打破了传统FIB聚合中每个前缀只有一个下一跳的限制,通过定义严格偏序(strict partial order,SPO)下一跳,为每个前缀构建多个可选下一跳,从而形成NSFIB;并在此基础上通过动态规划算法,实现了NSFIB聚合算法。图9显示了NSFIB聚合机制。对比图2显示的路由器模型,NSFIB主要引入2个需要解决的问题:NSFIB构造算法和NSFIB聚合算法。

图9 NSFIB聚合机制Fig.9 NSFIB aggregation scheme
NSFIB聚合能够大幅度地提升聚合的效果,根据实验显示,NSFIB可以将 FIB聚合到原来的10% ~20%。此外,相比传统FIB聚合,NSFIB聚合效果屏蔽了网络密度的影响:即性能不会随着网络度数的增加而降低。然而,作为一个全新的聚合方案,NSFIB聚合同样存在一些问题。首先,NSFIB聚合引入非最优下一跳,不可避免地导致路径拉伸。针对这个问题,作者提出了限制下一跳数量的方法,从而有效控制路径拉伸。其次,NSFIB聚合导致流量不可预测,给流量工程等带来一定的困难。
4.4 RIB 聚合
除了 FIB聚合之外,RIB(routing information base)聚合也是一个可以有效压缩路由表的方案。RIB聚合主要有2种方式:压缩通告路由和压缩本地路由。
压缩通告路由:通过配置的聚合路由,减少向邻居AS通告的前缀数量。假设自治域A有192.168.1.0/24,192.168.2.0/24 和 192.168.3.0/24 等路由,对邻居自治域B配置如下聚合路由:<192.168.0.0/16 A >。这样,A 只会向B 通告192.168.0.0/16路由(下一跳AS为A本身),被覆盖的路由都不需要通告。虽然这种路由聚合方式无法直接压缩本地路由表,但是广泛部署不仅能够有效减小核心网路由表的大小,还能将边缘网络的不稳定屏蔽在核心网之外。然而,这种聚合方式影响了域间路由行为,有潜在的问题:路由环路和路由黑洞等。在文献[28]中,作者针对这种聚合方式进行了详细的分析。
压缩本地路由:这种方法和FIB聚合类似,只是FIB聚合中针对具有相同下一跳的前缀,而此处的聚合针对的是具有相同下一跳AS的前缀。在文献[21]中,作者将NSFIB聚合的思想应用到本地路由压缩方案中,大幅度减小了路由表。然而,该方案打破了FIB聚合路由器级别增量部署的特性,失去了FIB聚合最大的优势。
5 总结与分析
本文总结了现存的主流可扩展路由方案并给出相关分析。从6个方面讨论了可扩展路由:解决/缓解路由可扩展性问题、路由表压缩效果、是否能抑制路由更新、是否支持增量部署,是否影响路由转发及是否改变路由协议。前3个因素反映性能,后3个因素反映代价。
如图3所示,虽然基于主机的ID/Loc分离方案[6-8]和边缘/核心网络地址分离方案[9-12]都能够解决路由可扩展性问题,然而这些方案都涉及路由协议的改变、对增量部署支持性较差且影响转发。1)基于主机的ID/Loc分离方案。此类方案需要扩展IP头部,导致转发的有效载荷降低;需要主机端升级,推广难度较大。2)边缘/核心网络地址分离方案。此类方案在转发过程中需要查询边缘网络地址和核心网络地址的映射关系,并完成2次转发,无法避免地会影响转发速度。根据IPv6的部署经验,短期内这些方案无法在互联网中得到实际应用,因此这些方案也被称为长期方案。
然而,当前互联网迫切需要解决路由表过大带来的成本上升、能耗过大等问题,因此,这给路由聚合[13-21]等短期方案提供了应用的空间。虽然这些方案只能缓解路由可扩展性问题,但是部署代价比较小,体现在:1)FIB聚合路由器级别的增量部署,虚拟聚合支持自治域级别的增量部署;2)不改变路由协议;3)传统FIB聚合不影响转发行为,虚拟聚合和NSFIB聚合只影响域内路由转发行为。因此,这些方案可以作为短期方案来缓解ISP的压力,为能够彻底解决问题的长期方案争取足够的部署时间。
[1]The Miniwatts Marketing Group.Top 20 Countries with the highest number of Internet users[EB/OL].(2012-12-01) [2012-12-03].http://www.internetworldstats.com/top20.htm.
[2]MEYER D,ZHANG L,FALL K.RFC 4984,Report from the IAB Workshop on Routing and Addressing[R].USA:IETF,2007.
[3]Huston Geoff.BGP analysis reports:BGP table statistics[EB/OL].(2012-04-01) [2012-11-13].http://bgp.potaroo.net.
[4]ELMOKASHFI Ahmed,KVALBEIN Amund,DOVROLIS Constantine.On the scalability of BGP:the role of topology growth[J].IEEE JSAC,2010,28(8):1250-1261.
[5]BU Tian,GAO Lixin,TOWSLEY Don.On characterizing BGP routing table growth[J].Computer Networks,2004,45(1):45-54.
[6]NORDMARK E,BAGNULO M.RFC 5533,Shim6:Level 3 Multihoming Shim Protocol for IPv6[R].USA:IETF,2009.
[7]MOSKOWITZ R,NIKANDER P,JOKELA P,et al.RFC 5201,Host Identity Protocol[R].USA:IETF,2008.
[8]ATKINSON Randall,BHATTI Saleem,HAILES Stephen.Evolving the internet architecture through naming[J].IEEE JSAC,2010,28(8):1319-1325.
[9]HINDEN R.RFC 1995,New Scheme for Internet Routing and Addressing(ENCAPS)for IPNG[R].USA:IETF 1996.
[10]LEWIS Darrel,FULLER Vince,FARINACCI Dino,et al.Locator/ID separation protocol(LISP),IETF Draft[R].USA:IETF,2009.
[11]JEN Dan,MEISEL Michael,YAN He,et al.Towards a new Internet routing architecture:Arguments for separating edges from transit core[C]//Soul.Proceedings of HotNets VII.Galgary:ACM Press,2008:1-6.
[12]VOGT Christian.Six/one router:a scalable and backwards compatible solution for provider independent addressing[C]//Soul.Proceedings of MobiArch '08.Seattle:ACM Press,2008:13-18.
[13]PAN Jianli,JAIN Raj,PAUL Subharthi,et al.MILSA:a new evolutionary architecture for scalability,mobility,and multihoming in the future internet[J].IEEE JSAC,2010,28(8):1344-1362.
[14]DRAVES R P,KING C,VENKATACHARY S,et al.Constructing optimal IP routing tables[C]//Soul.Proceedings of IEEE INFOCOM.New York:IEEE Press,1999:88-97.
[15]LIU Y,ZHAO X,NAM K,et al.Incremental forwarding table aggregation[C]//Soul.Proceedings of IEEE GLOBECOM.Miami:IEEE Press,2010:1-6.
[16]UZMI Zartash Afzal,NEBEL Markus,TARIQ Ahsan,et al.SMALTA:practical and near-optimal FIB aggregation[C]//Soul.Proceedings of ACM CoNEXT.New York:ACM Press,2011:1-12.
[17]ZHAO Xin ,LIU Yaoqing ,WANG Lan ,et al.On the aggregatability of router forwarding tables[C]//Soul.Proceedings of IEEE INFOCOM.Piscataway:IEEE Press,2010:848-856.
[18]BALLANI Hitesh ,FRANCIS Paul ,CAO Tuan,et al.Making routers last longer with ViAggre[C]//Soul.Proceedings of NSDI.Boston:USENIX Association,2009:453-466.
[19]LI Qing ,WANG Dan ,XU Mingwei,et al.On the scalability of router forwarding tables:Nexthop-selectable FIB aggregation[C]//Soul.Proceedings of IEEE INFOCOM.Shanghai:IEEE Press,2011:321-325.
[20]LI Qing,XU Mingwei,CHEN Meng.NSFIB construction& aggregation with next hop of strict partial order[C]//Soul.Proceedings of IEEE INFOCOM.Turin:IEEE Press,2013:1-5.
[21]WANG Yangyang,BI Jun,WANG Jianping .Towards an aggregation-aware internet routing[C]//Soul.Proceedings of ICCCN.Munich:IEEE Press,2012:1-7.
[22]KRIOUKOV Dmitri,FALL Kevin.Compact routing on internet-like graphs[C]//Soul.Proceedings of IEEE INFOCOM.Hong Kong:IEEE Press,2004:209-219.
[23]JAIN S,CHEN Y,ZHANG Z L,et al.VIRO:a scalable,robust and namespace independent virtual id ROuting for future networks[C]//Soul.Proceedings of IEEE INFOCOM.Shanghai:IEEE Press,2011:2381-2389.
[24]OLIVEIRA R,LAD M,ZHANG Beichuan,et al.Geographically informed inter-domain routing[C]//Soul.Proceedings of IEEE ICNP.Beijing:IEEE Press,2007:103-112.
[25]LI Taoyu ,ZHU Yuncheng ,XU Ke,et al.Performance model and evaluation on geographic-based routing[J].Comput Commun,2009:32(2):343-348.
[26]MATHY Laurent,IANNONE Luigi.LISP-DHT:towards a DHT to map identifiers onto locators[C]//Soul.Proceedings of ACM CoNEXT.Madrid:ACM Press,2008:1-6.
[27]FULLER Vince ,FARINACCI Dino,MEYER David,et al.LISP alternative topology(LISP+ALT)[R].USA:IETF Draft,2011.
[28]LE F,XIE G G,ZHANG H.On route aggregation[C]//Soul.Proceedings of ACM CoNEXT.Tokyo:ACM Press,2011:1-12.
猜你喜欢
有色金属科学与工程(2023年4期)2023-02-08 10:37:57
科学与生活(2021年32期)2021-01-17 23:17:58
湖北第二师范学院学报(2020年2期)2020-06-05 02:18:30
网络安全和信息化(2017年11期)2017-11-07 09:03:22
汽车零部件(2017年3期)2017-07-12 17:03:58
自动化博览(2017年2期)2017-06-05 11:40:39
电脑知识与技术(2016年14期)2016-06-30 20:29:18
电脑知识与技术(2016年12期)2016-06-14 19:38:04
现代工业经济和信息化(2016年12期)2016-05-17 05:38:00
无线互联科技(2016年5期)2016-05-16 03:16:06
