
基于规则的英汉商务信函语块提取研究
2013-09-12 07:57:54胡富茂
外国语文 2013年3期
胡富茂
(洛阳理工学院 外语系,河南 洛阳 471023)
1.引言
国内的语块研究越来越细致与深入,涉及的方面主要包括搭配研究(缪海燕、孙蓝,2005)、语块运用与英语口语和写作之间的关系研究(王立非、张岩,2006)、语块学习在二语习得中的地位研究(濮建忠,2003)、语块提取(李洁晶、赵晓临,2007;卫乃兴,2009;邢富坤,2012)等。语块是语言的半成品,以整体形式储存在大脑中,有较固定的语法结构限制和稳定的搭配意义,因此,在应用时具有快捷方便、准确流利的优势。此种言语程式或行话由于出现频率很高,并且形式和意义较固定,使用的语境也较固定,就像一个板块一样,如:cash on delivery(货到付款)、confirming your order(确认你方的订单)、accept your firm offer(接受你方的实盘)等。Sinclair(1991)认为:“那些出现频率高的词汇串成了英语中基本的语言单位,大约70%的英语语言由存储于人体大脑的语言板块构成”。“据电脑统计数据显示,像这些语义较固定的各类形式的语块在自然语言中占到90%的比例”(李太志,2006)。
本文提出了一种基于规则匹配的语块自动提取方案,通过自动在互联网上采集网页构建动态语料库,利用英汉商务信函语块的结构、意义和功能等方面的特征,将英汉商务信函语块分为全称缩略语块、惯用表达语块、专业术语语块三种类型,并制定英汉商务信函语块自动提取规则,最终实现从语料中自动提取英汉商务信函语块的功能。
2.构建动态语料库
语料库已成为语言学理论研究、语言学应用研究和语言信息处理不可缺少的基础资源。为了对英汉商务信函语块的语言学特点进行观察总结,同时进行基于规则的英汉商务信函语块提取,我们需要先构建一个规模足够大的语料库。显然,通过手工的方法下载分析成千上万的网页、提取语料信息是不可行的。因此,通过动态语料库构建的方式自动获取大规模的文本语料就显得尤为重要。
通过观察,我们发现随着互联网在信息传递中的地位越来越突出,很多报纸、期刊纷纷建立网站,以与纸质媒体同步的速度提供大量文献资料。这些文献资料大都结构规范一致,信息完整。这也为后期英汉商务信函语块的提取提供了方便。因此,我们希望对这些网站进行自动下载和分析,收集大量语料,构建英汉商务信函动态语料库。
从互联网上直接下载的语料是半结构化的,往往结构复杂,含有大量HTML语言标记,语料信息淹没在芜杂的网页标记中,不方便直接提取文本内容。我们采用基于网页结构分析的方法,通过HTML的起止标记来提取语料信息。HTML文档包括文本和标记,一条基本的标记语句形式为:
<标记名称 属性列表(参数列表)>[</标记名称>]
我们可以简单地把标记分为两类:包容标记和空标记。包容标记由一个开始标记和一个结束标记构成,中间是数据对象。空标记只有起始标记而没有结束标记。因此可以通过对网页中HTML标记的起止标记进行格式分析,判断标记的意义,提取其中有效的信息。我们以《中国日报(财经频道)》的英文官方网站“http://www.chinadaily.com.cn/business/”和中文官方网站“http://www.chinadaily.com.cn/hqcj/”为例,从网页自动下载和语料信息抽取两个方面来说明动态语料库的构建方法。
2.1 网页自动下载
首先,分析一下《中国日报(财经频道)》英文官方网站的特点,该网站提供的每一篇文献都有其单独的网页,网页地址中的编号简单递增(如 http://www.chinadaily.com.cn/business/2011-02/26/content_12082981.htm)。利用网页地址中编号的变化规律对网站进行爬取,就可以下载所有的文献网页。同样,《中国日报(财经频道)》中文网站提供的每一篇文献也都有其单独的网页(如http://www.chinadaily.com.cn/hqcj/gjcj/2011 -02 -24/content_1849755.html),网页地址中的编号简单递增。根据第一篇文献的网页地址向服务器发出HTTP请求,捕获服务器的HTTP响应信息,取出信息内容存入结果文本。改变参数n和code的值,依次获取所有文献网页。
2.2 语料信息抽取和格式化
每个网站都有自己的一套HTML起止标记模板,通过判断这些标记的意义,我们可以解析出大量网页的语料信息。
通过对上述网页的HTML语言标记的格式分析,可以建立其逻辑结构图,如图1所示。

图1 网页逻辑结构图
根据上面的起止标记可以解析得到网页的标题、正文等信息。由于我们建立动态语料库的目的是用于自动提取英汉商务信函语块,而同时包含英汉商务信函语块的句子一般只存在于网页的正文中,因此,构建动态语料库只需要提取网页的正文部分。通过对《中国日报(财经频道)》的英文官方网站和中文官方网站网页HTML格式的分析,我们发现网页正文部分起止标记如下:
<P class=MsoNormal style=[参数]align=[参数]>(正方信息)</P>
语料信息抽取主要利用起止标记,通过所设计的Extract类提供的属性和方法提取网页的正文信息。Extract类包含一个extract函数,该函数主要通过调用.NET Framework基类String类的成员public string Substring(int startIndex,int length)的方法实现单一信息的抽取功能,如抽取文章的标题等等。extract方法的数据输入为:待抽取的HTML字符串(string strInput)、模板的起止标记字符串(string strLeft,string strRight)。输出数据为抽取到的字符串(string strOutput)。具体流程如图2所示:

图2 语料信息抽取流程图
解析得到的数据还需要进行数据清洗和格式化。许多网页为了美观都加入了大量的网页特效标记、图片以及超链接等等,如:换行符(<br> </br>)、链接标记(<a> </a>)、层标记(<div> </div>)、空格标记( )等,这些都需要经过特别处理来实现对语料信息的格式化。“正则表达式是处理此类语块的强大工具。”(Friedl,2006)我们通过编程,利用正则表达式实现对数据的清洗和格式化处理工作。数据清洗和格式化用到的正则表达式举例如下:
(<[a-zA-Z]+[^>]* >)|(</[a-zA -Zd]+>)|( )
第一个“|”号前面部分匹配HTML开始标记,它查找一个“<”字符,后面跟a到z之间的大小写任意的任何一个或多个字母(“[a-zA-Z]+”部分中,“[a-zA -Z]”表示任意一个大写或小写字母,“+”表示一个或多个),接着是除“>”以外的零到多个任意字符(“[^>]* ”部分,“^”表示非,“[^>]”表示除“>”之外的任意字符,“* ”表示零或多个),最后以“>”字符结尾。
两个“|”号中间的部分“(< /[a-zA -Zd]+ >)”匹配结束标记,它匹配一个“<”字符,后跟一个“/”字符,然后是a到z之间的大小写任意的任何一个或多个字母或者数字(“d”表示数字),最后以“>”字符结尾。
最后的部分匹配空格标记“ ”。
如果还有其他特殊标记,可以参照上述方法设计相应的正则表达式进行清除。这样就基本完成了数据清洗和格式化,得到干净的文本,可以进行英汉商务信函语块的提取。
3.基于规则的英汉商务信函语块提取
基于规则的英汉商务信函语块提取共包括三个步骤:英汉商务信函识别规则设计、文本预处理和后期处理。
3.1 英汉商务信函语块识别规则设计
目前课题组初步构建了一个规模为200万词次的英汉商务信函语料库,包括四个子库:英语商务信函语料库、汉语商务信函语料库、英汉商务信函平行语料库、汉英商务信函平行语料库,该库为动态的,可以自动获取服务于语块自动提取的知识资源。我们从语言学的研究角度,将英汉商务信函语块分为全称缩略语块、惯用表达语块、专业术语语块三种类型:①全称缩略语块。经济原则是大量商务缩略词产生和被使用的最大原因。全称缩略语块涉及到贸易价格术语、保险、运输、支付与结算等商务各个方面。例如:FOB(Free On Board)船上交货、CFR(cost and freight)成本加运、FCA(Free Carrier)货交承运人、FPA(Free from Particular Average)平安险、WPA(With Particular Average)水渍险,等等。②惯用表达语块。惯用表达短语虽然专业性没有那么强,但是也是较常用的。例如:In reply to your letter(兹复)、Thank you for your cooperation(多谢你方合作)、by the way(转换话题)、such as(列举事物)、general speaking(评价),等等。③ 专业术语语块。商务英语信函中几乎每个环节都有套话与行话。例如:confirming your order(确认你方的订单)、accept your firm offer(接受你方的实盘),等等。
英汉商务信函语块识别部分的主要任务是根据英汉商务信函语块的结构特征、意义特征、功能特征,制定相应的规则识别出文本中的候选语块,从全称缩略语块、惯用表达语块、专业术语语块三种分类中制定英汉商务信函语块提取规则并进行识别。下表是在候选英语商务信函语块识别过程中使用到的文本标记和句法特征词规则。

表1 文本标记和句法特征词规则
确定句子以后就可以利用英语商务信函语块识别规则对候选英语商务信函语块进行识别。下表是制定的候选汉语商务信函语块提取规则。
找到候选汉语商务信函语块以后,系统可以利用该规则进行查找,将找到的词语与文本标记或句法特征词之间的字符串作为候选缩略语。在英汉商务信函语块提取阶段,系统利用模板将候选英语商务信函语块与候选汉语商务信函语块进行逐一匹配,最后找出正确的英汉商务信函语块。
3.2 文本预处理
文本预处理部分的主要任务是对动态语料库中的语料进行初步的处理,提取出包含指定规则的句子用于英汉商务信函语块识别。下面以缩略语的提取为例进行说明。该部分主要包括两个步骤:
(1)去除不可能包含英汉商务信函缩略语语块的括号。通过对实际语料的观察,我们发现存在一些括号作为插入语用于解释或说明。有的括号仅包含数字或者是数字加上特定符号(如百分号“%”、连字号“-”、斜杠“/”)等等。
对于这种括号中仅包含数字或者是数字加上特定符号的情况,由于括号内不可能包含英汉商务信函缩略语语块,如果不预先处理,势必会在下一步语块识别中进行许多无用的提取,浪费系统资源和时间,并且影响准确率。因此,有必要预先去除这种括号。
(2)将文本切分为句子,提取出包含括号的句子。如果一个句子中含有多个括号,则以右括号“)”为标记,将句子切分为若干个子句,提取出包含括号的子句。
对英语文本进行句子切分,鉴于英语文本中句点“.”的情况复杂,“需要设计详细的规则和相应的正则表达式,并结合一定的统计数据,才能提高英语句子自动切分的准确率”(Clough,2001)。我们采用了上述规则和统计相结合的句子切分方法,效果良好。“英语句子切分也可以用最大熵的方法解决”(Kit&Liu,2005)。汉语句子的切分也不容易,逗号“,”经常也可以作为断句的标记,利用中文树库,“通过机器学习的方法可以达到比较理想的切分效果”(Xue,2005)。切分好的英、汉句子可以通过句长、双语词典等进行句对齐处理(Gale&Church,1991;Brown et al,1991;Chen,1993;Wu,1994;Li et al,2010)。
3.3 后期处理
我们安排了课题组中两位外国语言学与应用语言学专业商务英语语言研究方向的教师(硕士学位)分别对测试语料中的英汉商务信函语块进行人工合法性验证,如果两位教师的意见出现分歧,则以课题组共同的意见为准。
4.实验测试及其分析

图3 基于规则的英汉商务信函语块自动提取系统层次结构图
英汉商务信函语块自动提取系统包括基础资源层、提取规则层和应用层三个层次。具体层次结构如图3所示。
各层次的主要功能和作用分别是:(1)基础资源层。该层通过对互联网中指定网站的网页进行定期爬取和更新以及对网页语料信息的抽取和格式化,自动构筑大规模英汉商务信函语料库,为英汉商务信函语块自动提取提供基础资源;(2)提取规则层。该层为英汉商务信函语块自动提取的规则库。英汉商务信函语块的自动提取规则主要通过人工内省的方式制定,辅之以规则与统计相结合的语言信息处理学习方法,从而对规则进行不断完善;(3)应用层。该层将英汉商务信函语块自动提取的多种规则综合地应用到语块的自动识别过程中,实现英汉商务信函语块的自动提取。通过英汉商务信函动态语料库的不断更新,逐步构建起一个较大规模的英汉商务信函语块库。
英汉商务信函语块自动提取系统包括动态语料库构筑和英汉商务信函语块自动提取两大部分,共五个模块。(1)网页自动下载模块。网页自动下载模块主要利用网页地址编号将指定网站的网页批量下载到本地硬盘;(2)语料信息抽取和格式化模块。语料信息抽取和格式化模块主要利用起止锚点标记对下载的网页进行结构解析,抽取网页正文部分的信息,利用正则表达式去除网页特效标记和超链接标记等噪音,对语料信息进行数据清洗和格式化,最后得到干净的文本语料;(3)文本预处理模块。文本预处理模块主要根据英汉商务信函语块的文本标记集和句法特征词集对输入的语料文本进行初步的处理,在排除一些不可能包含英汉商务信函语块的括号以后,提取出包含括号的句子;(4)英汉商务信函语块识别模块。英汉商务信函语块识别部分的主要任务是根据英汉商务信函语块的结构特征、意义特征、功能特征,制定相应的规则识别出文本中的候选语块,从全称缩略语块、惯用表达语块、专业术语语块三种分类中制定英汉商务信函语块自动提取规则进行识别;(5)后期处理模块。后期处理模块根据英汉商务信函语块的类型对提取出的英汉商务信函语块进行合法性验证。
为了测试系统对开放性语料中英汉商务信函语块自动提取的能力,我们进行了实验测试。下文以缩略语提取为例进行说明。
4.1 测试语料
本次实验的测试语料是从动态语料库中随机选取的500篇英文和500篇中文未经人工校对、自动分词以及词性标注的生语料,共计322156个英汉商务信函词形,语料大小约4.1M。我们的语料收集范围分为建立业务关系函、产品推销函、资信查询函、询盘函、发盘还盘函、订购函、装运通知函、支付结算函、索赔函、保险函等,这些信函涉及商务活动的全过程。
4.2 测试评价标准
为了更加客观地对系统性能进行评测,我们将准确率(Precision)、召回率(Recall rate)和F值(F values)作为测试结果的评价指标,将语言学家的意见作为参考标准。
一般情况下,达到一定的识别精度后,识别的准确率和召回率存在着一定的反相关性,准确率的提高以召回率的降低为代价。本研究希望通过语动态语料库的不断更新,逐步构建起一个较大规模的英汉商务信函语块库,因此我们相对更注重准确率的提高。
4.3 测试结果
利用基于规则的英汉商务信函语块自动提取系统,我们最后提取到367个英汉商务信函缩略语语块,其中正确的有360个。根据专家的反馈信息,测试语料中共有395个英汉商务信函缩略语语块。测试结果见表3。
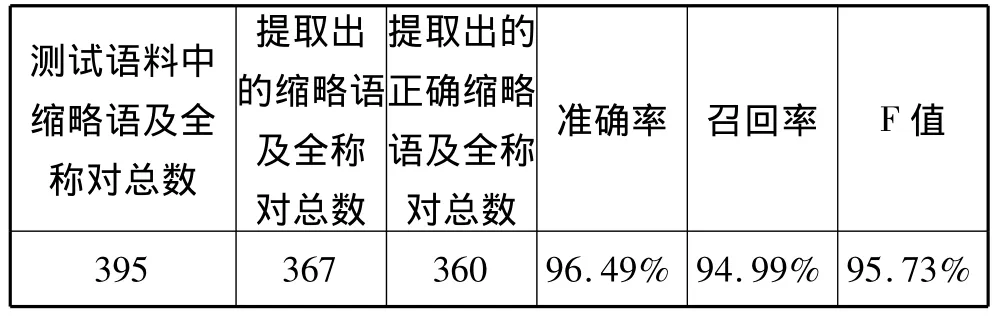
表3 基于规则的英汉商务信函语块自动提取系统测试结果
经过分析,测试结果中共有218个不同的英汉商务信函语块。下表是在测试结果中出现100次以上的英汉商务信函语块。

表4 测试结果中出现100次以上的英汉商务信函语块(部分)
4.4 测试结果分析
从测试结果来看,英汉商务信函语块自动提取系统取得了较好的效果,测试的准确率为96.49%、召回率为94.99%、F值为95.73%。经过分析,出现错误提取和未能提取出英汉商务信函语块的原因主要有以下几个方面:
(1)英汉商务信函语块都作为注释放在括号中;
(2)括号中除了英汉商务信函语块还包括其他信息。
造成提取问题的主要原因是因为自然语言系统并不是一个精心规划的系统,很难用一套规则提取所有的英汉商务信函语块,需要根据每种语言的具体情况不断对规则库进行完善。
5.结语
语块数量如此之多,仅靠死记硬背是不现实的,因此,研究如何利用语料库进行语块的自动提取,在英汉语言教学和机器翻译等方面的研究中具有十分重要的意义。我们利用计算机进行基于英汉商务信函语料库的语块提取研究,具有两方面重要意义:(1)英汉商务信函语块提取的实现为研制在互联网上进行机器辅助英汉商务信函翻译系统提供基础;(2)我们构建的英汉商务信函动态语料库是面向商务领域的一个特定的语料库,它对商务英语学习者、商务汉语学习者、翻译学习者及工作者的研究与学习起到指导作用。
[1]李洁晶,赵晓临.庆祝杨惠中先生执教50周年暨应用语言学研讨会综述[J].外语界,2007(3):75-79.
[2]李太志.词块在外贸英语写作教学中的优势及产出性训练[J].外语界,2006(1):34-39.
[3]缪海燕,孙蓝.非词汇化高频动词搭配的组块效应——一项基于语料库的研究[J].解放军外国语学院学报,2005(3):41-44.
[4]濮建忠.英语词汇教学中的类联接、搭配与词块[J].外语教学与研究,2003(6):438-445.
[5]王立非,张岩.基于语料库的大学生英语议论文中的语块使用模式研究[J].外语电化教学,2006(4):36-41.
[6]卫乃兴.语料库语言学的方法论及相关理念[J].外语研究,2009(5):36-42.
[7]邢富坤.多词单位的描写识别与词典编纂[J].当代语言学,2012(4):407-417.
[8]Brown,Peter F.,Jennifer C.Lai & L.Robert,Mercer.Aligning sentences in parallel corpora[C]//Proceedings of the29th Annual Meeting of the Association for Computational Linguistics.California:Berkeley,USA.1991:169 -176.
[9]Chen,Stanley F.Aligning Sentences in Bilingual Corpora Using Lexical Information[C]//Proceedings of the31st Annual Meeting of the Association for Computational Linguistics.Ohio:Columbus,USA.1993:9-16.
[10]Clough P.A Perl Program for Sentence Splitting Using Rules[M].University of Sheffield,2001.
[11]Friedl,Jeffrey.Mastering Regular Expressions(3rd Edition)[M].Publisher:O’Reilly,2006.
[12]Li P,Sun M,Xue P.Fast-Champollion:a Fast and Robust Sentence Alignment Algorithm[C]//Proceedings of the23rd International Conference on Computational Linguistics.Posters,2010:710 -718.
[13]Gale,William A.& Kenneth W.Church.A Program for Aligning Sentences in Bilingual Corpora[C]//Proceedings of the29thAnnual Conference of the Association for Computational Linguistics.Berkeley,1991:177 -184.
[14]Kit,C.,Liu X.Period Disambiguation with MaxEnt Model[C]//Natural Language Processing-IJCNLP2005.Springer Berlin Heidelberg,2005:223 -232.
[15]Sinclair,J.M.Corpus,Concordance,Collocation[M].Oxford:Oxford University Press,1991.
[16]Xue N,Xia F,Chiou F D,et al.The Penn Chinese Tree-Bank:Phrase Structure Annotation of a Large Corpus[J].Natural Language Engineering,2005,11(2):207-216.
[17]Wu,Dekai.Aligning a Parallel English-Chinese Corpus Statistically with Lexical Criteria[C]//Proceedings of the32nd Annual Meeting of the Association for Computational Linguistics.Las Cruces,New Mexico,USA.1994:80 –87.
猜你喜欢
苏州教育学院学报(2017年5期)2017-12-07 07:13:22
苏州教育学院学报(2017年4期)2017-09-14 09:04:51
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:14
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:12
河北传媒研究(2015年1期)2015-07-12 10:45:19
山西大同大学学报(社会科学版)(2015年6期)2015-01-22 07:22:32
语言与翻译(2014年3期)2014-07-12 10:32:10
自然科学史研究(2014年4期)2014-02-02 13:04:59
外国语文(2013年1期)2013-09-12 07:57:56
当代修辞学(2013年3期)2013-01-23 06:41:20
