
知识社区环境下的DBpedia研究
2013-08-21 08:36:38
图书馆 2013年4期
(北京大学信息管理系 北京 100871)
知识社区的概念源于知识管理。网络环境下,知识社区可理解为:由于部分人对某个主题的共同兴趣和知识获取、交流需求而聚集起来,并基于网络创造和分享知识的平台。维基百科作为开放、自由、免费、共享的多语言网络百科全书,由全球网民共同编写,正是知识社区的产物。然而维基百科的条目多以自然语言描述,只支持文本检索而不支持结构化检索,也无法跨页面进行检索,导致其中虽然蕴含海量信息,却无法被深度挖掘利用。
语义网作为万维网的延伸,利用XML、RDF、本体、OWL等技术,使其中的信息都具有定义完好的含义,通过机器可“理解”的语义,让计算机拥有一定的推理能力和自动处理大规模数据的能力。因此,利用语义网技术挖掘维基百科内容的项目不断展开,DBpedia就是其中一项。
1 DBpedia简介
DBpedia由柏林自由大学和莱比锡大学的研究人员发起,与OpenLink Software公司合作,致力于从维基百科的结构化和半结构化信息中抽取数据并生成RDF三元组,将其组织后形成庞大的数据集,与外部的关联数据连接,提供给人们使用。〔1〕该项目也被“互联网之父”蒂姆·伯纳斯·李盛赞为关联数据工程中最知名的项目之一。
2007年2月,DBpedia数据集开始开放下载,之后每隔约半年时间都会有更新。最新的版本为2012年8月发布的DBpedia3.8,该版本数据集中描述了超过377万个资源,其中235万个资源使用统一的DBpedia本体进行描述,包括76.4万个人物,57.3万个地点,11.2万张音乐专辑,7.2万部电影,1.8万种视频游戏,19.2万个组织机构(包括4.5 万家公司、4.2万所学校),20.2万个生物物种和5500种疾病。DB-pedia用111种不同的语言以RDF三元组的形式为上述资源做了摘要和详细的描述,其中有800万条指向图片的链接、2440万条指向其他Web页面的链接、2720万条指向其他RDF 数据集的链接。〔2〕
DBpedia的目标是从维基百科中抽取结构化信息并开放下载,与其他数据集互联而形成知识网络。如今该目标正在逐步实现,由于DBpedia的跨领域、多语言等特征,DB-pedia自发布后便与诸多数据集互联,成为关联数据网的核心。基于该数据集的应用也愈来愈多,渐渐渗入社会生活各个方面。
2 知识社区环境下DBpedia的信息组织
2.1 基于维基百科的信息抽取
信息抽取是指从文本中抽取出用户感兴趣的信息,包括实体、事实等,并以结构化的形式存储起来,即将非结构化的数据转换为语义信息。〔3〕维基百科中蕴含大量的信息,单靠人力不可能完成对其内容的抽取整理,因此必须依赖大规模的人机协同进行处理。
DBpedia通过知识抽取框架(DBpedia Knowledge Extraction Framework)抽取维基百科中的标签、摘要、语言链接、图片等数据项,该框架的技术基础由项目组提供,普通参与者亦可改进和完善。知识抽取框架从维基百科中抽取信息主要采用两种方式,其一是利用维基百科的数据库转储文件,将其关系数据表格中存储的关系直接转换为RDF三元组;其二是利用维基百科的文章内容及信息盒模版抽取RDF三元组。〔4〕从维基百科的文章内容中抽取信息时,既可以从部分非结构化的文本中抽取,也可以从半结构化的部分及条目内部的链接结构中抽取。其中主要的信息抽取来源如下图:
图示抽取源所含的信息都有较高的挖掘价值,且易于抽取,将这些信息抽取整理后能够进行更深层次的挖掘,从而得到更多有价值的信息。
目前DBpedia支持定时抽取和实时抽取两种抽取模式,前者以一个月为周期,后者可以动态监测维基百科页面,当数据内容有变化时,编辑者只需在维基百科中进行数据修改,就可以同步到DBpedia中。
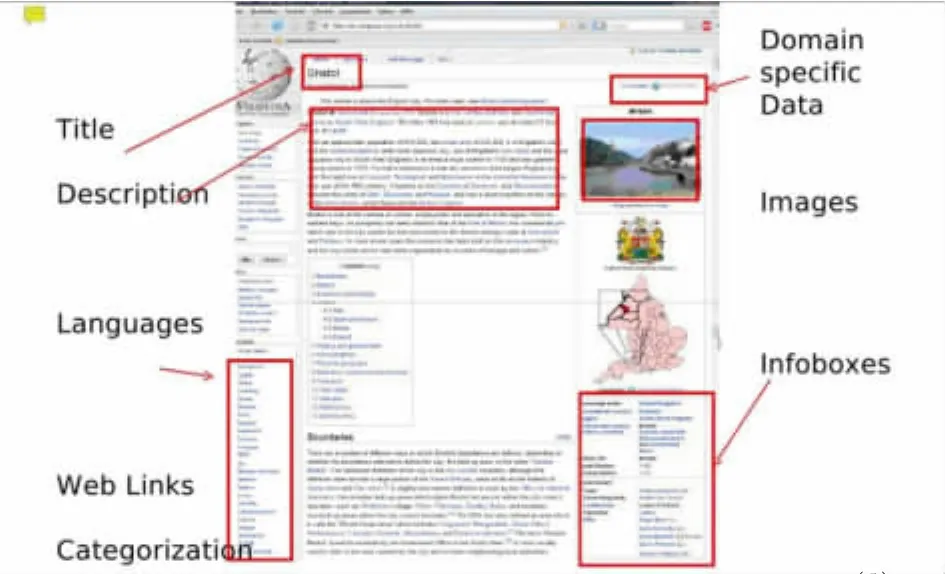
图1 DBpedia从维基百科抽取数据的信息源图解〔5〕

表2 DBpedia从维基百科抽取数据的信息源详解
2.2 DBpedia中的资源描述和组织
用RDF描述事物的基本思想是:将一切可以在万维网上标识的事物(具体的或抽象的,存在的或不存在的)统称为“资源”;用URI(统一资源标识符)表示资源;用属性和属性值描述资源,其中属性值可以包含URI,属性也是一种资源。〔6〕
维基百科中的每个条目在DBpedia中都拥有唯一的URI,与其页面链接地址相对应,形式为http://DBpedia.org/resource/Name,其中Name部分是从该资源的英文版维基百科的链接地址 http://en.wikipedia.org/wiki/Name中抽取的。这种方式使得该资源直接与英文版维基百科的条目页面联系起来。〔7〕
DBpedia中的每个资源都有标签、英文短摘要和英文长摘要、相应的维基百科页面链接和描述该资源的图片链接等属性。除了以上基本属性外,不同类型的资源通过不同的属性描述,这些属性不仅限于DBpedia所定义的,还可以引用其他本体或数据集中定义的,如FOAF、dc、RDF以及owl等。引用外部定义属性的优势可以弥补DBpedia属性定义的不足,更加完善地描述资源;缺陷在于,多处引用容易造成属性的重复,进而造成数据冗余。由于DBpedia涉及的资源多种多样,如何对某一类资源引用合适的外部属性也是DBpedia需要解决的问题。
通过精确细致的属性描述资源后,用户查询时得到的不再是整个页面,而是精确的答案。通过设定规则,为后续的自动推理和进一步数据挖掘提供了极大的便利。在DBpedia中,用RDF描述得到的实体通过本体和分类体系进行组织。DBpedia数据集的本体库是从维基百科信息盒中抽取并组织而成的,包括170个类和720个属性,是个浅层的分类体系。但该分类并不完善,因此DBpedia还使用了另外三种分类方法对资源进行组织,分别是:维基百科分类方法、YAGO分类方法和UMBE分类方法。〔8〕
维基百科的分类体系包含了415000个类目,该体系支持协同扩展并可以持续更新。但由于其编辑维护者为长尾用户,在分类体系的设置上权威性欠缺,类目的等级关系以及横向关系揭示方面也不完善。YAGO分类体系包含286000个类目,其特点是类目划分较深、较精确。UMBEL是一个轻型本体,包括20000个类目,该本体是为链接Web中的内容和数据而创建。
2.3 DBpedia的信息获取途径
2.3.1 SPARQL 端点检索
SPARQL是一种面向RDF数据模型的查询语言和数据访问协议,用于访问任何可以映射到RDF模型的数据资源。为了实现对DBpedia的查询,开发者提供了SPARQL终端,用户可以利用SPARQL语言在http://DBpedia.org/sparql进行检索,直接得到相应的数据。例如查询某条河流的长度,系统会直接返回其长度作为答案,而不是返回河流相关页面再让用户到其中筛选信息。用户也可以检索较复杂的问题,例如“从1990至1920年期间出生在北京的姓李的女作家”这个问题,经过正确的SPARQL语言组织后,系统即可匹配并返回结果。
然而鉴于大多数用户并不熟悉SPARQL语言,因此该系统的友好易用性欠缺。为了使普通用户也能够在DBpedia上进行查询,可以借助一些工具如 Auto SPARQL,用户只需键入所要查询的关键词并指定所查找的属性,检索工具会自动转换为SPARQL语言并将结果反馈给用户。
2.3.2 关联数据接口
关联数据在2007年提出,目的是构建计算机能理解的语义数据网络,而不仅仅是人能读懂的文档网络,也就是把文档的网络变成数据的网络,基于此构建更智能的应用。〔9〕DBpedia自与其他数据集互联以来,由于其跨领域的特点而处在关联数据网的核心。基于各个数据集间的互联,用户在数据集之间游历,一旦涉及DBpedia中的数据,自然会通接口进入其中。
在2007年,加入关联数据网的数据集共有16个,其中10个数据集与DBpedia相连接。到2011年,加入关联数据的数据集增长更迅速,而DBpedia俨然已经成为整个关联数据网中的核心。用户可以通过大其他数据集进入DBpedia,也可通过DBpedia连接到其他数据集,DBpedia作为关联数据中转站的特征也更明显。
2.3.3 下载RDF文件包
DBpedia的数据集是对公众开放并可以免费下载的,DB-pedia的下载页面列出了DBpedia的所有版本,并标出各版本的最后修改时间及其大小,用户点击相应的版本即可进入下载页面。在最新的DBpedia3.8中,共提供了111种语言版本的数据集,每个数据集中有不同的数据包,列出相应语言的标签信息、映射关系信息以及维基百科信息盒中属性等数据包供用户下载,用户可根据自己的需求有选择地下载或全部下载。
3 DBpedia的特点
3.1 协同编辑
知识社区环境下,DBpedia的一大特点就是协同编辑,由众多的用户共同完成数据集创建和维护。在数据集的建设过程中,除了数据源于维基百科,是大众共同编辑的成果外,其知识抽取框架、映射关系定义、本体维护等技术也并非项目组独立的成果,而是在项目组提供的基础框架上,经过许多人参与并贡献智慧后的成果。DBpedia能够成为大规模、跨领域、多语言的知识库,与其协同编辑的基本特征密不可分。
3.2 数据结构化
DBpedia区别于维基百科之处在于其数据描述的结构化,即用以描述资源的每个属性都是经过定义的,可被机器理解。描述资源的RDF三元组形式为“资源—属性—属性值”,以属性作为资源和属性值之间的联系,通过简单的三元组结构实现良好的组织,便于后续的数据利用。在有良好结构的数据基础上,通过定义一定的规则,可以实现机器自动推理。推理是使用预先定义的规则基于知识库中存储的事实信息获得额外的、潜在的知识。例如,预先定义“拥有相同父母的两个男性为兄弟”,那么在描述资源时,如果A和B的父母关系的属性值相同,则可以自动得出A和B是兄弟的结论,并自动将A的兄弟关系属性值赋值为资源B,B的兄弟关系属性值赋值为资源A,从而建立联系。同时,如果定义了出生年份更早则为兄长的规则,那么就可以根据两者的出生年份自动得出其长幼顺序。
3.3 大规模人机协同知识处理
在基于语义Web的知识处理过程中,人机协同知识处理强调人与计算机的分工与合作,通过人对知识处理前端控制,降低计算机知识处理的难度,在人与计算机之间寻找最佳的协同状态。〔10〕DBpedia从维基百科中抽取海量数据,是个规模庞大的工程,单靠人力无法实现,必须借助机器的协助。然而机器本身智能程度有限,知识抽取框架的建设、知识间的映射关系的定义均需要发挥人的智慧,而机器可以据此自动完成重复性的工作,从而发挥了计算机对结构化程度较高的数据的重复操作能力。
维基百科的数据是不定期更新的,在预先定义出检测和验证规则后,DBpedia可以按照一定的时间间隔、有针对性地检测对应的内容,如果有数据变化,则更新入数据集中。维基百科中的数据更新,则是依靠无数的编辑者进行的,通过人与机器的协同处理,完成数据集的更新和维护。
3.4 跨领域知识库
DBpedia所描述的数百万个资源中,内容涉及人类社会生活中所能涉及的几乎所有领域,目前涉及人物、地点、音乐、电影、游戏、组织机构、生物物种、疾病等多个方面,这些属于不同类别的实体又是相互关联的。即DBpedia所描述的实体不仅跨越多个领域,并且在这些领域之间建立了联系,随着其技术的日渐完备和规模的不断扩大以及越来越多志愿者的参与和贡献,DBpedia所能涵盖的范围势必会延伸至越来越多的角落,并不断在各个实体间建立联系,最终形成一张知识网络。DBpedia的这一特征使得它与其他的领域本体和目前发布的数据集都有了交集并与之相连,从而成为关联数据的核心,成为不同数据集之间链接的中转站。在日后的相关应用开发和数据深度挖掘中,它的中转站功能将不可忽视。
4 基于DBpedia的应用
4.1 为语义网应用服务提供数据支持
DBpedia的数据集可以授权给第三方使用,从而简单、快速地衍生出众多创新性应用,被美国科技媒体Read Write Web评为2009年最佳的语义网应用服务。
目前基于DBpedia开发的应用中比较典型的是DBpedia Mobile。DBpedia Mobile是一个基于DBpedia中的地理位置数据作为导航的客户端服务。基于现有的GPS定位功能,用户可以搜索、发布和标注某个地点的信息,并查看其它用户对周围环境的标注。由于DBpedia与其他数据集互联,用户有可能因此而进入一个更细致、针对性更强的数据集,从而得到更全面的信息。当然,仅靠DBpedia不可能完全满足用户的需求,只有越来越多的数据集发布并加入关联数据网,才可以在该网络中实现无缝隙游历。
DBpedia的数据也可以整合入Web页面中,例如从DBpedia查询得到一个数据表后,可以通过客户端将此数据表嵌入到用户的页面中并实现动态更新。目前正在进行的与之相关的应用是BBC interlinking project,该项目在DBpedia数据集和BBC的海量新闻信息间建立联系。例如,当BBC中出现关于某个音乐家的新闻时,BBC可以基于DBpedia提供该音乐家的基本信息如图片、个人资料、所发布的音乐专辑等。此外,BBC的新闻也可以通过DBpedia与对应的维基百科页面进行互联,例如当BBC中有关于某个城市的新闻,维基百科中对应城市的词条页面则可嵌入该新闻,让用户在查看词条的同时了解其最新信息。
DBpedia的海量数据也值得发掘,从而创造出更多知识。例如DBpedia Relationship Finder就是典型的基于DBpedia的数据挖掘与知识发现系统,它可以通过DBpedia计算在英文维基百科中描述的两个事物之间的语义距离。〔11〕
4.2 对维基百科的查询
DBpedia的结构化数据源于维基百科,因此可以提供更准确和更直接的维基百科搜索,用以更好地发掘其中的资源。目前检索界面如下:

图2 基于DBpedia的维基百科结构化查询界面
该检索界面主要包含四个模块:用于自由检索的文本检索框(图中①)、用于结构化检索的部分(图中②)、用于剔除检索限定条件的部分(图中③)、用于呈现检索结果的结果显示部分(图中④)。用户可以直接在文本检索框中进行检索,也可通过结构化检索部分进行筛选,并不断限定条件压缩范围,直至最后得出检索结果。
当用户有明确的检索词时,可以在文本检索框中输入检索词自由匹配,系统会判断检索对象的属性并在左侧的结构化检索部分予以调整,方便用户的后续甄选。例如检索“Beijing”一词,搜索结果包括与“beijing”相关的人物、地点、机构、组织等多种资源。此时,左侧结构化检索部分会陈列出人物、地点等相关的属性供筛选,用户可以做更为细致和精确的条件限定,从而缩小检索范围。检索得到的结果按照被引用次数、词条质量等综合排序,列表中会展示词条的缩略图、题名、英文摘要。在用户没有明确的检索词时,可通过层层筛选接近目标,例如检索“1960至1975年之间出生在北京的艺术家”,可在左侧的结构化检索框中选定目标类型为person,甚至更精确地选择artist,系统经筛选后列出与artist相关的属性,用户只需限定出生地和出生时间即可得到想要的结果集合。
5 DBpedia的意义
5.1 基于知识社区建立大规模知识库
DBpedia的数据抽取和更新依赖于Wiki这个协作共创的系统,该系统下众多的长尾用户所创造的知识涵盖各个领域。其中内容包罗万象,经过发展积累后,规模已非常庞大,并在不断发展。DBpedia从中抽取有用信息并整理为知识库后,不仅得到了大规模的数据,同时利用分类、本体以及内部互链等形式揭示了知识间的关系。DBpedia不仅具有大规模、跨领域、多语言的特征,其中的数据也是客观公正、及时更新的。每个用户既是读者,也是监督者和纠错者,一旦发现数据更新不及时,或观点有失偏颇、内容不准确,都可以基于维基百科进行讨论和修改。
5.2 多元应用为社会提供便利
DBpedia的出现为人们开发各种应用提供了便利,如前所述的DBpedia Mobile等项目已开创了良好的先例。在信息技术飞速发展的今天,各种各样的技术应用缤纷呈现,使得人们的社会生活越来越便利。DBpedia中的数据涵盖社会生活中的方方面面,依托这个庞大数据集的支撑,势必能够有更多应用出现。目前国外已经有许多政府和组织机构发布了相关的数据集,涉及地理、媒体、出版物、政府信息、生物科学等诸多方面,依托这些数据集的支撑和作为中介的DBpedia,可以开发涵盖各个领域的应用,例如可以综合正在建设的中药本体和DBpedia可以开发简单实用的中药小百科,供日常使用。
5.3 推动语义网发展
语义网自从被提出后,在国际上已掀起了一轮研发热潮,它的提出也为信息组织的发展提供了新的方向,其三大核心技术XML(S)、RDF(S)、Ontology也不断完善,为语义网的发展提供了有力支持。除了技术保证,语义网的发展还需要数据作为支撑,才能在实践中发现缺陷并弥补和完善。目前的领域本体建设中,由于所能接触的数据源大多规模小、数据少、数据更新不及时且涉及的领域狭窄,给语义网技术的大规模应用造成了不便。DBpedia的出现结合了维基百科这一超大规模数据源和语义网的优势,为本体和RDF等提供了数据支持。而基于DBpedia和其他数据集的应用的逐渐问世也必将使人们更加清晰地认识到语义网的先进之处与便利性,从而推动语义网的普及和发展。
6 结语
DBpedia在本体、网络资源分类、文本知识抽取、信息资源描述、网络信息传播等诸多方面都有涉及,作为一个跨领域多语言的大规模知识库,其在数据挖掘、语义网发展等方面都有着重要的意义。同时,作为知识社区环境下的产物,除了具有组织和传播知识的功能外,其维基精神也有极其深远的文化影响。希望在以后的学习和研究中能够对其有更深入的了解和分析,从而探索这个新的知识库在网络信息资源的组织传播等诸多方面的功能和意义。
虽然DBpedia有诸多优点,目前还是存在一些问题,例如数据抽取的来源还未覆盖词条正文,而正文才是信息量最大最全面的部分,这需要从自然语言中抽取结构化数据的技术支撑。此外,信息盒的覆盖率与质量、不同语言版本间的内容出入等问题,需要从维基百科和DBpedia两个方面进行探索。
1.Wikipedia:DBpedia.〔2013-03-01〕.http://en.wikipedia.org/wiki/DBpedia
2.DBpedia blog.〔2013-03-01〕.http://blog.DBpedia.org/
3.金海.语义网数据管理技术及应用.北京:科学出版社,2010:75
4.刘巧玲.维基百科上的语义搜索.上海交通大学计算机应用技术专业硕士论文,2009
5.图片引自:Anja Jentzsch.DBpedia-Extracting structured data from Wikipedia,Presentation at Semantic Web In Bibliotheken(SWIB2009),Cologne,Germany,November 2009
6.戴维民等.语义网信息组织技术与方法.上海:学林出版社,2008:11
7.Christian Bizer,Jens Lehmann,Georgi Kobilarov,et al.DBpedia-A Crystallization Point for the Web of Data.Journal of Web Semantics:Science,Services and Agents on the World Wide Web,Issue 7,2009
8.Christian Bizer,Jens Lehmann,etc.DBpedia-A Crystallization Point for the Web of Data.Journal of Web Semantics:Science,Services and Agents on the World Wide Web,Issue 7,Pages 154-165,2009
9.谭洁清.关联数据的简介与进展.信息与电脑,2011(1):103-106
10.朝乐门.基于语义Web的人机协同知识处理研究.图书情报工作,2009(24):115-119
11.朝乐门,张勇,邢春晓.DBpedia及其典型应用.现代图书情报技术,2011(3):80-87
猜你喜欢
英语世界(2023年10期)2023-11-17 09:18:46
保健医苑(2022年1期)2022-08-30 08:39:14
英语文摘(2021年8期)2021-11-02 07:17:46
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
计算机工程(2015年8期)2015-07-03 12:20:35
读者·原创版(2015年11期)2015-03-01 06:15:34
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
意林(2014年2期)2014-02-11 11:09:17
电脑爱好者(2011年11期)2011-06-22 08:20:18
