
基于提前分配路径的低时延片上路由器结构
2013-07-25 03:37郑小富顾华玺杨银堂黄忠凡
电子与信息学报 2013年2期
郑小富 顾华玺 杨银堂 黄忠凡
①(西安电子科技大学ISN国家重点实验室 西安 710071)
②(西安电子科技大学通信网络信息传输与分发技术重点实验室 西安 710071)
③(西安电子科技大学微电子学院 西安 710071)
1 引言
随着片上系统(System-on-Chip, SoC)可集成IP核的数目越来越多,现有基于总线架构的SoC在时延、吞吐、可靠性以及扩展性方面面临着诸多问题。作为解决多核互连的关键技术,片上网络(Network-on-Chip, NoC)采用片上路由器实现各IP核之间的可靠性互连[1-3],采用全局异步局部同步的通信机制解决了单一时钟全局同步较难问题[4-6],同时采用并行互连通信的方式,极大地改善了网络的时延、吞吐以及可扩展性等性能。
片上路由器是互连 IP核和转发分组的核心元件,它为 IP之间的通信提供了可靠的数据通路。NoC常见的路由器结构包括虫孔路由器和虚信道路由器。虚信道路由器在虫孔路由器基础上引入了虚信道流控技术[7],缓解了虫孔路由器的队头阻塞问题并能够解决片上的死锁问题,提高了片上网络的时延和吞吐等性能。因此这种路由器在NoC设计中应用较为广泛。虚信道路由器采用输入排队结构[8]。分组在路由器需经过路由计算、虚信道仲裁、开关仲裁以及开关传输4个阶段。其中路由计算完成输出端口计算,虚信道仲裁完成输入请求到输出端口空闲虚信道分配,开关仲裁完成输入请求到空闲输出端口的分配,开关传输完成分组从输入端口到输出端口的传输。这类按照4阶段实现的路由器结构具有严格的信号依赖关系,这种依赖关系导致虚信道路由器有较长的关键路径时延。因此,在国内外研究中常采用提前路由、投机仲裁以及预测等机制来缩短路由器的关键路径时延。文献[9]基于分类请求方式将虚信道仲裁和开关仲裁并行设计,将路由器的流水阶段缩短为2个,与4阶段的虚信道路由器相比可降低18%的时延,但当网络负载较大时投机成功的概率降低。与文献[9]相比,文献[10]基于区分优先级方式大大提高了投机成功的概率和路由器的性能。文献[11]通过在路由器中加入流量预测模块来提高分组在某方向上投机成功的概率,但是这种预测机制需设计复杂的预测算法,开销较大。上述方法虽可降低虚信道路由器关键路径时延,但设计复杂度较高并不适用于片上网络。当投机失败时,投机的分组必须重新进行虚信道仲裁和开关仲裁,这使得分组在网络中传输的时延反而增大;同时这些方法在仲裁的设计中常采用基于轮询仲裁或部分优先级规则进行仲裁,未考虑分组所在路由器的缓存等状态信息。最终导致了流量分布并不均衡,而且网络的链路利用率以及路由器的缓存利用率较低。
本文针对2D Mesh片上网络,提出一种提前分配路径的片上路由器结构,并给出一种基于缓存信息的仲裁算法。该路由器可降低分组在路由器中的关键路径时延,即使在提前分配失败的情况下也不会额外增加分组在网络的传输时延。基于缓存信息的仲裁算法可使微片数目多的缓存优先仲裁。提前分配和基于缓存信息仲裁不但降低了分组在路由器中的关键路径时延,而且可以提前释放阻塞较为严重的虚信道。保证了全网通信的低时延和高吞吐又达到了较高的平均缓存利用率。
2 路由器结构
2.1 路由器组成单元
图 1所示为本文提出的提前分配路径路由器(Pre-Allocated Path Router, PAPR)。路由器采用虚信道流控机制,每个路由器端口设置n个相互独立的虚信道缓存,每个缓存深度大于一个微片。路由器包括数据路径和控制分配路径两部分。数据路径包括输入、输出端口以及交叉开关,输入端口包括虚信道及虚信道缓存;控制路径包括路由计算单元、预处理单元、虚信道分配单元以及开关分配单元。路由计算单元的功能是完成提前路由计算,结果是分组在下节点的输出端口;虚信道分配单元为分组完成下节点虚信道的分配,结果为虚信道号(Virtual Channel id, VC_id),下节点路由器根据VC_id将微片存入对应的虚信道缓存;开关分配单元为分组完成交叉开关输入、输出端口的仲裁。
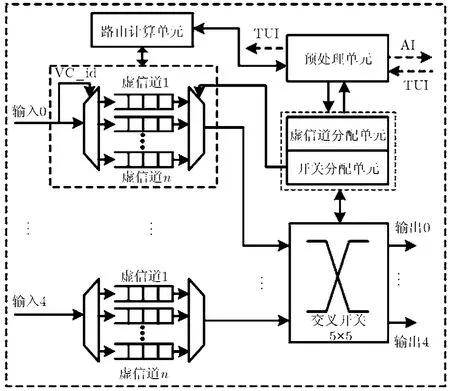
图1 PAPR结构
预处理单元主要包括用于记录信息的表。表中记录了当前输入端口每个缓存存放的微片数目(Input Buffer Length, IBL)、同一条链路相连的相邻端口缓存存放的微片数目(Neighbor Buffer Length, NBL)以及提前分配虚信道的状态信息(Virtual Channel Status, VCS), 1表示有虚信道分配结果,0表示无虚信道分配结果。以记录信息表为基础,该处理单元通过提前分配信息(Advanced Information, AI)和表更新信息(Table Update Information, TUI)与相邻路由器进行信息交互,其中提前分配信息(Advanced Information, AI)的功能是完成到相邻节点提前分配信息的传输,包括提前路由计算结果和发送 AI信息对应缓存的微片数(Advanced Buffer Length, ABL);表更新信息(Table Update Information, TUI)的功能是完成NBL和VCS的更新。对于采用5×5 Crossbar虚信道路由器来说,即使有多个虚信道分配结果,但开关传输阶段每个输入端口只传输一个缓存的微片,因此记录信息表中的IBL作用是用于AI信息发送时的仲裁、虚信道仲裁以及开关仲裁;由于存在多个请求竞争同一输出端口的情况,所以NBL是用于虚信道仲裁和开关仲裁中的竞争处理;VCS的作用是用于非头微片AI的发送;ABL的作用是用于AI所在节点的虚信道仲裁。
2.2 路由器工作原理
为详细描述PAPR路由器工作原理,按头微片和体微片(尾微片与体微片操作类似)在路由器中的流水线例程进行描述。对于头微片:图 2(a)所示为分组头微片经过3个PAPR路由器流水线示意图。设路由器流水线的一个关键路径时间长度为T,当分组的头微片到达路由器(1,1)时。在时刻t,路由器完成两个并行操作:(1)路由计算单元完成目的地址解析并为头微片计算出下一路由器结点的输出端口;(2)虚信道分配单元从微片中提取输出端口信息进行虚信道分配,分配结果为虚信道号;在t+T内,开关分配完成且预处理单元完成 AI信息的传输;在t+2T内,头微片在路由器(1,1)中完成开关传输,同时t+T发送的AI信息在路由器(2,1)内为头微片完成了虚信道分配,此时将成功预约的虚信道信息VCS通过TUI发送给相邻端口;在t+3T内,当头微片到达路由器(2,1)时,由于已有虚信道分配结果,因此头微片到达路由器(2,1)直接进行开关分配和提前路由计算,所以头微片在路由器(2,1)只需2T的时间。我们称这种在开关分配完成后传输 AI信息的机制为SAAH(Switch Allocation AHead)机制。该机制使头微片通过3个路由器的关键路径时间缩短为8T,与流水阶段为4T的经典虚信道路由器相比减少了4T的时间。对于分组的体微片来说:如图2(b)所示,体微片首先查看是否有已成功预约的输出虚信道信息,即查看VCS值:如果为1则表示有分配结果,如果为0则没有预约结果。当头微片成功预约了输出虚信道后,体微片在时刻t1完成了开关分配并发送了AI信息,在t1+T体微片进行开关传输,与此同时体微片在时刻t1发送的AH信息已经完成了开关分配。因此在t1+2T时间内,体微片在路由器(2,1)只需要进行开关传输。所以同样减少了体微片在路由器中的关键路径时延。当 AI信息在路由器(2,1)中未完成提前虚信道的预约时,此时头微片到达路由器(2,1)后,按照BSTS算法进行虚信道分配和开关分配。图2给出的是一个微片在3个路由器中流水线例程示意图,但是在路由器(2,1)中仍有其它端口微片进行AI的发送,图中未给出。
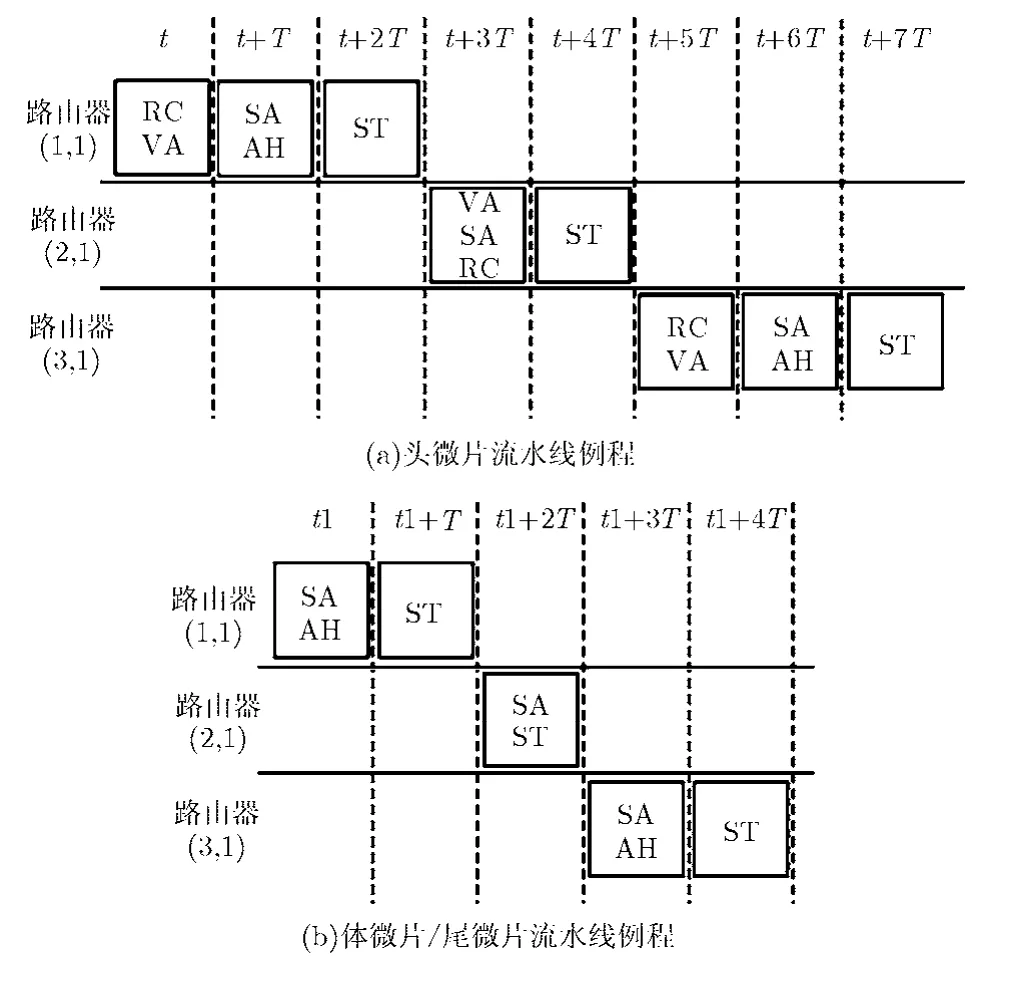
图2 微片流水线图
2.3 SAAH分配规则
由于每个时钟周期只能从一个端口的虚信道缓存中读取一个微片进行传输,因此AI信息分配规则为:(1)对于只有头微片请求来说,如果有多个微片完成开关分配,那么根据微片所在缓存对应的 IBL信息进行AI信息的选择,IBL值大的对应微片优先发送AI信息,相等情况按照等概率进行选择。如图3(a)中的同类微片SAAH操作,端口0内的缓存1对应的IBL值大,因此发送AI信息;(2)对于有头微片、体微片以及尾微片共存的情况,头微片优先发送AI信息。如图3(a)多类微片的SAAH操作,端口0的缓存0是头微片的请求,因此优先发送AI信息;(3)对于只有体微片或尾微片,那么对应的头微片已完成虚信道预约的微片优先发送AI信息,否则操作与同类微片的类似。
AI信息所在节点的分配规则:(1)一个输出端口收到多个AI和本地输入缓存的请求,输出端口按照ABL值进行选择,如果ABL值比本地IBL值大,那么选大ABL值对应AI请求,相等按等概率进行选择;如输出端口只收到本地缓存请求,分配单元按收集的NBL参数进行选择。如图3(b)响应过程,输入端口2缓存0对应的NBL值小于输入端口1的 NBL值,因此输出端口 1优先响应输入端口 1的2号队列AI请求;(2)输入端口收到多个响应,优先接受本地缓存ABL值大对应AI请求作为响应,相等按等概率选择,如图3(b)接受操作。输入端口1的0号输入缓存ABL值大于缓存1的ABL值,因此优先接受输入缓存 0;(3)输入端口接收到的响应包括AI响应和本地缓存响应两类,输入端口优先接受AI响应。例如图3(b)输入端口2的缓存1优先接受输出端口2的响应。
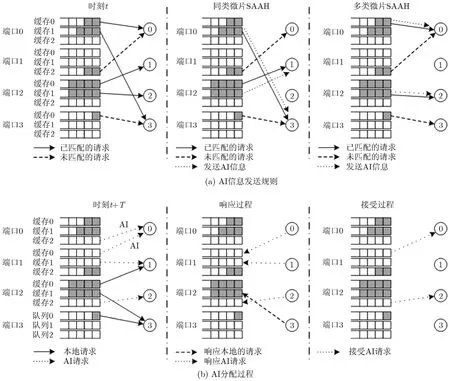
图3 SAAH分配例程
3 仲裁算法的设计
针对SAAH的分配规则,提出了适用于PAPR的仲裁算法BSTS。该算法用于AI分配节点以及非AI请求的分组分配。AI分配节点首先按照本地IBL进行选择。按照以下两种情况进行仲裁:
(1)对于头微片,仲裁单元按照本端口内IBL值进行仲裁,如果头微片所在队列的IBL值都不相等,那么IBL值大的对应虚信道缓存优先发送AI信息,否则按照等概率方式进行选择;
(2)对于体微片/尾微片,仲裁单元首先根据该队列是否有成功预约的VCS信息,如果有多个队列都有预约成功的VCS信息,那么按照IBL值大的对应虚信道缓存优先发送AI信息,否则按照等概率方式进行选择;如果没有预约成功的VCS信息则不进行本地AI信息的仲裁。对于完整仲裁过程表述为:虚信道仲裁及开关仲裁算法设计采用两阶段仲裁模式,第1阶段为输出端口的仲裁,第2阶段为输入端口的仲裁。该算法可以按照仲裁过程分为3个步骤,第1步主要完成用于仲裁过程相关信息的初始化,第2步完成输出端口对输入请求的响应过程,第3步完成输入端口最后对输出响应的接受过程即匹配,3个步骤详细描述如下:
第1步 初始化请求矩阵RST、响应权值矩阵GRT以及接受权值矩阵APT, RST记录输入端口到输出端口的请求情况,GRT记录仲裁过程使用的相邻端口的NBL信息,APT记录仲裁使用的本地端口IBL信息。当第1步完成之后,算法执行第2步;
第2步 输出端口根据RST元素对应的响应权值进行仲裁,如果有多个AI类型的请求,那么优先响应AI对应NBL最大的请求,如果AI类型请求对应的NBL最大值相等,则按随机规则进行仲裁;对于非AI类型的请求,按GRT列NBL元素最大值进行仲裁,如果对应请求NBL相等,则按随机规则进行仲裁,当响应完成后,算法执行第3步;
第3步 输入端口根据APT元素对应的接受权值进行仲裁,如果有多个AI类型的响应,那么优先响应AI对应IBL最大的请求进行仲裁,对于IBL值相等则按随机规则进行仲裁;对于非AI类型的请求,按APT行元素最大IBL值进行仲裁,如果行元素IBL值相等则按随机规则进行仲裁。当第3步完成之后,算法重新执行第1步。
4 仿真环境及参数配置
NoC的主要性能指标包括平均端到端时延、吞吐、缓存等待时延、链路利用率以及缓存利用率;为对比基于 BSTS仲裁算法的 PAPR路由器性能(PAPR-BSTS),分别对经典的4阶段虚信道路由器和PAPR进行了仿真。经典虚信道路由器分别采用轮询仲裁算法(GVCR-RR)和两次迭代的iSLIP[12]仲裁算法(GVCR-iSLIP-2)。仿真基于8×8 2D Mesh网络,软件平台为网络仿真软件 OPNET。路由器每个输入端口设置4条虚信道,每条虚信道的缓存深度为8个微片。分组的长度为16个微片,分组到达过程服从 Poisson分布。合成流量模式在空间的分布包括:均匀流量模式、矩阵转置流量模式以及龙卷风流量模式[13]。路由算法采用当前 Mesh网络中普遍采用的维序X-Y路由算法。另外我们采用了两类实际应用驱动流量模型:MPEG-4和视频对象平面解码(Video Object Plane Decoder, VOPD)。采用文献[13]中的配置方法将MPEG-4实现在4×3 NoC平台上,将VOPD实现在4×4的NoC平台上。这种模型是根据特定环境中所使用器件的专有流量模型,正是由于它的特定应用才使得仿真中比合成流量模型更复杂更具有实际意义。
5 仿真结果与分析
图4(a)和图4(b)为3种合成流量模式下网络时延和吞吐曲线。与iSLIP两次迭代的GVCR网络相比,PAPR路由器对平均端到端时延和吞吐率性能都有很大改善,平均端到端时延和吞吐能够改善24.5%和27.5%;与RRM的GVCR相比,时延和吞吐能够改善39.2%和47.2%。图4(c)所示为MPEG-4流量模型时延吞吐曲线,由图可知,当网络的吞吐率大于46 Gbit/cycle时,网络开始饱和时延呈指数上升,随着饱和程度进一步增大,由于PAPR路由器能充分利用路由器缓存资源,可减少空闲缓存概率。当吞吐率为 60 Gbit/cycle时,采用 PAPR路由器网络时延为63个周期,而采用GVCR路由器网络的时延为402个周期。整个网络的饱和时延平均降低了29.2%。图4(d)所示为VOPD流量模型的时延吞吐曲线,由图可知,当网络的吞吐率小于307.4 Gbit/cycle时,分组中在网络中竞争不明显,时延相差不大。随着饱和程度的进一步增大,当吞吐率大于360.2 Gbit/cycle时,采用GVCR路由器的网络平均时延迅速增大。当网络吞吐率为 388.6 Gbit/cycle网络进入饱和,在达到相同的饱和状态下PAPR网络的平均时延降低了35.1%。这是因为PAPR路由器在低负载及中度负载的情况下,提前分配机制一方面降低了路由器的关键路径时延,另一方面可保证下游路由器空闲虚信道得到充分利用,而仲裁过程微片数目多的缓存又可保证较高的优先级,因此缓解了路由器端口内缓存的阻塞问题。这与文献[9,10]不同,文献[9]中的投机路由器结构是对新到来的微片进行投机,以此达到虚信道分配和开关分配的并行,但是当网络进入饱和后,由于端口内的竞争较激烈,所以投机不成功的概率增大,当开关投机不成功时必须重新进行开关分配,而且投机过程中对微片所在的队列未进行区分等级,因此性能降低。这种路由器与经典虚信道路由器相比,平均时延降低17.2%,吞吐率提高18.9%;文献[10]中采用分类投机方式缩短路由器流水线深度,这种路由器对投机和非投机的请求设置不同优先级,请求的优先级可根据不同仲裁单元而动态变化,所以网络投机成功性能得到提升,但是网络负载较大时,分类投机成功的概率仍会降低。与经典虚信道路由器相比,平均时延降低19.2%,吞吐率提高20.5%。总体来说,这两类路由器在高负载情况下投机成功的概率大大降低,所以当网络注入继续增大时性能提升不明显。另外在仲裁过程中未考虑缓存的实时信息情况,投机过程导致了分组对缓存利用并不公平,所以路由器缓存利用率并不高。PAPR路由器的提前分配机制可提供尽最大努力缩短流水,仲裁过程参考了缓存信息,平均时延降低了 25.4%,吞吐率提高了26.8%。因此PAPR路由器性能优于文献[9,10]中提出的路由器结构。
文献[9]的投机路由器在投机过程未考虑微片在两个阶段仲裁缓存空闲情况,例如:两个分组可能同时请求同一个输出端口,但其中1个分组占用多个路由器节点缓存,而另1个分组未占多个路由器缓存,如前者投机失败则导致1个分组占用多个缓存。最终降低链路利用率。另外基于维序X-Y算法的2D Mesh网络中X与Y维链路利用率并不均衡,投机路由器并不能缓解这种情况。为分析PAPR对网络链路利用率的影响,取图 4(a)所示均匀流量模式下注入速率为0.025,该配置可使网络工作在饱和状态下。图5所示为8×8 Mesh网络中心区域的36条LU(Link Utilization)示意图,对于大多数中心区域链路来说,与GVCR-iSLIP-2相比,PAPR路由器提高了网络的LU,这使得分组通过网络中心区域的概率增大,缓解了中心区域链路的压力并提高了网络资源的利用率。
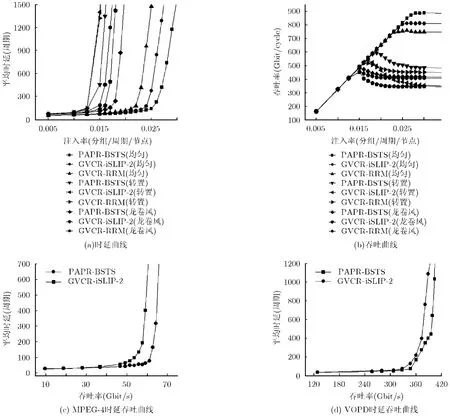
图4 不同流量模式的网络性能曲线
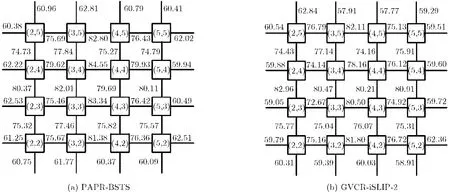
图5 均匀流量模式下的链路利用率示意图
文献[10]分类投机路由器当网络负载较大时,虽可使投机请求具有较高优先级来提高性能,但会使队列等待时间并不公平,分组平均队列等待时间反而会增大,缓存利用率降低。为研究PAPR在等待时延性能的改善,图6给出网络中心节点(3,3)两个队列等待时间曲线,很明显PAPR降低了每个缓存的分组等待时间,一是因为提前分配策略能尽力而为利用空闲缓存;另一方面,在网络接近饱和时,头微片预约的虚信道缓存仍处于空闲而不能被后续微片利用,而新仲裁机制可缓解空闲虚信道缓存的阻塞问题,提前释放虚信道,提高资源利用率。因此进一步给出(3,3)节点两个输出方向的平均缓存利用率,如图7所示,与GVCR-iSLIP-2相比,PAPR未降低每个虚信道缓存处于0-6个微片空闲状态的概率,但降低了缓存处于7-8个微片空闲的概率,即大大降低了缓存完全是空的概率,这与新仲裁设计目标相吻合,结果表明PAPR将端口内缓存平均利用率最大可提高4.5%。
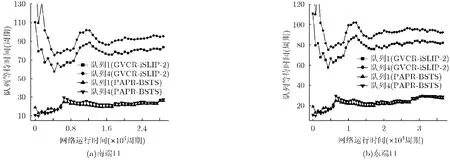
图6 均匀流量模式下的缓存等待时间
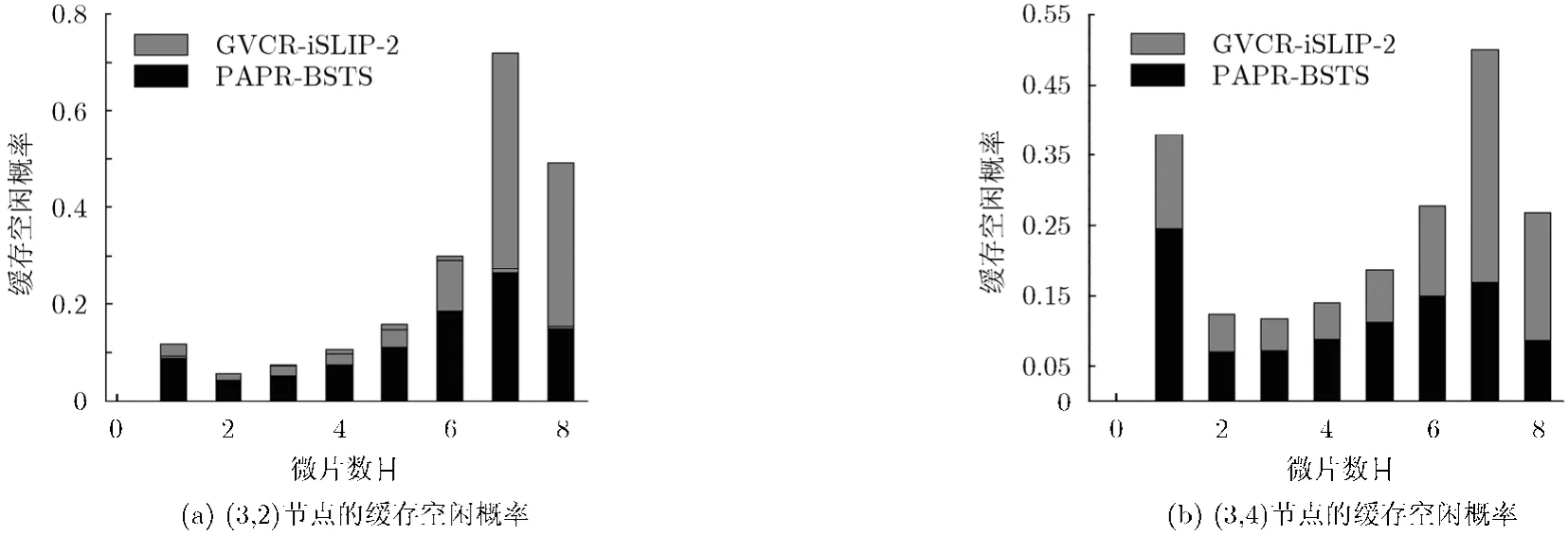
图7 缓存空闲概率
6 硬件及功耗开销
由上节的仿真结果可知,与经典虚信道路由器相比,PAPR路由器性能优势明显。本节主要说明PAPR路由器的实现成本代价,使用Verilog硬件表述语言对以上两种路由器模型进行建模,采用 ISE 11.3.0工具,在 Xilinx公司 Virtex 5系列的XC5VFX70T芯片上进行了设计实现,综合仿真结果如表1所示。综合结果显示,与采用两次迭代的经典虚信道路由器相比,PAPR查找表(逻辑单元)只增加了8.7%,而寄存器单元只增加了0.32%。可见采用提前分配路径的PAPR路由器硬件成本增加很少。
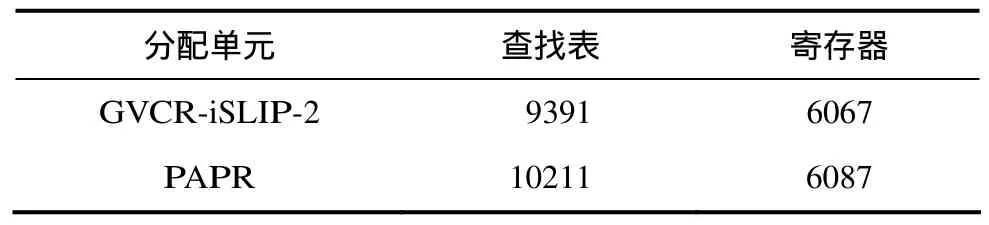
表1 硬件资源消耗对比
通过功耗仿真软件Orion2.0[14],在45 nm工艺下我们对8×8 2D Mesh网络中单个路由器的平均功耗进行了仿真,仿真结果如表2所示,与GVCRRR相比,GVCR-iSLIP-2功耗增加了1.7%, PAPR路由器功耗增加了5.9%。可见采用提前分配路径的PAPR路由器功耗增加很少。

表2 路由器平均功耗(W)
7 结论
片上路由器是片上网络研究的关键问题之一,路由器的性能影响着片上网络的最终性能。本文针对经典虚信道路由器存在的问题,根据分组在网络路径中的分布特性,提出一种提前分配路径的虚信道路由器。通过将网络中缓存信息引入到路由器的仲裁中,不但降低了分组在网络中关键路径时延,而且缓解了空闲虚信道阻塞带来的虚信道利用率低的问题。仿真结果表明,本文提出的路由器结构在相同的网络配置下,网络时延可降低 24.5%,吞吐率提高 39.2%,端口平均缓存利用率最大可提高4.5%。综合结果表明,PAPR导致路由器逻辑只增加8.7%,路由器平均功耗增加仅为5.9%。
[1]冯超超, 鲁中海, 张民选, 等. 片上网络中一种单周期 2 GHz无缓冲路由器[J]. 国防科技大学学报, 2011, 33(6): 43-47.
Feng Chao-chao, Lu Zhong-hai, Zhang Min-xuan,et al..A 1-cycle 2 GHz bufferless router for network-on-chip[J].Journal of National University of Defense Technology, 2011,33(6): 43-47.
[2]齐树波, 李晋文, 乐大珩, 等. 面向片上网络路由器漏流功耗优化的自适应缓冲管理策略[J]. 计算机研究与发展, 2011,48(12): 2400-2409.
Qi Shu-bo, Li Jin-wen, Yue Da-heng,et al..Adaptive buffer management for leakage power optimization in NoC routers[J].Journal of Computer Research and Development,2011, 48(12): 2400-2409.
[3]李丽, 万健, 王佳文, 等. 基于包-电路交换的片上网络回退转向路由算法[J]. 电子与信息学报, 2011, 33(11): 2759-2763.
Li Li, Wan Jian, Wang Jia-wen,et al..NoC retrograde-turn routing algorithm based on packet-circuit switching[J].Journal of Electronics&Information Technology, 2011,33(11): 2759-2763.
[4]常政威, 熊光泽, 桑楠, 等. 基于电压岛的能量和可靠性感知NoC映射[J]. 计算机辅助设计与图形学学报, 2009, 21(1):19-26.
Chang Zheng-wei, Xiong Guang-ze, Sang Nan,et al..Energy-and reliability-aware mapping for NoC implemented with voltage islands[J].Journal of Comuputer-Aided Design&Computer Graphics, 2009, 21(1): 19-26.
[5]王坚, 李玉柏, 蒋勇男. 片上网络通信性能分析建模与缓存分配优化算法[J]. 电子与信息学报, 2009, 31(5): 1059-1062.
Wang Jian, Li Yu-bai, and Jiang Yong-nan. Communication performance analytical model and buffer allocation optimizing algorithm for network-on-chip[J].Journal of Electronics&Information Technology, 2009, 31(5):1059-1062.
[6]葛芬, 吴宁. 面向特定应用的片上网络低能耗拓扑生成方法[J]. 系统工程与电子技术, 2010, 32(8): 1754-1759.
Ge Fen and Wu Ning. Low energy topology generation approach for application-specific network on chip[J].System Engineering and Electronics, 2010, 32(8): 1754-1759.
[7]Dally W J. Virtual-channel flow control[C]. IEEE the 17th Annual International Symposium on Computer Architecture(ISCA), Seattle, Washington, 1990: 60-68.
[8]Daniel U B and Dally W J. Allocator implementations for network-on-chip routers [C]. IEEE the Conference on High Performance Computing Networking, Storage and Analysis(SC), Portland, USA, 2009: 1-12.
[9]Peh L S and Dally W J. A delay model and speculative architecture for pipelined routers[C]. IEEEInternational Symposium on High-Performance Computer Architecture(HPCA), Leone, Mexico, 2001: 255-266.
[10]Mullins R, West A, and Moore S. The design and implementation of a low-latency on-chip network[C]. Asia and South Pacific Conference on Design Automation(ASPDAC), Pacifico, Yokohama, 2006: 24-27.
[11]Matsutani H, Koibuchi M, Amano H,et al.. Prediction router: yet another low latency on-chip router architecture[C]. IEEE International Symposium on High Performance Computer Architecture(HPCA), Raleigh, North Carolina,USA, 2009: 367-378.
[12]McKeown N. The iSLIP scheduling algorithm for inputqueued switches[J].IEEE Transactions on Networking,1999, 7(2): 188-201.
[13]邓植, 顾华玺, 杨银堂, 等. 基于拓扑划分的片上网络快速映射算法[J]. 电子与信息学报, 2011, 33(12): 3028-3034.
Deng Zhi, Gu Hua-xi, and Yang Yin-tang. A fast topology partition based mapping algorithm for Network-on-Chip(NoC)[J].Journal of Electronics&Information Technology,2011, 33(12): 3028-3034.
[14]Wang H, Zhu X, Peh L S,et al..Orion: a powerperformance simulator for interconnection networks[C].IEEE Internation on Microprocessor, Istanbul, Turkey,2002: 294-395.
猜你喜欢
科教新报(2022年24期)2022-07-08
作文小学中年级(2021年10期)2021-12-26
科教新报(2021年23期)2021-07-21
恋爱婚姻家庭·养生版(2021年5期)2021-05-31
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
电子制作(2018年19期)2018-11-14
武大国际法评论(2017年1期)2018-01-23
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
