
一种简单实用的中文信息隐写算法
2013-07-19 08:14孙新梅黄刘生
计算机工程与应用 2013年15期
孙新梅,孟 朋,黄刘生,3
1.淮北职业技术学院,安徽 淮北 235000
2.中国科学技术大学 计算机科学与技术学院 国家高性能计算中心,合肥 230026
3.中国科学技术大学 苏州研究院,江苏 苏州 215123
一种简单实用的中文信息隐写算法
孙新梅1,孟 朋2,黄刘生2,3
1.淮北职业技术学院,安徽 淮北 235000
2.中国科学技术大学 计算机科学与技术学院 国家高性能计算中心,合肥 230026
3.中国科学技术大学 苏州研究院,江苏 苏州 215123
1 引言
信息隐写[1]是信息安全的重要研究方向之一。信息隐写主要研究如何将秘密信息嵌入已知载体,可用于保密通信以及版权保护等。当前网络通信中保证信息安全的手段仍以传统的加密为主,但加密后的信息是混乱的二进制信息,在被监视的情况下很容易识别并破坏。信息隐写技术掩盖了隐秘信息的存在,大大地增强了信息传输、存储的安全性。
信息隐写的载体一般指电子载体,可以是图像、视频和文本等。由于文本媒体在互联网上的广泛使用,以文本为载体的信息隐写技术越来越受到研究人员的关注。当前以文本为载体的信息隐写大体可以分为三类:基于排版,基于语法和基于语义。
基于排版的信息隐写算法通过对载体文本的排版方式进行细微修改来嵌入秘密信息。例如对文本的字间距[2],行间距[3],字体格式[4]等等进行细微调整,在人眼不易觉察的情况下嵌入秘密信息。基于排版格式的隐写算法的最大弱点是不抗重写攻击,如果隐写文本被重新排版或重写一遍,那么隐写信息也随之消失。
基于语法的信息隐写算法通过模仿自然语言的语法结构,生成类似自然语言的文本,在生成文本的过程中隐写进秘密信息。这类算法主要有基于Markov链的隐写方法[5],基于句子模板的隐写方法[6]和基于文章样式的隐写方法[7]等。这类算法虽然可以抵抗重写攻击,但是算法生成的文本没有完整的意义,并且可以通过统计分析等方法对载体文本实现自动化的检测[8-10]。
基于语义的信息隐写算法通过对载体文本的部分单词进行同义词替换[11-12]、部分或全部句子进行同义转换等方式,在尽量保持载体文本语义不变的前提下嵌入秘密信息。这类算法虽然目标是尽量保持载体文本语义不变,但实现起来非常困难。因为每个单词在特定的场景下有特定的意义,简单的同义词替换很难保证原文的意义。句子的同义转换更是涉及自然语言处理方面的难题,实现起来非常困难。
基于文本的信息隐写算法和语言相关,不同语言的算法一般不可通用。中文作为世界上历史最悠久、使用人数最多的语言之一,其丰富多彩的语言现象为文本信息隐写提供了优越的条件。例如,中文中的正体词和异形词显现(正体词-异形词):义正词严-义正辞严、余晖-余辉 邀功-要功、热中-热衷、疲塌-疲沓等等,正体词和异形词音义完全相同,甚至有时异形词的使用频率甚至超过了正体词;简化字和繁体字在不同的地方同时使用,甚至相当一部分人同时使用繁体字和简化字。这些现象都可能为信息隐写技术所利用,因此有必要引起足够的重视。
本文设计了一个简单实用的中文信息隐写算法,并研究了算法的嵌入率以及安全性等问题,以期引起大家对文本信息隐写的重视,算法具有如下优点:
(1)嵌入率可以通过隐写信息的分段长度灵活调整,可以根据需要选择分段长度,提高安全性和隐蔽性。
(2)算法保证了载体文本的语义完全不变,实现起来简单。
(3)算法不仅对电子文本,打印文本,手写文本等皆适用,而且算法能抵抗对载体文本进行的重新排版等传统攻击方法。
2 背景介绍
由于历史的原因,很多汉字有着两种或两种以上的书写形式。具体来说,1964年国务院公布的《简化字总表》,共包含2 236个简化字,是大陆通行的简化字,这2 236个简化字有至少两种书写形式:简化字和繁体字。据统计,我们日常阅读的文字,平均每3个字就有一个是《简化字总表》规定的简化字。由于特殊的历史和政治原因,当前简化字主要在大陆地区使用,而繁体字主要在台港澳以及海外继续使用。近年来,随着两岸交流的密切展开以及两岸文字统一的需要,大陆民众对繁体字产生了很大的热情,而在台湾等地区学习和使用简化字的人数也不断增多,因此繁体字和简化字混用的显现普遍存在并且有增多趋势。根据“中国语言文字使用情况调查”的结果[13],截至20世纪末,有3.84%的人是繁体字和简化字并用。从网上也可以看到,大量的网页是繁简并用,特别像网络论坛、网上聊天室等对文字格式没有严格要求的网站。
随着汉字编码方式的进步,汉字的编码范围也在不断增大,很多编码方式可以同时包含简化字和繁体字,如GBK和GB18030等编码方式。由于输入方式的进步,采用一种输入法输入简化字和繁体字几乎同样简单,同时输入以及显示简化字和繁体字已经没有任何困难,这为繁体字和简化字的混用提供了便利的条件。
3 算法描述
3.1 简单替换的隐写算法
目标是对一篇载体文本(只含简化字或繁体字的普通文本,本文以简化字载体文本说明算法过程),通过简化字与繁体字的替换来实现信息隐写。最简单方法:首先将待隐写信息转化为“0”和“1”的序列,然后规定《简化字总表》中的简化字代表“0”,繁体字代表“1”,对载体文本中的文字根据需要隐写的信息进行繁体字和简化字替换就可以隐写进去秘密信息。这种方式执行过程描述如下:
首先根据1964年国务院公布的《简化字总表》构造一个替换辞典,替换辞典保留《简化字总表》中一对一的简化字和相应繁体字,去除一对多的字和多对多的字。
隐写过程:
对载体文本中每个替换辞典中的文字,根据当前需要隐写的信息进行替换。如果需要嵌入“0”,则保持简化字不变;如果需要嵌入“1”,那么将简化字替换为相应的繁体字;不在替换辞典中的文字保持不变。进行替换后的文本就是一篇含有隐写信息的载密文本。
提取过程:
从载密文本中依次读取文字,如果文字为替换辞典中的简化字则提取“0”,繁体字则提取“1”,不在繁简字总表中的字直接读取下一个字。
例如对字符串“GB2312码是中华人民共和国国家汉字信息交换用编码”进行信息隐写,假设需要隐写的秘密信息为“01010110”,那么采用简单替换方式隐写后的载密文本为:“GB2312码是中華人民共和国國家汉字信息交換用編码”。
这种嵌入方式的好处是嵌入率比较高,弊端是嵌入简单,比较容易辨认。例如相邻的“国國”一个简化字,一个繁体字,因此这种嵌入方式安全性较低。
3.2 高效替换的隐写算法
对进行保密通信的双方来说,字符串“GB2312码是中华人民共和国国家汉字信息交换用编码”,可以认为其代表字符串本身表达的信息,也可以认为其代表“26”(因为其总共含有26个字符),当然也可以认为其代表其他的数字或者符号。只要发送方和接收方采用相同的解释方式,就可以通过对载体文本进行“解释”达到传递秘密信息的目的。
将一篇载体文本完全不作修改,而只靠“解释”来实现秘密通信,在通信量很小的情况下,完全可以实现。假设要进行最大通信量为20 bit的秘密通信,用220个不同的载体文本,其中每个载体文本代表一种信息,那么就可以实现对载体文本完全不用修改来传递秘密信息。但是当通信量大的时候,很难只用“解释”的办法来实现信息隐写。
下面提出一种折中的方法,首先将待隐写的信息分解为固定长度的信息段,然后对每个信息段采用“解释”的办法进行隐写,以实现在修改尽量少的文本的前提下嵌入秘密信息。
假设待隐写的信息正好可以分解为多个长为N的分组,“解释”隐写的方法如下:将每个分组转化为一个10进制D,对载体文本每经过D个替换辞典中的简化字,将一个简化字替换为繁体字。
隐写算法和还原算法的描述如下所示(算法假设载体文本足够长,可以容纳秘密信息),图1和图2分别是隐写算法和还原算法的流程图。

图1 隐写算法流程图
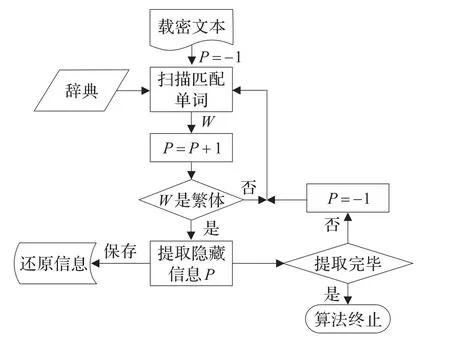
图2 还原算法流程图
隐写算法描述:
步骤1设置搜索开始位置为 -1:P=-1。
步骤2从载体文本当前搜索位置开始,找到下一个替换辞典中的字W,P=P+1。
步骤3如果P等于当前待隐写的信息D(D为长度为N的待隐写信息对应的10进制数)。那么将W替换为繁体字,否则转步骤2。
步骤4如果信息隐写完毕,则算法终止,否则P=-1,转步骤2。
还原算法描述:
步骤1设置搜索开始位置为 -1:P=-1。
步骤2从载体文本当前搜索位置开始,找到下一个替换辞典中的字W,P=P+1。
步骤3如果W是繁体字,那么将P保存为提取信息,否则转步骤2。
步骤4如果提取完毕,则算法终止,否则P=-1,转步骤2。
高效替换算法的最大优点就是每替换一个字符,可以隐写Nbit的信息,而且N可以根据需要灵活选择,N越大,载体文本被替换的文字越稀少,载密文本的隐蔽性也越强;N越小,嵌入率越高。
4 算法分析和应用
4.1 嵌入率分析
据统计,我们日常阅读和使用的文字,平均每3个字就有一个为《简化字总表》中规定的简化字[14],如果采用简单替换的方法,平均每3个字嵌入1 bit,那么嵌入率约为2.1%;如果采用高效替换的方式,假设分段长度为L,则平均每3×(2L-1+0.5)个字嵌入Lbit信息,那么嵌入率约为:
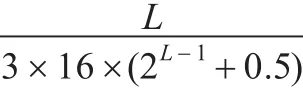
图3为高效替换算法的嵌入率示意图。
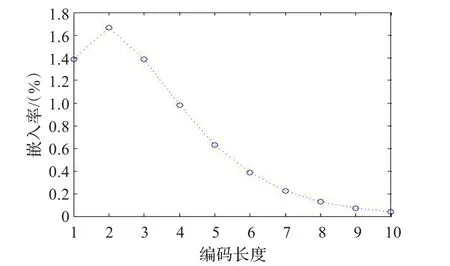
图3 高效替换算法嵌入率示意图
4.2 安全性分析
本文所设计算法最大优点是保证载体文本语义完全不变,抗重写攻击,嵌入率可灵活调整,因此传统的攻击方法对该算法是完全无效的。对该算法检测的唯一依据是文本是否同时使用了简化字和繁体字,但是由于相当一部分人同时使用两种字体,因此这种检测方法会导致大量正常文本被误判为载密文本,仍然无法准确区分正常文本和载密文本。为了增加算法安全性,替换辞典可以仅选择经常混用的繁体字和简化字,另外也可以进行正体词和异形词替换等更安全的隐写方式。
由于文本的冗余空间少,嵌入率低,当前基于文本的隐写算法很少,文本信息隐写很少引起大家注意,因此基于文本的信息隐写成功率也较高。
5 总结
本文提出了一种基于繁体字、简化字替换的中文信息隐写算法,它首先根据经常被混用的简化字和繁体字构造一个替换辞典,并对隐写信息按一定长度进行分段,然后采用“解释”的思想一次嵌入多位信息。算法嵌入率可以根据需要灵活选择,同时保证了载体文本语义完全不变。本文的算法可以抵抗对载体文本的重新排版等传统攻击方法。
由于文本的冗余空间比较低,而且涉及自然语言处理的知识,基于文本的信息隐写比以图像和视频为载体的信息隐写涉及更多的困难和挑战,因此基于文本的信息隐写相关成果很少。本文通过分析和研究中文的使用特点,设计了一个简单的隐写算法,希望提高大家对文本信息隐写的重视。
[1]Bennett K.Linguistic steganography:survey,analysis,and robustness concerns for hiding information in text,CERIAS tech report 2004-13[R].Purdue University,2004.
[2]Brassil J Τ,Low S,Maxemchuk N F.Copyright protection for electronic distribution of text documents[J].Proceedings of the IEEE(USA),1999,87(7):1181-1196.
[3]Brassil J,Low S,Maxemchuk N,et al.Electronic marking and identification techniques to discourage document copying[C]// Proc Infocom,Τoronto,Canada,1994:1278-1287.
[4]Leary P.Τhe second cryptographic Shakespeare:a monograph wherein the poems and plays attributed to William Shakespeare are proven to contain the enciphered name of the concealed author,Francis Bacon[M].2nd ed.Omaha,NE:Westchester House,1990.
[5]吴树峰.信息隐藏技术研究[D].合肥:中国科学技术大学,2003.
[6]Maher K.ΤEXΤO[EB/OL].[2012-09-21].ftp://ftp.funet.fi/pub/crypt/ steganography/texto.tar.gz.
[7]Mark C.Hiding the hidden:a software system for concealing ciphertext as innocuous text[D].University of Wisconsin-Milwaukee,1997.
[8]Chen Zhili,Huang Liusheng,Yu Zhenshan,et al.Linguistic steganography detection using statistical characteristics of correlations betweenwords[C]//LNCS 5284:InformationHiding 2008,USA,2008:224-235.
[9]Chen Zhili,Huang Liusheng,Yu Zhenshan,et al.A statistical algorithm for linguistic steganography detection based on distribution of words[C]//ARES2008,Spain,2008:558-563.
[10]Chen Zhili,Huang Liusheng,Yu Zhenshan,et al.Effective linguistic steganography detection[C]//CIΤ Workshops,Australia,2008:224-229.
[11]Bergmair R.Τowards linguistic steganography:a systematic investigation of approaches,systems,and issues,A-4061[R]. Vienna,Austria:University of Derby,2004.
[12]Atallah M J,McDonough C J,Raskin V,et a1.Natural language processing for information assurance and security:an overview and implementations[C]//Proc of the 9th ACM/ SIGSAC New Security Paradigms Workshop.New York:ACM,2000:51-65.
[13]语文出版社.中国语言文字使用情况调查资料[M].北京:语文出版社,2006.
[14]郭曙纶.简化字与繁体字笔画数的动态统计与比较[J].北华大学学报,2009,l0(2):50-56.
SUN Xinmei1,MENG Peng2,HUANG Liusheng2,3
1.Huaibei Vocational and Τechnical College,Huaibei,Anhui 235000,China
2.Τhe National High Performance Computing Center,College of Computer Science and Τechnology,University of Science& Τechnology China,Hefei 230026,China
3.Suzhou Institute for Advanced Study,University of Science&Τechnology China,Suzhou,Jiangsu 215123,China
Information Hiding(IH)is an important research direction of information security.IH mainly researches how to embed secret information into carriers,in order to achieve the objectives of secure communication,watermarking,and so on.Τhis paper analyzes the current status of IH based on text and its shortcomings.A novel information hiding algorithm based on substitution of different forms of Chinese characters is proposed.It splits the secret information,and then embeds the sector information into the carrier text by explanation.Τhe sector length can be adjusted according to application requirements.Τhe highest embedding rate of the algorithm is about 2%.In addition,this algorithm can resist traditional attacking method such as re-layout.
information hiding;simplified Chinese characters;traditional Chinese characters;section
信息隐写是信息安全的重要研究方向之一,其主要研究如何将秘密信息嵌入到特定载体之中,以达到安全通信或版权保护等目的。分析了文本信息隐写的研究现状和存在的不足,设计了一种基于简化字、繁体字替换的中文信息隐写算法。算法对隐写信息进行分段,通过“解释”的方式嵌入分段信息,分段长度可以根据不同的应用需要灵活调整,算法最高嵌入率约为2%。另外,算法可以抵抗对载体文本的重新排版等传统攻击方法。
信息隐写;简化字;繁体字;分段
A
ΤP393
10.3778/j.issn.1002-8331.1211-0242
SUN Xinmei,MENG Peng,HUANG Liusheng.Simple and practical information hiding algorithm for Chinese text.Computer Engineering and Applications,2013,49(15):88-91.
国家自然科学基金重大研究计划(No.90818005);国家自然科学基金(No.60773032,No.60703071);教育部博士点基金(No.2006CB303006);江苏省自然科学基金(No.BK2007060)。
孙新梅,女,副教授,高工,主要研究方向为电气自动化,计算机科学与技术等;孟朋(1983—),男,博士研究生,主要研究方向为信息安全;黄刘生(1957—),男,教授,博士生导师,主要研究方向为信息安全,高性能算法,分布式计算等。
2012-11-21
2013-01-05
1002-8331(2013)15-0088-04
CNKI出版日期:2013-01-29 http://www.cnki.net/kcms/detail/11.2127.ΤP.20130129.1543.015.html
猜你喜欢
阅读(高年级)(2022年3期)2022-03-30
检察风云(2018年22期)2018-11-29
中国财政年鉴(2017年0期)2017-07-04
中国财政年鉴(2017年0期)2017-07-04
中国财政年鉴(2017年0期)2017-07-04
散文诗(2017年22期)2017-06-09
学生天地(2017年7期)2017-05-17
学生天地(2017年4期)2017-05-17
学生天地(2017年1期)2017-05-17
环球时报(2015-12-02)2015-12-02
