
基于PAD三维情绪模型的情感语音韵律转换
2013-07-11 09:36:44鲁小勇杨鸿武郭威彤
计算机工程与应用 2013年5期
鲁小勇,杨鸿武,郭威彤,裴 东
1.西北师范大学 计算机科学与工程学院,兰州 730070 2.西北师范大学 物理与电子工程学院,兰州 730070
基于PAD三维情绪模型的情感语音韵律转换
鲁小勇1,杨鸿武2,郭威彤2,裴 东2
1.西北师范大学 计算机科学与工程学院,兰州 730070 2.西北师范大学 物理与电子工程学院,兰州 730070
1 引言
语音信号不仅包含了要表达的文本内容,而且还蕴含了大量的情感信息。而情感信息不仅是语音自然度和表现力的重要组成部分,更是人类智能的重要表现方面之一。
目前的合成语音系统,虽然在可懂度和自然度上已普遍被用户所接受,但合成语音仍主要以中性语调(Neutral Intonation)的方式呈现给用户,缺乏丰富的情感表达。因此,高表现力语音合成的研究成为了近年来言语工程领域中一个重要的研究热点[1]。情感语音的合成主要采用基于隐马尔可夫模型的统计参数语音合成方法[2]和基于大规模语料库的拼接语音合成方法[3]。前者虽然能够利用说话人自适应变换[4-5]等方法实现情感语音的合成,但统计参数语音合成的音质仍难以被用户接受。拼接语音合成方法虽然能获得高质量的合成语音,但录制不同情感的语料库非常困难。为此,部分研究提出了通过韵律转换实现情感语音合成的方法。文献[6]选取了喜、怒、哀、乐四种基本情感,进行了相应的韵律及情感特征研究。文献[7-8]将PAD三维情绪模型引入高表现力语音合成,文献[9]利用PAD三维情绪模型实现了情感语音的转换,文献[10]利用SVR预测情感韵律参数。但以上的工作缺乏对基频曲线的建模,只能简单修改基频均值、斜率等参数,不能修改基频包络的形状,而基频包络的形状在不同情感的表达中起着重要的作用。
为了在情感语音的转换中,能够对基频包络进行转换,设计了11种典型情感的文本语料,录制了相应的语音语料,采用心理学的方法标注了语音语料的PAD值,运用五度字调模型[11]建立了音节的基频模型,并利用广义回归神经网络(Generalized Regression Neural Network,GRNN)构造了情感语音韵律参数的预测模型。根据语句的PAD值和语境特征预测目标情感语音的韵律参数,采用STRAIGHT[12]算法实现情感语音的转换。实验结果表明,提出的方法得到的转换后的语音,能够较好地表现出相应的情感。
2 PAD三维情绪模型
情感描述[13]的主要方法包括离散的情感范畴表示方法和在连续变化的维度上描述情感的维度表示方法。范畴描述的方法无法表示出情感之间的相对关系及变化,也难以描述混合情感的情况。因此,本文采用了PAD三维情绪模型来描述情感语音,以便能将情感语音的研究扩展为量化情感的计算性研究。
PAD三维情绪模型[14]由三个维度组成:(1)愉悦度(Pleasure-Displeasure),表示情绪状态的正、负性;(2)激活度(Arousal-Nonarousal),表示情绪生理激活水平和警觉性;(3)优势度(Dominance-Submissiveness),表示情绪对他人和外界环境的控制力和影响力。
在PAD三维情绪模型中,每一种情感都与PAD空间中的位置相对应。当PAD得分被标准化以后,可以用一组三维坐标来唯一表示。三维坐标具有高置信度的评价,三个维度基本独立。而且,PAD情感坐标的评定是通过一套精心设计的量表来完成的,每一种情感都可以看作是在PAD三维坐标系中的一个点。Mehrabian[14]提出了简化版本的PAD情感量化表,总结出了常见情感状态和对应的PAD坐标之间的映射关系。中科院心理所又进一步对简化版PAD情感量表进行了中国化的修订,得到了适用于评定中国人和汉语情感的量化表。
3 语料库的建立与PAD评定
3.1 文本语料设计
文本语料的设计,要以有利于情感的激发与保持为首要目标,还要兼顾可能产生影响的语音学和心理学要素,以及保证与PAD三维空间中选取的典型情感的一致性。同时,情感在PAD情感空间上的选取不能只局限于基本感情,选择时需要尽量分布均匀,区分性要强。为了能够收集到最自然的情感语音,避免语义因素和音素固有声学特征的影响,从PAD三维空间的每个象限中各选取了能够代表该象限的一至两种常见情感,共10种,分别包括放松、惊奇、温顺、喜悦、轻蔑、厌恶、恐惧、悲伤、焦虑、愤怒。再加上中性情感,共选取了11种典型情感。
文本语料的内容既要考虑需要具有一定长度,还要具备丰富的情感特征。在文本语料的设计方案中,采用了将无情感偏向的句子嵌入到含有11种典型情感的语段中的方式。这样处理,比单个孤立的句子更容易激发出所需要的情感特征。实验中为每种情感各设计了10个基于特定情景的情感语段,每个情感语段各嵌入一个无情感偏向的语句,最后形成110个不同的语段。在无情感偏向的语句选取上,采取长短结合的方法,有5到6个语句较长,约为150个音节;有4到5个语句较短,约为50个音节。这样,共设计得到了约2 200个音节。
每种情感语段的语境信息,包括音节的声调和位置信息,都利用自己开发的基于TBL算法的韵律边界标注工具[15]和文本分析工具标注并手工校对。

表1 部分情感的文本语料
3.2 语音语料的录制
在特定的情景下,情景激发[9]的方式比直接地要求产生一种情感更加容易,并且得到的语音表达也更自然真实。因此,借鉴心理学领域的经验,通过内心模拟情景的方式来激发所需情感。
在录音中,选择了一位女性普通话录音人在录音棚中录音,录音人不是专业演员。要求首先录制中性语音,然后录制情感语音。在录制中性语音时,要求录音人用无表情的、语调和语速基本不变化的方式朗读录音文本。在录制其他10种情感语音时,首先设置特定的场景激发出录音人相应的情感表露,然后再去朗读文本并录音。比如,在录制悲伤情感语音时,利用观看悲伤的电影片段、观看悲伤的图片等来激发出录音人的悲伤情感。录音人的情感被激发出来后,让录音人按照自然的情感表达方式说出10段情感语句。实验最终录制的语音用16 kHz采样、16 bit量化后以单声道WAV文件格式保存。
3.3 PAD评定
语音语料录制结束后,采用中科院心理所改进的汉化版情感量表[16]评测了录制的语音语料的PAD值,如表2所示。从表2可以看出,录制的情感语音基本表达了选取的11种情感。
4 基于GRNN的情感语音韵律转换框架
4.1 转换框架
提出了一种基于GRNN的情感语音韵律转换框架,如图1所示,包括训练和转换两部分。

图1 情感语音韵律转换框架图
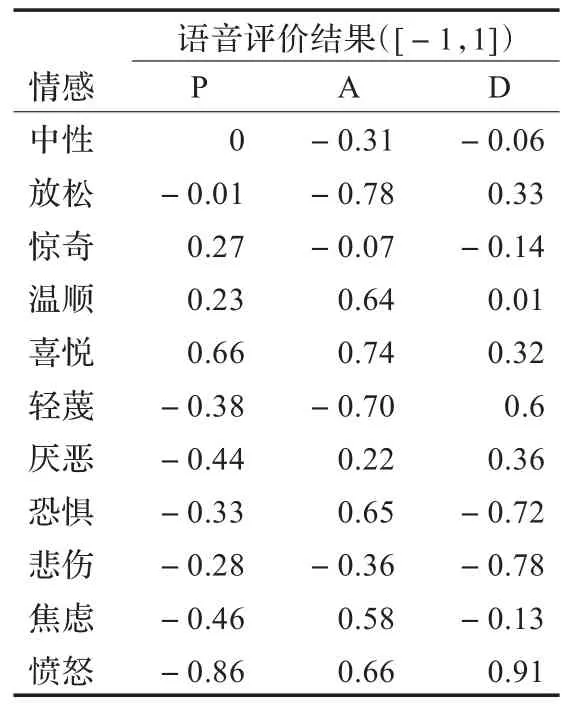
表2 语音语料库中无情感偏向文本的11种情感PAD得分
在训练过程中,首先从文本语料中提取音节的语境特征参数,将每个音节的语境参数和评定所得到的语句的PAD值作为训练GRNN的输入参数。同时,从语音语料提取音节的基频曲线、时长和停顿时长,利用五度字调模型对基频曲线建模,将模型参数和时长、停顿时长作为GRNN的输出参数。利用输入参数和输出参数,训练转换模型。
在转换阶段,首先根据文本语料获得待转换语音的音节语境参数,与目标语音的PAD值同时作为GRNN的输入参数,来预测目标情感语音的音节的五度字调模型参数、时长和停顿时长,并利用五度字调模型生成目标语音的音节基频包络。同时,对待转换语音,利用STRAIGHT获得语音的频谱参数和非周期索引。最后,利用生成的基频包络、预测的时长和停顿时长以及STRAIGHT分析获得的频谱参数和非周期索引,合成出目标情感语音。
4.2 基于五度字调模型的基频建模
因生理、年龄等方面存在差异,人的音高变化也不近相同。但对于一个特定的人或一群人来说,可以找到一个音高的基准值,语流的音高是在此基准值上下变动。而且,声调的音高变化范围是相对稳定的,有一定的调域存在。对某一声调的单音节而言,发音人不同和时长不同时,基频的依时变化虽有差异,但大体趋势是相同的,即调型大体相同。基于此,本文利用式(1)所示的归一化五度字调模型,来刻画不同调值的基频曲线。

其中,t是归一化的时间,范围为[ ] 0..1。fc是对数表示的体现嗓音高低的中值基频,fd是对数表示的基频变化的调域,f0i(t)是一个如式(2)所示的四次曲线,代表四个声调的调型函数,i代表阴平、阳平、上声、去声四种声调。F0i(t)是生成的基频曲线。
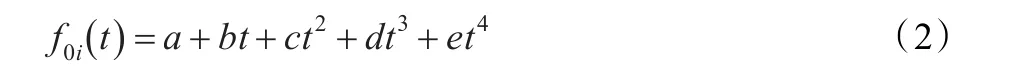
利用原始基频值,得到每个音节的基频中值及调域。然后,根据音节基频点数算得相应音节的归一化时间,通过式(2)拟合求得基于音节的四次多项式系数。最后,再通过式(1)在归一化时间下得到基于五度字调模型的音节基频曲线。
4.3 基于GRNN的预测模型
4.3.1 GRNN的结构
1.1 一般资料 2010年10月至2015年3月共30例恶性肿瘤患者治疗前后在复旦大学附属中山医院核医学科行18F-FDG PET/CT显像,其中男性20例,女性10例;年龄15~87岁,平均(56.17±14.96)岁。30例中,肺癌5例,胰腺癌4例,非霍奇金淋巴瘤19例,慢性淋巴细胞白血病/小B细胞淋巴瘤1例,背部多形性未分化肉瘤1例。
GRNN是一种基于径向基函数网络结构的神经网络,利用非线性回归理论,从训练数据中估计输入输出之间的映射关系。设向量x是输入向量,其对应的输出为标量 y, x和y是随机变量。
设向量x和标量y是随机变量,X和Y是测量值,定义f(x ,y)是连续概率密度函数。如果 f(x ,y)已知,容易得到y在x上的回归为:
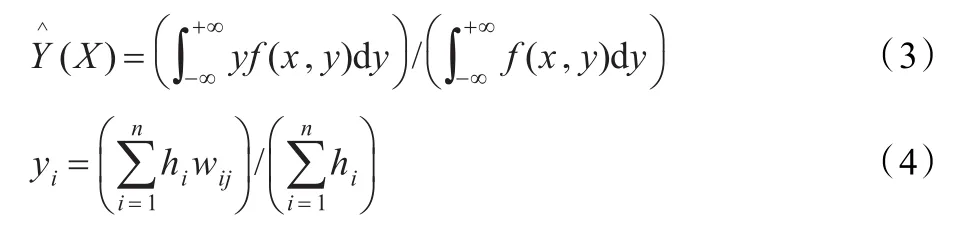
其中,ωij为对应于输入训练矢量 χi和输出 j的目标输出,hi=exp[- D2
i/(2σ2)]为隐层神经元的输出,Di2=(X-Xi)T(X-Xi)
为输入矢量和训练矢量距离的平方,σ称其为光滑因子spread。
GRNN由四层构成,它们分别为输入层(input layer)、模式层(pattern layer)、加和层(summation layer)和输出层(output layer)。输入层的各单元是简单的线性单元,直接将输入变量传递给模式层;模式层又称隐回归层,每个单元对应于一个训练样本,以高斯函数e-d(xo,xi)为活化核函数,xi为各单元核函数的中心矢量,共有n个单元;加和层有两个单元,其一计算模式层各单元输出的加权和,权为各训练样品的 yi值,算得式(4)的分子,称为分子单元,另一单元计算模式层各单元的输出之和,算得式(4)的分母,称为分母单元;输出层单元将加和层分子、分母单元的输出相除,算得y的估算值。
4.3.2 GRNN的输入输出参数
以语句的PAD值、音节的声调信息和位置信息作为GRNN的输入参数,以音节基频包络的五度字调模型参数和音节的时长、停顿时长作为GRNN的输出参数,设计了如图2所示的情感语音韵律预测模型。GRNN的输入参数和输出参数见表3和表4。
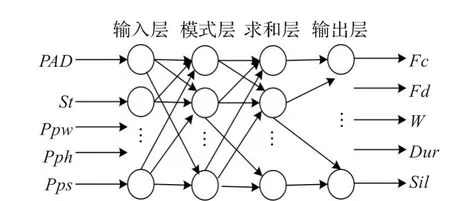
图2 GRNN情感语音韵律预测模型图

表4 GRNN的输出参数
5 实验结果
5.1 五度字调基频模型的性能评测
为了能够更加精确地构建基于GRNN的情感语音韵律转换模型,在训练GRNN模型之前,利用五度字调模型转换了所有情感音节的基频曲线,建立了各个音节的基频模型。图3示例了一句语音的原始基频曲线和五度字调模型生成的基频曲线。图中,虚点曲线代表原始基频曲线,实线曲线代表五度字调模型生成的基频曲线。原始的基频曲线利用STRAIGHT算法计算获得。从图中可以看出,五度字调模型产生的基频曲线能够很好地逼近原始基频曲线,而且比原始基频曲线更为光滑。
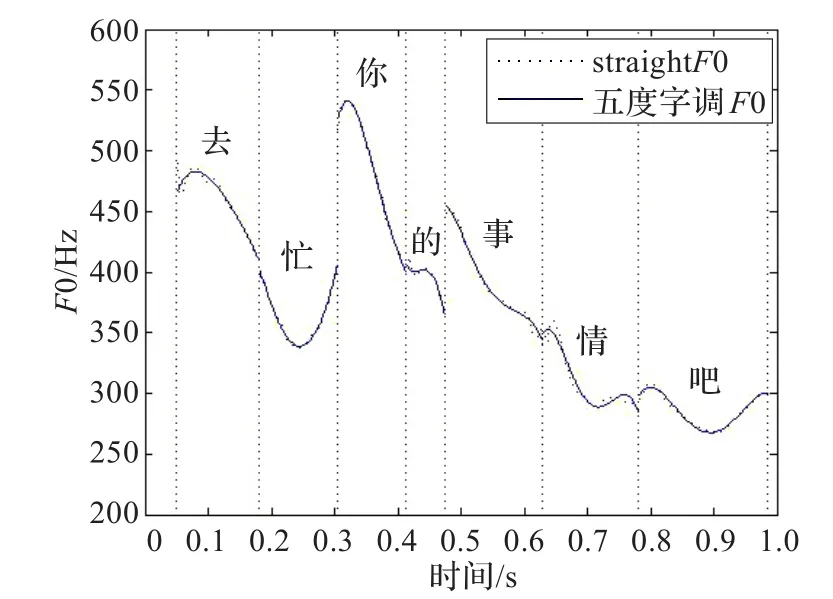
图3 语料10在焦虑情感下两种算法基频曲线对比图

表3 GRNN的输入参数
为了进一步检验五度字调模型对音节基频包络的建模性能,文中计算了五度字调模型产生的基频曲线与原始基频曲线之间的均方根误差(Root-Mean-Square Error,RMSE),如表5所示。RMSE的计算如式(5)所示:

其中,di为测量值与平均值的偏差,其中i=1,2,…,n。
表5列出了五度字调模型对不同情感的音节基频包络建模的RMSE值,从表中可以看出,恐惧情感的误差最大,放松情感的误差最小,但最大误差不超过6.9 Hz。因此,五度字调模型能够满足对基频曲线建模的要求。
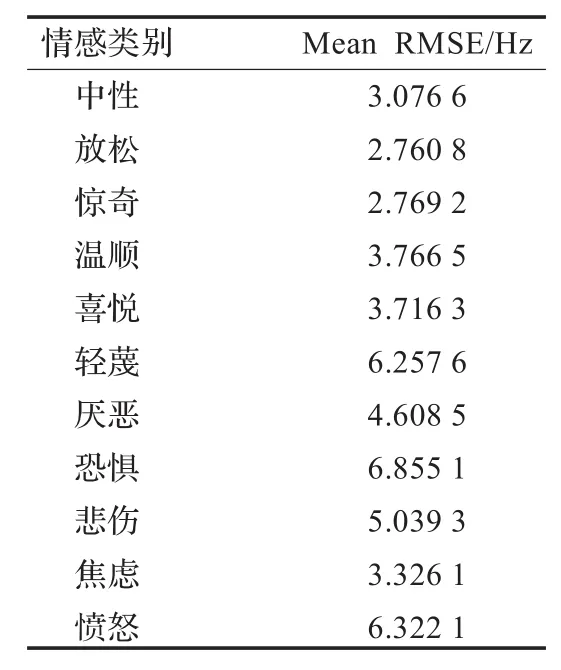
表5 五度字调模型对各类情感的基频包络建模的RMSE
5.2 GRNN预测模型的性能评测
按照本文模型的转换框架,在训练阶段,将实验语料的4/5,用于GRNN模型的训练中。在对该模型进行了多次的训练并利用交叉验证的方法后,寻找得到了在spread值为0.7时,模型达到了最优状态。在此基础上,将剩余的1/5实验语料作为测试数据,应用于训练阶段得到的GRNN模型中,预测得到了相应情感语句的五度字调模型参数、时长和停顿时长,并利用五度字调模型生成了音节的基频包络。图4和图5分别显示了恐惧和焦虑情感下的预测结果,其文本内容为“去忙你的事情吧!”。从图中可以看出,预测得到的基频曲线范围及其走势都比较接近原始的情感语音。
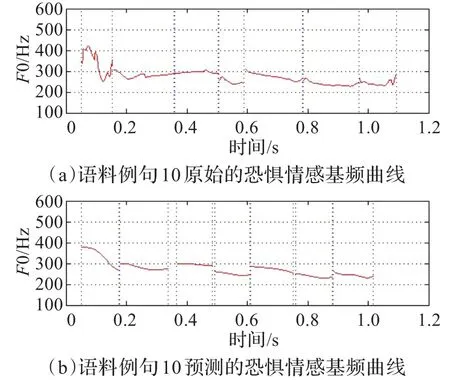
图4 原始恐惧情感曲线与预测恐惧情感曲线对比图
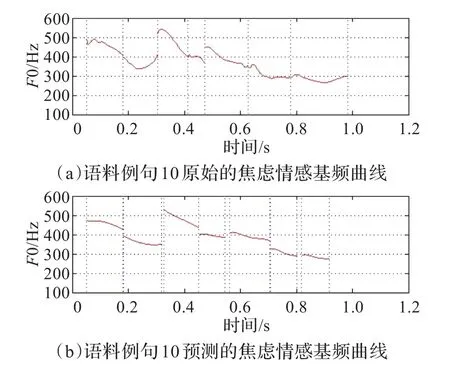
图5 原始焦虑情感曲线与预测焦虑情感曲线对比图
为了进一步观察GRNN模型的性能,利用式(5)计算了预测的基频、时长和停顿时长的RMSE值,如表6所示。
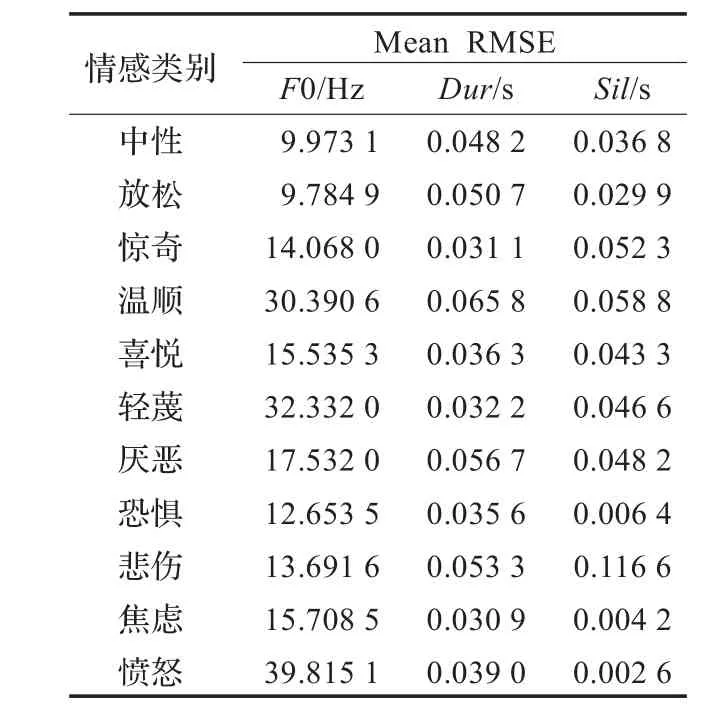
表6 GRNN模型预测的基频、时长和停顿时长的RMSE
同时,为了进一步验证GRNN的性能,对模型预测值和原始值进行了相关分析,如表7所示。
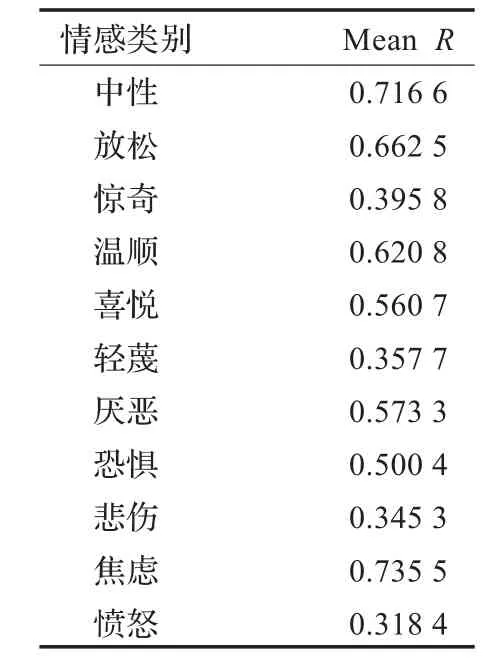
表7 11种情感下所有特征相关系数的平均值
表7中,R为相关系数,当R=1时,为完全相关。从中可以看到中性、放松、温顺、焦虑等情感,在模型中所有预测特征达到了较好的相关。
5.3 转换结果的主观评测
采用情感平均评定得分(Emotion Mean Opinion Score,EMOS),对转换后的情感语音进行主观评测。EMOS评测方法主要侧重于对情感表达程度的评测,它用5级评分标准来评价变换后语音相对于原始语音而言情感表达的相似度。EMOS评测将语音质量分为优、良、中、差和劣5个等级,各等级分别给以5分、4分、3分、2分、1分的权值。在实验中,选择了10名从未接触过EMOS打分的本科生,五男五女。将实验转换得到的440句语句,每人从中随机选取110句进行评测。在评测时,首先播放原始情感语音,作为自然语音的标准,该语音的EMOS得分为5分,然后根据被测试语音的情感相似度进行EMOS打分。最后,将各听音人对所评测语音的打分结果平均后计算出最终的EMOS得分,并且计算了其95%的置信区间,如图6所示。
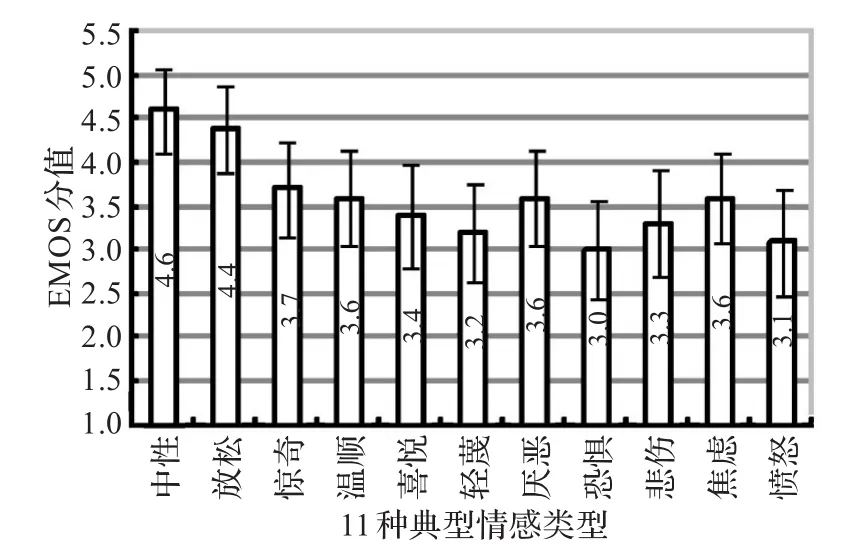
图6 EMOS主观评测结果及95%置信区间
从图6中可以分析发现,类似于轻蔑、恐惧、悲伤和愤怒等一些典型情感的体现,其不仅仅是在其韵律特征上,而是更注重语音、面部表情、心理等多方面综合的反映。如果仅用语音的一些声学韵律特征,还不能够较为充分地体现其相应的情感成分的。所以,才导致了部分典型情感的EMOS得分偏低的结果。
6 结论
通过PAD三维情绪模型以及基于五度字调模型的基频建模,利用GRNN神经网络建立了一个人不同情感语音转换的韵律特征模型,最终得到了其相应的情感语音。实验表明,在语料库数据较少的情况下,从听音测试结果显示了本文所给出的转换方法还是一个比较可行的方法。但是,由于情感语音的变化不仅仅体现在基频的变化上,因此,还需要加入其他一些语音参数进行设置深入分析。进一步的工作包括将PAD三维情绪模型应用于统计参数语音合成,实现基于HMM的情感语音合成。
[1]蔡莲红,贾珈,郑方.言语信息处理的进展[J].中文信息学报,2011,25(6):137-141.
[2]Zen H,Tokuda K,Black A W.Statistical parametric speech synthesis[J].Speech Communication,2009,51(11):1039-1064.
[3]蔡莲红,崔丹丹,蔡锐.汉语普通话语音合成语料库TH-CoSS的建设和分析[J].中文信息学报,2007,21(2):94-99.
[4]YamagishiJ,KobayashiT,NakanoY,etal.Analysisof speaker adaptation algorithms for HMM-based speech synthesis and a constrained SMAPLR adaptation algorithm[J]. IEEE Transactions on Audio,Speech,and Language Processing,2009,17(1):66-83.
[5]Nose T,Tachibana M,Kobayashi T.HMM-based style control for expressive speech synthesis with arbitrary speaker's voice using modeladaptation[J].IEICE Trans on Inf& Syst,2009,E92-D(3):489-497.
[6]徐俊,蔡莲红.面向情感转换的层次化韵律分析与建模[J].清华大学学报:自然科学版,2009,49(S1):1274-1277.
[7]YangHongwu,MengH M,CaiLianhong.Modelingthe acousticcorrelatesof expressiveelementsin text genres for expressive text-to-speech synthesis[C]//Proceedings of International Conference on Spoken Language Processing. Pittsburg,USA:[s.n.],2006:1806-1809.
[8]Wu Zhiyong,Meng H M,Yang Hongwu,et al.Modeling the expressivity of input text semantics for chinese text-to-speech synthesisin a spoken dialog system[J].IEEE Transactions on Audio,Speech,and Language Processing,2009,17(8):1567-1577.
[9]崔丹丹.情感语音分析与变换的研究[D].北京:清华大学,2007.
[10]周慧,杨鸿武,蔡莲红.基于SVR的情感语音变换[J].西北师范大学学报:自然科学版,2009,45(1):62-66.
[11]Guo Weitong,Yang Hongwu,Pei Dong,et al.Prosody conversion of Chinese northwest mandarin dialect based on five degree tone model[J].International Journal of Digital ContentTechnology and its Applications,2012,6(17):323-332.
[12]Kawahara H,Masuda-Katsuse I,de Cheveigne A.Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency-based F0 extraction:possible role of a repetitive structure in sounds[J]. Speech Communication,1999,27(3/4):187-207.
[13]Cowie R,Cornelius R R.Describing the emotional states thatare expressed in speech[J].Speech Communication,2003,40:5-32.
[14]Mehrabian A.Correlations of the PAD emotion scales with self-reported satisfaction in marriage and work[J].Genet Soc Gen Psychol Monogr,1998,124(3).
[15]杨鸿武,王晓丽,陈龙,等.基于语法树高度的汉语韵律短语预测[J].计算机工程与应用,2010,46(36):139-143.
[16]Li Xiaoming,Zhou Haotian.The reliability and validity of the Chinese version of abbreviated PAD emotion scales[J]. Affective Computing and Intelligent Interaction,2005,3784 (1):513-518.
LU Xiaoyong1,YANG Hongwu2,GUO Weitong2,PEI Dong2
1.College of Computer Science and Engineering,Northwest Normal University,Lanzhou 730070,China 2.College of Physics and Electronic Engineering,Northwest Normal University,Lanzhou 730070,China
This paper proposes a framework for prosody conversion of emotional speech based on PAD three dimensional emotion model.It designs an emotional speech corpus including 11 kinds of emotional utterances.Each utterance is labelled the emotional information with PAD value.A five-scale tone model is employed to model the pitch contour of emotional speech at the syllable level.It builds a Generalized Regression Neural Network(GRNN)based prosody conversion model to realize the transformation of pitch contour,duration and pause duration of emotional speech according to the PAD values of emotion and context information of text.Speech is then re-synthesized with the STRAIGHT algorithm by modifying pitch contour,duration and pause duration.Experimental results on Emotional Mean Opining Score(EMOS)demonstrate that the modified speeches achieve 3.6 of average Emotional Mean Opining Score(EMOS).
PAD emotion model;five degree tone model;Generalized Regression Neural Network(GRNN);STRAIGHT algorithm;prosody conversion
提出了一种基于PAD三维情绪模型的情感语音韵律转换方法。选取了11种典型情感,设计了文本语料,录制了语音语料,利用心理学的方法标注了语音语料的PAD值,利用五度字调模型对情感语音音节的基频曲线建模。在此基础上,利用广义回归神经网络(Generalized Regression Neural Network,GRNN)构建了一个情感语音韵律转换模型,根据情感的PAD值和语句的语境参数预测情感语音的韵律特征,并采用STRAIGHT算法实现了情感语音的转换。主观评测结果表明,提出的方法转换得到的11种情感语音,其平均EMOS(Emotional Mean Opinion Score)得分为3.6,能够表现出相应的情感。
PAD情绪模型;五度字调模型;广义回归神经网络(GRNN);STRAIGHT算法;韵律转换
A
TP391
10.3778/j.issn.1002-8331.1211-0193
LU Xiaoyong,YANG Hongwu,GUO Weitong,et al.Prosody conversion of emotional speech based on PAD three dimensional emotion model.Computer Engineering and Applications,2013,49(5):230-235.
国家自然科学基金(No.61263036,No.60875015);甘肃省自然科学基金(No.1107RJZA112,No.1208RJYA078)。
鲁小勇(1982—),男,讲师,主研方向:语音合成;杨鸿武,通讯作者,男,博士,教授;郭威彤,女,助教;裴东,男,副教授。E-mail:yanghw@nwnu.edu.cn
2012-11-19
2013-01-14
1002-8331(2013)05-0230-06
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20 02:51:14
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27 02:08:08
山东交通科技(2020年2期)2020-08-13 09:24:06
中华诗词(2019年1期)2019-08-23 08:24:12
北方文学(2018年32期)2018-11-19 10:12:34
乡村地理(2018年4期)2018-03-23 01:53:58
文艺生活·中旬刊(2017年7期)2017-09-04 09:05:57
电子制作(2017年20期)2017-04-26 06:57:35
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
福利中国(2015年5期)2015-01-03 08:41:48
