
面向环境监测的遥感信息快速时空聚集研究
2013-04-28 06:14李继园孟令奎
武汉理工大学学报(信息与管理工程版) 2013年6期
李继园,孟令奎
(武汉大学遥感信息工程学院,湖北 武汉 430079)
随着高时空谱传感器技术的发展,对地观测平台持续产生了海量遥感数据[1]。数据聚集技术根据研究需要在特定时空尺度内对接收数据集进行相关信息抽取和概化,能有效去除冗余信息,并简化后期数据分析[2-3]。遥感信息聚集主要包括时间维和空间维聚集。其中,时间维聚集综合特定时段内的数据,以清晰反映该时段内信息变化趋势[4]。而空间维聚集通过降低空间分辨率来概化地表传感特征,实现宏观监测。
然而,信息时空聚集过程本身面临海量计算压力,其处理性能对后期处理与分析有很大影响。目前基于高性能服务器的计算方法维护代价高且可扩展性不强。Map-Reduce是近年来快速发展的数据密集型编程模型,可扩展至上千个普通计算节点[5]。笔者以 MODIS(moderate resolution imaging spectroradiometer)[6]旱情监测中的植被指数聚集计算为例,在数据集网格化基础上尝试应用该编程模型实现计算可扩展的遥感信息快速时空聚集过程。
1 遥感信息的时空聚集方法
根据所提取的环境参数与指标要求,遥感信息的聚集方法有多种,如常用的MVC(maximum value composite)法[7],均值法,MRB(majority rulebased)法,以及 RRB(random rule-based)分类法[8]等。笔者以遥感旱情中常用指数和数据源NDVI(normalized difference vegetation index,250 m分辨率)为例阐述笔者的方法。NDVI反映了地表植被的当前长势和营养信息,可由式(1)计算,其中,ρnir和ρred分别为植被在近红外波段和红光波段上的反射率。
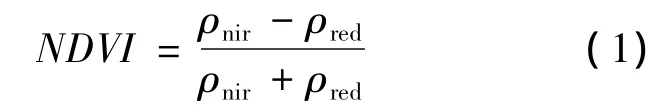
NDVI根据聚集的时间尺度(如日、旬、月等)涉及多种聚集方法,如MVC,CV-MVC(constrained view angle-maximum value composite)和BRDF(bidirectional reflectance distribution function)。
图1给出了一种由原始MODIS数据到旬NDVI产品的聚集过程。其中,原始数据在NDVI日度聚集计算前需经过预处理(包括几何校正,辐射校正及NDVI计算)。日度NDVI产品采用MVC法(选取每个地理位置上最大的NDVI像素值)以聚集该日内的所有NDVI。每旬NDVI聚集在晴空数为2且晴空率为30%时优先采用CVMVC法(即选择传感器视角最小的两景NDVI并取最大值),若只有一天晴空则直接采用该天NDVI值,其次采用MVC法。目前该聚集流程以单机方式运行于某信息中心专属高性能服务器上。该系统日均接收实时MODIS 0级数据15 GB,在无数据接收等待情况下单幅处理时长35min,批处理总时长约6 h且无容错机制。笔者将阐述如何利用Map-Reduce加速该聚集过程,在满足及时性要求的同时达到较好扩展性与容错性。
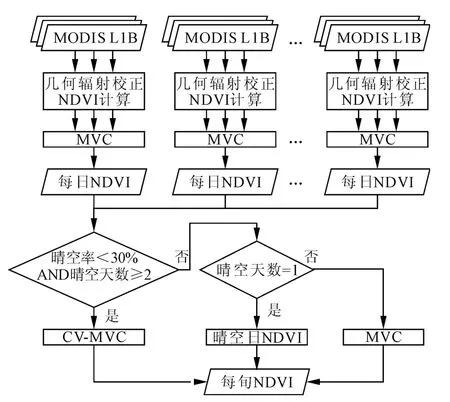
图1 NDVI旬度产品的时空聚集过程
2 NDVI时空聚集的Map-Reduce化
Map-Reduce模型通过操作key-value数据集实现分布式环境下大规模数据处理,一个Map-Reduce任务包括以下处理阶段:①Map阶段执行用户定义函数,将输入key-value转换为中间keyvalue;②Shuffle阶段合并中间结果,分组并发送至Reduce端;③Reduce阶段执行用户函数,处理一组具有相同key的value,并输出最终结果[9]。复杂处理则由多个Map-Reduce任务链完成。在该模型支持下,构建图2所示平台以支撑分布式NDVI聚集过程。
图2 NDVI聚集的Map-Reduce运行平台示意图
该平台包括3层。其中,资源层为由本地网络环境下的多计算节点和控制节点组建的普通机群,通过专线接入MODIS实时接收与传输系统。应用层客户端负责与框架层交互,提交信息聚集流程或控制流程驱动方式,以及获取聚集结果。框架层包括Map-Reduce框架与分布式文件系统HDFS,基于 Hadoop MapReduce(http://hadoop.apache.org/)构建了计算环境。该环境中,计算服务(task tracker)与存储服务(data node)部署于同一节点,控制节点运行管理服务(job tracker),实现计算资源请求与调度。原始数据抵达HDFS后,控制节点将调度该批次数据处理,并行复杂性(容错性、任务分配和工作流控制)可交由Map-Reduce框架自动处理。因此该研究的关键是将应用层NDVI信息聚集过程转化为框架层的Map-Reduce任务链,笔者将详细阐述其实现机制。
2.1 网格化
网格化即基于特定剖分格网将栅格数据划分为多个空间上无缝连接的地理栅格单元。网格化基于数据并行策略将大的栅格任务分解为多个独立并行小任务,并且为时空聚集提供统一的空间尺度与范围。采用全球逻辑瓦片策略(global logical tile scheme)[10],即在 Plate Carree 投影下以 2n+1×2n划分的多级经纬网为基础建立全球范围内的格网划分,如图3所示。在第n级划分时,每个单元经度间隔为xtile=360/n,维度间隔为ytile=360/n。经纬度范围为[xmin,ymin,xmax,ymax]的影像在该层的单元数目numn可由式(2)计算。其中,numx和numy分别为经度和维度方向上的单元行列数。对于MODIS 250 m分辨率数据,限定n=7。
图3 当n=7时的全国网格化NDVI图
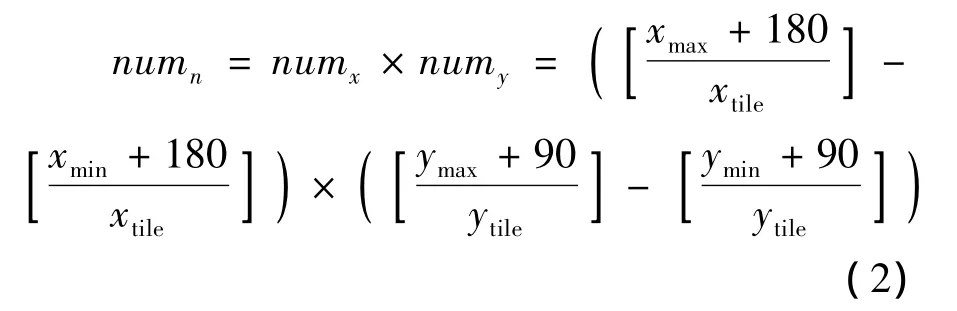
划分后的栅格单元以key-value形式表示,value为栅格值,key为<geo,time>。其中geo为单元编码(采用简单行列编码),time为数据时间属性。如日度NDVI的时间为04/03/2010,网格行列数为32和24,则其 key可表示为 <L7-32-24,2013-03-04>。于是,一景或多景MODIS数据集D可表达为基于单元的key-value数据集:
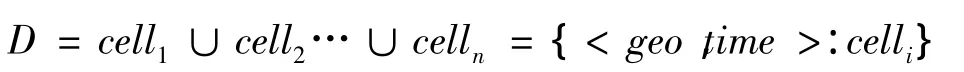
若D上的聚集函数为:F=f(D),且满足式(3),则该聚集可执行数据并行分解。考察图1中的函数,每个地理单元计算都是独立的,因此式(3)成立。
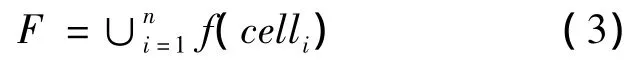
2.2 批处理聚集的实现
基于Map-Reduce原理与上述网格化机制,实现NDVI聚集的Map-Reduce任务 (Job)链的关键是将聚集计算及其他处理函数转化为对keyvalue数据集的分组合并操作。HDFS中的 Sequence File被用作key-value数据集的存储格式。MODIS原始数据到达本地机群后,以key-value形式序列化至Sequence File中(key为接收时间,value为以字节类型存储的栅格数据)。经过网格化后,key-value的数据粒度变为栅格单元,同样采用Sequence File存储各种中间结果和数据集。该任务链由MODIS预处理、NDVI日聚集和旬聚集3个Job串联而成,且每个Job以前一个Job的输出为输入,如图4所示。
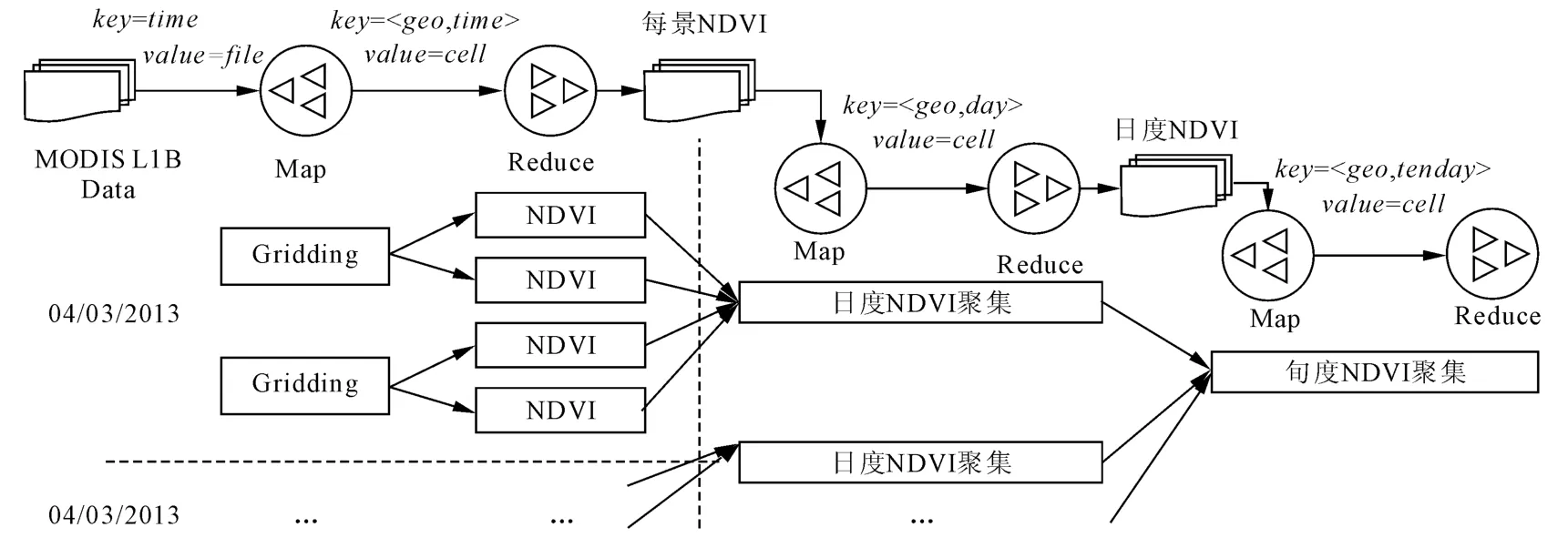
图4 旬度NDVI的聚集流程及其Map-Reduce实现
(1)MODIS预处理。Map阶段,每个Map分配并读取Sequence File中的一条记录,并反序列化为栅格数据,然后执行波段提取(band1、band2和band3)和几何校正,最后执行网格化,并将每个单元传递至相应的 Reduce端,输出 key为<geo,time>。Reduce阶段收集具有相同key值的所有单元,执行辐射校正及NDVI计算,且每个Reduce结果输出至新的 Sequence File中,输出key不变,value为地理单元的栅格字节流。
(2)NDVI日度聚集。该Job输入上阶段产生的Sequence File以执行日度聚集。Map阶段为一个数据读取过程,每个Map读取本地的单元后传递到Reduce端,输出 key为 <geo,day>,其中day为聚集目标日期。Reduce阶段收集同一key值的所有单元执行图1中的日度聚集。由于Map所在节点可能存在对应同一地理范围的栅格单元,Map-Reduce中的Combine策略可预先在本地聚集这些单元,以减少向远程Reduce节点的传输量。同样,Reduce阶段的结果输出至新的 Sequence File中,输出key不变。
(3)NDVI旬度聚集。该Job的Map阶段也为数据读取过程,其传递日度聚集的单元到Reduce端,输出 key为 <geo,tenday>,其中 tenday为聚集目标旬标签。Reduce阶段收集同一key值的所有单元执行图1中的旬度聚集并输出结果。
以上3个Job间以Sequence File文件形式通信,故每个Job可独立运行,也可链接成Map-Reduce任务链。因此在实际运行中,可以基于时间驱动方式在日末执行当日批处理,在每旬末执行当旬批处理,也可在旬末一次性执行整个批处理任务流。该过程中,可通过如下3种优化手段减少数据冗余,加速处理。
(1)中间缓存文件。将中间结果临时写入Sequence File中,在整个Job运行结束后才执行删除命令,因此当Map或Reduce阶段出错时重新执行调度,程序可追溯到离出错点最近的数据输入处执行容错处理,避免了整个计算的重新调度和传输开销。
(2)最小外包矩形。在网格划分时会生成沿地理边界或水陆边界的地理单元,其真实参与计算的区域只占单元的部分面积。因此整个单元参与计算将造成数据和计算冗余。在Map阶段读取每个单元时,采取只保留地物最小外包矩形的方法,即摒弃不参与计算区域,可大幅减少数据处理量和传输量。该数据可通过Geo编码表达其所在单元的地理范围。
(3)Map和 Reduce重叠。Map阶段和 Reduce阶段的重叠策略确保了在Map完成前可开始Reduce计算,从而减少处理延迟。在Hadoop MapReduce中,Map和 Reduce默认重叠率为20%。该参数通过实验优化可进一步提高整体聚集过程的加速性能和资源利用率。
2.3 增量聚集的实现
上述聚集过程需要在所有数据完备情况下方可执行。在数据持续接收情况下,若要及时获取当天NDVI实时聚集值,则可在约束条件(如固定时间窗口内和达到一定数据量)的驱动下执行该批次处理,以及时更新NDVI聚集值,最终以多次小批处理完成当日所有聚集任务,该过程称为增量式聚集。图5给出了日度NDVI的增量式聚集示意图及其Map-Reduce实现。每次更新值作为临时文件存储于Sequence File中。Map-Reduce任务由两个Map和一个Reduce组成。一个Map负责当前批次数据预处理,输出key为<geo,day>。另一个Map从Sequence File中读取最近聚集值,输出key为<geo,day>。Reduce阶段收集同一key两种栅格单元,执行MVC聚集并完成一次Sequence File的更新。
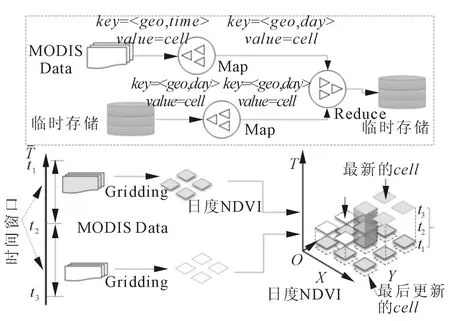
图5 日度NDVI增量式聚集及其Map-Reduce实现
3 实验分析
基于Hadoop 0.20.2搭建计算环境,并利用Java和 GDAL(www.gdal.org)实现了上述聚集流程。硬件环境为具有1 GB/s理论网速的普通PC集群(10个计算节点,1个控制节点,各节点配置一个4核2.8 GHz CPU和4 GB RAM)。Hadoop中每个Map Slot分配1个CPU和1 GB内存,每个Reduce Slot分配1个CPU和2 GB内存,其他配置默认。为考察所提出方法的整体加速性能与可扩展性,实验1在增加计算节点数情况下,采用批处理模式执行一旬MODIS数据(2010年4月份上旬,数据量为139.8 GB)的NDVI聚集流程,并统计每个Job的执行时间。作为对比,同时记录原有系统在单节点上相应阶段的执行时间,结果如图6所示。
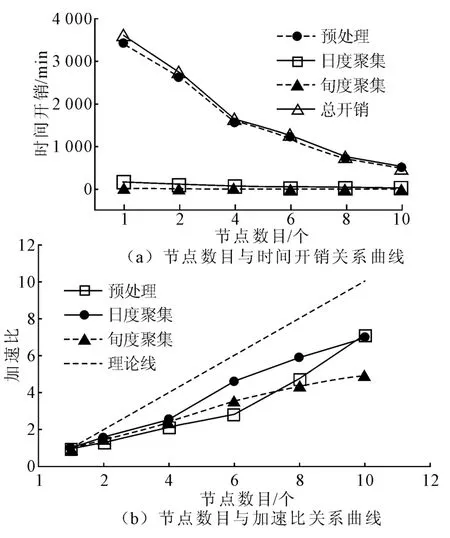
图6 随节点增长的NDVI聚集任务的性能对比
数据聚集是一个信息量逐渐精简的过程。据统计,日度聚集量减少为72.5 GB,旬度聚集量为8.4 GB。图6(a)显示单机预处理时长为3 432.6 min,远高于NDVI聚集时间,因而其对分布式计算资源的效率利用较为充分,在10个节点时已达到7倍多的加速性能。总体时间开销也与预处理时间基本保持一致。图6(b)显示上述处理随节点增大的加速比变化情况。其中预处理在节点增长前期加速不明显,后期增速较快。这是由于相比于单机计算,Map-Reduce预处理阶段包含数据网格化,该部分开销减弱了任务并行带来的加速性能。节点增大后,其并行加速性能得到迅速提升,大大抵消了网格化影响。相反,日度聚集的加速比在前期增长较快,但由于处理数据量相对较小,节点计算性能没得到充分利用,因此后期因节点增长而带来的加速效果逐渐减缓。旬度聚集处理数据量最小,只有一次聚集批处理任务,但在满节点时也达到5倍加速性能。
为考察聚集过程随数据量增长的可扩展性,实验2在1天内数据处理景数不断增加的情况下执行MODIS预处理过程(满节点负载),记录其执行时间如图7所示。结果显示单机处理随数据量增长呈线性提高趋势,但Map-Reduce的处理时长却变化较小,在单节点和满节点时的加速比分别为1.2和7.1。该实验显示基于 Map-Reduce方法具有较好的数据可扩展性,即加速性能不会随数据量的增加而降低。
实验3以日度NDVI聚集计算为例,测试在不同Map完成时间点开始Reduce阶段任务的Job加速比。图8显示当Map完成率为80%,加速比达到最大值。若在Map结束时开始Reduce任务,将造成数据在同一时间内的传输竞争。而在60%时开始的Reduce同样会竞争Map计算资源,造成延迟。
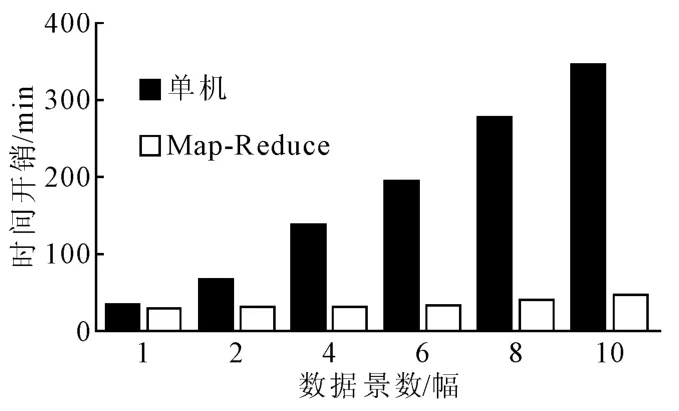
图7 随数据量增长的NDVI聚集时间开销
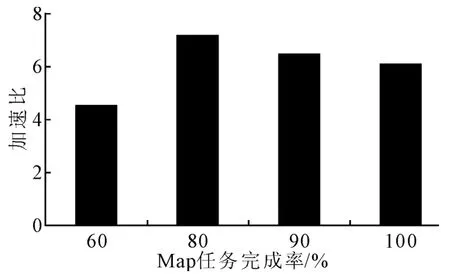
图8 随Reduce起始点变化的加速比
4 结论
针对当前遥感信息时空聚集面临的海量数据计算压力,详细阐述了利用Map-Reduce编程模型聚集计算资源,通过分布式数据并行方法使该问题得到有效解决。实验证明该方法具有较好的节点扩展性和数据可扩展性,能大幅提高遥感信息聚集的吞吐能力。下一步研究将通过Map-Reduce的各种参数优化进一步提升信息聚集的效率和资源利用率。
[1] GASSTER S D,PLAZA A,CHEIN I C,et al.Recent developments in high performance computing for remote sensing a review [J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2011,4(3):508 -527.
[2] JIE Z.Spatio-temporal aggregates over streaming geospatial image data[C]∥International Conference on Extending Database Technology 2006 Workshops.[S.l.]:[s.n.],2006:32 -43.
[3] 牛宝茹,刘俊蓉,王政伟.干旱半干旱地区植被覆盖度遥感信息提取研究[J].武汉大学学报:信息科学版,2005,30(1):27-30.
[4] 蒋耿明,牛铮,阮伟利,等.MODIS影像合成算法研究和实现[J].国土资源遥感,2004(2):11-15.
[5] JEFFREY D,SANJAY G.Map reduce:simplified data processing on large clusters[C]∥Symposium on Operating Systems Design and Implementation.San Francisco:USENIX,2004:137-150.
[6] USGS.MODIS[EB/OL].[2013-05-03].https://lpdaac.usgs.gov/products/modis_overview.
[7] RAMON S,KAMEL D,ANDREE J,et al.MODIS VI user guide[EB/OL].[2013-05-03].http://vip.arizona.edu/documents/MODIS/MODIS_VI_UsersGuide_0 -1_2012.pdf.
[8] RAHUL R,NICHOLAS A S,HAMM A,et al.Analysing the effect of different aggregation approaches on remotely sensed data[J].International Journal of Remote Sensing,2013,34(14):4900 -4916.
[9] TOM W.Hadoop:the definitive guide[M].[S.l.]:O'Reilly Media,2009:23-26.
[10] JOHN T.Sample,elias loup:tile- based geospatial information systems[M].New York:Principles and Practices,2010:7 -9.
猜你喜欢
科技创新与应用(2021年31期)2021-11-09
北京大学学报(自然科学版)(2021年3期)2021-07-16
科学导报·学术(2020年84期)2020-11-08
电脑爱好者(2020年19期)2020-10-20
中北大学学报(自然科学版)(2020年4期)2020-07-13
电子制作(2019年13期)2020-01-14
网络安全和信息化(2017年12期)2017-11-08
电脑爱好者(2017年18期)2017-11-03
弹箭与制导学报(2015年1期)2015-03-11
雷达学报(2014年4期)2014-04-23
