
基于依存特征的汉语框架语义角色自动标注
2013-04-14 07:49王智强阴志洲刘海静李双红
中文信息学报 2013年2期
王智强,李 茹,2,阴志洲,刘海静,李双红
(1.山西大学计算机与信息技术学院,山西太原030006;2.计算智能与中文信息处理教育部重点实验室,山西太原030006;3.School of Information Technologies,University of Sydney)
1 引言
语义角色标注是对一个句子中谓词所支配的论元进行识别、分类,其实质是在句子级进行浅层语义分析。该标注任务是自然语言处理中的一项重要任务,由于语义角色标注可以直接获得句子层面“谓词—论元”形式的语义结构信息,因此它能够有效应用于自然语言处理的许多领域,如问答系统、信息抽取、机器翻译、文本摘要等。
语义角色标注按语料库资源划分,主要有基于英文的PropBank[1]、NomBank[2]、FrameNet[3]以及汉语的PropBank、FrameNet。英文方面,最早是Dan Gildea与Dan Jurafsky[4]在FrameNet上的工作,在完全句法分析基础上,选取短语类型、句法功能、位置、语态、中心词、路径等大量特征,使用条件概率估计方法,最终取得了65%的准确率(precision)和61%的召回率(recall)。随着宾夕法尼亚大学的英文PropBank的建立,语义角色标注任务越来越受到国际自然语言处理领域的关注。许多统计学习的方法被应用于语义角色标注任务中,其中包括J Chen[5]、Prandhan[6]、Cohn[7]、Surdeanu[8]、刘挺[9]等的工作。刘挺[9]等基于PropBank,以句法成分为基本标注单元,使用最大熵分类模型在开发集和测试集上分别获得了75.49%和75.60%的F值。国际上也先后举行了多次语义角色标注任务的评测,其中在基于FrameNet的语义角色标注评测任务(SemEval 2007)[10]中,达到了86.9%的准确率与75.2%的召回率。
汉语方面,有Xue等[11]基于Chinese PropBank的研究,通过使用人工标记的句法树,获得了94.1%的F值,但如果采用自动句法分析,只能达到71.9%的F值。这说明句法分析性能很大程度上制约了语义角色标注。为了克服这种制约,丁伟伟等[12]基于语义组块进行汉语语义角色标注,将传统的“句法分析—语义角色识别—语义角色分类”简化为“语义组块识别—语义组块分类”,突破了汉语句法分析器的时间和性能限制,取得了一定的结果。王鑫等[13]将中文语义角色标注建立在浅层句法分析基础上,利用构词法获得目标动词的语素特征,在细粒度上描述了动词本身的结构,为角色标注提供了更多的信息,相比前人工作有显著的提升。王步康等[14]实现了一个基于依存句法的汉语语义角色标注系统,该系统通过抽取依存句法树上的特征进行角色标注。针对汉语FrameNet的框架语义角色标注,有刘开瑛等[15]基于层叠条件随机场对句子进行的框架元素、短语类型、句法功能的三层标注。李济洪等[16]采用条件随机场模型,以词为基本标注单元,在25个框架的6 692个例句中获得了61.62%的F值。由于框架语义角色种类众多,类型丰富,加之汉语自身比较灵活,导致汉语框架语义角色标注性能偏低。
本文在词、词性层面特征的基础上,利用树条件随机场模型,通过加入依存句法层面的特征进行汉语框架语义角色自动标注。第2节为框架语义角色标注的相关概念及任务描述;第3节为介绍树条件随机场及特征选择;第4节为实验设置与结果分析;最后为总结与展望。
2 框架语义角色标注相关概念及任务描述
2.1 框架语义角色标注相关概念
汉语框架网[17]
汉语框架网(Chinese FrameNet,CFN)是以C J Fillmore的框架语义学为理论基础、以加州大学伯克利分校的FrameNet为参照、以语料库为事实依据的计算词典编纂工程。框架语义学认为,“框架”是一个与激活性语境相一致的结构化范畴系统,是存储在人类认知经验中的图示化情境。
为了便于理解框架语义角色标注任务,以下主要介绍框架语义角色标注中目标词与框架元素的概念。
框架元素[17]
框架中涉及的各种参与者、外部条件和其他概念角色,称为框架元素(Frame Elements)。框架元素分为核心框架元素、非核心框架元素和通用的非核心框架元素。核心框架元素是一个框架在概念理解上的必有成分,它们在不同框架中的类型和数量不同,显示出框架的个性。非核心框架元素并不显示框架的个性,仅表达时间、空间、环境条件、原因、目的等外围语义成分。
与传统的语义角色或者格角色相比而言,语义角色或者格角色是相对词汇而言的,而框架元素仅适用于具有相同框架背景的一组词语,它摆脱了格角色个数无法确定的问题,因此用其来描述自然语言的语义更为合适,但也增加了标注的难度。
目标词[17]
框架承担词,它包括动词、形容词和名词,它们是标注工作的着眼点,与通常所说的谓词相当。
例如:
<前几年time>,<一名大学生cog><tgt=“发明”发明>了<一种电脑病毒inv>。
其中,词语“发明”属于“发明”框架的词元集合,是句子的目标词(tgt)。<一名大学生cog>则表示“一名大学生”是句子中“发明”框架的核心框架元素“认知者[cog]”。核心元素和非核心元素都是与所给定的框架密切相关的,框架不相同时,对应的核心元素和非核心元素也不相同。
2.2 框架语义角色标注任务描述
CFN中的一个框架下通常包含多个目标词,即一个框架可以被多个目标词激起。对于一个目标词来说,当它存在多个义项时,它又可以激起多个框架。一般地,把确定句子中目标词所属框架的任务称之为框架识别任务,框架语义角色标注任务有时将框架识别任务合在一起,例如SemEval 2007 Task-19;也有在直接给定目标词及所属框架的基础上进行语义角色标注。本文的框架语义角色标注任务为后者,且将框架语义角色的边界识别与分类合为一步,具体如下:
例句:前几年,一名大学生发明了一种电脑病毒。
给定目标词“发明”及其所述框架“发明”,在此框架下所包含的框架语义角色类型有:
核心框架元素:
Cog:认知者Inv:发明
非核心框架元素:
Degr:程度Depic:形容Loc_apr:出现地点Manr:修饰Mat:材料Mns:方法Place:空间Purp:目的Result:结果Time:时间
框架语义角色标注的目的是:在给定目标词及其所属框架下识别并赋予目标词所支配的角色与角色类型。
此例的标注结果为:
<前几年time>,<一名大学生cog><tgt=发明>了<一种电脑病毒inv>。
一般地,框架语义角色与通常所讲的“语义角色”“格角色”在标注工作中等同对待,不同之处在于框架语义角色(框架元素)是建立在框架概念之上。
3 基于T-CRF的框架语义角色自动标注
3.1 T-CRF模型
近年来,条件随机场模型被广泛地应用于自然语言处理序列标注的问题中。条件随机场模型Conditional Random Fields(CRF)由Lafferty和McCallum等[18]于2001年提出。它将无向图中的团函数和最大熵有机地融合到一起,得到一个用来解决序列标注和分割的概率模型。条件随机场模型不存在隐马尔科夫模型[19]的强独立性假设,也不具有最大熵马尔科夫模型[20]的标注偏执问题。继CRF模型之后,Tree Structured Conditional Random Fields(TCRF)[21-23]越来越多地被应用于语义角色标注任务中,它主要借助层次依赖特征来提高标注的准确性,适用于本文基于依存特征的框架语义角色标注。具体地,我们抽取依存句法树中的依存特征,对于特征向量:
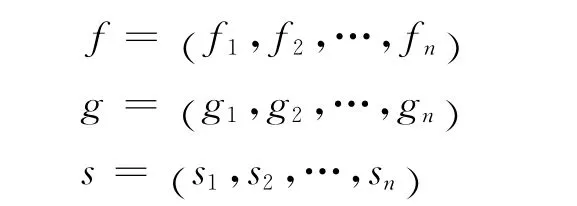
其中,fj、gk、sl分别表示当前节点、当前节点的父节点、当前节点的子节点的特征函数,分别乘以其相应的特征权重向量λ= (λ1,λ2,…,λn)T,η=(η1,η2,…,ηn)T,σ= (σ1,σ2,…,σn)T可得式(1)、式(2)和式(3)。
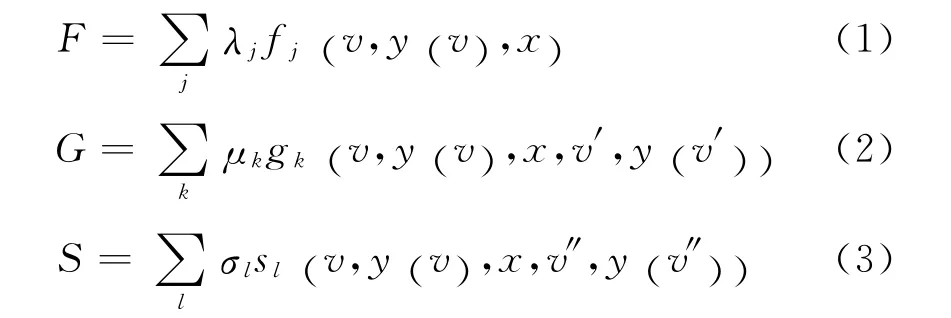
v表示句中词语对应在树中的节点,v′表示v的父节点,v″表示v的子节点。则对于观察值x,最终输出y的概率为式(4)。
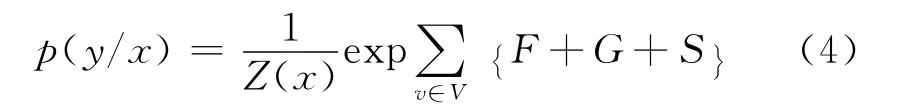
在框架语义角色标注的任务中,观察值x代表句子中的当前词,y则代表当前词x所承担的框架语义角色。
3.2 特征选取及特征模板设置
基于统计机器学习的语义角色标注中,特征选择是关键。条件随机场模型中的特征选择可以通过定义特征的窗口,来描述标注单元与其上下文的某种依赖关系。通过各种特征窗口大小的组合来构成相应的特征模板,因此特征选择实际上是特征模板的设置。本文主要关注不同依存特征对框架语义角色标注的影响,首先选择基本特征来设置基线模板,在此基础上加入依存特征,针对加入的不同依存特征设置相应的扩展特征模板,这样能够通过比较不同模板下的标注结果来分析不同依存特征对标注结果的影响。
文献[16]以词为基本标注单元,通过选取基于词、词性层面的特征研究了汉语框架语义角色标注,验证了词、词性层面特征对于汉语框架语义角色标注的有效性。因此本文借鉴了其中词、词性层面的特征来构建基线特征模板。本文选取的依存特征包括依存节点、依存关系及其组合特征,并设置了相应的特征模板。
表1为基线模板与扩展模板的特征选取与模板设置情况。
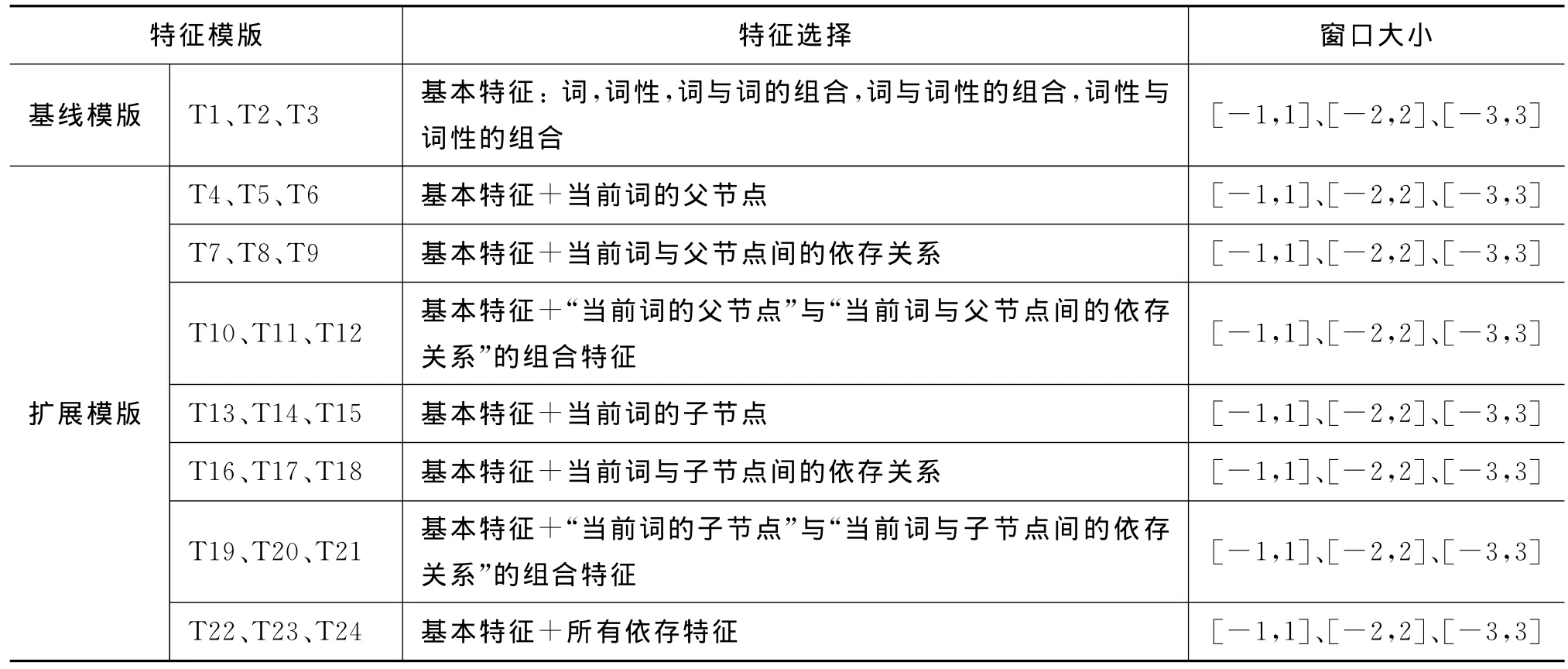
表1 特征选取及模板设置情况
表1共列出了8类特征,每一行表示一类特征。每类特征按窗口大小不同([-1,1]、[-2,2]、[-3,3]),又包含3个特征模板,共计24个特征模板。其中第1类T1、T2、T3为基线模版,其余属于扩展模版。基线模版中包含词、词性及其组合特征,扩展模版则是在基线特征的基础上加入依存层面特征,所加入的依存特征依次为:当前词的父节点、当前词与父节点间的依存关系、“当前词的父节点”与“当前词与父节点间的关系”组合特征、当前节点的子节点、当前节点与子节点间的依存关系、“当前词的子节点”与“当前词与子节点间的关系”组合特征,最后一类模板T22、T23、T24包含以上所有依存特征。
4 实验设置及结果分析
4.1 实验语料及预处理
实验所用测试与训练语料均来自山西大学构建的CFN语料库及扩充语料。由于目前CFN的语料规模有限,实验前期将现有CFN句子库中“发明”、“查看”、“拥有”框架下的句子进行扩充,针对每个词元扩充20条句子,从原有的688条扩充至1 188条。表2为扩充后3个框架下语料规模及分配情况。
实验采用哈尔滨工业大学LTP平台[24]来对语料进行依存句法分析,并对其中明显的句法错误进行人工校正。语料在分词、词性标注、句法分析的基础上,使用O-S-B-I-E策略对框架语义角色进行标注,记标注集合为{S-X,B-X,I-X,E-X,O},示例如下:
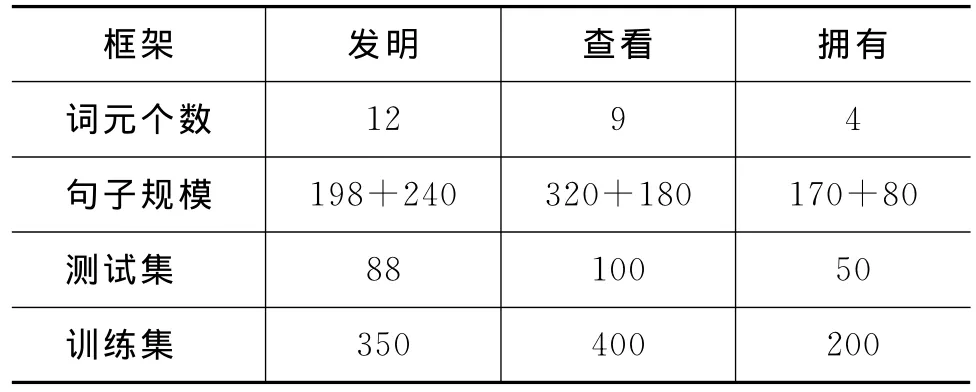
表2 语料规模及分配情况
我们S-cog设计tgt了O社会B-inv贡献率I-inv和I-inv社会I-inv积累率I-inv两个I-inv指标E-inv。O
其中S-cog表示当前词单独承担一个框架语义角色“cog”,B-inv表示当前词是框架语义角色“inv”的开始,I-inv表示当前词是框架语义角色“inv”的延续,E则代表当前词是框架语义角色“inv”的终止,O则表示当前词不承担框架语义角色。
4.2 实验结果及分析
实验中将所选语料例句拆分为5份,为了避免由词元分配不均所带来的数据稀疏影响,我们将每个框架下不同词元的例句进行平均分配。实验采用5-fold交叉验证,具体做法为:任取语料的4份作为训练集,其他1份作为测试集,最终的评价指标以交叉验证实验结果的平均值(mP、mR、mF)来评价标注模型的性能。其中mP、mR与mF分别表示为平均准确率、平均召回率及平均F值。实验主要从以下两个角度对结果进行比较分析:
(1)不同依存特征对最终标注结果的影响;
(2)不同特征对与不同长度的框架语义角色标注影响。
为了比较标注结果间是否存在显著性差异时,对模型间的F值进行了差异的显著性检验。具体做法为:假设模型A,B在交叉验证下的平均F值为mFA,mFB,当两个模型mFA,mFB的1-α的置信区间没有交叉、重叠时,则认为两模型在置信水平α下有显著差异,本文取α=0.05。
4.2.1 不同依存特征下的框架语义角色标注情况
实验对24个特征模板进行逐一测试,在8类不同的特征组合中分别选出标注结果最好的特征模板为:T3、T4、T7、T10、T13、T16、T19、T22。实验结果如表3,其中带星号的数字表示该值相对于基线最优模版T3的提升具有统计显著性。
从表中可以看出,扩展模版中的多数标注结果比基线模板有所提升。尤其是“发明”与“查看”框架在T16模版(基线特征中加入当前词与子节点间的依存关系特征)上的测试结果比基线模板T3(仅包含词、词性层面的特征,未加入依存特征)有近3%的显著提高。可见依存句法层面特征的加入能够一定程度上改善基于词层面特征的框架语义角色标注。还可以看到,三个框架在T7模版(基线特征中加入当前节点与父节点间的依存关系特征)上的测试结果都优于T4模版(基线特征中加入当前节点的父节点特征);在T16模版(基线特征加入当前节点与子节点间的依存关系特征)上的测试结果都优于T13模版(基线特征中加入当前节点的子节点特征),这说明依存节点间的关系特征相比依存节点的特征更有效。另外,三个框架在T4模版(基线特征中加入当前节点的父节点特征)上的测试结果都优于T13模板(基线特征加入当前节点的子节点特征);在T16模版(基线特征中加入当前节点与子节点间的依存关系特征)上的测试结果都优于T7模板(基线特征中加入当前节点与父节点间的依存关系)。说明依存特征中子节点层面特征比父节点层面特征更有效。
4.2.2 依存特征对不同长度框架语义角色的标注影响
追踪错误的标注结果发现,较长的框架语义角色在边界识别时错误较多。统计了语料中不同长度的框架语义角色在不同特征模板下的标注情况,如图1所示。
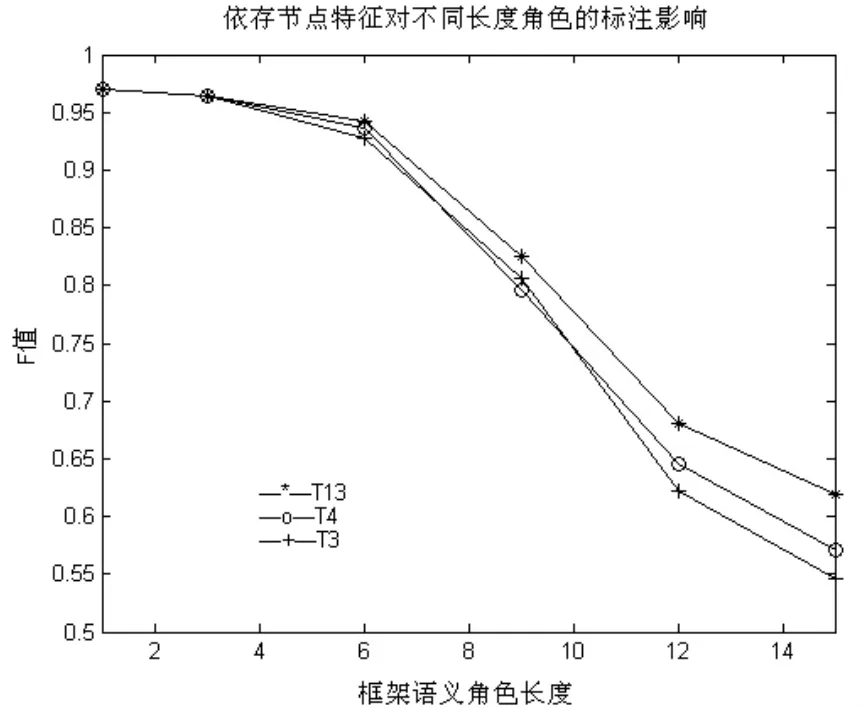
图1 不同长度的框架语义角色标注情况(模板T3、T4、T13中的测试结果)
图1为模板T3(仅包含词、词性层面特征未加入依存特征)、T4模版(基线特征中加入当前节点的父节点特征)、T13模版(基线特征中加入当前节点的子节点特征)下的结果。可以看到,随着依存节点特征的加入,较长框架语义角色的标注情况有所改善,特别是加入子节点特征之后的改善效果更好。
图2为模板T3(仅包含词、词性层面特征未加入依存特征)、T7模版(基线特征中加入当前节点与父节点间的依存关系)、T16模版(基线特征中加入当前节点与子节点间的依存关系)的测试结果。可以看出,父节点关系与子节点关系特征的加入,对较长框架语义角色的标注结果都有一定的改善,其中加入子节点关系特征的改善最为明显。
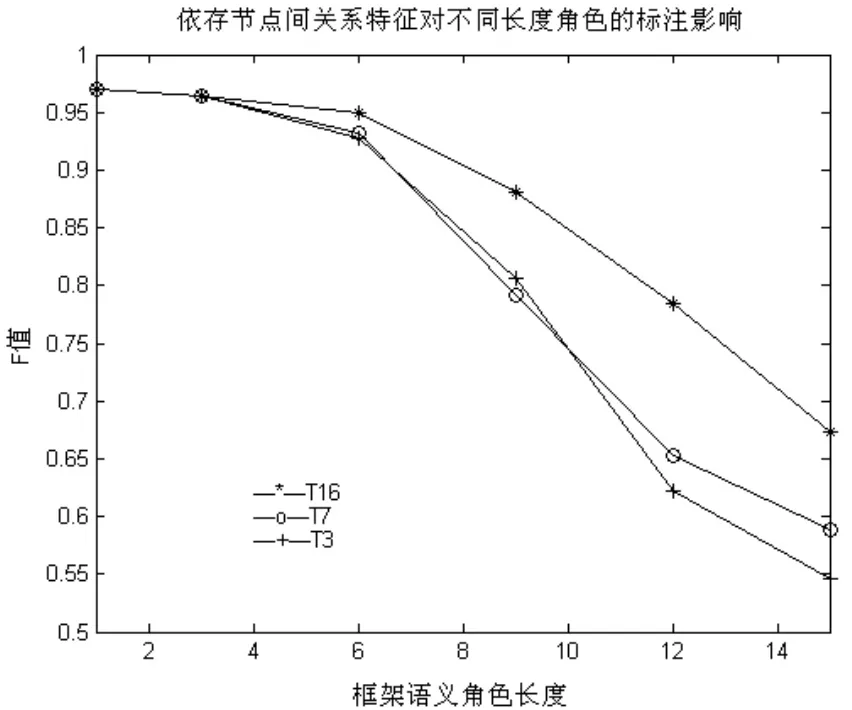
图2 不同长度的框架语义角色标注情况(模板T3、T7、T16中的测试结果)
5 结论与展望
本文提出了一种基于依存特征的框架语义角色标注方法,该方法在词、词性及其组合特征的基础上融入依存句法层面的特征,相比仅依赖词、词性层面特征的框架语义角色标注,标注结果有一定提升。进一步比较了依存特征对不同长度框架语义角色的标注影响,发现依存特征对较长框架语义角色标注结果有一定改善,这其中子节点比父节点特征更为重要,依存关系比依存节点更为重要。这些结论都将为进一步深入的语义角色标注研究提供重要的特征选择依据。
模型与特征的选择只能解决语义角色标注中的部分问题,数据稀疏同样是影响标注结果的一个重要因素。目前汉语框架语义角色标注性能整体偏低,很大程度是受数据稀疏的影响。针对这些问题,今后将进一步扩充标注语料,并尝试用半监督学习方法来提高框架语义角色标注的结果。
[1] Palmer M,Gildea D,Kingbury P.The Proposition Bank:An Annotated Corpus of Semantic Roles[J].Computational Linguistics,2005,31(1):71-106.
[2] Meyers A,Reeves R,Macleod C.The NomBank Project:An Interim Report[C]//HLT-NAACL Workshop:Frontiers in Corpus Annotation,2004:24-31.
[3] Baker C F,Fillmore C J,Lowe J B.The Berkeley FrameNet Project[C]//Proceedings of the ACL,1998:86-90.
[4] Gildea D,Jurafsky D.Automatic Labeling of Semantic Roles[J].Computational Linguistics,2002,28(3):245-288.
[5] Chen J,Rambow O.Use of Deep Linguistic Features for the Recognition and Labeling of Semantic Arguments[C]//Proceedings of EMNLP,2003.
[6] Pradhan S,Hacioglu K,Krugler V,et al.Support vector learning for semantic argument classification[J].Machine Learning,2005,60(1):11-39.
[7] Cohn T,Blunsom P.Semantic role labelling with tree conditional random fields[C]//Proceedings of CoNLL-2005,2005.
[8] Surdeanu M,Màrquez L,Carreras X,et al.Combination Strategies for Semantic Role Labeling[J].Journal of Artificial Intelligence Research,2007,29:105-151.
[9] 刘挺,车万翔,李生.基于最大熵分类器的语义角色标注[J].软件学报,2007,18(3):565-573.
[10] Baker CF,Ellsworth M,Erk K.SemEval 2007Task 19:Frame Semantic Structure Extraction[C]//Proceedings of the 4th International Workshop on Semantic Evaluations,2007:99-104.
[11] Xue N W,Palmer M.Automatic semantic role labeling for Chinese verbs[C]//Proceedings of the 19th International Joint Conference on Artificial Intelligence,2005.
[12] 丁伟伟,常宝宝.基于最大熵原则的汉语语义角色分类[J].中文信息学报,2009,23(5):53-61.
[13] 王鑫,孙薇薇,穗志方.基于浅层句法分析的中文语义角色标注研究[J].中文信息学报,2011,25(1):116-121.
[14] 王步康,王红玲,袁晓虹,等.基于依存句法分析的中文语义角色标注[J].中文信息学报,2010,24(1):25-29.
[15] 刘开瑛,陈雪艳,李济洪.汉语框架元素自动标注实验报告[C]//第四届全国信息检索与内容安全学术会议,2008,1:48-55.
[16] 李济洪,王瑞波,王蔚林,等.汉语框架语义角色自动标注[J].软件学报,2010,21(4):597-611.
[17] 郝晓燕,李茹,刘开瑛.汉语框架语义知识库及软件描述体系[J].中文信息学报,2007,21(5):96-100,138.
[18] Lafferty J,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18th International Conference on Machine Learning,2001:282-289.
[19] Rabiner L R.A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition[C]//Proceedings of the IEEE,1989,77(2):257-286.
[20] Mccallum A,Freitag D,Pereira F.Maximum Entropy Markov Models for Information Extraction and Segmentation[C]//Proceedings of ICML,2000:591-598.
[21] Jie Tang,Mingcai Hong,Juanzi Li,et al.Treestructured Conditional Random Fields for Semantic Annotation[C]//Proceedings of 5th International Conference of Semantic Web,2006.
[22] Awasthi,P,Gagrani A,Ravindran B.Image modeling using tree structured conditional random fields[C]//Proceedings of the 20th International Joint Conference on Artificial Intelligence.2007:2060-2065.
[23] Trevor Cohn,Philip Blunsom.Semantic role labeling with tree conditional random fields[C]//Proceedings of CoNLL2005.
[24] http://ir.hit.edu.cn/demo/ltp/[EB/OL]
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
通信技术(2021年12期)2022-01-25
科学(2020年5期)2020-11-26
开放教育研究(2020年2期)2020-03-31
中国惯性技术学报(2019年3期)2019-10-15
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
中国修辞(2017年0期)2017-01-31
舰船电子对抗(2016年5期)2016-12-13
长江学术(2016年4期)2016-03-11
外语教学理论与实践(2014年2期)2014-06-21
