
基于稀疏表示的安防系统的研究与设计
2013-02-13 09:58林之喆
电视技术 2013年1期
周 腾,林之喆
(1.华南理工大学,广东 广州510006;2.广州医学院,广东 广州510182)
随着生活水平的提高,人们对家居安防的要求日益提高。目前,市面的安防监控系统主要有视频监控、门磁、窗磁和红外越界报警等[1]。这些系统都是通过“机械式”捕获某一个信号,并进行告警。这里所指的“机械式”是指这些系统并不能判定该信号是受到入侵还是一些环境的干扰。例如,门磁系统可以使用机械式的磁石开关的开闭状态来判定窗户是否被打开,但是这种系统无法判定窗户是被风吹开或是遭到入侵。典型的智能视频监控系统可以计算画面的一些变化来判定是否受到入侵,但是其无法从语义上判定入侵物。
另外,目前市售的安防系统,如视频监控、窗磁、门磁或红外越界报警系统都需要对建筑进行改造和安装调试。红外越界报警系统必须对原有的门窗进行钻孔,安装发射装置和接收装置。安装完成后还需要专业的技术人员进行调试方可使用,安装使用成本较高。
当前市售的安防系统多数隐蔽性较差。例如视频监控系统,由光直线传播的原理,该系统的探头必须安装在监控区域上方无遮挡的地方,极易被专业盗匪所破坏。
针对当前市售安防系统的弱点,提出基于稀疏表示、使用音频特征进行安防监控的模型。本文的贡献有:1)提出基于稀疏表示,使用音频特征进行安防监控的模型;2)提出一种使用最大似然估计求解稀疏向量和训练矩阵的算法;3)设计了一个基于上述模型的安防系统,详细阐述了系统的关键技术实现。
1 系统原理
本文讨论的安防监控模型通过机器学习,使用稀疏表示[2]对模型进行训练,到达准确的入侵检测的目的。本文提出基于声音采集的安防模型。因为声音的波长远远大于可见光的波长,所以声音可以绕过障碍物到达声音采集器。
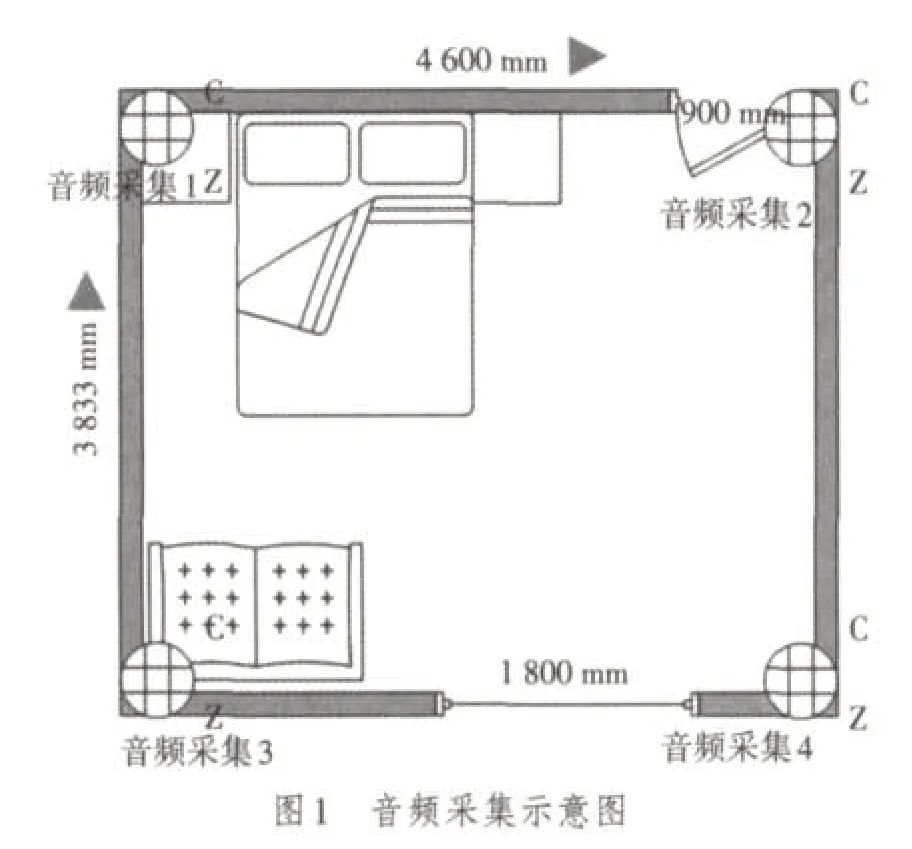
本模型首先必须在家庭中设置一个或多个音频采集的装置,这些装置可以隐藏在任意非可见的位置。如图1所示,房间中共设置了4个音频采集装置。根据实验结果,将音频采集装置设置于房间的每个角落效果较佳。
通过设置音频采集装置,将音频数据传送至家庭安防服务器。使用家庭安防服务器,对采集的数据进行计算。
为了方便讨论该模型,令第n个音频装置第m个时间点采样并量化得到的数据记为xm(n),μ为某事件的特征向量,那么采样数据x(n)和μ之间的误差可以表示为

式中:μ可以表示为μ=M(n)θ(n),M(n)为训练矩阵,θ(n)为m维稀疏向量,θi=0,1(i=1,2,…,m)。那么特征向量μ可以看成M的列向量的线性组合,因为当1时表示选择训练矩阵M中的第i列的特征,反之,当θi(n)=1时表示忽略训练矩阵M中的第i列的特征。


那么,当安防撤销时,在该音频采集的区域内的人类活动的音频将被作为训练的样本,令入侵的概率密度为

假设在第k次撤防做了mk个时间点的采集,在第k次撤防做了m'k个时间点的采集。直觉上,认为布防时,房间中没有人类活动,而撤防时,房间中可能有人类活动。由是,其最大似然估计为
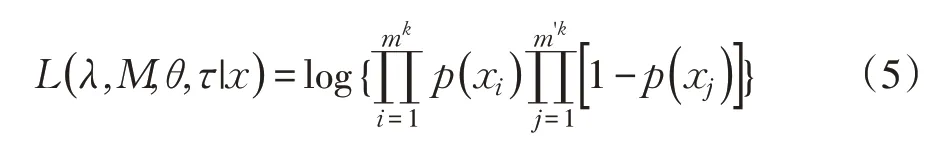
对公式(5)求解梯度方向,令梯度方向为0,可以求得λ,M,θ,τ,得到第n个采集装置的训练矩阵和稀疏向量。其中,j=1,2,…,m,表示第j次采样。
综上所述,由式(3)、式(4)、式(5),通过训练样本得到估计参数λ,M,θ,τ,代入公式(3),最后由式(4)可以由每一个测试音频特征向量,求得该房间受到入侵的概率。
2 系统设计
本节讨论本文提出的安防系统设计,如图2所示,使用音频采集装置对音频进行采集,然后对音频进行采样、量化,提取音频特征,最后通过概率计算可得房间受到入侵的概率,当概率高于某个阈值的时候,进行安防告警。

2.1 音频采样量化
声音在时间和幅度上都是连续的,为了对声音数据数字化,必须对声音进行采样和量化。对音频进行量化必须考虑两个重要的参数,即频率和幅度。频率是指声音的机械波每秒钟振荡的次数,而幅度是指该机械波振荡的强度[5]。本系统采用44 100 Hz采样频率,16位量化位数。那么通过采样和量化,可以得到各个音频采集装置对应的数字音频流[5]。
2.2 特征提取
对于各个音频装置采集得到的音频数据,以1 s为单位,可以得到44 100个16位的整数,将其看成一个44 100维的向量,就是本文所指的特征。这些特征向量包含两部分,一部分是撤防时采集的,另一部分是布防时采集的。每一次布防后,当未出现警情的所采集的特征向量和撤防时所采集的特征向量都作为训练的样本。当每一次布防开始到布防结束所采集的特征向量,用于测试样本。
2.3 概率计算及安防告警
当某一个特征向量计算所得的入侵概率大于所设阈值,本系统的安防服务器通过网络进行告警,并将该时间段中所采集的音频信号通过网络发送至安防中心,由安防中心进行进一步处理。
3 总结与展望
本文提出基于稀疏表示、使用音频特征进行安防监控的模型,推导一种使用最大似然估计求解稀疏向量和训练矩阵的算法,并设计了一个基于上述模型的安防系统,详细阐述了系统的关键技术实现。
但是,如何通过调整音频采集装置的摆放位置,以获得更好的监控效果,本文并未进行详细的探讨和数学证明,在今后的工作中可以在该方面进行更深入的研究。
[1]孙玉.数字家庭网络总体技术[M].北京:电子工业出版社,2007.
[2]王天荆,郑宝玉,杨震.基于自适应冗余字典的语音信号稀疏表示算法[J].电子与信息学报,2011,33(10)∶2372-2377.
[3]CHIANG C K,DUAN C H,LAI S H.Learning component-level sparse representation using histogram information for image classification[J].IEEE International Conference on Computer Vision,2011.[S.l.]:IEEE Press,2011:1519-1526.
[4]周伟锋,熊金凯,李榕,等.视音频硬盘采集压缩系统设计、应用及分析[J].电视技术,2011,35(20):67-69.
[5]宋明超,林岩.TMS320C6727的音频采集处理与回放系统设计[J].单片机与嵌入式系统应用,2008(10):26-28.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
新高考·高一数学(2022年3期)2022-04-28
保定学院学报(2022年2期)2022-04-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
电子制作(2017年9期)2017-04-17
高中生学习·高三版(2016年9期)2016-05-14
