
基于Matlab仿真的模式分类实验研究
2013-01-17 02:13刘忠宝赵文娟
实验技术与管理 2013年3期
刘忠宝,赵文娟
(1.中北大学电子与计算机科学技术学院,山西太原 030051;2.山西大学商务学院信息学院,山西太原 030031)
基于Matlab仿真的模式分类实验研究
刘忠宝1,赵文娟2
(1.中北大学电子与计算机科学技术学院,山西太原 030051;2.山西大学商务学院信息学院,山西太原 030031)
模式识别逐步成为高校本科生和研究生的主干课程,模式分类实验越来越受到重视。以目前广泛的模式分类方法——支持向量机为例,通过Matlab仿真,对模式分类实验方法进行探讨与研究。该实验有助于学生进一步理解模式分类的工作原理,为后续相关内容的学习奠定坚实的基础。人工数据集和标准数据集上的实验表明,支持向量机能较好地完成分类任务。
模式分类;Matlab仿真;支持向量机
模式分类是数据挖掘、机器学习和模式识别的重要方法之一,目前已广泛应用于字符识别、计算机辅助诊断、语音识别、签名认证、地学分析、文件检索等领域。模式分类利用计算机来模拟人类对信息的分析处理能力,使计算机能够识别已有知识、获取新知识并不断改善性能,实现自身完善[1-2]。模式分类的目的是在已有数据的基础上利用某种分类方法构造一组分类规则,对未知数据类型进行预测[3]。模式分类可分为线性方法和非线性方法。线性方法通过模拟人脑的感知和学习能力来揭露数据间的内在关系;非线性方法通过将线性不可分的数据,以非线性映射方式映射到新的特征空间,使得数据在新空间中线性可分。
相对于其他高级语言,Matalb[4]适用于对数据编辑、整理、统计分析以及图表的绘制,具有简单、易读、易学的特点。Matalb的数据处理能力和操作简易性越来越为人所接受。因此,本文以支持向量机(support vector machine,SVM)为例对模式分类实验方法进行探讨与研究。学生在学习模式分类基本原理后,通过Matalb构建合适的算法,在分析人工数据集和标准数据集实验结果的基础上,加深对模式分类工作原理的理解。
1 模式分类工作原理
模式分类主要有信息获取、预处理、特征提取与选择、分类器设计及分类决策等五大步骤。模式分类工作原理如图1所示。
(1)信息获取。信息获取指利用各种传感器把研究对象的各种信息转化为计算机可接受的数据或符号。

图1 模式分类工作原理图
(2)预处理。预处理的目的是去除信息获取中掺入的干扰和噪声,并对各种因素造成的退化现象进行复原。
(3)特征提取。上述步骤得到的数据量一般较大。为了有效地实现分类,应对原始数据进行选择或映射,得到最能反映分类本质的特征,此过程即为特征提取。特征提取不仅减少了处理时间,而且提高了分类效率。
(4)分类器设计。分类器设计的目的是把待识别的模式分配到相应类别中。基本做法是:对一定量的样本进行训练得到某个判别准则。
(5)分类决策。分类决策的出发点是分类器。分类器按照判别准则将待识别模式进行类属判别。
在模式分类中,步骤(1)和(2)一般属于数字信号处理和图像处理领域研究的内容,并且与具体问题有关,步骤(3)属于特征降维领域研究的内容,因此本文重点关注步骤(4)和(5)。
2 支持向量机
对于一个包含N个模式二类划分问题,设给定训练集合为

支持向量机是一种基于统计学习理论的机器学习方法[5-7]。它建立在统计学习VC维理论和结构风险最小原理基础上,成功地将最大分类间隔思想和基于核的方法结合在一起。其几何原理是使用2个带有最大间隔的平行超平面,将两类样本尽可能地分开。设超平面方程为wTx+b=0,分类间隔为2/‖w‖,则该最优化问题线性形式可描述为

其中C为惩罚因子,它控制对错分样本的惩罚程度,C=0时表示线性可分,C>0时表示线性不可分;对于线性不可分或事先未知是否线性可分的情况,通过引入松弛因子ξi允许错分样本的存在。
最优化问题非线性形式为

其中φ(xi)表示从原始样本空间到高维特征空间的映射。
由Lagrangian定理可将原问题转化为如下对偶形式:
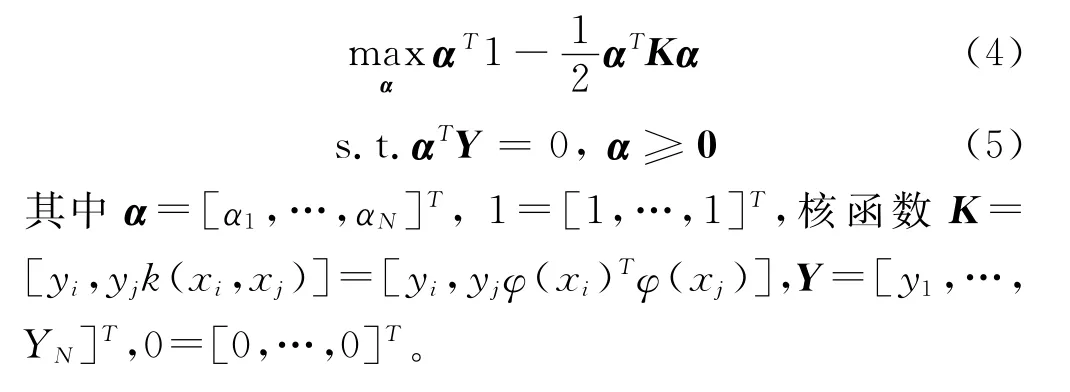
3 实验设计
实验环境为3GHz Pentium4CPU、1GRAM、Windows XP及Matlab7.0。实验选取的核函数为高斯核函数:
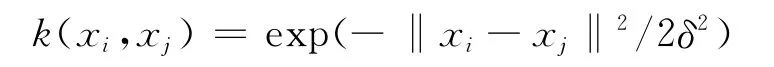
式中δ为方差。
3.1 实验参数设置
目前参数选择的主流方法有:单一验证估计、留一法、K倍交叉验证法以及基于样本相似度的方法等。除测试样本外,本文将训练样本分为4份训练集和1份验证集进行5倍交叉验证以获取实验参数。
参数通过网格搜索策略[8]选择。高斯核函数的方差δ在网格搜索选取,其中¯x为训练样本平均范数的平方根;惩罚因子C在网格{0.01,0.05,0.1,0.5,1,5,10}中搜索选取。
3.2 人工数据集实验
人工构造一个二维香蕉型数据集,如图2(a)所示。该数据集两类样本有交叉。实验选取高斯核函数的方差δ=1。该数据集中,第一类(Class1)有52个样本,其中训练样本30个,测试样本22个;第二类(Class2)有53个样本,其中训练样本30个,测试样本23个。SVM的实验参数及分类结果见表1和图2。在表1中,Accuracy(%)表示分类精度。在图2(a)中,Class1和Class2分别表示两类样本;在图2(b)中,Train1和Train2分别代表两类的训练样本;Test1和Test2分别代表两类的测试样本;支持向量(support vectors)用SVs表示;样本错分点(misclassified points)用MPs表示。
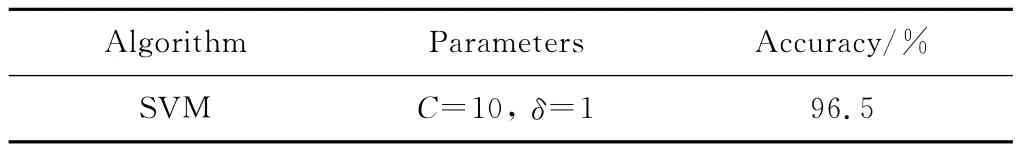
表1 SVM参数选取及分类结果(人工数据集)

图2 人工数据集及分类结果
由图2可以看出:SVM发现的支持向量主要分布在两类交界附近。这些支持向量对SVM分类精度影响较大,主要原因是它们直接关系到分类面的确定。由表1可以看出:SVM在上述人工数据集上具有较高的分类精度,较好地完成了模式分类任务。
3.3 标准数据集实验
实验数据集见表2。表2中的#Total表示样本总数,#Class1表示第一类的样本数,#Class2表示第二类的样本数,Dim表示样本维数。实验参数及分类结果见表3。

表2 实验数据集
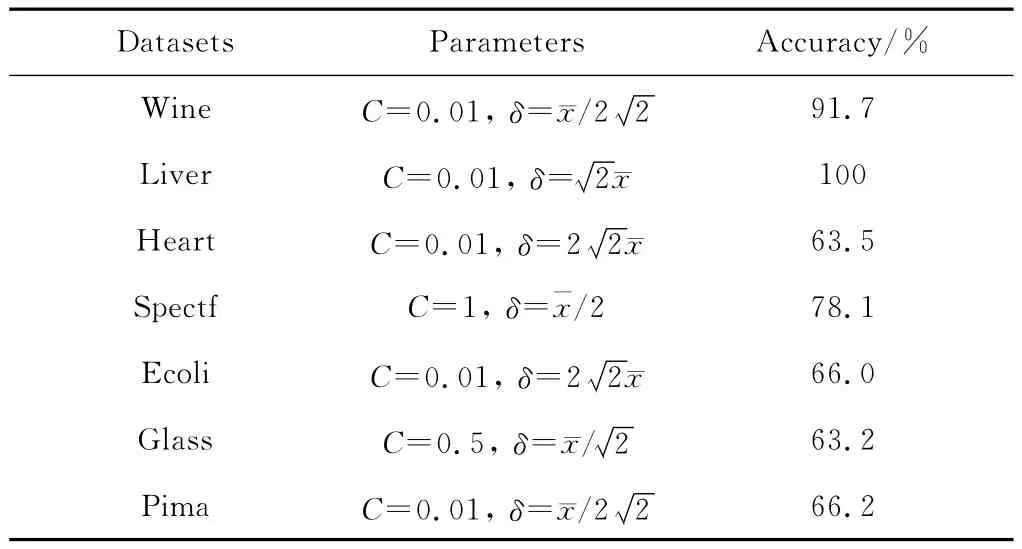
表3 实验参数及分类结果
由表3可以看出:在Wine、Liver数据集上SVM的分类精度优良;在Spectf数据集上分类精度较好;在Heart、Ecoli、Glass、Pima数据集上的分类精度基本可以接受。由上述实验得出以下结论:
(1)SVM在UCI数据集上具有较好的分类效果;
(2)分类方法均有一定的适用范围,没有适用于任何数据集的分类方法。
4 进一步实验
尽管SVM在实际应用中取得了理想的分类效果,但仍面临两大问题:大规模数据分类问题和抗噪问题。为了解决上述问题,需对传统SVM进行相应改进。
(1)针对大规模数据分类问题,引入核心向量机(core vector machine,CVM)[9]。Tsang等人提出的核心向量机把QP问题的求解转化为最小包含球问题,并使用一个逼近率为(1+ε)的近似算法得到核心集。该核心集规模远小于原始样本规模,通过对该核心集训练可得到理想的分类效果。此外,核心集规模仅与参数ε有关,与样本数及样本维数无关。该结论从理论上保证CVM适用于大规模样本分类问题。因此,通过建立SVM与CVM之间的关系,将SVM的适用范围从中小规模数据扩展到大规模数据。
(2)针对抗噪问题,引入模糊理论。模糊理论是一种处理不精确性和不确定性信息的理论工具。采用模糊技术进行模式识别时,某特征属于某集合的程度由0与1之间的隶属度来描述。把一个具体的元素映射到一个合适的隶属度由隶属度函数实现[10-11]。因此,在SVM中引入隶属度函数,以提高SVM的抗噪能力。
5 结束语
模式识别逐步成为高校本科生和研究生的主干课程,而模式分类实验越来越受到重视。鉴于Matlab在数据编辑、整理、统计分析以及图表绘制方面的优势,本文在Matlab基础上,以SVM为例,对模式分类实验方法进行了探讨和研究。人工数据集和标准数据集上的实验表明,SVM能较好地完成模式分类任务。本文提出的实验方法有助于学生进一步理解模式分类的工作原理,为后续学习奠定坚实的基础。
(References)
[1]王珏,周志华,周傲英.机器学习及其应用[M].北京:清华大学出版社,2006.
[2]徐勇,张大鹏,杨健.模式识别中的核方法及其应用[M].北京:国防工业出版社,2002.
[3]刘红岩,陈剑,陈国青.数据挖掘中的数据分类算法综述[J].清华大学学报:自然科学版,2002,42(6):727-730.
[4]刘卫国.MATLAB程序设计与应用[M].北京:高等教育出版社,2006.
[5]Vapnik V.The nature of statistical learning theory[M].New York:Springer-Verlag,1995.
[6]邓乃扬,田英杰.支持向量机:理论、算法与拓展[M].北京:科学出版社,2009.
[7]Pal M,Foody G M.Feature selection for classification of hyper spectral data by SVM[J].IEEE Trans on Geoscience and Remote Sensing,2010,48(5):2297-2307.
[8]Muller K R,Mika S.An introduction to kernel-based learning algorithms[J].IEEE Trans on Neural Networks,2001,12(1):181-201.
[9]Tsang I W,Kwok J T,Cheung P M.Core vector machines:fast svm training on very large data sets[J].Journal of Machine Learning Research,2005(6):363-392.
[10]Lin C F,Wan S D.Fuzzy support vector machines[J].IEEE Trans on Neural Networks,2002,13(2):464-471.
[11]孙名松,高庆国,王宣丹.基于双隶属度模糊支持向量机的邮件过滤[J].计算机工程与应用,2010,46(2):93-95.
Research on pattern classification experiments based on Matlab simulation
Liu Zhongbao1,Zhao Wenjuan2
(1.School of Electronics and Computer Science Technology,North University of China,Taiyuan 030051,China;2.School of Information,Business College,Shanxi University,Taiyuan 030031,China)
Pattern recognition gradually becomes a major course of undergraduates and postgraduates,and the researchers are paying more and more attention to pattern classification experiments.Taking a widely-used classification method,i.e.,Support Vector Machine(SVM)as an example,pattern classification experiments based on Matlab simulation are discussed.The experiments proposed enable students further to understand the working principle of pattern classification and lay foundation for further study.Experiments on man-made and UCI datasets show that the SVM is effective and it can complete the classification task.
pattern classification;Matlab simulation;support vector machine(SVM)
TP391.4-33
A
1002-4956(2013)03-0092-04
2012-06-08
江苏省自然科学基金(BK2009067)
刘忠宝(1981—),男,山西太谷,博士,CCF会员(E200015757M),主要研究领域为机器学习、信息检索.
E-mail:liu_zhongbao@hotmail.com
猜你喜欢
数学物理学报(2022年4期)2022-08-22
中学生数理化·高一版(2021年2期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
数学物理学报(2017年5期)2017-11-23
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
新课程学习·中(2013年3期)2013-06-14
