
基于图理论学习模型的胃窥镜图像自动标注
2012-12-22 07:34:56王李冬
杭州师范大学学报(自然科学版) 2012年1期
王李冬
(杭州师范大学钱江学院,浙江杭州 310012)
基于图理论学习模型的胃窥镜图像自动标注
王李冬
(杭州师范大学钱江学院,浙江杭州 310012)
为了解决目前医学图像检索领域不能有效缓解“语义鸿沟”的问题,提出基于图理论学习模型的图像自动标注方法.首先讨论了医学图像的标注问题,总结了现有关医学图像标注的研究工作.以胃窥镜图像为具体研究对象,针对图学习模型中的图像-标注词间的关系提取以及图像相似度计算进行了详细分析,并有效地融合进医生的诊断信息作为图像的高级语义特征,更有效地计算出图像间相似度.最后,在Toy data数据集和临床胃窥镜图像集上进行了一系列的实验,结果表明本文方法优越于传统图像标注方法.
自动医学图像标注;图理论学习;胃窥镜图像;高级语义
1 概 述
有效的医学图像检索系统对诊断和治疗起到有效的辅助作用.随着数字成像技术的发展,近几年医学图像的存储量也在大规模增长.医学图像检索技术应运而生,并且受到了广泛关注.
医学图像检索的目标即从图像库中检索到具有相同病灶的病理图像,因此于不同种类、不同部位之间的医学图像间进行检索,实用意义不大.由于相同部位医学图像存在过度相似、分辨率高等特性,单纯依靠底层特征进行检索往往达不到用户需求,所以目前医学图像检索领域的一个瓶颈问题即底层视觉特征和高层语义之间的语义鸿沟(semantic gap).因此,如何实现医学图像的自动语义标注,将是MIR(medical image retrieval)技术中极具挑战的一项工作.
目前,普通图像的自动标注已经得到广泛研究并取得了较好的效果[1-5].而医学图像标注问题在国内外研究较少.医学图像自动标注属于医学图像的自动分类问题[6-7],分类的主要标准在于视觉和解剖部位的区别.而针对同一解剖部位的医学图像检索而言,自动标注问题就演化为同一种类医学图像中病理特征的分类,即将患有相同病理特征的病患者图片归为同类.要实现该目标需要借助专业医生的诊断信息作为训练数据.文献[8]针对灰度医学图像和彩色医学图像基于神经网络学习进行分类,提取了底层纹理和颜色特征进行网络的训练.文献[9]针对X光图像进行基于区域的内容层次语义架构,实现多层次图像标注.另外,ImageCLEF[6]中加入了医学图像标注任务.该任务的主要目标是针对116幅类别中的10 000幅训练图像库进行训练,并对1 000幅测试图像库进行标注.
上述所有方法解决的主要问题即针对不同的解剖部位和形态(modality)的医学图像进行训练,从而实现对测试图像的正确解剖部位和形态的标注.但这些方法主要存在两个缺点:1)分类方法还是源于图像的底层特征间的差异,没有从根本上建立底层特征和高级语义的关系.2)针对解剖部位和形态的标注并不能解决同类医学图像检索的问题,因为目前的医学图像检索研究对象为同种部位图像.因此,本文提出的方法跟以往的医学图像标注有所区别.为了进一步提高医学图像检索的效率,针对同一解剖部位图像,本文标注的内容为该图像中体现出的病理特征,这往往需要医生的专业诊断信息,再在其基础上进行训练得到未标注医学图像的病理特征.
基于上述分析,为了保证图像标注的准确性,本文提出基于图理论学习模型的医学图像自动标注方法.研究对象采取胃窥镜(内镜)图像.为了有效结合医生的诊断语义信息,图理论方法中的测试图像集利用医生的诊断信息,并从诊断信息中提取出关键诊断词作为标注词,再利用图理论学习模型设计出胃窥镜图像标注框架.
2 图理论学习模型
图理论学习模型属于半监督学习算法(semi-supervised learning)[10],是近年来模式识别和机器学习领域研究的重点问题.它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题.也就是说,已知类标的训练数据和未知类标的测试数据都参与到训练过程中来.半监督学习和传统的监督学习和无监督学习相比,更适合于数据总量较大,但训练数据相对缺乏的情况.
图理论模型最初于文献[11]中被提出,通过图理论来学习流形空间中数据集合的分类情况.接下来简要介绍图理论学习模型的原理.
给定一系列的点集合χ={x1,...,xl,xl+1,...,xn}⊂Rm和类标集合Γ={1,...,c},前l个点xi标记为yi∈Γ,其余的点的类标未知.图理论模型的目标即获得未知类标的点的类别信息.矩阵F=[F1T,…,FnT]T对应于数据集χ上的分类信息,其中每个点xi对应的类别信息yi满足yi=argmaxj≤cFij,可以理解,F主要实现数据集χ到Rc上的映射.定义n×c大小的矩阵Y,若xi的类标yi=j,则Yij=1,否则Yij=0.那么,图理论学习算法如下:
1)计算邻接矩阵W,W定义为
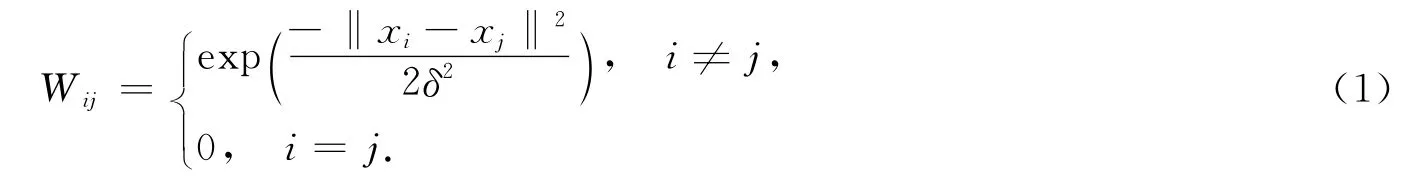
2)构造相似性矩阵S,满足S=D-1/2WD-1/2.其中,D为对角矩阵,Dii为W中第i行各元素之和.
3)迭代计算式(2)直至收敛

其中,α为(0,1)间的参数.
4)按照最终状态F*,对各点进行分类.
假设给定图G=(V,E),点集合V等价为为上述提到的数据集χ,边集合E则通过邻接矩阵W体现.算法第2步中,邻接矩阵经过了正则化处理,而该步骤对接下来的迭代过程是必不可少的,可见,第1、2步的过程和谱聚类算法相似.由第3步的迭代过程可以发现,每个点从邻近点获得信息,同时保留了初始信息.参数α代表了邻近点信息和初始信息的比例.
为了减少迭代过程,可以直接计算出学习过程的收敛解,具体计算过程见文献[11],其最终的收敛解F*为

由上述分析可得,为了避免复杂的迭代计算,可以直接计算式(3),从而避免庞大数据量带来的计算开销.
3 基于图理论学习的内镜图像标注
3.1 图像标注框架
基于以上讨论,本文将每幅图像作为图节点V,以图像间的相似度作为边E,通过图理论模型的建立就可以实现将类标信息从已标注图像到未标注图像的传播,从而完成所有图像的标注任务.由此,笔者提出了基于图理论的胃镜图像标注框架,如图1所示.
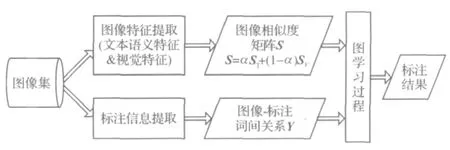
图1 基于图理论学习的胃窥镜图像标注Fig.1 Endoscopic image annotation based on graph learning model
由图1可得,本模型框架主要步骤包括图像特征提取得到图像间相似度S,以及图像标注信息提取得到图像和标注词间的关系Y,接下来介绍这两部分的具体实现过程.
3.2 图像 -标注词间关系
胃镜图像的训练数据集需要病理特征相关的信息.由于研究对象统一为胃窥镜图像,所以针对解剖部位的标注信息并无意义.本文的训练图像集中的标注信息来源于医生的诊断信息,具体如表1所示.

由上表可得,医生的诊断信息包括“内镜表现“和“内镜诊断”两部分.而本文使用的训练集数据的标注信息由医生的“内镜诊断”词构成,如胃窦炎、溃疡、胃Ca等关键病理特征词汇.由于某位病者所拍的胃窥镜图像可能含有多种病理特征,那么一幅图像可以含多个标注词,这正符合了图像标注是一种多标记问题(multi-label)而非多分类(multi-class)问题.笔者将每个标注视为一类,若库中所有图像数为M,标注的类别数为c,则初始状态矩阵Y的大小为M×c,即当某胃镜图像被标注为某词汇wj时,Yij=1,否则Yij=0.描述标注状态的矩阵FM×c,Fij表示为第i幅图像被标注为第j个关键词的可能性.
3.3 图像相似度
以往的图像相似度主要建立在视觉特征的基础上,即通过提取图像的底层视觉信息计算图像间的相似度.本文除了采用底层特征建立内镜图像间的相似度SV之外,利用训练图像的诊断文本信息建立图像间的文本语义相似度ST,有效地融合进图像的高层语义特征,减小高层语义特征和低层视觉特征间的“语义”鸿沟.
由表1的信息可得,训练图像包含了医生诊断文本信息.为了自动提取语义信息,首先利用中文分词系统ICTCLAS(http://ictclas.org/)进行分词,并过滤掉停用词.由于医学用词主要集中于名字和形容词,所以再次过滤掉其他词性的词汇,保留名词和形容词词汇.将图像i所对应的文本信息表示为表示每个词汇的权重值,权重值的计算采用TFIDF方法[12]实现.最后,两幅图像的文本语义相似度可以通过余弦距离计算得到:
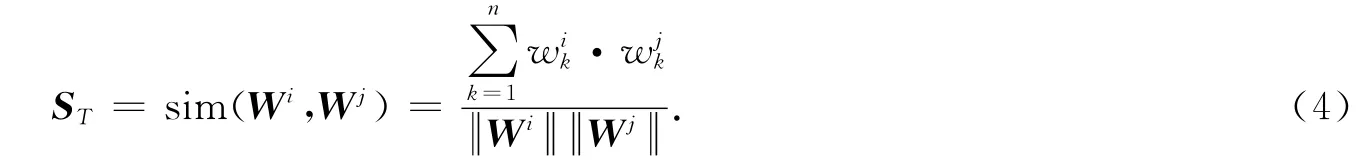
由于内镜图像属于彩色图像,并含有丰富的纹理信息,于是,本文采用颜色直方图和纹理谱方法[13]分别提取出图像的颜色和纹理特征向量.将2个向量合为一维特征,则图像间的视觉相似度转换为向量间的距离计算,同样采用余弦距离进行测量,得到SV.因此,最终图像间的相似度融合进视觉特征差异和文本语义特征差异,由下式得到:

其中,α表示文本语义特征所占的比重.若该值为0,则最终的图像间的相似度完全由视觉特征来决定.
4 实验与讨论
4.1 实验数据
为了有效验证图理论学习算法的效果,通过两部分实验来证明:第一部分,采用Toy Data数据集验证该算法的半监督分类性能;第二部分,采用的实验数据来自于医院的专业临床内镜图像.共采集500幅图像进行试验,其中随机抽取300幅作为训练数据,200幅作为测试数据,图像大小统一为360×357.
4.2 Toy Data实验效果
Toy Data数据集由呈半月型分布的数据集构成,如图2a所示(每个小圆圈表示一个数据点).指定每个半月型中的某个点为已标识点,其余都为未标识点.那么由该图可得到,较理想的分类标准为:每个点和邻近点存在一定的相似性,而且在同一个半月中的点间相似度应该大于不同半月中的点间相似度.本文将图理论方法的分类效果和基于RBF核函数的SVM算法以及KNN算法进行比较,效果分别见图2b和图2c.由图2可以得到,基于图理论的分类算法取得了理想的分类效果.
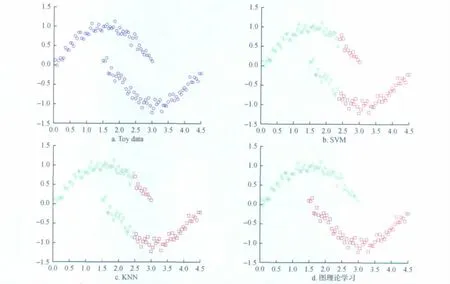
图2 Toy data数据集分类性能比较Fig.2 Comparison of classification performance on Toy dataset
4.3 内镜图像实验效果
表2给出了个别内镜图像的标注实例,并展示了本文方法对部分测试内镜图像的标注结果.表中的第3列代表本文方法的标注结果.判断标注结果是否正确,主要判断标注词是否来源于“内镜诊断”信息.由表2的数据可以得到图像1959_5取得的标注信息和“内镜诊断”信息保持一致,图像2129_1和2127_4取得的标注信息少了病理特征词“十二指肠炎”.但总体来说,图像标注结果和内镜诊断信息大致保持一致,能较准确地描述出一幅图像的主要病理特征.

?
为了证明本文提出方法的有效性,该部分实验采用跨媒体相关模型(CMRM)[2]与本文方法进行比较.CMRM属于传统的图像标注方法之一,在该方法中,图像被表示为经过量化后分割区域的组合,每个量化区域叫做“blob”,利用每个“blob”之间的差异计算图像间的相似度.该方法实现的是基于图像视觉相似性的类标信息的传播.为了评价图像标注方法的整体性能,采用查准率作为判定指标.首先以某一关键词wi作为查询,在标注好的测试图像集中进行查找,实验设计共返回Nr幅图像,返回的图像中和关键词wi相关的,即标注正确的图像数为Nc幅,则查准率precision的计算方式为

在测试集中的每个关键词都需执行上式计算,最后针对每次计算取平均值作为最终结果,以此作为评价指标.CMRM方法和图理论方法的标注性能比较见图3.
由图3可得,基于图理论模型的标注方法比CMRM表现出更好的标注性能.不论检索返回的图像数为多少,都能保持较稳定的优越性.这是因为,CMRM方法同样需要计算图像间的视觉相似性来传播类标信息,而该视觉相似性的计算方法是通过“blob”的量化,该方法存在两个缺点:1)量化过程中存在一定的信息丢失;2)单纯依靠底层视觉特征还是无法缓解和高层语义之间的“语义”鸿沟.本文提出的图理论模型标注方法计算图像相似度时,有效地融合进了图像的文本相似度,能更好地估计图像间的相似性.
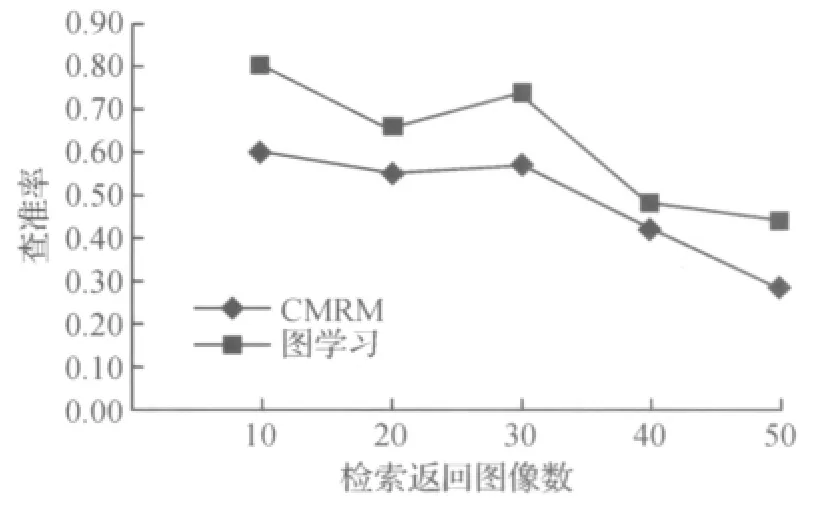
图3 内镜图像集上的标注性能比较Fig.3 Comparison of annotation performance on endoscopic image dataset
5 结 论
提出一种基于图理论学习模型的内镜图像标注方法,并将该方法的主要2个步骤进行详细解析.主要包括图像-标注词间的关系提取以及图像相似度的计算.其中,图像-标注词间的关系提取利用医生的专业诊断信息得到,图像相似度的计算融入了每幅内镜图像的诊断信息,并在计算底层视觉信息的基础上融入了图像间的文本相似度计算,即融合了底层特征和高层语义特征.最后,通过在Toy data数据集和临床内镜图像集上对本文方法分别在分类和标注功能上进行了比较,验证了该方法的有效性.
在今后的工作中,将针对内镜图像同种病理特征的进一步标注,如浅表性胃窦炎和萎缩性胃窦炎的进一步分类,以实现医学图像的有效病理特征自动标注,从而有效提高医学图像检索的效果.
[1]Agrawal R,Changhua W,Grosky W,etal.Bayesian framework for automatic image annotation using visual keywords[J].Communications in Computer and Information Science,2010,75:142-157.
[2]Jeon J,Lavrenko V,Manmatha R.Automatic image annotation and retrieval using cross-media relevance models[C]//Proc.of the ACM SIGIR.Toronto:ACM Press,2003:119-126.
[3]Kang F,Jin R,Sukthankar R.Correlated label propagation with application to multi-label learning[C]//Proceedings of CVPR.New York,2006:1719-1726.
[4]Xiang Yu,Zhou Xiangdong,Liu Zuotao.Semantic context modeling with maximal margin Conditional Random Fields for automatic image annotation[C]//Proceedings of CVPR,San Francisco,CA,USA,2010:3368-3375.
[5]Wang Yong,Mei Tao,Gong Shaogang,etal.Combining global,regional and contextual features for automatic image annotation[J].Pattern Recognition,2009,42(2):259-266.
[6]Deselaers T,Deserno T M,Muller H.Automatic medical image annotation in ImageCLEF2007:Overview,results,and discussion[J].Pattern Recognition Letters,2008,29:1988-1995.
[7]Yao Jian,Zhang Zhongfei,Antani S,etal.Automatic medical image annotation and retrieval[J].Neurocomputing,2008,71(10):2012-2022.
[8]Kalpathy-Cramer J,Hersh W.Automatic image modality based classification and annotation to improve medical image retrieval[J].Study Health Technology Information,2007,129(2):1334-1338.
[9]Mueen A,Zainuddin R,Sapiyan M.Automatic multilevel medical image annotation and retrieval[J].Journal of Digital Imaging,2010,21(3):208-295.
[10]卢汉清,刘静.基于图学习的自动图像标注[J].计算机学报,2008,31(9):1629-1639.
[11]Zhou Dengyong,Bousquet O,Lal T N,etal.Learning with local and global consistency[C]//Proceedings of NIPS,Cambridge,MA:MIT Press,2003:237-244.
[12]Martineau J,Finin T.Delta TFIDF:an improved feature space for sentiment analysis[C]//Proccedings of ICWSM,San Jose,CA:AAAI Press,2009:258-261.
[13]He Dongchen,Wang Li.Texture features based on texture spectrum[J].Pattern Recognition,1991,24(5):391-399.
Automatic Endoscopic Image Annotation Based on Graph Learning Model
WANG Li-dong
(Qianjiang College,Hangzhou Normal University,Hangzhou 310012,China)
To solve the“semantic gap”problem in medical image retrieval,the paper proposed the automatic image annotation based on graph learning.It discussed the process of medical image annotation,and summarized related researchworks.Choosing endoscopic images as the object,the thesis analyzed the ectraction of the relationships between images and annotation words as well as the image similarity computation,compromised doctors'diagnostic information as the high-level semantic features of the images,which effectively calculated the image similarity.A series of experiments were conducted on Toy data and endoscopic images,the results show the method in this paper is better than the traditional image annotation methods.
automatic medical image annotation(AMIA);graph-based learning;endoscopic image;high-level semantic feature
TP391
A
1674-232X(2012)01-0071-06
11.3969/j.issn.1674-232X.2012.01.016
2011-02-10
浙江省教育厅科研计划项目(Y201016245).
王李冬(1982—),女,讲师,博士,主要从事数字图像处理、图像检索、文本语义挖掘等研究.E-mail:violet_wld@163.com
猜你喜欢
保健医苑(2022年4期)2022-05-05 06:11:12
开放教育研究(2020年2期)2020-03-31 01:54:14
医学新知(2019年4期)2020-01-02 11:04:02
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
现代语文(2016年21期)2016-05-25 13:13:44
专利代理(2016年1期)2016-05-17 06:14:36
西南国防医药(2015年11期)2015-02-28 19:38:48
大连民族大学学报(2015年2期)2015-02-27 08:28:11
河南医学研究(2014年3期)2014-02-27 14:51:52
外语学刊(2011年1期)2011-01-22 03:38:33
