
基于隐马尔可夫模型的转录因子文本挖掘算法
2012-12-06 11:40:48吴晓洲万里明韩霄松梁艳春吴春国
吉林大学学报(理学版) 2012年2期
吴晓洲, 万里明, 韩霄松, 梁艳春, 吴春国,3
(1. 吉林大学 计算机科学与技术学院, 符号计算与知识工程教育部重点实验室, 长春 130012; 2. 中国人民解放军空军装备研究院 装备总体论证研究所, 北京 100076; 3. 上海理工大学 管理学院, 上海 200093)
本文基于文献[1-2]提出一种基于隐马尔可夫模型的转录因子文本挖掘算法HMM-TFM(hidden Markov model based transcription factor name mining), 使用隐马尔可夫模型在英文文献中识别转录因子名称, 该方法HMM易于建立, 不需要大规模的转录因子实体词库与规则集.
1 基于隐马尔可夫模型的转录因子文本挖掘算法
隐马尔可夫模型HMM由一个五元组(ΩX,ΩO,A,B,π)表示, 其中:ΩX={X1,…,XN}表示隐藏状态集合;ΩO={O1,…,OM}表示观察值集合;A=(aij)表示状态转移概率矩阵;B=(bi(k))表示观察值概率矩阵;π=(π1,…,πN)是初始状态[3]. 通常简略地将隐马尔可夫模型表示成三元组的形式λ={A,B,π}. 观察值集合与隐藏状态集合的选择对算法的性能至关重要.
HMM-TFM首先将文献以自然语句为单位处理成观察值序列, 每个单词对应一个观察值. 一些在自然语言中频繁出现的常用单词, 如连接词、 介词、 系动词等, 由于其数量较少, 可标记其真实词性, 并以真实词性作为其观察值, 其他单词的观察值是根据后缀判断的词性. 本文的观察值集合为
ΩO={verb,adv,conj,art,prep,adj,be,noun,punctuation,unknown},
其中: verb表示动词; adv表示副词; conj表示连接词; art表示冠词; prep表示介词; adj表示形容词; be表示系动词; noun表示名词; 有从句出现时, 若不考虑标点符号会使句子语法结构变得混乱, 则punctuation表示标点符号也作为一种观察值; unknown表示根据后缀无法判断词性的单词. 高频词和后缀到观察值的映射关系列于表1. 由表1可见, 映射关系可判断多数单词的词性. 如后缀“-ment”对应观察值noun, 后缀“-ate”对应观察值verb. 在本文使用的训练样本中, 共出现1 095个不同的单词, 其中只有370个单词根据该映射表不能判断词性, 即训练样本的观察值序列中, unknown的比例较小.

表1 高频单词与后缀到观察值的映射关系Table 1 Relationship of high-frequency words, suffixes and observations mapping
HMM-TFM算法中隐藏状态表示单词在实际语境中的真实词性, 本文的隐藏状态集合为
ΩX={verb,adv,conj,punctuation,art,prep,adj,be,noun,tf},
其中, 状态tf为表示转录因子的单词,其他隐藏状态的含义与观察值集合中对应元素的含义相同, 但观察值通过判断后缀得到词性, 而隐藏状态通过人工标记或HMM解码得到当前语境中的真实词性.
为了高效过滤掉与转录因子无关的语句,本文定义一个谓语集, 通过语句的谓语判断其是否与转录因子的描述相关. 谓语集中包含8个元素, 是通过人工阅读50篇转录因子相关文献总结出的动词, 这些动词在文献中通常作为谓语描述转录因子与启动子的调控或结合关系. 因此, 在将文献中语句处理成观察值序列时, 只需处理谓语集中元素出现的语句. 与建立转录因子名称的词库相比, 使用谓语集更简单易行. 谓语集中元素如下:
predicate{repress,bind,transactivate,regulate,activate,suppress,upregulate,downregulate}.
谓语集中元素作为谓语出现在语句中时, 转录因子可能出现在主语或主语从句中. 语句中动词后面的部分是宾语、 宾语从句或修饰宾语的定语. 在使用谓语筛选语句后, 对于主动语态语句, 转录因子的名称不会出现在谓语后面, 因此在将语句处理成观察值序列时, 可不考虑动词后面的部分; 类似地, 对于被动语态语句, 则只处理谓语后面的部分. 理论上, 这样处理可缩短时间序列的长度, 从而降低HMM-TFM算法的时间复杂度和空间复杂度.
2 实验结果
以“transcription factor”和“promoter”为关键词在科技引文数据库中进行文献的采集, 选出50篇英文文献作为HMM-TFM算法的训练集. 经过人工筛选后共得到969条包含谓语集中动词的语句, 选出其中100条作为训练样本. 通过人工标记词性得到这些语句的隐藏状态序列, 观察值序列通过上述方法获得. 训练得到的初始概率向量为π={0.070 18,0.162 36,0.092 97,0.001 17,0.162 07,0.116 43,0.069 65,0.000 29,0.231 78,0.093 09}. 状态转移概率矩阵和观察值概率矩阵分别列于表2和表3.
由于文献长度影响单词的总得分, 而且有的文献会同时提到若干个转录因子, 因此选择一个固定的阈值或取最高得分并不合适. 对于每篇文献, HMM-TFM算法选择最高分单词得分的80%作为阈值. 实验结果表明, 当文献中只提到一种转录因子时, 其得分明显高于其他单词, 不会因为将阈值降低到最高得分的80%而将其他单词识别为转录因子名称. 而文献中出现多个转录因子时, 这些单词的得分较接近, 这种阈值设定方法能够避免转录因子的遗漏.
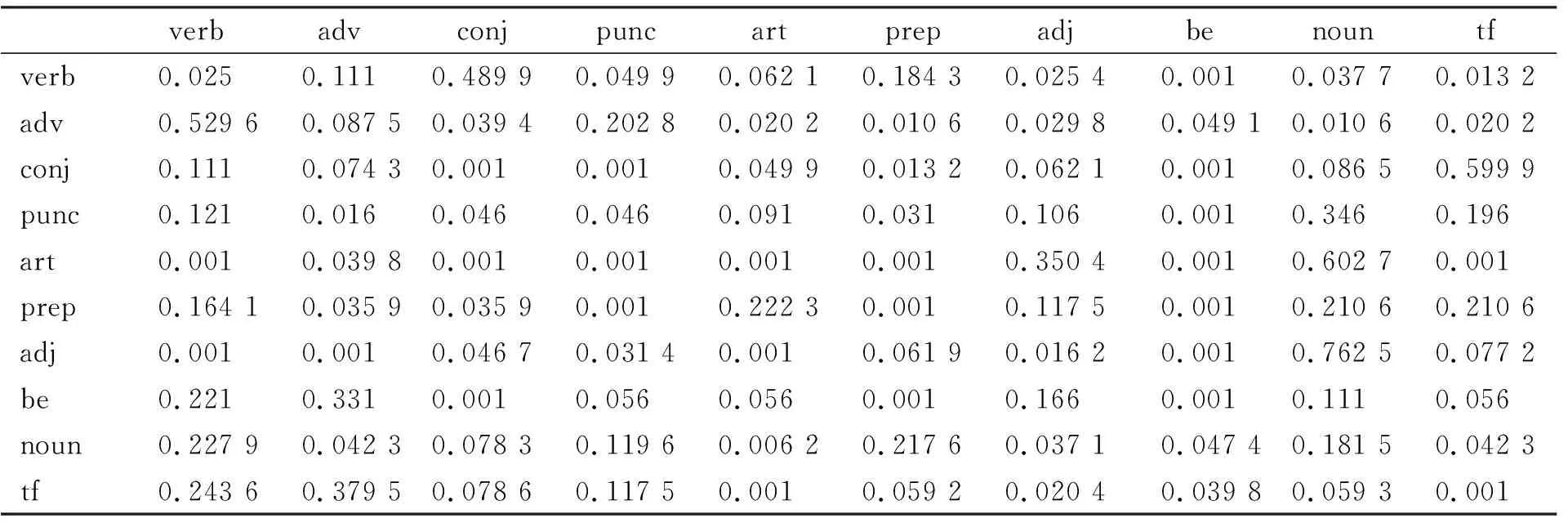
表2 状态转移概率矩阵Table 2 State transition probability matrix
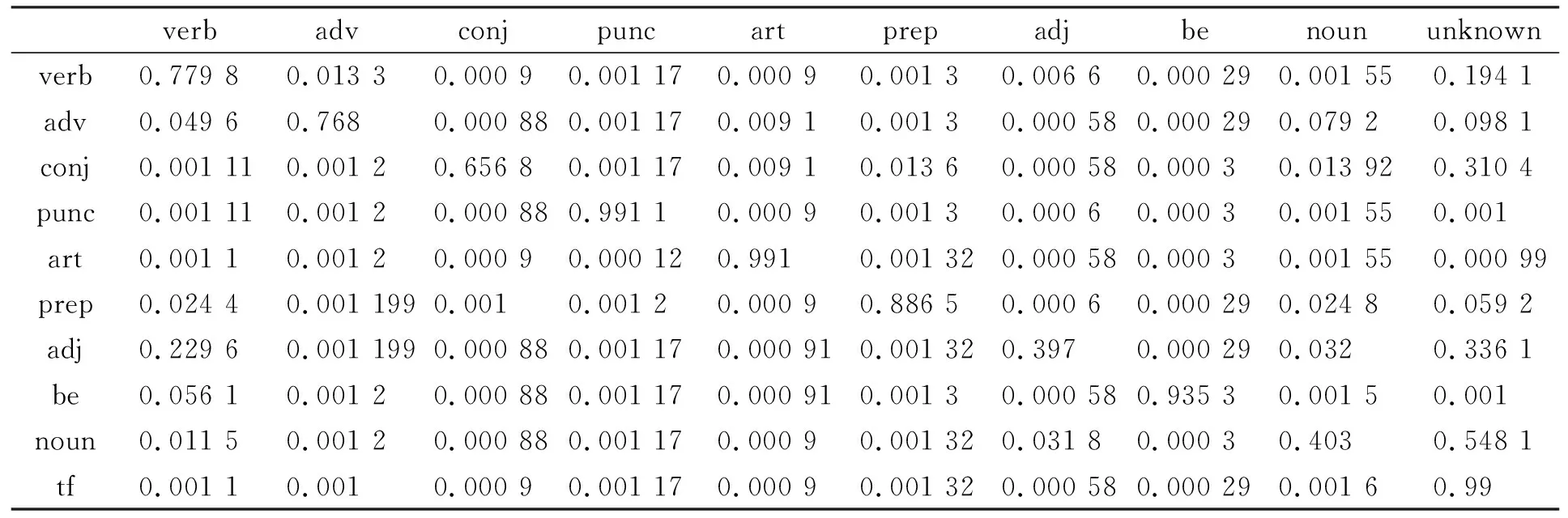
表3 观察值概率矩阵Table 3 Observation likelihood matrix
为了测试HMM-TFM算法的准确性, 本文在Pubmed上以“transcription factor”为关键词选择150篇文献作为实验样本, 通过人工阅读标记出190个转录因子名称. HMM-TFM算法共找到181个表示转录因子的单词, 其中有141个与人工标记结果一致. 实验结果表明, HMM-TFM的查全率和查准率分别为74.2%和77.9%. 与文献[4-5]中算法性能接近, 但不需要使用转录因子名称词库, 通过HMM标记单词词性减少了工作量, 更简单易行.
[1] ZHOU De-yu, HE Yu-lan, Kwoh C K. Semi-supervised Learning of the Hidden Vector State Model for Extracting Protein-Protein Interactions [J]. Artificial Intelligence in Medicine, 2007, 41(3): 209-222.
[2] LIU Jie-bin, SONG Mao-qiang, ZHAO Fang, et al. Second-Order Hidden Markov Model Based on Context [J]. Computer Engineering, 2010, 36(10): 231-233.
[3] ZOU Ling-yun, WANG Zheng-zhi, WANG Yong-xian, et al. Combined Prediction of Transmembrane Topology and Signal Peptide of Beta-Barrel Proteins: Using a Hidden Markov Model and Genetic Algorithms [J]. Computers in Biology and Medicine, 2010, 40(7): 621-628.
[4] Fundel K, Guttler D, Zimmer R, et al. A Simple Approach for Protein Name Identification: Prospects and Limits [J]. BMC Bioinformatics, 2005, 6(Suppl 1): 1-15.
[5] Yang Q, Zheng G Y, Xiong Y, et al. Qnet-BSTM: An Algorithm for Mining Transcription Factor Binding Site from Literature [J]. Journal of Computer Research and Development, 2008, 45(Suppl 1): 323-329.
猜你喜欢
疯狂英语·初中天地(2022年1期)2022-07-07 08:38:30
疯狂英语·初中天地(2020年9期)2020-10-28 08:39:06
高中生·天天向上(2016年10期)2016-11-23 09:02:08
现代语文(2016年21期)2016-05-25 13:13:35
数学理论与应用(2016年3期)2016-05-17 04:50:14
意林(绘英语)(2016年5期)2016-04-09 10:55:20
辽金历史与考古(2016年0期)2016-02-02 01:34:10
核科学与工程(2015年3期)2015-09-26 11:58:25
电子与信息学报(2015年2期)2015-07-18 12:04:47
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:33
