
北京地铁换乘站客流预测模型研究
2012-11-28 03:00:16曾加贝
铁道运输与经济 2012年5期
冷 彪,曾加贝
(1.北京航空航天大学 计算机学院,北京 100191;2.北京航空航天大学深圳研究院,广东 深圳 518057)
2011年,北京市地铁路网日均客运量为 598万人次,占全市公交运输的 35%。预计到 2015年日均客运量将增至 1 000万人次。因此,分析、预测和掌握北京地铁客流实时数据,为线路和车站的客流组织与优化提供数据支撑,提高地铁规划、设计和建设的科学决策水平,提高运营管理决策的实时性和高效性,进而提高北京地铁的运营服务水平和运营效率具有重要意义。
1 客流预测模型
目前,北京地铁采用全网一票通和一卡通无障碍换乘机制,自动售检票系统仅能获取乘客的 OD(Origin-destination) 数据,即进出站数据,无法获取乘客的换乘信息。由于相同进站和出站之间有多种出行线路,仅根据乘客的 OD 数据无法确定其具体出行方案,因此必须采用北京市轨道交通清分管理中心清分方法[1]才能详细分析北京轨道交通路网中的详细客流数据,包括换乘站的换乘客流和车站的站内客流等。由于大部分客流预测方法不具备北京地铁票卡清分的特点,而只能利用乘客的 OD 数据对车站的进站和出站客流量进行预测,此类算法称做面向车站的客流预测模型。这类预测模型主要包括基于线性系统理论的预测方法、基于非线性系统理论的预测方法和基于组合模型的预测方法。其中,基于线性系统理论的预测方法计算较简单,但对于较复杂的交通系统,其预测效果不甚理想。基于非线性系统理论的预测方法体现了交通系统的非线性特点,准确性相对较高,但计算复杂度高,理论基础尚不成熟。面向路网的客流预测模型因具备地铁票卡清分的特点,利用实时 OD 数据不仅能对车站的出站客流进行预测,而且还能对换乘车站的换乘客流和站内客流进行预测。
1.1 面向车站的客流预测方法
主要有3种面向车站的客流预测方法:历史平均预测法、基于最小二乘支持向量机时间序列预测法和分峰段混合预测法。这3类方法仅能利用 OD数据对车站进站客流和出站客流进行预测。
1.1.1 历史平均预测法
历史平均预测法属于基于线性系统理论的预测方法,其主要是利用历史 OD 数据计算平均值,计算的复杂度较低。
设时间序列为{Xt}={Xt-p,Xt-p+1,…,Xt-1},其观测序列为{xt}={xt-p,xt-p+1,…,xt-1},并且 p=mn,其中:p 表示历史时间序列里共有 p个点,周期为 n,历史时间序列中共有 m个周期。则 xi的预测值 yt为:
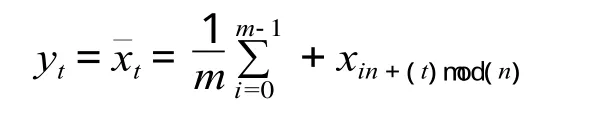
1.1.2 基于最小二乘支持向量机时间序列预测法
基于最小二乘支持向量机时间序列预测法属于基于非线性系统理论的预测方法,其通过训练学习历史 OD 数据,调整模型中的核心参数,但计算复杂度较高。
非线性自回归模型为:
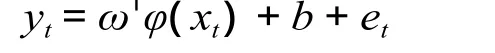
式中:ytÎR;xtÎRn是回归向量[yt-1,yt-2,…,yt-p];贝叶斯项 bÎR;ωÎRnh是未知高维系数向量。函数映射φ:Rn→Rnh将原始的输入向量 xt映射成一个高维向量 φ(xt)ÎRnh。
约束优化问题使用的成本函数[2]为:

式中:γ 为规范化常数。约束优化问题可应用拉格朗日算子计算,最终解可表述为:
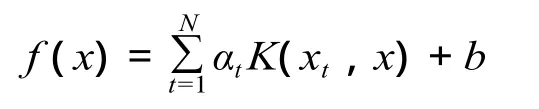
最小二乘法支持向量机[2]的训练过程,主要包括选择核参数、规范化常数 γ 和回归量。在研究中用 10 倍交叉验证核参数和规范化常数。回归量的选择需大量样本信息,在交叉验证的基础上,用贪心算法剔除无用的延迟信息。在每次贪心算法的剔除信息阶段,如果回归的交叉验证均方误差增加,则剔除该回归量。
1.1.3 分峰段混合预测法
分峰段混合预测法主要根据地铁客流出行峰段的特点,将历史平均预测法和基于最小二乘支持向量机时间序列预测法相结合,属于组合模型预测方法。通过对历史OD数据进行分析,历史平均预测法在客流量较小时准确度较高,而最小二乘支持向量机方法对客流量大时具有较高的准确度。因此,可以根据北京地铁客流出行峰段将两种方法结合进行混合预测。设某项客流信息历史 t 天的时间序列为:

其中,每天有 n 项,即周期为 n。则第 t+1天的全天预测值为{ ytn+p},p=1,2,…,n。
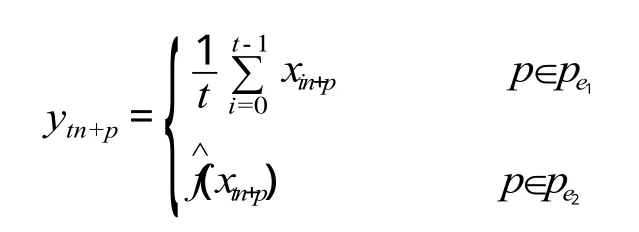
式中:Pe1为早低峰和晚低峰;Pe2为早高峰、平峰和晚高峰为最小二乘支持向量机的预测函数。
1.2 面向全路网的客流预测模型
基于概率树全路网预测方法的核心是以北京地铁票卡清分方法为基础,根据乘客 OD 数据中进站位置和时间信息,预测其出站位置和时间。全路网的客流预测模型利用古典概率方法,统计分析学习历史 OD 数据的进出站位置特点,为指定时间段每一车站建立出站概率树,用于预测查询。下面介绍概率树的生成方法及预测出站位置的查询方法,详细内容参考文献[3]。
1.2.1 概率树
概率树的每个节点 n 都有一个属性值,可称之为节点概率 pn,即节点 n 以概率 pn被选中。二叉树中的每个非叶节点 n 含有一个属性,为分叉概率qn,qn决定下一步是查询节点 n 的左子树还是右子树。叶节点指向一个位置站,并且没有分叉概率。
对于一个给定的位置站 sO,乘客从sO进站,可能的出站位置为集合 SD:

抵达每个出站位置的概率集合为 PD:

生成概率树的原则是被选择的概率越大,则该出站位置所在的深度越小。
1.2.2 预测算法
已知概率树T(t,sO),可预测出站位置SD。出站时间则需要根据进站位置、进站时间、出站位置及选择的有效路径 path0,模拟乘客进站、等车、上车、下车、换乘、出站等,从而算出其出站时间,可描述为tD=M (sO,tO,sD,path0)。
2 实验分析
2.1 实验数据和评判标准
以 2009年11月25日—2010年1月20日的9个星期三的北京地铁历史客流 OD 数据和票卡清分数据为基础,利用历史平均预测法、基于最小二乘支持向量机时间序列预测法、分峰段混合预测法,以及基于概率树全路网预测模型等方法对西单和国贸两个典型车站在 2010年1月27日的进站客流、出站客流、换乘客流和站内客流进行预测。
采用国际通用的预测评判标准相对平均误差(RME) 和均方误差 (MSE) 对预测结果进行分析:
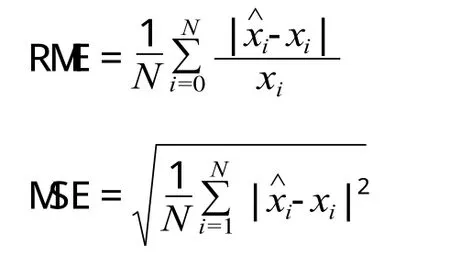
式中:xi为实际值;ˆix为预测值;N 为预测时间点个数。
2.2 进站客流与出站客流预测
首先,利用4种预测方法对西单和国贸站进站客流和出站客流进行预测。对整体预测结果的分析如表1所示,表2详细描述了多种预测方法对国贸站 8:00—9:00 早高峰出站客流的预测结果。实验结果表明,在面向车站的客流预测模型中,分峰段混合预测法能较好地根据历史OD 数据对车站的进出站客流进行预测,并优于面向全路网的客流预测方法。
2.3 换乘客流预测
由于面向车站的客流预测模型无法利用 OD 客流数据对换乘车站的换乘客流进行预测,故仅利用面向全路网的客流预测模型对西单和国贸站的换乘客流进行客流预测,其整体预测结果如表3所示,表4描述了平峰时段对西单站换乘客流的预测结果。实验结果表明,由于早高峰、平峰和晚高峰3个时间段的换乘客流比较集中,此3个峰段的预测结果优于其他峰段。
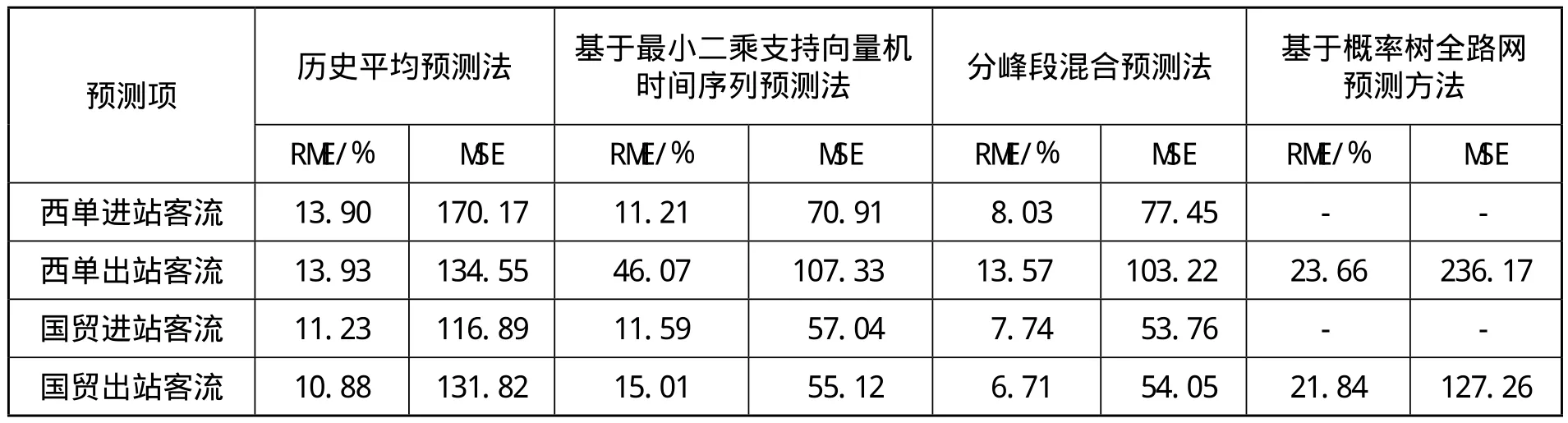
表1 西单和国贸站进站和出站客流预测结果
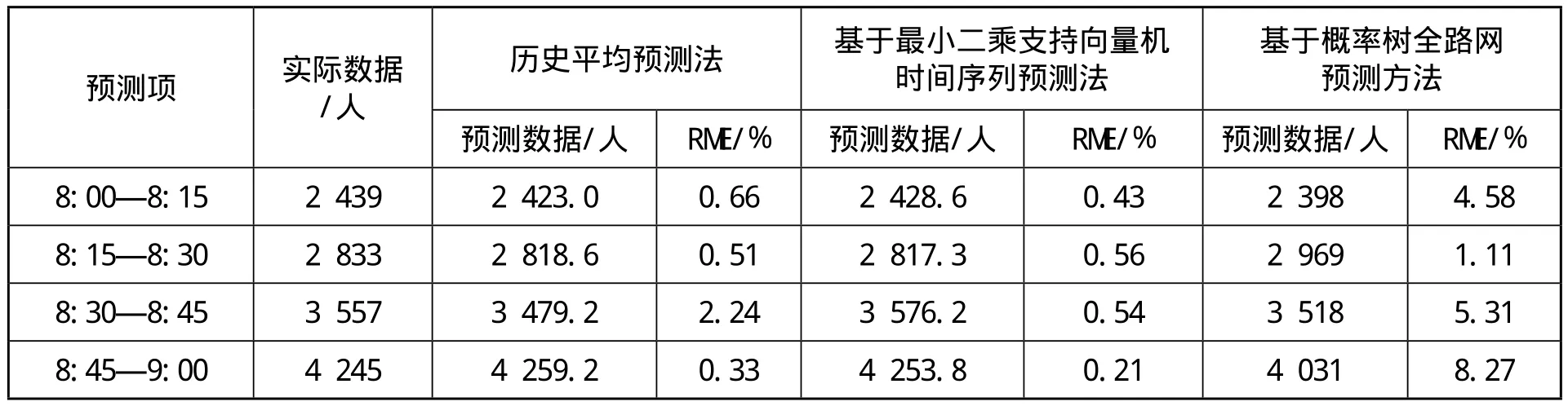
表2 国贸站早高峰出站客流的预测结果
2.4 车站客流预测应用
利用基于概率树全路网预测方法对西单和国贸站的站内客流量进行预测,由于国贸站的客流量比西单站大,因此该方法对国贸站的站内客流量的预测结果比西单站精准,RME 为12.66%,如图1所示,西单站的预测结果 RME 为 25.81%。
3 结束语
通过对西单和国贸站客流预测结果的研究,可以看出针对车站的进出站客流预测,分峰段混合预测法具有较好的预测结果。针对车站的换乘客流和站内客流,面向车站的预测模型因不具备北京地铁票卡清分的特点,故无法进行相关的客流预测,而只有面向全路网的预测模型能解决相应的客流预测问题,且基于概率树全路网预测方法能利用实时OD 数据进行准确的换乘客流和站内客流预测。由此可见,分峰段混合预测法和基于概率树全路网预测方法能根据北京地铁的特点,对车站内各种客流量进行预测,针对性强。

表3 基于概率树全路网预测方法的西单和国贸站换乘客流预测结果 %

表4 基于概率树全路网预测方法的西单站平峰换乘客流预测结果
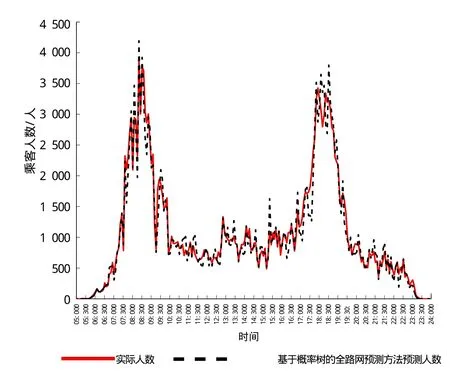
图1 基于概率树全路网预测方法国贸站的站内客流预测曲线图
[1]北京市轨道交通指挥中心. 北京市轨道交通清分管理中心清分方法研究[R]. 北京:北京市轨道交通指挥中心,2007.
[2]M. Espinoza,T. Falck,Johan A. K. Suykens,et al. Time Series Prediction Using LS-SVMs [C]// Proceedings of the European Symposium on Time Series Prediction. Espoo:Multiprint Oy/ Otamedia, 2008:187-196.
[3]曾加贝. 轨道交通客流预测与疏散建模研究[D]. 北京:北京航空航天大学,2011.
猜你喜欢
现代装饰(2021年4期)2021-11-02 07:07:46
铁道通信信号(2019年9期)2019-11-25 01:44:50
祖国(2018年6期)2018-06-27 10:27:26
阅读(科学探秘)(2018年8期)2018-05-14 10:06:29
现代城市轨道交通(2018年1期)2018-01-25 23:33:48
现代装饰(2017年11期)2017-05-25 02:14:46
中华皮肤科杂志(2014年3期)2014-12-19 12:54:58
中华皮肤科杂志(2014年3期)2014-12-19 12:54:46
铁路通信信号工程技术(2014年6期)2014-02-28 16:58:34
都市快轨交通(2014年4期)2014-02-27 08:35:07
