
C4.5决策树法在高校奖学金评定中的应用
2012-11-22 01:46:52马伟杰
河南工程学院学报(自然科学版) 2012年2期
马伟杰
(郑州航空工业管理学院 计算机科学与应用系,河南 郑州 450015)
高校奖学金评定是一项每年必须重复的繁琐而又重要的工作,涉及范围很广,它要根据不同情况评定出不同的奖学金获得者,需要记录和处理的数据量也很庞大.如何对奖学金获得者做出科学、有效的评价已成为高校学生管理者关注的焦点问题之一[1].
决策树是判断给定样本与某种属性相关联的决策过程的一种表示方法,该方法广泛应用于数据挖掘和机器学习等领域,用来解决与分类相关的问题[2],是应用最广泛的逻辑方法.目前,生成决策树方法的算法主要有3种:CART算法、ID3算法和C4.5算法,其中C4.5算法具有分类速度快且精度高的特点,是发展得比较完善的一种决策树算法[3].
1 C4. 5决策树算法
C4.5算法是构造决策树分类器的一种有效算法,最终可以形成产生式规则.C4.5算法的输入是一张关系表,由若干不同的属性及若干数据元组(称为训练样本)组成.属性分为两部分,一部分作为判定对象属性(判定树中的非叶节点),另一部分作为分类对象属性(判定树中的叶节点).C4.5算法采用信息熵的方法,比较各个判定对象属性的信息增益率的大小,选择信息增益率最大的属性进行分类,递归生成一个判定树[4-5].
设|S|为训练集S的样本总数,一共有m类样本Ci(i=1,2,3,…,m),|Ci|为类Ci中的样本数,设Pi=|Ci|/|S|是任意样本属于Ci的概率,训练样本分类属性的总信息熵E(S1,S2,…,Sm)的计算公式为:
(1)
设属性A具有v个不同值{a1,a2,…,av},可以用属性A将S划分为v个子集{S1,S2,…,Sv},其中Sj包含S中这样一些样本,它们在A上具有值aj(j=1,2,…,v).设|Sij|为Si类中Cj的样本数,以属性A为分类所需的期望熵E(A)的计算公式为:
(2)
属性A相对于类别集合C的信息增益Gain(C,A)的计算公式为:
Gain(C,A)=E(S1,S2,…,Sm)-E(A).
(3)
属性A相对于类别集合C的信息增益率GainRatio(C,A)的计算公式为:
GainRatio(C,A)=Gain(C,A)/E(S1,S2,…,Sm).
(4)
C4.5算法是一个循环、递归的过程,核心部分的描述如下:
/*参数:R表示判定对象属性,C表示目标属性,S表示训练集*/
DecisionTree C45(R,C,S)
{
if(S为空) return NULL;
if(S包含目标属性的值都相同) return 具有该值的结点;
if(R为空) return 具有S中出现最频繁的目标属性值的结点;
获取R中最大增益Gain(D,S)的属性D;
{d[j]|j=1,2,…,m}为属性D的取值;
{s[j]|j=1,2,…,m}为与S相对应的包含属性D相应取值d[j]的训练集;
Return(以D为根,D射出的弧为d[1],d[2],…,d[m]的决策树);
/*递归得到包含属性D相应取值d[j]的各个子决策树*/
for(i-1;i<=m;i++)C45(R-D,C,S[i]);
}
2 C4. 5算法在高校奖学金评定中的应用
2.1 问题定义与数据预处理
奖学金的评定,一方面要根据学生各个科目的学习成绩,另一方面还要结合每位学生的具体表现和实际情况,包括学生的德育、体育及某方面的突出表现等.根据学生各个科目的学习成绩的平均绩点、德育成绩(把某方面的突出表现转换为德育成绩)以及体育成绩,建立C4.5决策树的分类预测模型,对奖学金等级进行评价,其实质是运用C4.5算法进行数据挖掘,获得分类规律,即成绩与奖学金等级之间的关系,推导出分类规则,即奖学金等级智能评价模型.
以计算机系2009级216名学生2010—2011学年的成绩为例建立数据表,包括字段学号、平均绩点、体育成绩、德育成绩和奖学金等级.通过数据清洗、数据转换、数据集成及数据规约等技术,去掉数据集中的噪声和不相关信息,将数据源的数据类型与值转换成统一的格式.对奖学金等级的属性作处理:①全年级前10%的学生获得一等奖学金;②排名在11%~20%的学生获得二等奖学金;③排名在21%~40%的学生获得三等奖学金;④剩下的学生不能获得奖学金,奖学金等级为无.
定义德育成绩:根据系部情况,将德育成绩转换为A,B,C三等,其中A表示排名在全年级的前40%,B表示排名在41%~70%,剩余学生的德育成绩为C.
定义体育成绩:根据系部情况,将体育成绩划分为合格与不合格两类.
数据预处理完成后得到转换后的学生成绩信息表,见表1.由于记录太多,表1仅显示部分记录[6].
随机抽取预处理后2/3的数据即144个数据样本作为C4.5算法的训练集,剩下1/3的数据即72个数据样本作为测试集.
2.2 构造决策树
数据预处理后,开始归纳决策树,此过程使用数据预处理得到的训练集.根据前述的C4.5算法,将属性平均绩点、体育成绩与德育成绩作为算法的对象属性, 将属性奖学金等级作为目标属性,利用信息增益率的定义将属性进行排列,具有最高信息增益率的属性选作给定集合的测试属性.创建一个根结点,以该属性标记对属性的每个值创建分枝,然后递归建树,可构造一棵决策树,算法具体处理过程如下[7]:
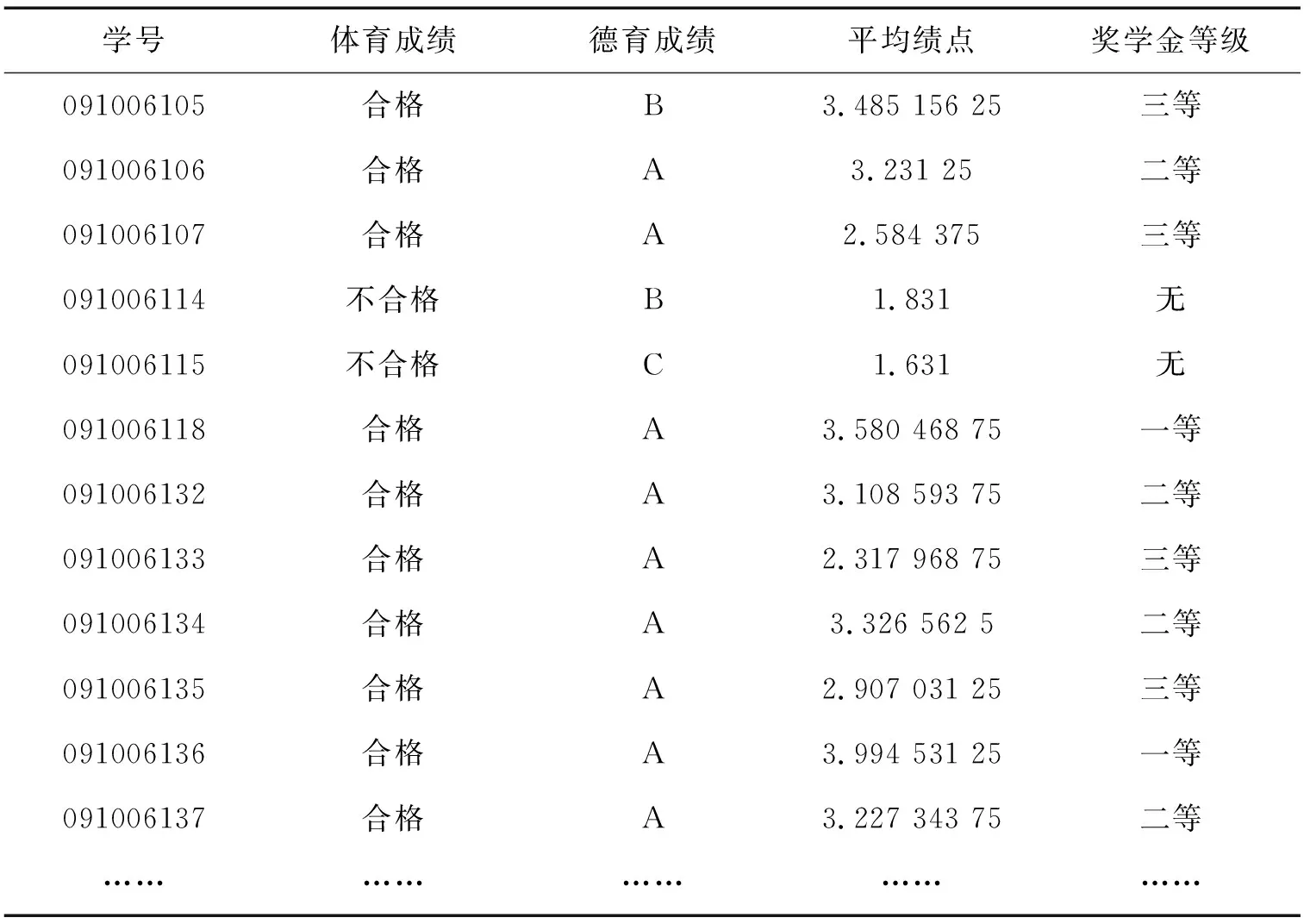
表1 数据转换后的学生成绩信息特征集(部分)Tab.1 The information feature set of students achievement after data transformed(partly)
训练样本数据集S中共有144个元组,其中奖学金等级属性(属性值为一等、二等、三等和无)的每个属性值所对应的子集中元组个数分别为S1=6,S2=10,S3=20,S4= 108.为了计算每一个决策属性的信息增益,首先利用公式计算集合S分类的总信息熵:
然后计算每一个决策属性的期望信息熵.
对属性体育成绩,当体育成绩=“合格”时:
当体育成绩=“不合格”时:
由此,得出体育成绩的熵值为:
因此,体育成绩的信息增益为:
Gain(TY)=E(S1,S2,S3,S4)-E(TY)=0.063.
属性体育成绩的信息增益率为:
GainRatio(TY)=Gain(TY)/E(S1,S2,S3,S4)=0.055.
同理,得到属性德育成绩和平均绩点的信息增益律分别为:
GainRatio(DY)=0.051,GainRatio(PJ)=0.039.
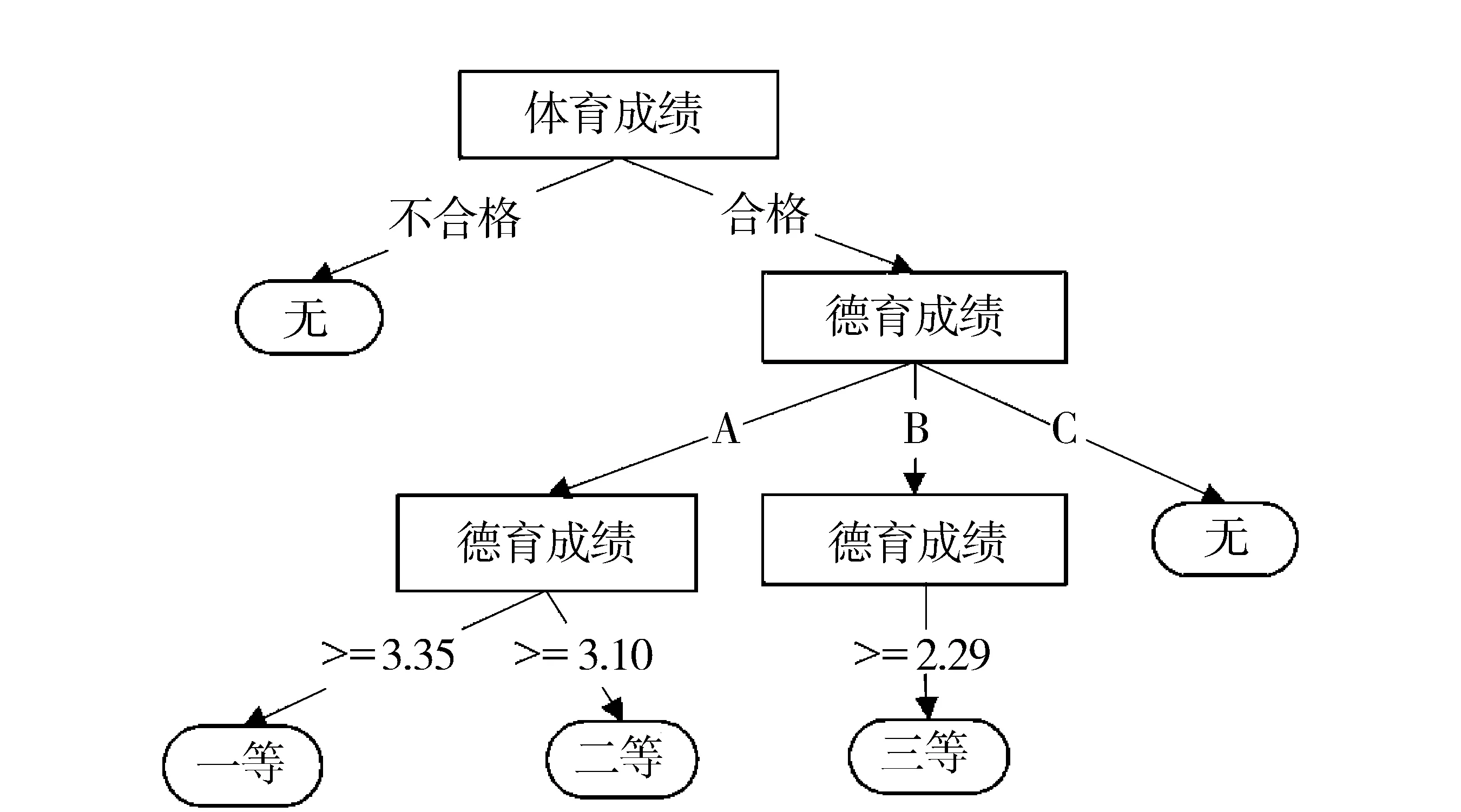
图1 C4.5算法构造奖学金评定决策树Fig.1 C4.5 algorithm structured scholarship assessment decision tree
由于属性体育成绩具有最大的信息增益率值,故选择该属性作为决策树的根节点.对于每一个分支,重复上述步骤生成决策树,如图1所示.因篇幅有限,只画出第一层次单位的决策树.
2.3 分类规则提取
从决策树中提取一等、二等、三等类的规则,分类规则如下:
(1)if体育成绩=“合格” and 德育成绩=“A” and 平均绩点>=3.35 then 一等奖学金;
(2)if体育成绩=“合格” and 德育成绩=“A” and平均绩点>=3.10 then 二等奖学金;
(3)if体育成绩=“合格” and 德育成绩=“B” and平均绩点>=2.29 then 三等奖学金.
由以上规则可以看出,学生要想获得奖学金,必须要按时参加体育锻炼,同时要积极地参加学校的活动以提高自己的德育分,还要努力学习提高自己的专业课成绩[8].
3 结束语
在目前以手工方式进行奖学金评定的低效率的情况下,提出了关于奖学金评定的数据挖掘模型,引入了数据挖掘理论中的决策树算法,对高校奖学金评定系统中的数据进行了分析.实验表明,此数据挖掘算法构造简单,能正确分类,处理速度较快.
参考文献:
[1] 顾晓春.高校奖学金评定系统的设计研究[D].大连:大连理工大学,2008.
[2] 吴陈,林炎钟.C4.5算法在高校教师评价中的应用研究[J].信息技术,2010(1):17-19.
[3] 云玉屏,林克正.C4.5算法在冠状造影数据处理中的应用[J].计算机工程与应用,2008,44(10):25-27.
[4] 宋晖,张良均.C4.5决策树法在空气质量评价中的应用[J].科学技术与工程,2011(7):16-18.
[5] 邹竞,谢鲲.C4.5 算法在移动通信行业客户流失分析中的应用[J].计算机技术与自动化,2009(9):33-35.
[6] David B.Style System Overview[DB/OL].http: / /www.mozilla.org /newlayout /doc /style- techtalk.html, 2002-06.
[7] 邵兴江.数据挖掘在教育信息化中的应用空间分析[EB/OL] .http:// www. Zjedu.org/ xdjyjs/ 107/64781thm,2008-01-08.
[8] 李楠,段隆振,陈萌.决策树C4.5算法在数据挖掘中的分析及其应用[J].计算机与现代化,2008(12):160-163.
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:36
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
电子制作(2019年19期)2019-11-23 08:41:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
英语文摘(2019年5期)2019-07-13 05:50:30
电子制作(2018年19期)2018-11-14 02:37:02
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
大学生(2016年7期)2016-04-29 20:30:06
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
