
基于多元Laplace语音模型的语音增强算法
2012-07-25 04:08张雄伟
电子与信息学报 2012年7期
周 彬 邹 霞 张雄伟
(解放军理工大学指挥自动化学院 南京 210007)
1 引言
语音增强是现代语音信号处理中的关键技术。实际环境中的语音不可避免地受到各种噪声源的干扰,语音增强的目的就是尽可能地消除噪声的影响,从带噪语音中提取出纯净的原始语音。目前,各种语音增强算法已广泛应用于语音通信、语音编码和语音识别等诸多领域。其中,基于短时谱估计的语音增强算法具有较好的噪声抑制效果,且复杂度低易于实现,因而得到了广泛关注和研究。
在短时谱估计语音增强算法中,首先要对语音和噪声信号的先验分布进行合理假设。经典的算法如最小均方误差短时谱幅度估计(MMSE-STSA)[1]假设语音信号的短时谱服从高斯分布,且不同谱分量之间相互独立。近几年的研究表明,超高斯分布更符合语音信号的实际分布[2]。因此,文献[3-7]提出基于超高斯分布的语音短时谱估计算法,包括基于Laplace分布模型的 MMSE短时谱估计,基于Gamma分布模型的 MMSE短时谱估计,基于Laplace分布模型的最大后验概率(MAP)短时谱估计等。文献[8]进一步将上述Gauss, Laplace, Gamma等分布模型进行一般化推广,提出语音信号的广义Gamma分布模型。文献[8,9]据此提出基于广义Gamma分布的语音信号MMSE估计。
上述改进算法虽取得了一定的效果,但仍然采用传统的语音谱分量独立性假设。实际上,由于分帧、加窗等影响,以及语音信号内在的谐波结构,语音的短时谱分量之间存在相关性[10]。因此,这一独立性假设是不准确的。针对这一问题,文献[10]提出分块的线性最小均方误差估计方法,主要通过语音信号的协方差矩阵描述浊音谐波结构的谱相关性,以此改进短时谱估计,取得了一定的效果。但该方法的增益因子估计仍基于传统的 Wiener滤波法,没有更好地利用语音的先验分布信息。文献[11,12]提出多维贝叶斯短时幅度谱估计方法,对具有相关性的谱分量进行联合最优估计,从而改进语音增强性能,但该方法仍采用传统的Gauss分布假设,且作者没有给出MMSE估计的解析解。
针对上述问题,本文提出采用多元Laplace分布对语音信号进行建模,以此利用语音短时谱分量间的相关性。考虑离散余弦变换(DCT)相对于离散傅里叶变换(DFT)具有更好的能量压缩特性,且不存在相位失真问题,本文将语音信号变换到DCT域进行处理。在假设语音信号的 DCT系数服从多元Laplace分布的基础上,推导了语音短时谱的MMSE估计和语音存在概率。与传统的语音增强算法相比,本文提出的算法能够利用语音谱分量之间的相关性,更有效地抑制背景噪声,减少语音失真,从而取得更好的语音增强效果。
本文第 2节描述了基于语音先验分布模型的短时谱估计语音增强算法的基本框架。第 3节介绍了多元Laplace分布模型,推导了最小均方误差准则下基于多元Laplace分布模型的语音短时谱估计,以及语音存在概率修正因子。第 4节给出实验结果和分析。第5节进行总结。
2 基于语音分布模型的短时谱估计方法
设s(n)和d(n)分别表示纯净语音信号和加性高斯白噪声,带噪语音信号y(n) =s(n) +d(n)。其中,s(n)和d(n)相互独立。经过分帧、加窗和DCT变换后,得到
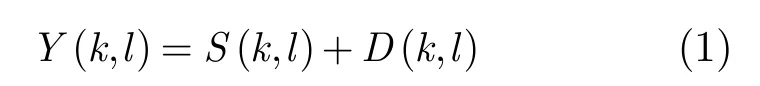
其中Y(k,l),S(k,l),D(k,l)分别表示带噪语音、纯净语音和噪声的DCT变换系数,k表示频带序号,l表示时间帧序号。为简化表示,下文中将序号k和l省略。
语音增强的目的就是从带噪语音谱Y中恢复得到尽可能纯净的语音信号谱。假设纯净语音和噪声的DCT变换系数相互独立,且其概率密度函数分别为pS(S)和pD(D),则根据贝叶斯估计原理,在已知带噪语音信号Y的条件下,纯净语音信号的MMSE估计为
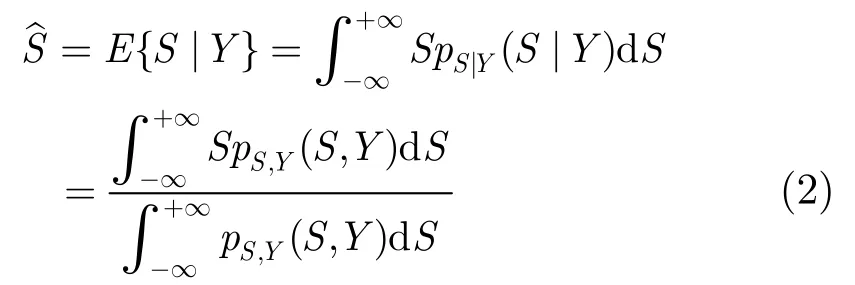
以式(2)为基础,在不同的先验分布假设条件下,可以得到不同的估计器。例如,假设语音信号服从方差为的零均值高斯分布:
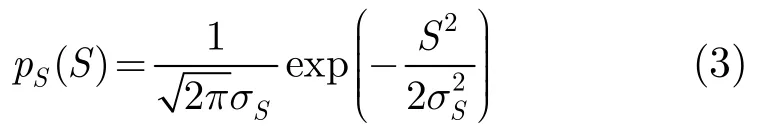
并假设噪声服从方差为的零均值高斯分布:
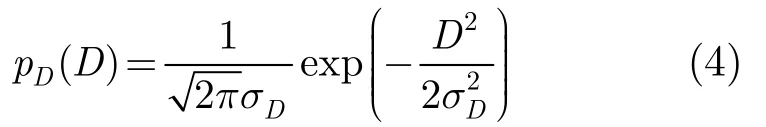
则语音的MMSE估计为

研究表明,超高斯分布更符合语音信号在变换域的统计特性,据此,文献[3]假设语音信号服从Laplace分布,即
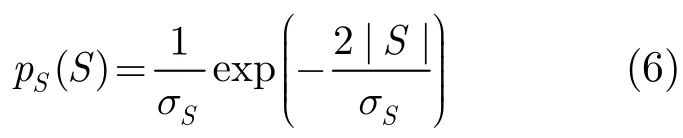
而噪声仍服从零均值高斯分布,推导得到语音信号的MMSE估计为
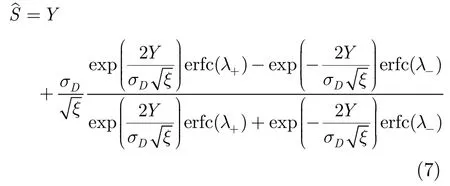
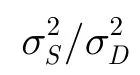
3 基于多元Laplace分布的短时谱估计
由于实际的语音谱分量间存在着相关性,而传统的一元分布模型假设谱分量相互独立,难以较好地描述语音信号的先验分布。为了克服这一问题,本文提出采用多元 Laplace分布对语音信号先验分布进行建模,并据此推导语音短时谱的MMSE估计。
3.1 多元Laplace分布
对于服从d元球形轮廓 Laplace分布的随机矢量S,其联合概率密度函数为
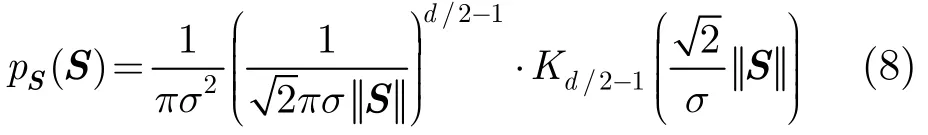
其中Kl(u)为修正的第2类贝塞尔函数,其表达式为
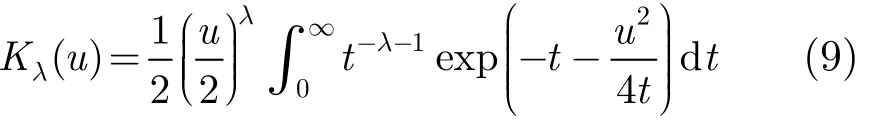
为便于推导计算,实际中通常采用S的高斯尺度模型表示[13],即,
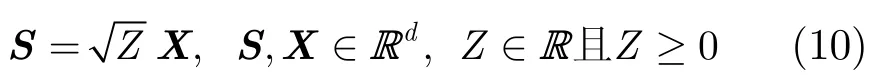
其中,随机矢量X服从均值为零,协方差矩阵为s2Id的d元高斯分布,其概率密度函数为

Z与X相互独立,且Z服从指数分布,其概率密度函数为
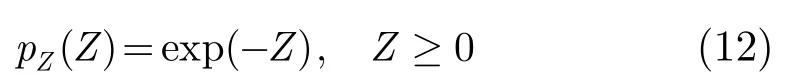
设a=,则S=aX,通过变量代换得到d元Laplace概率密度函数的高斯尺度混合表示为
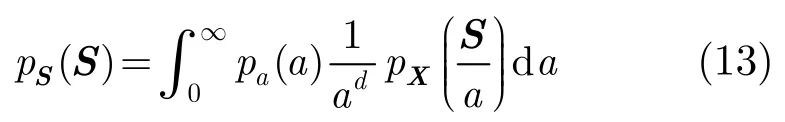
其中pa(a) = 2apZ(a2)为a的概率密度函数。
图1给出了s=1时的二元Laplace概率密度函数图。S中的每个元素Si(1 ≤i≤d)均服从方差为s2的一元零均值Laplace边缘分布,相对于Gauss分布其峭度更大,具有重拖尾、尖峰特性,因而更加符合实际的语音先验分布[3],且能够表示不同分量间的相关性。
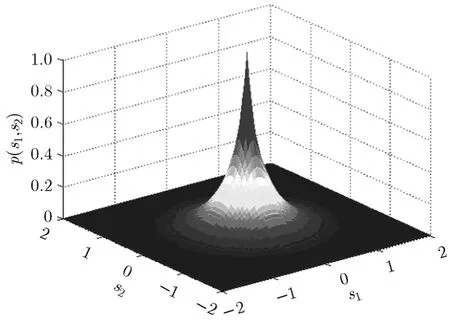
图1 多元Laplace概率密度函数图(s=1,d=2)
3.2 基于多元Laplace语音分布的MMSE估计
假设语音的DCT系数矢量S服从d元球形轮廓Laplace分布:
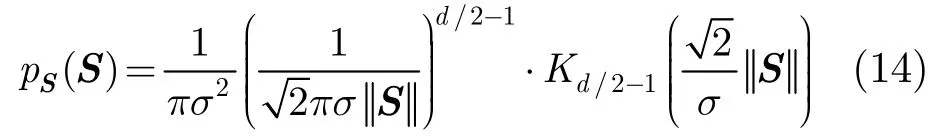
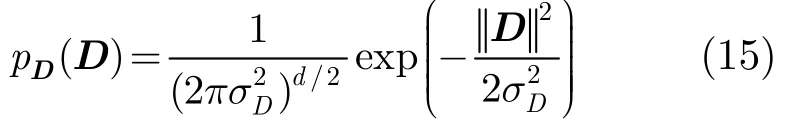
假设S和D相互独立,则带噪信号Y=S+D的概率密度函数可以通过多元卷积求得[14]
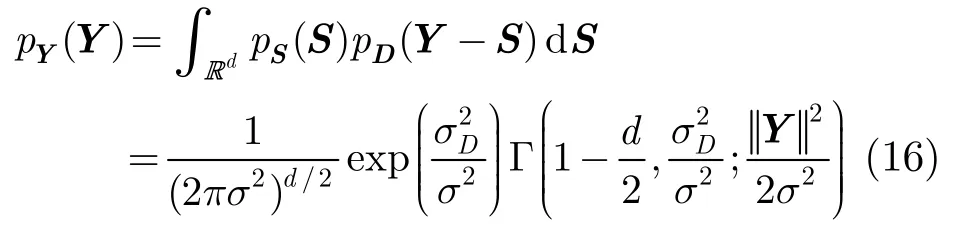
其中 Γ (a,x;b)为广义不完全Gamma函数,其表达式为
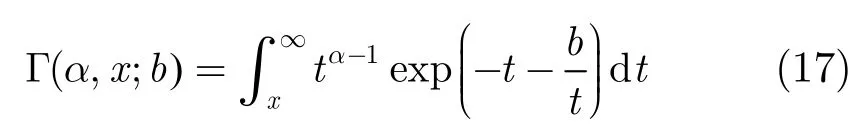
则语音信号DCT系数的MMSE估计可通过式(18)得到
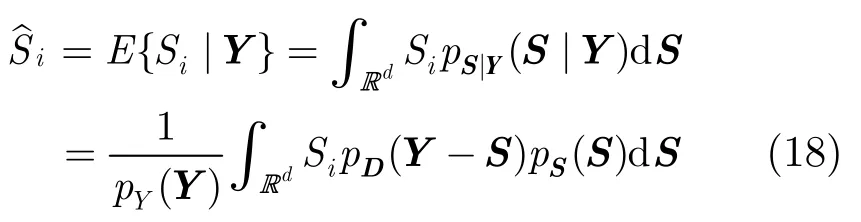
其中Si(1 ≤i≤d)为d维矢量S中的元素。利用S的高斯尺度混合表示,将式(13),式(15),式(16)代入式(18)并化简后得到
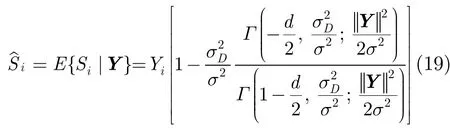
其中Yi( 1 ≤i≤d)为带噪语音矢量Y中的元素。
在式(19)中,当d=1时,得到一元 Laplace分布模型下的MMSE估计,与文献[3]中的推导结果相一致。由此可见,本文得到的 MMSE估计为一元Laplace分布模型算法的多元推广,而文献[3]中的MMSE估计子为一元分布条件假设下的特殊形式。
3.3 基于语音存在概率修正MMSE估计
假设H1表示语音信号存在,H0表示语音信号不存在,则修正后的语音信号MMSE估计可表示为
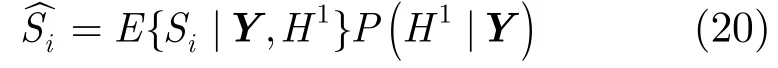
其中E{Si|Y,H1}为假设语音必然存在条件下的MMSE估计,其表达式由式(19)给出;P(H1|Y)表示在给定带噪语音频谱Y的条件下语音信号的存在概率,根据贝叶斯原理,
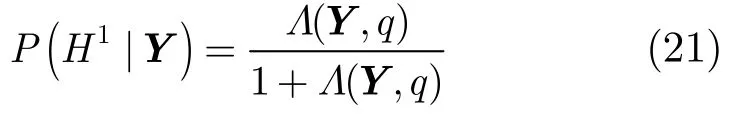
其中L(Y,q)表示广义似然比,其表达式为
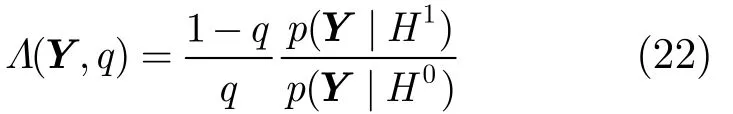
其中p(Y|H1) =pS(Y) ,p(Y|H0) =pD(Y),q为先验语音不存在概率。在多元Laplace语音分布假设和多元Gauss噪声分布假设条件下, 将式(14)和式(15)代入式(22)可得
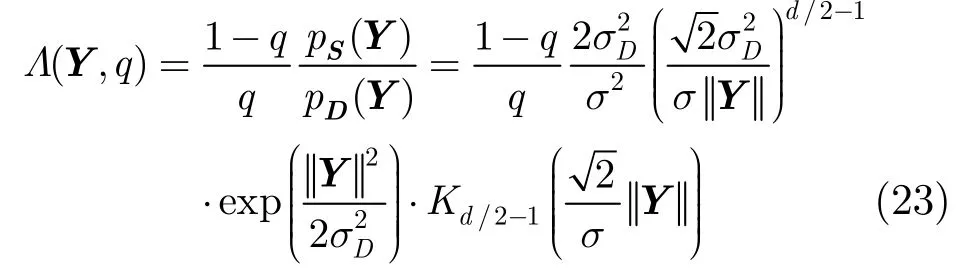
4 实验结果
在实验仿真中,基于Matlab实现本文所提出的语音增强算法,并与其他两种算法进行比较,包括文献[3]中提出的基于一元Laplace分布的MMSE语音增强算法,文献[11]中提出的基于多元Gauss分布的语音增强算法,下文中分别用 UniLap,MultiGauss表示这两种算法。为便于比较,3种算法实现中的噪声参数均采用最小统计量方法估计得到[15]。实验仿真中的参数设置为:帧长L=256,帧移M= 1 28;维数d=16,先验语音不存在概率q= 0 .2;最小统计量搜索窗参数D= 1 20,U=8,V= 1 5。
从标准噪声库 Noisex92 中选取白噪声、M109坦克噪声、F16飞机噪声作为原始噪声,并将采样率转换为8 kHz。干净语音选取采样率为8 kHz的标准汉语语音信号,其中男女声各 6 句,每句时间长度约为8 s。通过MATLAB 对噪声信号和干净语音混和,信噪比分别为-5 dB, 0 dB, 5 dB 和10 dB。
采用信噪比衡量语音增强算法的噪声抑制效果。图2给出了3种算法增强后语音的信噪比比较结果。从图中可以看出,本文算法比基于一元Laplace分布的算法有较大提高,与文献[11]中提出的基于多元Gauss分布的估计算法相比也有一定的提升。
表1给出了3种算法增强后语音的对数频谱距离比较结果。从中可以看出,相对于一元 Laplace模型估计和多元Gauss模型估计算法,本文算法的增强语音具有更小的语音失真,尤其是在低信噪比条件下改进幅度较大。
图3给出了3种算法增强后语音的感知语音质量评估(PESQ)比较结果。从中可以看出,与其他两种算法相比,本文所提算法的输出语音具有更好的语音质量,非正式的主观听觉测试与上述结果相一致。
图4给出了在白噪声条件下、输入信噪比为5 dB时的原始语音、带噪语音、以及 3种算法增强后语音的波形和语谱图。从图中可以看出,本文算法能够有效抑制噪声,恢复语音信号的频谱结构。

图2 3种算法增强后语音的信噪比比较

表1 3种算法增强后语音的对数频谱距离(LSD)比较
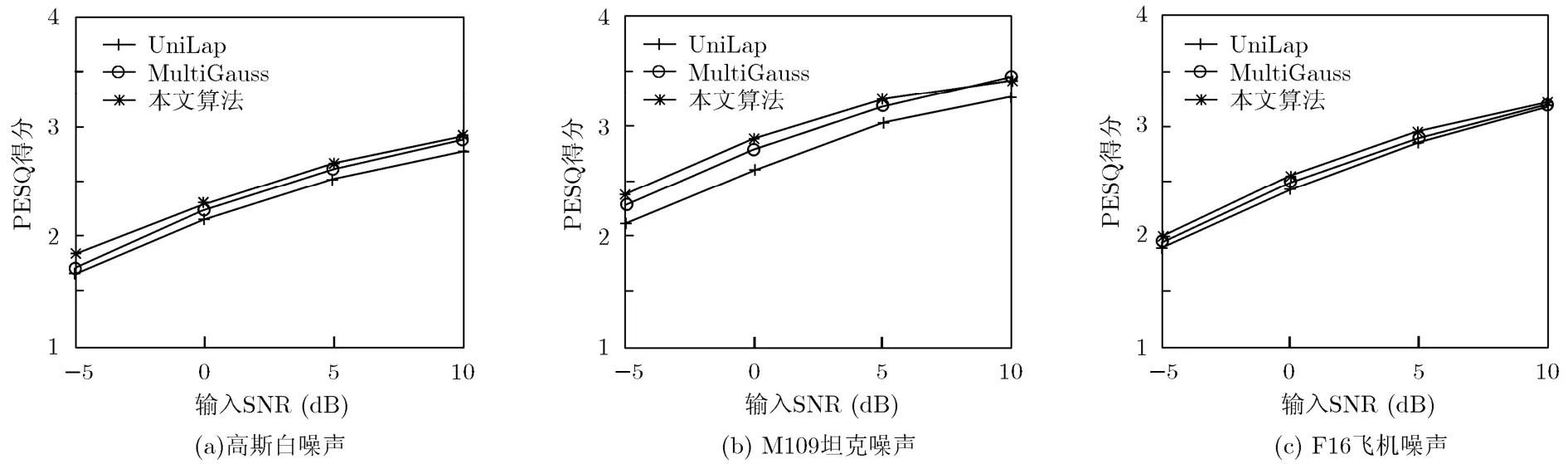
图3 3种算法的PESQ评估结果
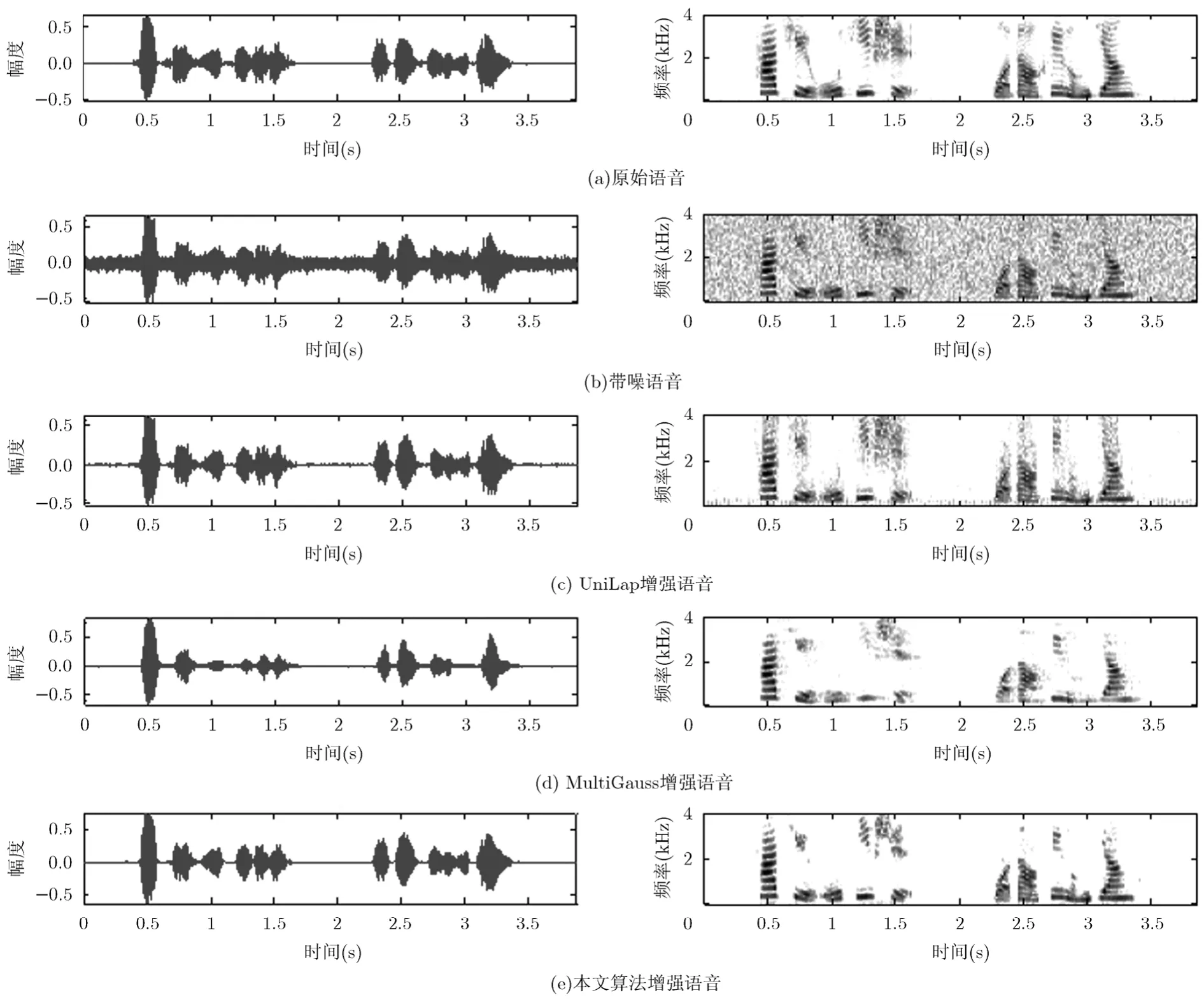
图4 3种算法增强语音信号的波形和语谱图(左:波形图,右:语谱图)
5 结论
本文提出一种基于多元Laplace分布模型的DCT域语音增强算法。采用多元Laplace分布模型对语音信号的 DCT系数进行建模,以此利用语音谱分量间的相关性,在此基础上实现语音信号DCT系数的最小均方误差(MMSE)估计。当该分布模型中的参数d=1时,本文方法退化为传统的基于一元Laplace分布的MMSE估计。因此,本文方法可视为对传统MMSE谱估计方法的一种推广。实验结果表明,与传统的基于一元分布模型的语音增强算法和近几年提出的基于多维贝叶斯估计的语音增强算法相比,本文算法在多种背景噪声条件下能够取得更好的语音增强效果。
[1]Ephraim Y and Malah D. Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator[J].IEEE Transactions on Acoustic,Speech and Signal Processing, 1984, 32(6): 1109-1121.
[2]Gazor S and Zhang W. Speech probability distribution[J].IEEE Signal Processing Letters, 2003, 10(7): 204-207.
[3]Martin R. Speech enhancement based on minimum mean square error estimation and supergaussian priors[J].IEEE Transactions on Speech and Audio Processing, 2005, 13(5):845-856.
[4]Lotter T and Vary P. Speech enhancement by MAP spectral amplitude estimation using a super-gaussian speech model[J].EURASIP Journal on Applied Signal Processing, 2005,2005(7): 1110-1126.
[5]Hendriks C R, Heusdens R, and Jensen J. Log-spectral magnitude MMSE estimators under super-gaussian densities[C]. INTERSPEECH, Brighton, UK, 2009:1319-1322.
[6]Paliwal K, Schwerin B, and Wojcicki K. Single channel speech enhancement using MMSE estimation of short-time modulation magnitude spectrum[C]. INTERSPEECH,Florence, Italy, 2011: 1209-1212.
[7]Esch T and Vary P. Model-based speech enhancement using SNR dependent MMSE estimation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing,Prague, Czech, 2011: 4652-4655.
[8]Erkelens S J, Hendriks C R, Heusdens R,et al.. Minimum mean-square error estimation of discrete fourier coeffcients with generalized Gamma priors[J].IEEE Transactions on Audio,Speech and Language Processing, 2007, 6(15):1741-1752.
[9]Borgstrom J B and Alwan A. Log-spectral amplitude estimation with generalized Gamma distributions for speech enhancement[C].IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech,2011: 4756-4759.
[10]Li C and Andersen V S. A block-based linear MMSE noise reduction with a high temporal resolution modeling of the speech excitation[J].EURASIP Journal on Applied Signal Processing, 2005, 2005(18): 2965-2978.
[11]Plourde E and Champagne B. A family of Bayesian STSA estimators for the enhancement of speech with correlated frequency components[C]. IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, USA, 2010:4766-4769.
[12]Plourde E and Champagne B. Multi-dimensional Bayesian STSA estimators for the enhancement of speech with correlated frequency components[J].IEEE Transactions on Signal Processing, 2011, 59(7): 3013-3024.
[13]Selesnick W I. The estimation of Laplace random vectors in additive white Gaussian noise[J].IEEE Transactions on Signal Processing, 2008, 56(8): 3482-3496.
[14]Plourde E and Champagne B. Bayesian spectral amplitude estimation for speech enhancement with correlated spectral components[C]. IEEE Workshop on Statistical Signal Processing, Cardiff, UK, 2009: 397-400.
[15]Martin R. Noise power spectral density estimation based on optimal smoothing and minimum statistics[J].IEEE Transactions on Speech and Audio Processing, 2001, 9(5):504-512.
猜你喜欢
广西民族大学学报(自然科学版)(2022年1期)2022-05-18
数字通信世界(2021年3期)2021-04-09
湖北理工学院学报(2020年4期)2020-08-22
微型电脑应用(2019年4期)2019-04-26
当代旅游(2018年8期)2018-02-19
数学学习与研究(2018年2期)2018-02-09
计算机应用与软件(2017年4期)2017-04-24
哈尔滨商业大学学报(自然科学版)(2015年4期)2015-03-09
装备环境工程(2015年1期)2015-02-06
现代电子技术(2014年4期)2014-03-05
