
印刷体英文单词识别与朗读在辅助阅读中的应用
2012-07-13 03:06孙国瑞程荣花
电子设计工程 2012年3期
马 飞,申 远,孙国瑞,程荣花
(平顶山学院 软件学院,河南 平顶山 467000)
现代生活节奏的加快要求我们高效的工作效率和低成本的产出,科技的发展使得这一要求得以实现。我们用到很多工具来帮助我们节省时间,手机电脑等工具几乎应有尽有。但是这些技术仍存在一些不完整性和缺陷。比如广告纸上的联系方式、姓名只需拍照识别就能及时获得,即时拨通电话就可以通信。这种方式较之保存图片来说,省去大量的内存空间和拨打电话的时间,是人们期望的方式,也是人工智能的发展趋势。我们都想坐在电脑前把纸张上的内容通过摄像头获取,这就推动了印刷体识别的发展。因为现在印刷体识别仍存在代价高,操作复杂的弊端,而图像若通过摄像头获取则节约了大量的成本,所以基于图像处理的印刷体的单词识别系统就显得十分必要。由于计算机科学和科技的发展诸多的此类产品也露出水面如:汉王双枪笔,智能监控系统,人脸通,指纹识别,车牌识别等产品等都是基于图像来处理的。常见的图像识别技术研究也很广泛,如模板匹配、贝叶斯、Fisher、SVM和神经网络[1-3]等主要算法。
1 获取图像
获取图像是设计识别软件的基础,最常见的获取方式有:在图像输入区进行手动绘制,这有利于样本训练时的样本多样化。导入本地图像到图像输入区,这是最基本的获取图像的方法。通过摄像头拍摄获取图像。
1)摄像头拍摄:通过摄像头拍摄得到图像,将图像导入到图像输入区,或直接把拍摄到的图像设置到输入区。
2)导入本地图像:在项目中添加一个文件对话框,通过打开文件对话框找到目标图像,将其添加到图像输入区。
2 预处理
图像预处理是一个良好的图像识别系统必不可少的环节。本节主要包括全局二值化、3×3中值滤波去噪等操作,以达到改善原图像的目的。
一般的阈值的处理方式如下:设一幅原始图像的像素值p(i,j)的取值范围为[0,m],那么设有其阈值为 T=t,0<t<m,则映射成新的二值图像的像素值 p′(i,j)为:
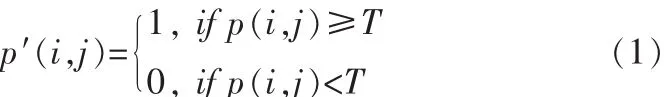
用1表示需要的图像,0表示背景。
在字符图像处理中,二值化处理占有非常重要的地位。这样在图像处理系统中,可以减少图像冗余信息的提取从而提高处理速度。虽然一般的图像处理时会利用所有的图像灰度级,但是本系统处理的图像灰度级不会太多,因为有的字符、指纹、工程图等图像本身就是二值的,而且需要获取的图像信息只是字符像素的信息,所以本系统二值化处理只要得到两个灰度值。
图像信息在采集过程中往往受到各种噪声源的干扰,这些噪声在图像上的常常表现为一些孤立的像素点,这可理解为像素的灰度是空间相关的,即噪声点像素灰度与它们邻近像素的灰度有着显著不同。通常,一般的前置图像处理后的图像仍然带有后续所不希望夹带的孤立像素点,这种干扰或孤立像素点如不经过滤波去噪处理[4],会对以后的图像区域分割、分析和判断带来影响。所以为了精确识别,要进行图像的滤波去噪处理。本文采用3×3中值滤波去噪,如图1所示为图像去噪前的原始图像,如图2所示为经过中值滤波后的图像,从图像效果来看,噪声的支队效果较好。像中的所有行的上下边界。

图1 图像去噪前Fig.1 Image before the filter noise
[Step 2]:定义图像的左边界、右边界为此行的左边界、右边界 edgeRows[rowsNumber,left],edgeRows[rowsNumber,right]。
[Step 3]:获取了行的上下边界后,从图像的左边界扫描到右边界第一次获取的黑色像素点的位置的水平分量位置存到 edgeRows[rowsNumber,left]中,再以行的上下边界为边界,从图像右边界扫描到左边界第一次获取的黑色像素点的位置的水平分量位置存到edgeRows[rowsNumber,right]中。
2)在行的基础上单个字符的定位
[Step 1]:在第一步中获得的行位置的基础上,以行的上下边界为扫描边界从左到右扫描图像中标定的字符行的区域,判断扫描的像素点是否为黑色,若为黑色则记下此像素点位置的水平分量即将它设置成字符的左边界edgeLetters[lettersNumber,left];继续循环判断像素点是否还有黑色若有则继续循环,直到不发现黑色像素点记下此时像素点位置的水平位置为字母的右边界edgeLetters[lettersNumber,right];继续用递归算法获取下一个字母的左右边界。
[Step 2]:利用同[step1]同样的原理获得每行的每个字母的 上 下 边 界 edgeLetters [lettersNumber,top], edgeLetters[lettersNumber,dwon]。
多个字符定位功能的实现如图3多个字母定位示例。

图2 图像去噪后Fig.2 Image after the filter noise
3 字符区域定位
处理印刷体文字识别时,最常见的还是多个字母的识别,当图像中有多个印刷体字符时,需要先获取行的行的上下左右边界坐标,再获取单个字符的上下左右边界坐标,以便进行单个字符的特征提取和特征值匹配来识别的字符。多个字符的定位分两步,实现算法:
1)行的定位
[Step 1]:获取图像后从图像的上边界到下边界扫描图像区域,当检测到黑色时记下此像素点位置并把该点的水平方向的坐标存入数组edgeRows[rowsNumber,top]即行的上边界,继续向下扫描若仍检测到黑色不做任何事,直到检测到非黑色记下此时像素点,并把此点的坐标的垂直分量值记下存入edgeRows[rowsNumber,down]即行的下边界,继续扫描图像获取下一行字符的上、下边界,直到扫描完整张图片,获取到图

图3 多个字母定位示例Fig.3 Location of multiply characters
4 特征提取与训练入库
字母分割的具体算法:
[Step 1]:经过字符区域定位,得出字符所占区域的边界坐标为左边界 edgeOfLetter[left],右边界 edgeOfLetter[right],上边界 edgeOfLetter[top],下边界 edgeOfLetter[down], 字符区域的宽 width=edgeOfLetter[right]-edgeOfLetter[left],高 height=edgeOfLetter[top]-edgeOfLetter[down];
[Step 2]:判断字符区域的宽度 width和高度height,若width和height同时大于9则用9×9分割取N=9;若width和height有一个不满足大于9则用5×5分割。
[Step 3]:为保证划分的区域均匀,将前(N-1)×(N-1)格的每一格的宽度设为wx=width/N,高度设为hy=height/N;
[Step 4]:由于字符区的宽高大小不定,不是每个字符都能刚好平均划分,所以最后一列的宽应定为width-wx×(N-1),最后一行的高应定为 height-hy×(N-1);
[Step 5]:获取分割点后,将分割线以横向和纵向不同颜色绘制到定位的字符图像中,直观地显示出分割的效果(这一步可有可无,在完善系统时并不需要将分割线描绘出来);如图4分割字母前和图5分割字母后的效果图。
本文采用的网格统计特征值[5]算法,具体实现算法:

图4 字母“B”分割前Fig.4 Letter B before splitting

图5 字母“B”分割后Fig.5 Letter B after splitting
[Step 1]:在对单个字符进行定位后,将定位的字符区域分为N×N(本系统采用9×9的分割)个小区域;
[Step 2]:分别对每个小区域进行判断,利用calculatePixel(int left, int right, int top, int down)函数统计[1]中分割后每个小区域中黑像素点的个数,若一个单元格的黑像素点个数超过pixelNum(本系统设为6)个,就将此区域的特征值设置为1,否则设置为0存储于特征数组arrayOfCharacter[];
[Step 3]:将步骤[Step 2]中获得的该字符的所有特征值arrayOfCharacter[],按照特定的命名方式,存储到相应的*.dat的文件中;如图7字符“a”的9×9分割特征值。

图6 字符“a”的9×9分割特征值Fig.6 9×9 grid feature of"a"
5 字符识别
英文单词的识别实际上就转换为英文字母的识别,然后再组合为单词的过程。识别就是将提取的信息与记忆中的信息进行分类和模式匹配的过程。分类是将一个未知样本分到几个预先已知类的过程。数据分类问题的解决是一个两步过程:第一步,建立一个模型,描述预先的数据集或概念集。
本文所用最短欧式距离的模式识别方法,结合特征提取阶段所得的各字母的特征,实现单词中字母的识别。具体实现如下:
[Step1]:从特征库打开各字母的特征存储文件,遍历所有文件,统计出特征文件的数量;
[Step2]:将提取出来的特征值与特征库里的所有文件进行比对;
[Step3]:使用上述公式,计算待测样品x与训练集中的汉字的每个特征的距离,并将结果存放在二维数组arrTrainedFeature[]中;
[Step5]:找出运算结果数组arrTrainedFeature[]中的最小值对应的字母编码,转换为对应的字母和空格、标点符号,识别后进行组合成单词。
6 文本朗读
语音合成技术是信息处理领域的一个重要分支 ,实现计算机文本文件语音合成 ,就是让计算机开口说话 ,这也是人工智能的一个重要研究方向。语音合成是一门跨学科的技术,涉及到自然语言理解、语音学、信号处理、心理学、声学等。TTS技术(Text To Speech)是当前语音合成技术的代表性研究内容 ,它解决的主要问题是如何将文本状态的文字信息转化为可听的声音信息。这一技术在人机对话、电话咨询、自动播音、助讲助读、语音教学等方面有着广阔的应用前景。
最新的TTS技术推出已经两年有余。Text To Speech是一个将Text文本通过计算机读出来的过程。TTS的原理在此不作更深入的讲解 ,因为Speech SDK开发包已经将所有的技术包含在内 ,只需要将这些技术以 “类”和“函数”的方式应用到自己的程序中就可以了。
通过研究现有的一些语音朗读软件发现,有很多的产品都使用了MicroSoft的Speech Api。MicroSoFt Speech Api的功能十分强大,不仅可以准确读出单词,而且还能够实现流利地朗读句子乃至段落、文章。对于不常见的单词(如中文人名的拼音),也能够根据英文的发音原则,读出较准确的发音。
本课题运用了现有的语音技术融合到本系统中。下面介绍一下实现算法:
[Step 1]:安装 MicroSoFt Speech Api,它可以在金山词霸的光盘上找到,或者从网上下载,文件名是SpchApi.exe,是个自解压文件,直接运行即可。同时还需要安装朗读的引擎tts51eng.msi,本系统采用的是男声的引擎;
[Step 2]:在项目中引入TTS技术相应的开发包SpeechLib;
[Step 3]:虽然开发包中有可以进行朗读的类,但是开发包中的类方法中有太多的参数,使用不方便,所以在本系统中创建一个类Speech,该类中定义一个SpVoicel类型的变量voice 和 Speak(String text)方法;
[Step 4]:完成字符识别后的文本会在richTextBox中展现,使用字符串变量text获取richTextBox的文本;
[Step 5]:在窗体中加入一个按钮,触发单击按钮事件创建一个 Speech对象 speech,speech调用 Speak(String s)方法即speech.Speak(text)。完成这些步骤,就完成了文本朗读功能的实现。
最终处理效果系统界面图如图7所示。本系统能够对成篇的英文进行精确的定位、识别和朗读,并能够将中间处理结果显示出来,以方便用户查阅对应的识别过程。

图7 识别结果图Fig.7 Recognition system
7 结 论
文中利用VS.net2005[6-7]构建了一个可以进行印刷体单词识别和朗读的系统,能够进行较为准确的识别和朗读。但印刷体单词识别的难点主要在于以下几方面:
1)有些英文单词大小写字形区别不大,在识别中很容易将大写识别成小写,或者把小写识别成大写如:W和w,S和s等。
2)英文单词分词问题。英文单词由字母组成,字母之间的距离和单词之间的距离在印刷体中有时很难区分。所以在识别单词时,要注意分词。
3)由于脱机印刷体字母的输入只是简单的一幅图像,它不像联机输入那样可以从物理输入设备上获得字符笔画的顺序信息,因此脱机印刷体字母识别是一个更有挑战性的问题。
[1]王科俊.印刷体中文文档识别系统的研究 [D].哈尔滨:哈尔滨工程大学,2009.
[2]张宏涛.印刷体汉字处理后处理方法的研究[J].中文信息学报,2009(11):67-71.
ZHANG Hong-tao.Post-processing approach for printed chinese character recognition[J].Journal of Chinese Information Processing,2009(11):67-71.
[3]梁涌.印刷体汉字识别系统的研究与实现 [D].西安:西北工业大学,2006.
[4]倪桂博.一种快速有效的印刷体汉字识别方法[J].华北电力大学学报,2008(5):107-112.
NI Gui-boa.A fast and effective method for printed Chinese character recognition[J].Journal of North China Electric Power University:Natural Science Edition,2008(5):107-112.
[5]杨淑莹.模式识别与智能计算:Matlab技术实现[M].北京:电子工业出版社,2008.
[6]赵春江.C#数字图像处理算法典型实例 (附光盘)[M].北京:人民邮电出版社,2009.
[7]李兰友.Visual C#图像处理程序设计实例[M].北京:国防工业出版社,2003.
猜你喜欢
现代电子技术(2021年1期)2021-01-17
美与时代·美术学刊(2020年7期)2020-10-13
校园英语·月末(2020年4期)2020-06-08
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
