
通用语义角色自动标注研究
2012-07-09 01:44尹晓丽
长春工业大学学报 2012年2期
尹晓丽
(山西大学商务学院理学系,山西太原 030031)
0 引 言
语义角色标注(Semantic Role Labeling,SRL)是目前语义分析的一种主要实现方式,它也是近年来自然语言处理领域的一个研究热点,是信息抽取、信息检索、阅读理解问答系统等多种自然语言处理技术的重要基础。
文中以Fillmore的框架语义学[1-3]为理论基础,以汉语真实语料为依据,由山西大学2005年开始开发的汉语框架网络(CFN)知识库[4-5]作为语料库,以条件随机场[6]为基本模型研究了框架语义中通用语义角色的语义角色、短语类型和句法功能三层自动标注问题,获得了较好的实验结果。
1 基于条件随机场模型的通用语义角色自动标注
通用语义角色的自动标注包含语义角色、短语类型和句法功能标注3部分。我们采用层叠式标注方法:先标注语义角色,再标注短语类型,最后进行句法功能的标注。
1.1 标注过程
基于条件随机场的通用语义角色标注过程主要由以下5个模块组成:
1)预处理模块;
2)语料生成模块;
3)模型训练模块;
4)标注模块;
5)评测模块。
该标注过程如图1所示。
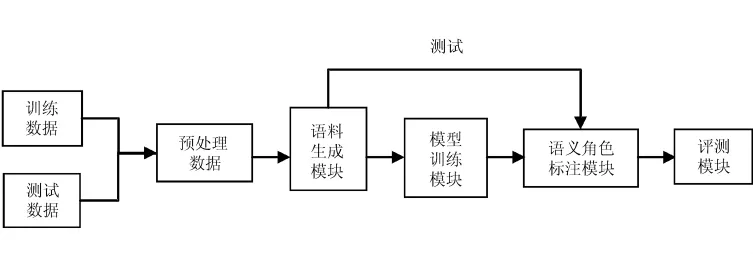
图1 语义角色标注过程流程
1.2 语料的选取
语料库选用了山西大学CFN句子库,其中包含了195个框架,1 548个词元和15 999个句子,且每个句子都已经进行了分词和词性标注,并且也人工标注了框架元素、短语类型和句法功能3种信息。我们抽取CFN句子库中的含有通用语义角色的句子作为数据集,并按9∶1的比例对句子进行了划分。该语料库中共有13个通用语义角色:time,manr,place,degr,sco_role,part_iter,purp,mns,depic,reci,iter,freq,dui_action。
1.3 工具的选取
实验中使用的是版本为0.42的CRF++软件包,该软件包是由Taku Kudo开发的开源软件包。该软件包被应用到了许多序列标注任务,如命名实体识别、信息抽取、文本语块分析等。实验采用了高斯平滑,将平滑参数C设置为1.0,然后使用LBFGS进行MAP估计。
1.4 实验评测标准
实验采取两种不同的测试性能评价指标。
1.4.1 MUC会议上采用的指标


为了综合评价系统的性能,通常还计算召回率和准确率的加权几何平均,即F值,它的计算公式如下:
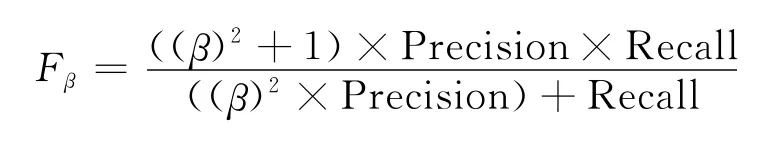
式中:β——召回率和准确率的不同权重,β越大,Recall对Fβ的影响越大。通常情况下,β=1,Recall和Precision具有相同的权重。
1.4.2 综合排名法
根据实验结果,按从大到小的顺序排列,依次为1,2,3,…,如果有相同的名次排名相同,最终综合排名靠前的实验结果好。
2 特征的选取
通用语义角色自动标注实验所使用的特征分为3类:基本特征、扩展特征、规则特征。
2.1 基本特征
基本特征是指词、词性和位置。
词,分词后的单个字,一个词或标点符号;词性,词所对应的词性;位置,该词相对于目标词的位置。
2.2 扩展特征
扩展特征是指句法标记、结构标记和功能标记。
句法标记和结构标记都属于基本块标记,功能块标记[7]是定义在句子层面的句法成分,我们采用清华大学周强教授提供的基本块和功能块标注工具[7]对语料进行了基本块标注。
赵颖泽[8]对清华大学的TCT功能块语料库进行了统计,发现语料中S,P,O,D块所占的比例达到了97%,文中在进行功能块标注任务时,仅对S,P,O,D 4块识别。
2.3 规则特征
对于time,freq,degr,sco_role这4种语义角色,它们经常以一定的频率出现,为此,我们引用了词表信息。
3 实验结果及其分析
3.1 语义角色标注实验结果
由于语义角色标注是进行短语类型标注和句法功能标注的基础,所以语义角色标注的好坏直接影响到短语类型和句法功能的标注结果。根据特征选取的不同,先后进行了下面3组实验。
我们把只考虑词、词性特征的T1模板作为Baseline。
实验1:在T1模板的基础上,加入位置、功能块、结构标记和句法标记单个特征,见表1。
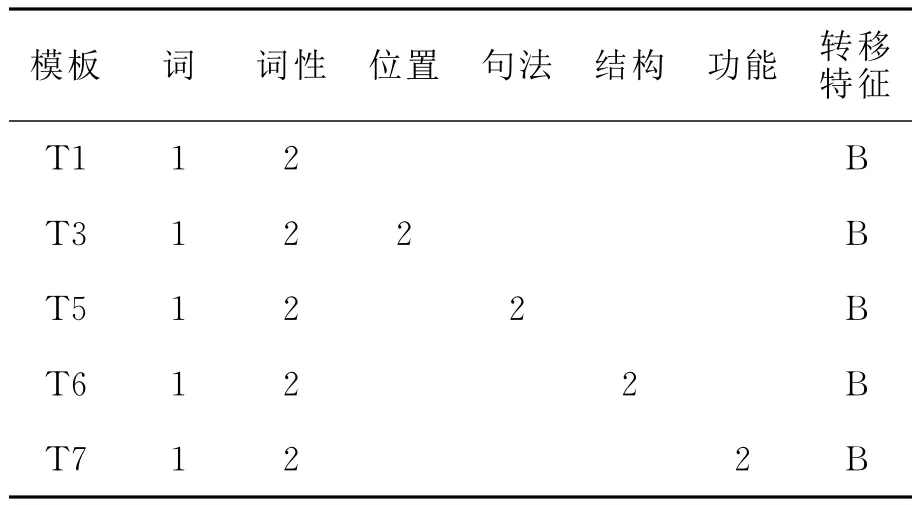
表1 T1基础上加入位置、功能、结构、句法特征的模板
对这5个模板的实验结果进行分析,见表2。

表2 实验1的结果
由表2可以看出,T3模板的F值综合排名最好,而且明显优于其它模板;另外,T3模板比T1模板的平均准确率、召回率和F值都高。可见位置特征是一个很重要的特征,把它作为一个必要特征加入实验,称之为Baseline1,下面的实验都是基于T3模板上进行的。
实验2:在T3基础上加入单个结构标记、句法标记、功能标记特征,并且考虑加入它们的组合特征,见表3。
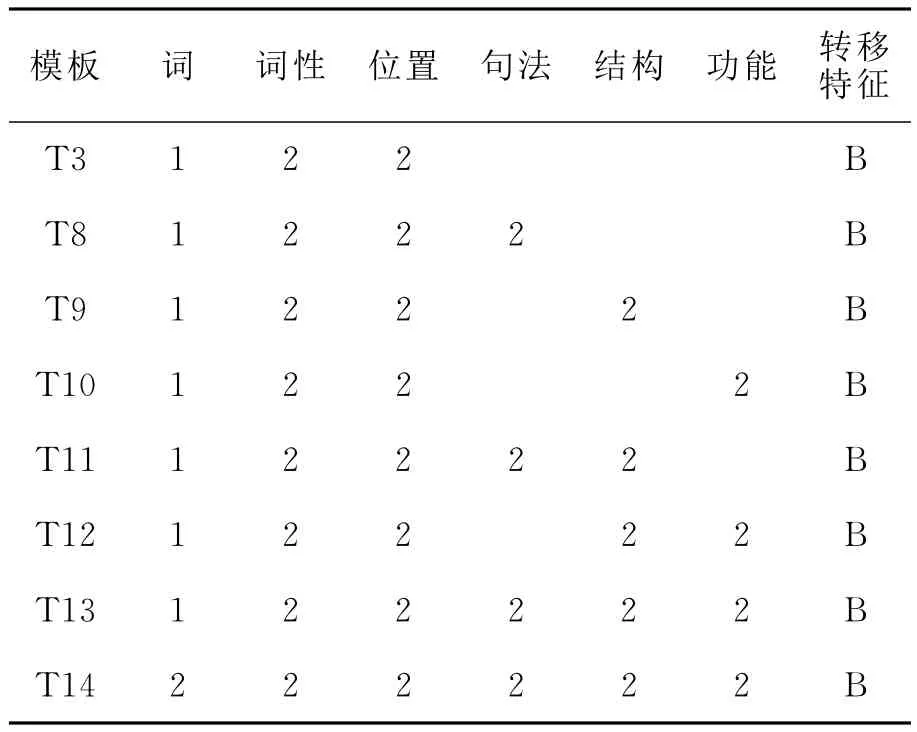
表3 实验2的模板
对这8个模板的实验结果进行分析,见表4。
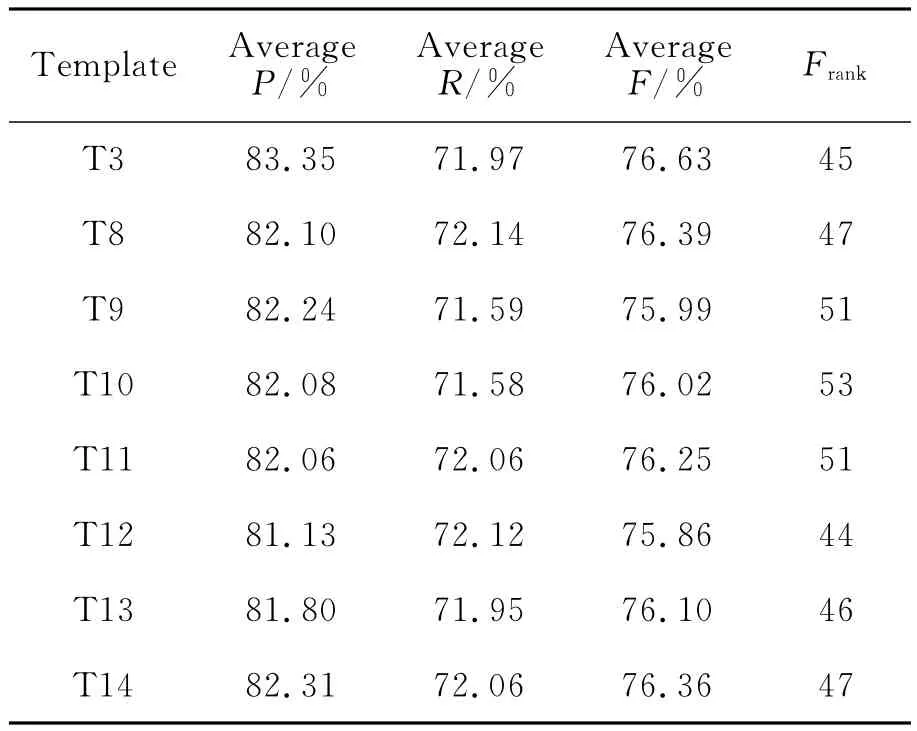
表4 实验2的结果
由表中可见,这几个模板的综合排名差异不是很大,它们的平均召回率和平均F值波动幅度不到1%,平均准确率波动幅度不到2%。换句话说,在T3的基础上引入结构标记、句法标记、功能标记特征,并没使结果变好,而是随着特征的增多,测试平均准确率、召回率和F值有所下降。主要原因是基本块和功能块标注工具存在一定的错误率,实验用的测试集都是自动标注语料,存在部分标注错误,由于误差累积影响到系统的性能。
实验3:由于以上8个模板差异不是很大,在这8个模板基础上,把time,freq,degr,sco_role这4个语义角色加入规则特征,即引入词表信息作为特征进行实验,结果见表5。
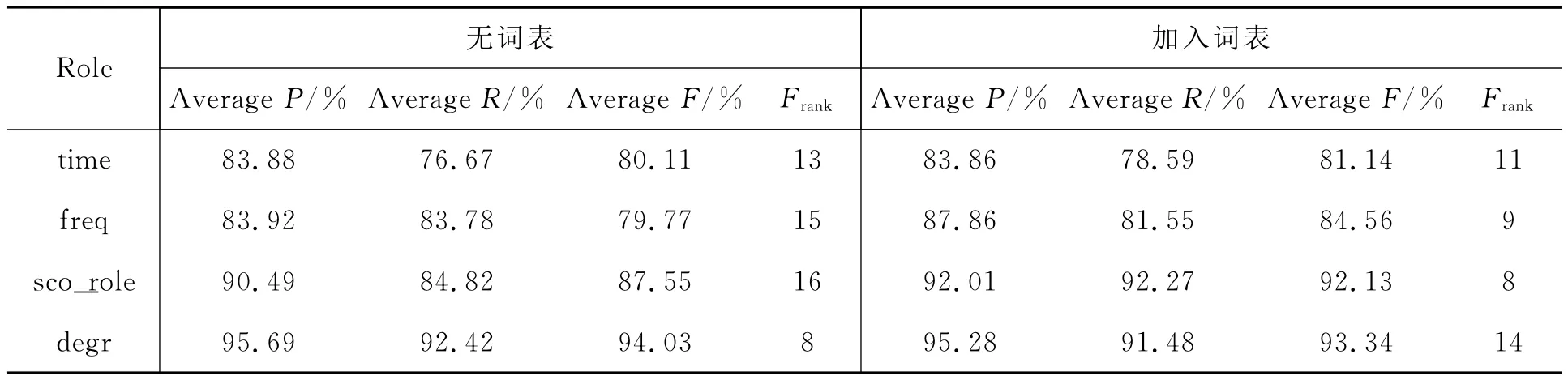
表5 实验3的结果
由表5可见,在引入词表信息作为特征后,time,freq,sco_role这3个语义角色的平均F值大约提高了1%,4.8%,4.6%,而且综合排名也优于不加词表特征的排名。只有degr的平均F值降低了不到0.7%,不过从总体上看,引入词表特征对实验结果有一定的提高。
3.2 短语类型和句法功能标注实验结果
为了进行下面的短语类型和句法功能的标注,我们对各个通用语义角色在这13个模板下分别进行了实验,得到每个语义角色最好的实验结果作为短语类型标注的输入来进行研究。然后,选取语义角色和短语类型双层标注后最好的标注结果进行句法功能标注。
最后,把这三重自动标注实验的最终结果进行一个简单的比较。其中,Role_F表示语义角色自动标注结果的F值,PT_F表示语义角色、短语类型自动标注结果的F值,TriGroup_F表示语义角色、短语类型、句法功能三层标注结果的F值,Error1表示语义角色和短语类型标注结果的F值的差值,Error2表示短语类型和语义角色三层标注F值的差值,Error3表示语义角色和语义角色三层标注F值的差值,见表6。
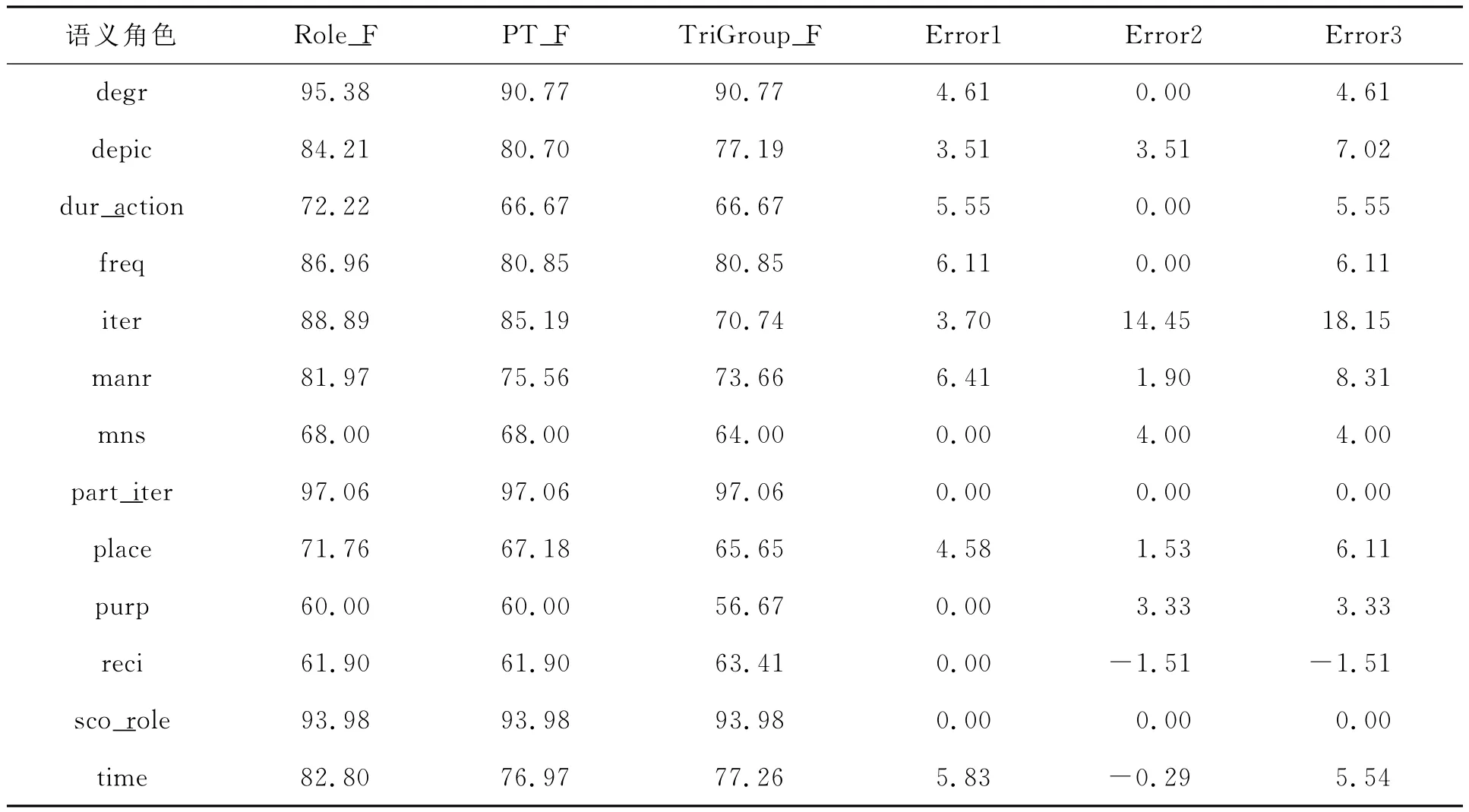
表6 语义角色、短语类型和语义角色三层标注的结果 %
由表6可以看出,每一层标注基本上都存在一个误差累积,这也正是层次标注的缺陷。对part_iter和sco_role这两个语义角色,它们在语义角色标对的情况下,短语类型和句法功能也全部标注正确,这跟语义角色本身的定义有很大关系。而对于上表中一些差值为负的情况,则是由在自动标注过程中,机器自动找到的个数变少,使得准确率和F值相应提高而导致,但这种情况出现的比较少。总体上看,我们在进行语义角色三层的标注获得了比较好的实验结果。同时,语义角色标注的结果直接影响到短语类型和句法功能的标注,因此,提高语义角色标注的结果是下一步研究的重点。
4 结 语
采用山西大学开发的汉语框架网络知识库作为语料资源,以条件随机场为基本模型框架,设计并实现了一个通用语义角色三层标注系统。该系统采用层叠结构,首先标注语义角色,其次标注短语类型,最后进行句法功能的标注。从实验结果可以看出,基于条件随机场的通用语义角色三层自动标注已经表现出了良好的性能。但是,采用层叠式标注方法容易产生误差累积,导致实验结果逐步下降。语义角色标注的结果直接影响到短语类型和句法功能的标注,为此,如何进一步提高语义角色标注的结果是以后研究的主要工作。
[1] Charles J Fillmore.Frame semantics and the nature of language[A]//Annals of the New York Academy of Sciences:Conference on the Origin and Development of Language and Speech[C].1976,280:20-32.
[2] Charles J Fillmore,Charles Wooters,Collin F Baker.Building a large lexical data bank which provides deep semantics[A]//Proceedings of the 15th Pacific Asia Conference on Language,Information and Computation[C].HongKong,2001:3-26.
[3] Baker C F,Fillmore C J,Lowe J B.The berkeley frameNet project[A]//Boitet C,Whitelock P,eds.Proc.of the ACL&Coling’98.Montreal:ACL,1998:86-90.
[4] 刘开瑛,由丽萍.汉语框架语义知识库构建工程[A]//中文信息处理前沿进展[C].中国中文信息学会成立二十五周年学术会议论文集,2006,11:64-71.
[5] 由丽萍.构建现代汉语框架语义知识库技术研究[D]:[硕士学位论文].上海:上海师范大学,2006.
[6] John Lafferty,Andrew McCallum,Fernando Pereira.Conditional random fields:Probabilistic Models for Segmenting and Labeling Sequence Data[A]//Proceedings of the 18th International Conference on Machine Learning[C].San Francisco,2001:282-289.
[7] 周强.汉语基本块描述体系[J].中文信息学报,2007(3):23-29.
[8] 赵颖泽.汉语功能块的自动分析[D]:[硕士学位论文].北京:清华大学,2006.
猜你喜欢
大连民族大学学报(2021年2期)2021-07-16
开放教育研究(2020年2期)2020-03-31
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
现代语文(2016年21期)2016-05-25
海峡姐妹(2016年2期)2016-02-27
大连民族大学学报(2015年2期)2015-02-27
当代修辞学(2014年3期)2014-01-21
外语学刊(2011年1期)2011-01-22
