
中文歧义研究25年
——以《中文信息学报》论文为例
2012-06-29 06:15:02张禄彭易绵竹
中文信息学报 2012年4期
张禄彭,易绵竹,周 云
(1. 解放军外国语学院 欧亚语系,河南 洛阳 471003;2. 解放军外国语学院 国防语言文化研究所,河南 洛阳 471003;3. 国防科技大学 计算机学院,湖南 长沙 410073)
1 引言
D. Jurafsky和J.H. Martin认为[1],“在自然语言自动处理过程中需要的语言学知识可以分为语音学与音系学、形态学、句法学、语义学、语用学、话语学等多个层面”,而“语音和语言计算机处理的绝大多数或者是全部研究都可以看成是在其中某个层面上的消解歧义。”俄罗斯在线学术大百科词典“Кругосвет”中“歧义”(неоднозначность)词条指出[2],歧义体现为一个能指对应多个所指,它存在于语言的各个层级,包括词素(морфемы)、词形(формы слов)、词(слова)、成语(фразеологические обороты)、短语(словосочетания)和句子(предложения)。可见,自然语言处理所面临的歧义问题存在于多级语言单位以及语言学研究的多个层面。
20~21世纪之交是中文信息处理科学迅猛发展的时期,其间中文的歧义和消歧(或称“排歧”)研究也越来越受重视。以中国中文信息学会会刊《中文信息学报》(以下简称《学报》)为例,从1986年创刊至2010年的25年,歧义问题研究取得了长足进步,涌现出大量的科研成果。本文试图以《学报》刊载的文章为例,管窥20世纪后15年和21世纪前十年*关于21世纪的首年有两种认定方式,一种是2001年,另一种是2000年,各自的理由在此不再赘述。本文中我们采用第一种认定方式,这种方式在我国广泛使用。间中文信息处理领域歧义研究的大体趋势,调查各类型歧义的研究状况,探讨消歧方面研究的主要进展和特点。不当之处,敬祈雅正。
1986~2010年的25年间《中文信息学报》所刊论文中以“歧义”、“消歧”、“排歧”以及“歧”、“岐”作为主题或关键词共可选中八十余篇文章*为保证论文搜索完整无遗漏,我们在CNKI中国知网及维普资讯两个期刊数据库进行了检索和下载。。经认真研读比对,我们将“论文中至少有一小节是关于歧义问题的专门研究或者全文研究与歧义问题有紧密联系”设为必要条件,最终有66篇论文[3-68]符合这一必要条件,被选定为本文的研究素材*此外,2011年还有李济洪等[69]和时迎超等[70]两篇文章,但由于2011年度尚未结束,难以将该两文计入分时间段定量统计分析中。为保证统计规则的统一及严谨,本文中的很多统计分析并未计算该两文。。该66篇论文大体可分为两种,一种是全文都是关于歧义问题的专门研究,可称为“关于歧义问题的专门论文”(以下简称“歧义专文”),有41篇;另一种是文中至少有一小节是关于歧义问题的专门探讨或全文内容与歧义问题有密切联系,可称为“涉及歧义问题的相关论文”(以下简称“涉歧论文”),有25篇(详见文末表1)。
从论文的研究对象看,66篇文章大体可分为分词歧义研究[3-18]、结构歧义研究*“结构歧义”主要是指句法结构歧义。此外,刘蓓等[29]还涉及到了语义结构歧义,其称谓和消解方法均源自句法结构歧义,故一并归为此类。[19-34]、词义歧义研究*“词义歧义”即词汇语义的歧义。[35-52]、其他类型歧义研究[21,53-64]和歧义消解的一般性研究[65-68]五个方面。其中前四个方面具有明确的考察对象,针对具体类型的歧义现象提出具体的消歧策略或算法;最后一个方面并不明确限定歧义的具体类型,而是宏观性地提出歧义消解的某种总体性方略或思路。主要研究方法可归为基本策略和具体方法两部分,其中基本策略大致分为本体论与分类研究、基于规则、基于统计、基于知识库、基于实例等五个方面,具体方法包括各种知识库、多种算法、语料库的运用、机器学习等。下面我们将分别对各方面进行述评,并通过定量统计来观察中文信息处理领域歧义研究的特点和趋势。
2 对歧义问题的不断关注
《学报》自1986年创刊以来最早的歧义研究主要见之于李国臣等[3]、俞士汶[65]、冯志伟[19-20]、孙茂松等[21]几篇文章,学术前辈们富有开创性的研究工作开辟了中文信息处理中的歧义问题这一重要领域。此后,歧义问题不断受到学界的关注,从讨论的歧义类型,到研究方法,再到具体算法都在不断演进。
我们将二十五年来《学报》中关于歧义问题的66篇论文以五年为一段,分为五段(下同),从而观察在各时间段歧义研究论文的分布情况,如图1所示。

图1 歧义研究各时间段的分布
通过图1我们不难看出,自1986年《学报》创刊以来,歧义及其消解问题一直受到中文信息处理领域学者们的关注,每个阶段的歧义研究都不曾间断。总体来看,对歧义及其消解问题的研究表现出一个稳步升温的趋势*《学报》自1999年由季刊改为双月刊,每年发表论文总数随之增多。这也是影响歧义问题研究的论文数量增长的一个积极因素,促进了歧义问题研究在中文信息处理领域受关注程度稳中有升的总体态势。,尤其是近五年的歧义研究达到了一个高峰。
随时间的推移,经过学者们不断的开拓研究,逐步积累了较多成果。但中文信息处理领域的歧义问题一直未能得到根本的解决,促使学者们对歧义问题的研究持续深入。这样的态势显示出歧义及其消解问题是中文信息处理领域关键的课题之一,同时也是相当有难度的课题。在接下来相当长的时间内,歧义及其消解问题作为中文信息处理领域的一个重点和悬而未解的难题仍将受到学界的不断关注。
此外值得一提的是,涉歧论文的分布呈较快增长的趋势,越来越多的课题中出现了“一个输入对应多种输出”的情形,研究者们越来越习惯称其为“歧义”,例如,短语边界歧义,音字转换歧义,中文姓名识别歧义、类码语句歧义、非标准词歧义、翻译对齐歧义等[58-64]。多种新类型的歧义与其他课题交织在一起,并成为某中的一部分,这是歧义研究所体现出的与相关课题间的交叉性。交叉性也将是中文歧义问题在未来的一个发展趋势。
接下来,我们更为细致地讨论不同类型歧义的情形。
3 各种类型歧义的研究态势
中文信息处理领域的歧义问题按照其研究对象大体可分为分词歧义研究、结构歧义研究、词义歧义研究、其他类型歧义(如词类(词性)歧义、短语边界歧义、文字歧义、缩略语歧义等)研究和歧义及其消解的一般性研究五个方面。其中前四个方面具有明确的考察对象,针对具体类型的歧义现象提出具体的消歧策略或算法;最后一个方面并不明确限定歧义的具体类型,而是宏观性地提出歧义消解的某种总体性方略或思路。分词歧义、结构歧义、词义歧义、其它类型歧义四种类型中,前三种构成了中文歧义问题的主要部分。
3.1 各种类型歧义研究的总体分布情况
二十五年来《学报》的各种类型研究总的分布情况如图2所示*孙茂松等[21]一文中词类歧义和结构歧义两方面研究并重,因此在统计中我们将其分割放置在结构歧义和其他类型歧义两个部分中,各计0.5篇文章。(下同)。

图2 各类型歧义研究的总体分布
《学报》刊登的66篇文章中讨论分词歧义[3-18]、结构歧义[19-34]和词义歧义[35-52]的论文各有15~18篇,分别占总数的四分之一左右;其他类型歧义研究[21,53-64]加上关于歧义问题的一般性研究[65-68]两方面总和也占总数的四分之一。图2显示,从所有论文的范围来看,分词歧义、结构歧义、词义歧义研究三足鼎立,目前占据中文信息处理领域歧义研究的绝大部分。
以上是所有论文的总体情况,歧义专文的情况如图3所示。

图3 各类型歧义专文的分布
41篇歧义专文中探讨分词歧义[3-13]、结构歧义[19-31]和词义歧义[35-44]问题的文章各占24%~30%;而其他类型歧义研究[21,53-54,56-57]加上关于歧义问题的一般性研究[65-67]两方面总和还不到总数的20%。图3显示的情况与图2相一致,而且歧义专文中的分词歧义、结构歧义、词义歧义研究三个方面更为明显地占据中文歧义研究的主要部分。
下面我们分时间段从历时角度观察《学报》中各种类型歧义研究的分布情况,讨论其趋势和特点。
3.2 各种类型歧义研究的按段分布情况
3.2.1 三种主要类型歧义研究的按段分布
各时间段内三种主要类型歧义研究的总体分布情况如图4所示。
歧义专文的按时间段分布情况如图5所示。
结合图4和图5我们看到:
(1) 从三种主要类型歧义论文的延续性和密集程度来看,研究者们对于分词歧义、词义歧义、结构歧义的探讨在向不断深入的方向发展。

图4 三种主要类型歧义研究论文总数的按段分布

图5 三种主要类型歧义专文的按段分布
(2) 分词歧义始终受到关注,而且受关注度不断提升。结构歧义也不断受到关注,但在20~21世纪之交达到高点之后,其受关注度逐渐下降。词义歧义在《学报》的前十年并未得到探讨,自20世纪90年代后半期以来,中文信息处理领域对词义歧义的研究异军突起。
(3) 若将歧义问题依据研究对象的不同分解为若干子集,则各时段的研究热点有所不同。早期重结构歧义和分词歧义,现今注重词义歧义和分词歧义。图5反映的趋势特点与图4基本吻合,结构歧义的发展趋势不如图4明显,这与数据稀疏有关。总而言之,词义歧义和分词歧义研究的发展速度比结构歧义研究更快,尤其是在2001年以后的十年间。
3.2.2 其余两方面歧义研究的按段分布
本小节我们考察其他类型歧义的研究以及关于歧义问题的一般性研究两方面的分布情况,其分布状况也反映了中文歧义问题研究的某些趋势(图6)。

图6 其余两方面歧义研究的总体按段分布
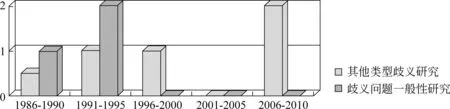
图7 其余两方面歧义专文的按段分布

图8 其余两方面涉歧论文的按段分布
结合图6,7,8我们看到:
(1) 其他类型歧义的研究在近年来活跃起来,体现歧义问题研究对象的范围正在扩大。在对三种主要类型歧义研究向深化发展的同时,歧义的其他类型也有向广度发展的趋势。这说明中文信息处理的许多课题、领域都遇到了歧义的情况。研究其他类型歧义的文章共13篇。早期研究对象是传统的歧义类型,如词类(词性)标注歧义[21,53-55];近期的研究对象范围扩大,更多新的歧义类型进入研究者的视野,如民族语言文字歧义、缩略语歧义、短语边界歧义、非标准词歧义、中文姓名歧义、音字转换歧义等等[56-64]。*此外,赵军[49]探讨了命名实体的排歧,高维君等[45]讨论了关联词语识别歧义,张顺昌等[18]论述了拼音流切分存在的歧义,这三篇文章也体现出歧义研究对象向广度发展的趋势。但根据原文作者对这些类型歧义的定义,该三文总体属于词义歧义和分词歧义的范畴,因此未归入“其他类型歧义研究”的序列。
(2) 其他类型歧义的研究大多数存在于涉歧论文中,因为其他类型的歧义大多是新出现的类型,它们出现在相关课题中的某个或某些环节,于是很自然地被归为其他类型的歧义。这些类型的歧义虽然从个体来看并不多也不算是歧义问题的主流,但是它们总体作为一个属种确实在近年成长为一股新潮流,体现出歧义研究在向交叉性的方向发展。
(3) 歧义问题一般性研究不明确限定具体类型的歧义,而是综合性、概括性地提出歧义消解的某种基本思路和体系。例如,杨莹等[66]提出一种可以表示常识及语言知识的意象知识体系;钱树人[67]提出汉语语言片段歧义分析模型系统CAAMS。歧义问题的一般性研究的文章主要出现在20世纪90年代前后,之后这种研究基本方法的文章减少,消歧研究向细化、深化的方向发展,绝大多数研究工作致力于深入挖掘用于消解具体类型歧义的新算法。
3.3 思考与讨论
第一,歧义问题作为一个整体长期以来受到学界的不断关注,然而在不同的时间段内研究者们更为关注的歧义具体类型有所不同。
第二,随时间的推移,歧义及其消解问题的研究对象正在向广度和深度发展,在向与相关课题交叉的方向发展,这符合人类认识世界的规律。已有的歧义种类,其研究将不断深入;相关领域的新的歧义类型也将逐渐出现。
第三,事实上,中文信息处理中的歧义问题也应是广泛存在于各个语言单位和语言学的各个层面上的。现在我们处理的歧义主要是词汇、短语(字符串)单位上的,其次是句子、单字单位上的,将来可能还将扩展到段落和篇章单位。当今我们研究的歧义主要是构词、句法结构和词汇语义层面的,其次是语音和形态层面,将来可能会涉及到现代语义学、语用学以及心理语言学、文化语言学等交叉学科的层面。
4 歧义及消歧研究的策略方法
本节考察66篇论文的研究方法。为便于更直观地了解每篇论文的情况,我们将所有论文的相关信息总结列于表1中,以发表时间进行排序。
4.1 处理歧义的基本策略
结合图9与表1我们看到:

图9 基本处理策略的按段分布
(1) 1990年以前,多采用本体论和分类的策略,主要任务是对歧义进行定义和分类,并对消歧提出一些指导性的建议,例如,冯志伟[19-20]、俞士汶[65]和孙茂松等[21]。这些基础性的研究为后来歧义研究的大发展奠定了基础。
(2) 在早期的歧义研究中,基于规则的策略占据主导地位。1995年以前,较多使用规则集来处理歧义,构建了一些实用的系统。截至2005年前的许多论文中还都会综合利用规则的消歧策略,但2006年以来,相对于其他策略的增长,基于规则的策略有了实质性的减少。基于规则的策略应当怎样发挥更大的作用,是值得我们探讨的问题,在这方面,香港城市大学《切词规则》(转引自: 李玉梅等[17])在2005年细致总结出中文分词的诸多规则[71]。
(3) 20世纪最后的几年间,基于与规则的策略与基于统计的策略并存。周强[53]首先采用了规则和统计相结合的策略,使用二元语法对语言进行建模,用Viterbi算法进行极大似然估计,还制定数据集对所用的方法进行了系统的评测。以概率统计为核心的现代自然语言处理手法在周强[53]一文得到了较完整的体现,这点对于后来的研究具有重大意义。
(4) 随着时间的推移,概率统计的研究策略被越来越多且越来越频繁地使用。自1996年以来,基于概率统计的策略开始被大量采用。统计的策略常常与其他策略结合在一起,通过其他方法策略或者语言知识的加强提高歧义消解的正确率。2000年以来,基于统计的策略更是开始占据主导,各类统计方法逐步成熟,这体现出实证主义的定量分析方法在当今的中文歧义问题研究中占据了统治地位。
(5) 基于知识库的处理策略被广为使用,且这一策略保持稳定增长的态势。研究者们使用的词典知识库种类多样,常常与规则或统计的策略配合使用,可预见今后一段时间内基于词典知识库的处理策略将得到沿用和发展。另外,基于实例的策略在上世纪末出现后成为歧义处理策略的有益补充。
4.2 处理歧义的具体方法
结合图10可以看出:
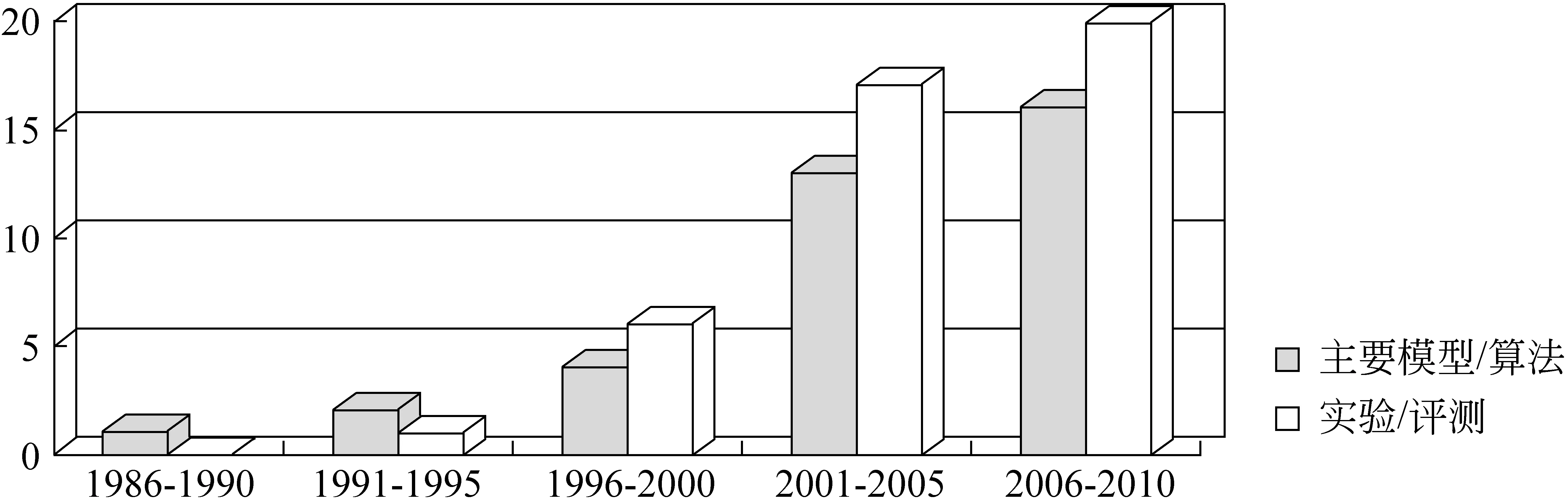
图10 具体处理方法的按段分布
(1) 使用语料库进行实验评测的方法迅速发展。基于规则和基于知识库的方法需要大量的专家进行总结归纳,而且知识表示是一个长期以来难以解决的问题。于是研究者们收集并加工语言资源形成语料库,进行实验让计算机从训练语料库中自动学习数据用于消歧,并在新的语料上进行消歧方法评测。这些实验评测大多具有严格的数学、统计学基础,在计算机上实现具有天然的优势,因此使用语料库进行实验评测的方法自20世纪末以来急速增长。
(2) 1990年以来,机器学习(尤其是有监督机器学习)的各种算法在该领域取得了显著的效果。有监督方法需要标注语料,这同样需要大量的人力物力,代表性的有李蓉等[7]采用SVM和K-NN相结合的方法。由此无监督方法也逐渐应用到该领域,王伟等[6]将非监督的机器学习方法引入歧义研究,从原始语料库中聚类出用于消歧的信息,其后,陈浩等[39]采用K-means方法进行词义消歧。但目前无监督方法的消歧性能与有监督方法还有一定差距。除此之外,如何挖掘互联网语料、平行语料、维基百科等新兴资源也成为该领域关注的问题,例如,刘冬明等[40]利用HowNet资源中概念的可计算性和句子对齐的汉英双语平行语料库信息,将词义排歧的问题转化为两种语言相对应句子词义组合的相似度计算问题。
(3) 具体算法迅速更新,层出不穷的新算法能够在一定范围内逐步提高消歧正确率,但现有算法总体是在传统算法的基础上进行的改善,原创性的、本土化的算法有待加强创新。
4.3 思考与讨论
回顾25年来歧义及消歧研究的主要策略方法,总体呈现出前期多本体论及规则后期多概率统计、前期多原则定义后期多实验评测的态势。当前,基于统计的消歧方法在中文信息处理的歧义研究中发展空前,其贡献是巨大的,但由于该方法固有的属性,如果不能与语言科学和认知心理科学有效结合的话,始终难以最终克服概率最优的计算宗旨与小概率事件之间的矛盾问题,从而无法在海量信息处理中达到高的正确率。近年来,以概率统计占统治地位的消歧策略发展到了高峰,然而其正确率的提高却难以再有实质性的超越,在这样的情形下,消歧研究应当在思变中谋发展。
第一,歧义处理与语言知识、语言科学相结合,语言学中的一些理论及模型是可能强化基于统计的消歧算法的。比如篇章语言学,消歧所需的知识大体可分为上下文知识和世界知识(文化背景知识),现有的上下文知识主要考察邻近的语言单位,如左上文、左右上下文,但如果把歧义单位放到全文这一更大的上下文中去考察,结合篇章语言学的知识分析全文的特征用以加强概率算法,就会提高消歧的准确率。再比如概念依存理论、格语法,其关于题元角色的思想对于我们理解句子单位的语义结构大有裨益,如何将这种现代语义学知识用于强化现有的消歧算法也值得我们深入思考。另外,语义场、wordnet、知网等本体知识网在消歧的过程中也能够提供强大的背景知识支持,这方面的研究已经有之,我们相信这方面的研究在未来会获得更大的发展,也将做出更多贡献。
第二,歧义处理与关于语言的心理认知科学相结合。心理语言学中的心理词典理论和言语理解与生成模型、神经网络模型、认知语言学等都可能为中文信息的消歧处理带来新的增长点。
第三,“统计+结构”将成为主流模型。如前所述,如何将语言科学、心理认知科学等先验知识与统计方法相结合是一个十分重要的问题,而“统计+结构”就是解决该问题的有效手段之一。“统计+结构”模式首先通过先验知识给出问题的结构,然后用统计的方法解决。目前,概率图模型是“统计+结构”的重要代表,它的结构为一个概率图,图中的结点是随机变量,图中的边为随机变量之间的依赖关系,可用来表达问题的内部结构。概率图模型,包括条件随机域(Conditional Random Fields, CRF)、潜在狄里克莱分配(Latent Dirichlet Allocation, LDA)等,已经在消歧研究等自然语言处理的子领域得到了十分广泛的应用。另外,对于一些长距离依赖,纯统计方法的计算复杂度过高,而将语言学结构模型加入到统计中则有可能较大幅度地降低计算复杂度。
第四,近年中文信息处理的消歧研究较为注重向美国学习先进经验,也确实取得了很大进步。当然,在借鉴美国的统计消歧策略的同时,了解借鉴其他国家的一些模型也许将是有益的补充。例如,俄国学者梅尔丘克的《意义—文本》理论模型也是面向自然语言处理的强大语言学理论体系。
第五,与英语相比,汉语的标准数据集还比较缺乏,已有的影响力也不大,对实验评估和研究的导向性作用不明显。在这方面还需要加大投入,打造实用、权威的汉语数据集,为研究的发展进步提供坚实基础。
5 结语
我们以中国中文信息学会会刊——《中文信息学报》的25年来歧义问题研究的论文[3-68]为例,对中文信息处理领域的歧义研究进行系统梳理与评析。当今歧义问题的研究对象正在向深度和广度两个方向发展,歧义问题与相关课题交叉产生多样的歧义新类型。分词歧义、结构歧义和词义歧义是当今歧义问题的主要类型。歧义问题的研究方法具体化多样化,消歧策略以概率统计为主流,由单一化向综合化方向发展,算法不断在已有基础上更新,语料库、机器学习和实验评测方法运用广泛。
歧义现象的本质是自然语言处理过程中一个输入对应多个输出的情形,其中绝大多数的歧义是只有计算机才会遇到的伪歧义[72]。其深层原因在于语言符号及其结构的多义性以及自然语言的经济原则,正是在漫长的历史中人类逐步学会以有限的符号表达无限的意义和思想,因此越是古老和基本的语言符号单位,其意义也就越是复杂[73]。人类个体在成长过程中会逐渐习得运用语言进行表达和交际,其中人的很多表达习惯、表达定式和言语交际知识有助于伪歧义的消解。
计算语言学(自然语言处理)是一门公认的交叉学科,然而遗憾的是,长期以来以计算机科学为背景和以语言科学为背景的两方面科研工作者在很大程度上却是各自为战,计算机科学和语言科学仍然未能得到较好地融合。语言学的很多有益知识,比如涉及语义因素的概念依存理论与格语法,篇章语言学关于文本篇章语言特点的理论,普通语言学关于语言层级的学说,心理语言学中的心理词典理论以及关于言语理解与生成的模型等,在未来需要更为有效地融入歧义及其消解问题研究中。如何将上述领域的研究成果转化为计算机可操作的知识系统是一个值得在未来继续深入研究探讨的课题。

表1 全部论文的信息总表*关于主要研究方法我们通过仔细研读人工整理分类而成,若有与原文不甚契合处,恳请原文作者及读者指正。

续表
[1] Jurafsky D., Martin J.H. 冯志伟,孙乐(译). 自然语言处理综论[M]. 电子工业出版社. 2005.
[2] неоднозначность词条[DB/OL]. 俄罗斯Кругосвет大百科词典. http://www.krugosvet.ru/
[3] 李国臣,刘开瑛,张永奎. 汉语自动分词及歧义组合结构的处理[J]. 中文信息学报,1988,2(3): 27-33.
[4] 刘挺,王开铸. 关于歧义字段切分的思考与实验[J]. 中文信息学报,1998,12(2): 63-64.
[5] 孙茂松,左正平,邹嘉彦. 高频最大交集型歧义切分字段在汉语自动分词中的作用[J]. 中文信息学报,1999,13(1): 27-34.
[6] 王伟,钟义信,孙建,等. 一种基于EM非监督训练的自组织分词歧义解决方案[J]. 中文信息学报,2001,15(2): 38-44.
[7] 李蓉,刘少辉,叶世伟,等. 基于SVM和k-NN结合的汉语交集型歧义切分方法[J]. 中文信息学报,2001,15(6): 13-18.
[8] 李斌,陈小荷,方芳,等. 基于语料库的高频最大交集型歧义字段考察[J]. 中文信息学报,2006,20(1): 1-6.
[9] 秦颖,王小捷,张素香. 汉语分词中组合歧义字段的研究[J]. 中文信息学报,2007,21(1): 1-8.
[10] 王思力,王斌. 基于双字耦合度的中文分词交叉歧义处理方法[J]. 中文信息学报,2007,21(5): 14-17.
[11] 冯素琴,陈惠明. 基于语境信息的汉语组合型歧义消歧方法[J]. 中文信息学报,2007,21(6): 13-16.
[12] 乔维,孙茂松. 汉语交集型歧义切分字段关于专业领域的统计特性[J]. 中文信息学报,2008,22(4): 10-18.
[13] 任惠,林鸿飞,杨志豪. 融合字特征的平滑最大熵模型消解交集型歧义[J]. 中文信息学报,2010,24(4): 18-24.
[14] 周依欣,吴蔚天. 汉英机译研究(二): 一种实用的汉语切分方法—链接表法[J]. 中文信息学报,1990,4(2): 34-41.
[15] 徐秉铮,詹剑,贺前华. 基于神经网络的分词方法[J]. 中文信息学报,1993,7(2): 36-44.
[16] 赵铁军,吕雅娟,于浩,等. 提高汉语自动分词精度的多步处理策略[J]. 中文信息学报,2001,15(1): 13-18.
[17] 李玉梅,陈晓,姜自霞,等. 分词规范亟需补充的三方面内容[J]. 中文信息学报,2007,21(5): 3-7.
[18] 张顺昌,孙乐. 音字转换中分层解码模型的研究与改进[J]. 中文信息学报,2009,23(6): 79-85.
[19] 冯志伟. 中文科技术语的结构描述及潜在歧义[J]. 中文信息学报,1989,3(2): 3-18.
[20] 冯志伟. 中文科技术语中的歧义结构及其判定方法[J]. 中文信息学报,1989,3(3): 12-27.
[21] 孙茂松,黄昌宁. 汉语中的兼类词、同形词类组及其处理策略[J]. 中文信息学报,1989,3(4): 11-23.
[22] 邰晓英,童兆页. 限制汉语语法分析中歧义性的启发式方法[J]. 中文信息学报,1993,7(4): 10-17.
[23] 冯志伟. 论歧义结构的潜在性[J]. 中文信息学报,1995,9(4): 14-24.
[24] 孙健,张尧,王启祥. 汉语受限语言的设计与应用[J]. 中文信息学报,1997,11(3): 41-50.
[25] 苑春法,黄锦辉,李文捷. 基于语义知识的汉语句法结构排歧[J]. 中文信息学报,1999,13(1): 1-8.
[26] 詹卫东,常宝宝,俞士汶. 汉语短语结构定界歧义类型分析及分布统计[J]. 中文信息学报,1999,13(3): 9-17.
[27] 杨晓峰,李堂秋,洪青阳. 基于实例的汉语句法结构分析歧义消解[J]. 中文信息学报,2001,15(3): 22-28.
[28] 张克亮. 基于HNC理论的句法结构歧义消解[J]. 中文信息学报,2004,18(6): 43-52.
[29] 刘蓓,杜利民. 汉语口语对话系统中语义分析的消歧策略[J]. 中文信息学报,2005,19(1): 76-83.
[30] 王锦,陈群秀. 现代汉语语义资源用于短语歧义模式消歧研究[J]. 中文信息学报,2007,21(5): 80-86.
[31] 董强,郝长伶,董振东. 基于知网的中文结构排歧工具——VXY[J]. 中文信息学报,2010,24(1): 60-64.
[32] 周强. 汉语短语的自动划分和标注[J]. 中文信息学报,1997,11(1): 1-10.
[33] 刘颖. 句法评分和语义评分[J]. 中文信息学报,2000,14(4): 17-24.
[34] 苑春法,陈刚,黄昌宁. 基于词性和语义知识的汉语句法规则学习[J]. 中文信息学报,2001,15(3): 1-8.
[35] 王永生,柴佩琪,卫蔚. 德汉机器翻译中的语义消歧策略[J]. 中文信息学报,1998,12(2): 54-62.
[36] 李涓子,黄昌宁,杨尔弘. 一种自组织的汉语词义排歧方法[J]. 中文信息学报,1999,13(3): 1-8.
[37] 郑杰,茅于杭,董清富. 基于语境的语义排歧方法[J]. 中文信息学报,2000,14(5): 1-7.
[38] 全昌勤,何婷婷,姬东鸿,等. 从搭配知识获取最优种子的词义消歧方法[J]. 中文信息学报,2005,19(1): 30-35.
[39] 陈浩,何婷婷,姬东鸿. 基于k-means聚类的无导词义消歧[J]. 中文信息学报,2005,19(4): 10-16.
[40] 刘冬明,杨尔弘,方莹. 汉英双语平行语料库的词义标注[J]. 中文信息学报,2005,19(6): 50-56.
[41] 刘风成,黄德根,姜鹏. 基于AdaBoost.MH算法的汉语多义词消歧[J]. 中文信息学报,2006,20(3): 6-13.
[42] 吴云芳,金澎,郭涛. 基于词典属性特征的粗粒度词义消歧[J]. 中文信息学报,2007,21(2): 3-8.
[43] 郭宇航,车万翔,刘挺. 基于语言模型验证的词义消歧语料获取[J]. 中文信息学报,2008,22(6): 38-42.
[44] 车超,滕弘飞. 伪实例与人工标注实例相结合的词义消歧方法[J]. 中文信息学报,2009,23(6): 31-38.
[45] 高维君,姚天顺,黎邦洋,等. 机器学习在汉语关联词语识别中的应用[J]. 中文信息学报,2000,14(3): 1-8.
[46] 杨尔弘,郝秀兰,李盛. 基于粗集的汉语词语义项知识的获取[J]. 中文信息学报,2002,16(3): 27-33.
[47] 柯淑津. 以词汇知识驱动的词网自动对映[J]. 中文信息学报,2002,16(4): 32-38.
[48] 金澎,吴云芳,俞士汶. 词义标注语料库建设综述[J]. 中文信息学报,2008,22(3): 16-23.
[49] 赵军. 命名实体识别,排歧和跨语言关联[J]. 中文信息学报,2009,23(2): 3-17.
[50] 王石,曹存根. WNCT: 一种WordNet概念自动翻译方法[J]. 中文信息学报,2009,23(4): 63-70.
[51] 朱虹,刘扬,俞士汶. 汉语形容词的自动词义区分研究[J]. 中文信息学报,2009,23(6): 19-25.
[52] 乔剑敏,张仰森. 词义标注一致性检验系统的设计与实现[J]. 中文信息学报,2010,14(4): 44-51.
[53] 周强. 规则和统计相结合的汉语词类标注方法[J]. 中文信息学报,1995,9(3): 1-10.
[54] 冯志伟. 英日机器翻译系统E-to-J原语分析中的兼类词消歧策略[J]. 中文信息学报,1999,13(5): 14-27.
[55] 钱揖丽,郑家恒. 汉语语料词性标注自动校对方法的研究[J]. 中文信息学报,2004,18(2): 30-35.
[56] 蔡京哲,崔荣一. 线性化朝鲜文字的歧义性研究[J]. 中文信息学报,2008,22(5): 121-128.
[57] 于中华,陈蓉,胡俊锋,等. 基于加权投票K-近邻法的生物医学缩略语消歧[J]. 中文信息学报,2008,22(2): 18-23.
[58] 万建成. 语音代码—汉字智能转换研究[J]. 中文信息学报,1994,6(2): 61-72.
[59] 王晓龙,王幼龙. 语句级汉字输入技术[J]. 中文信息学报,1996,8(4): 50-59.
[60] 张昱琪,周强. 汉语基本短语的自动识别[J]. 中文信息学报,2002,16(6): 1-8.
[61] 王振华,孔祥龙,陆汝占,等. 结合决策树方法的中文姓名识别[J]. 中文信息学报,2004,18(6): 10-15.
[62] 王立霞,孙宏林. 现代汉语介词短语边界识别研究[J]. 中文信息学报,2005,19(3): 80-86.
[63] 贾玉祥,黄德智,刘武,等. 中文语音合成中的文本正则化研究[J]. 中文信息学报,2008,22(5): 45-50.
[64] 肖桐,李天宁,陈如山,等. 面向统计机器翻译的重对齐方法研究[J]. 中文信息学报,2010,24(1): 110-116.
[65] 俞士汶. 自然语言的歧义与机器翻译对策[J]. 中文信息学报,1989,3(3): 59-66.
[66] 杨莹,李应潭. 基于意象知识的消歧体系[J]. 中文信息学报,1993,7(1): 40-47.
[67] 钱树人. 歧义、系统歧义和语境[J]. 中文信息学报,1993,7(2): 18-26.
[68] 刘颖. 健壮性学习算法[J]. 中文信息学报,2001,15(4): 1-6.
[69] 李济洪,高亚慧,王瑞波,等. 汉语框架自动识别中的歧义消解[J]. 中文信息学报,2011,25(3): 38-44.
[70] 时迎超,王会珍,肖桐,等. 面向人名消歧任务的人名识别系统[J]. 中文信息学报,2011,25(3): 17-22.
[71] 切词规则[DB/OL]. 香港城市大学语言资讯科学研究中心,2005. http://sighan.CS.uchicago.edu/
[72] 张禄彭. 面向自然语言处理的歧义概念[J]. 解放军外国语学院学报,2007(5): 48-53.
[73] 张禄彭. 计算语言学视野下的俄语潜在歧义问题研究[D]. 解放军外国语学院,2008.
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
中国外汇(2019年12期)2019-10-10 07:26:58
中文信息学报(2019年2期)2019-04-02 03:08:28
中文信息学报(2018年2期)2018-04-16 07:53:36
电脑与电信(2018年12期)2018-03-23 02:37:20
疯狂英语·新悦读(2017年2期)2017-04-08 01:31:27
海南师范大学学报(社会科学版)(2015年7期)2015-12-28 08:17:40
中文信息学报(2012年4期)2012-06-29 06:29:14
当代修辞学(2011年3期)2011-01-23 06:40:16
