
基于非完备信息系统的评价对象情感聚类
2012-06-29 06:29王素格尹学倩吕云云
中文信息学报 2012年4期
王素格,尹学倩,李 茹,张 杰,吕云云
(1. 山西大学 计算机与信息技术学院, 山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室, 山西 太原 030006;3. 山西大学 数学科学学院, 山西 太原 030006)
1 引言
随着计算机技术、网络技术和通信技术的迅猛发展,网络已成为企业与消费者进行信息发布、信息传播、信息沟通的重要途径与平台。对于知名企业不再担心别人不了解自己,真正担心的是自己不了解“别人”,例如,用户“如何看待自己的产品”,迫切地想知道自己企业产品与其他同类产品用户的反馈信息。而作为普通消费者,在购买产品之前,往往倾向于在网上查询该产品的相关评论,尤其是同类产品的评论,但用户没有足够的时间和精力浏览大量的信息,因此,若想通过与其他产品的对比后再做出最终决策是比较困难的事情。然而,互联网上的信息聚集效应(涌现效应)使得人们更乐于在一个大的交流群体中发表观点和意见,大量的产品评论分布在同类产品的论坛、聊吧等,更为重要的是论坛、聊吧中的评论信息更为真实。如何有效地自动地对带有情感色彩的主观性文本进行分析、处理、归纳和推理[1],发现和概括相关产品的观点就变得非常重要。
目前, 大多研究者只针对某类产品评论判断一篇文档(句子)所表达产品的整体倾向[2-7],然而,无论是文档级还是句子(或子句)级,均以产品包含的特征及其评价词的倾向作为依据,用于计算文档或者句子(或子句)的情感倾向值。在实际产品评论中,一种产品可能涉及多篇文档。如果仅从文档级或句子级进行情感倾向判别,均不能获得人们对产品的多个不同品牌在其性能方面的综合评价。如何在某类产品的性能方面对多个产品品牌即评价对象进行聚类,以获得评价对象的等级,有关这方面的研究目前还没有看到相关报道。
一般作者在撰写产品的各性能方面的评论时所使用的评价对象、评价特征以及观点词等词汇与产品所在的领域知识密切相关。因此,本文利用已建立的领域本体,按照产品性能抽取含有评价特征以及观点词的句子。通过对评价同一对象的句子进行汇总,按其特征及其观点词进行整合与表示,使得每个产品性能构建一个具有情感特征值的非完备信息系统[8]。为了完成评价对象的情感聚类,采用基于差别矩阵的特征约简算法,去掉那些区分能力差且特征值稀疏度高的特征,从而获得各性能方面的新表示,以提高评价对象的相似性。本文利用K-means聚类算法实现对产品的评价对象的情感聚类,并在汽车评论文本数据上进行实验,实验结果表明,本文提出的方法提高了评价对象聚类的效果。
2 基于本体的句子抽取与表示
2.1 基于本体的句子抽取
本文假定一篇文本只针对一个评价对象的多个性能进行评价,而一个评价对象又涉及多个评论文本。文献[9]已建立了面向汽车领域观点挖掘的本体库,该本体库包含汽车的评价体系、词汇知识库以及概念间的关系,其详细介绍见文献[9]。根据文献[9]已建立的汽车领域本体知识库,基于本体的句子抽取过程如下:
(1) 抽取性能Pi(i=1,2,…)对应评价对象Oj(包含评价特征、观点词)(j=1,2,…)的所有句子;
(2) 句子预处理。将(1)中抽取的句子sentencek(k=1,2,…)进行中文分词、去除停用词;
(3) 利用文献[10]对句子sentencek(k=1,2,…)进行情感倾向判断,并进行人工校对。
2.2 基于本体的评价对象及特征整合
利用本体知识库中评价对象之间以及评价特征之间的关系,对评价对象对应的句子与评价特征进行整合。
(1) 句子合并。将具有概念之间的继承关系的评价对象所对应的句子进行合并。例如,“宝马320i”继承了“宝马3系”的性能优劣程度,因此假定评价对象“宝马320i”和“宝马3系”具有共指关系,将评价“宝马320i”的所有句子合并到评价“宝马3系”中。
(2) 评价特征共指消解。将具有下列关系的评价特征进行共指消解,将其视为同一评价特征。
① 具有传递性的整体与部分关系的评价特征。例如,“车载Mp3”就是“音响设备”的一部分。
② 实例与概念之间的关系。例如,“DSG变速箱”是“变速箱”的一个实例。
③ 某个概念是另一个概念属性的从属关系。例如,“发动机参数”是“发动机”的一个属性。
3 非完备情感信息系统的特征降维
由于网络上的产品评论语言表达具有非规范性、丰富性和多样性等特点,因此,在对产品性能方面进行数据表示时, 会存在特征值缺失,导致评价对象的特征有较高的冗余度、较差的类别区分度。若在高维特征空间中对评价对象进行聚类,不仅会增加聚类的时间复杂度,而且影响评价对象间相似性,降低评价对象聚类的性能。为了减少各性能方面的评价对象的特征维数,本文利用特征间类别区分能力,设计基于启发式的差别矩阵特征约简的特征降维方法。
3.1 非完备情感信息系统的建立
利用评价对象对应的句子集,以本体中的性能方面对应的特征为对象属性,分别建立产品各性能的非完备的情感信息系统。
设产品的r个性能方面的非完备情感信息系统分别为Si(i=1,2,…,r),它们是由四元组构成。设四元组Si={Ui,Ti,Vi,Wi(d)},这里的每一个元素所表示的意义如下:
Ui={d1,d2,…,dn}为论域,dk为产品第i个性能方面的第k个评价对象对应的句子集,k=1,2,…,n,n为评论文本中包含的评价对象总数。
Ti={ti1,ti2,…,timi}为特征集,tij为产品第i个性能方面所包含的第j个特征。j=1,…,mi,mi为产品第i个性能方面所包含的特征总数。
Wi(dk)=(w(tk1),…,w(tkj),…,w(tkmi)),w(tkj)为产品第i个性能方面的第k个评价对象对应句子集dk中第j个特征tkj的特征值函数。由于w(tkj)中有缺省值,因此,每个性能方面将得到非完备信息系统Si[10]。
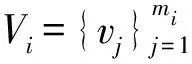
3.2 基于评价特征情感倾向的特征值计算
对于评价特征的情感倾向,不仅与自身特征的情感倾向有关,还与特征所在的上下文有关[11],例如,“变速器档位清晰,但换档时,比较费力,有些生涩感。”句子中的评价特征为“变速器档位”,评价词为“清晰”,特征自身的倾向为正面。但是由于受句子中转折词“但”的影响,该句子的整体倾向应为反面,在这情况下,应将评价特征的正面情感倾向值减弱。另外,对于评价特征在评论文本中出现多次时,应对其规范化处理。因此,定义特征如下。
定义1: 非完备情感信息系统中评价特征tkj的值w(tkj)如式(1)所示。
这里的N为特征tkj出现的频次,sq表示包含特征tkj的第q个句子,SOSq(tkj)表示特征tkj在句子sq中的倾向,comp(tkj,sq)表示句子sq倾向弱化特征tkj倾向的程度,其度量值用式(2)计算:
这里α∈(0,1),本文取α=0.5。

3.3 基于差别矩阵启发式特征约简算法
基于差别矩阵的特征约简算法被认为是一种有效的特征约简方法[12]。对于非完备信息表S′={U,T′,V′,W′(d)},|U|=n。为了约简非完备情感信息系统中的特征,需对特征的特征值进行离散化处理。本文采用边界点,将特征值划分为五个等级。


信息表S′的核CORE(T′)={t′|t′∈T′∧cij={t′}},即为Mn×n中所有单个属性元素组成的集合。
本文利用特征在文本中出现次数,启发式差别矩阵属性约简算法具体描述如下:
输入: 非完备信息表S′={U,T′,V′,W′(d)}
输出:S′的特征约简集合A
Step 1: 计算S′的差别矩阵Mn×n=(cij)n×n;
Step 2: 计算S′的核CORE(T′),A=CORE(T′);
Step 3: ∀cij∈Mn×n,如果cij∩A≠∅,则,令cij=∅;
Step 4: ∀cij∈Mn×n,如果cij=∅,则,转Step 6;
Step 5: 统计当前Mn×n中每个特征出现的次数,选择出现次数最多的特征t′,令A=A∪{t′},转Step 3;
Step 6: 输出A。
4 评价对象的情感聚类过程
为了获得评价对象的聚集结果,其聚类详细过程如下。
(1) 基于本体的句子抽取。
利用2.1节的句子抽取过程,从句子层面获得评论文本中经过分词、情感类别标注后的所有句子SentenceSet;
(2) 评价对象相关句子汇总、整合以及数值化表示。
这一过程从SentenceSet中,将有关产品每个性能方面评价同一对象的句子进行汇总,得到其句子集。例如,得到第i个性能方面的第k个评价对象对应的句子集记dik,相当于将评价同一个对象的句子集构成一篇新的文档,该文档只包含用户对某个评价对象在某个性能方面的评价。每个特征值计算采用第3.2节中的式(1)。再通过第2.2节的基于本体的特征合并,得到合并后的特征集,其特征的权重采用式(3)。
(3) 非完备信息系统的建立及特征降维。采用第3.1节和第3.2节建立的产品各性能的非完备的情感信息系统,采用启发式差别矩阵的特征约简方法,获得特征的约简,利用约简后的特征对各性能方面的评价对象重新表示,并恢复约简后的各特征的数值化权重,对特征的缺省值权重均赋予0值,将非完备情感信息系统完备化。
(4) 利用K-Means聚类算法[13]对各性能方面的非完备信息系统的评价对象进行聚类。
在利用K-Means聚类算法聚类时,其距离度量采用欧氏距离。
(5) 输出各性能方面的评价对象聚类结果。
5 实验结果与分析
5.1 实验数据
本文实验数据来源于太平洋汽车网 (http://www.pcauto.com.cn/)的13个厂商的68个车系的汽车评论。样本总量为742篇,7 960条句子,通过预处理得到“评价特征—观点词”评价搭配285个。根据国内首个指导消费者理性购车的指标体系——“消费者轿车产品价值评价体系”(http://www.bitauto.com/topic/pinggu/index.html),将汽车的性能分为安全性、操控性、动力性、服务性、经济性、舒适性六个方面,各性能所包含的原始特征数分别为: 安全性25个、操控性42个、动力性48个、服务性23个、经济性13个、舒适性134个。
5.2 评价指标
为了验证本文方法的有效性,从特征降维效果和聚类质量两个方面进行检验。
(1) 特征降维效果
特征的降维效果从约简率(Reduction Ratio)、稀疏度和系统运算时间这三个指标来体现。
约简率=(1-N′/N)×100%,N为原始特征数量,N′为约简后剩余的特征数。约简率用来验证特征的约简能力。约简率越高,约简的能力越强;反之,约简的能力越弱。
稀疏度指不包含数据的多维结构单元(缺省值)的相对百分比。稀疏度越高,则系统所包含的有效信息越少。它用来验证约简后数据稀疏度的改善效果。
运行时间指聚类算法的运行时间,用来验证聚类的运算效率。
(2) 聚类质量
本文采用两个常用指标纯度和F值[13]。
5.3 实验结果及讨论
利用第四节中的评价对象聚类过程,采用K-Means算法[18]对5.1节的数据中的评价对象(车系)进行聚类。为描述方便,我们将安全性、操控性、动力性、服务性、经济性、舒适性六种性能的非完备信息系统依次记为S1,S2,…,S6。为了说明本文特征降维的有效性,采用另一种特征降维的方法浅层语义分析LSA作为与其比较实验。设计三个实验如下。
Exp1: 利用第三节的特征降维方法进行特征降维后,再对评价对象(车系)聚类。
Exp2: 利用本体整合后的特征作为非完备信息系统的特征,直接对评价对象(车系)聚类。
Exp3: 对于本体整合后的特征,利用LSA进行特征降维,再对评价对象(车系)聚类。降维后的语义块数r选取Exp2中约简后的特征维数值。
为了验证聚类后的结果,我们对所有车系的六种性能采用三个人进行人工打分,取其平均值作为用户实际评级。分为三类: 差、一般、好。在利用K-Means算法时,类别数也选取k=3。
(1) 特征降维效果
为了说明本文方法特征降维的效果,从特征约简率、稀疏度与运算时间进行验证。通过特征降维后,六种非完备信息系统的降维结果如表1和表2所示。

表1 Exp 1中六种非完备信息系统中特征约简后的特征数和约简率

表2 Exp1和Exp2中六种非完备信息系统的聚类运行时间和稀疏度
① 由表1可知,各性能方面的约简率不尽相同,例如,S5即“经济性”约简前后没有太大的变化,仅去掉五个特征,这主要是因为经实验统计,人们对经济性的关注度较低,描述的语言词汇也较少,所用来描述的特征主要集中在“性价比”和“燃油经济性”这一类词汇上,极少有人评价其他方面,例如,“GPS导航”。而S6即“舒适性”,其约简率高达69.2%,说明评论者对产品的舒适性方面评论时所用的语言表达较为丰富,而且关注度较高。
② 由于K-Means算法的时间复杂度是O(m×n×k×t),其中n表示所有车系的个数,k是簇的数目,t是迭代次数,m是特征的个数。因此,特征的数量一定程度上会影响到聚类算法的运算效率。由表2可以看出,经过降维处理后,随着约简率增大,Exp 1的运算时间明显低于Exp2,约简后特征数量的减少一定程度上提高了运算效率。
③ 由于基于差别矩阵的非完备信息表特征约简过程中,只考虑特征的区分能力和特征的冗余度,并没有考虑评价对象在特征表示下的稀疏度。因此,特征降维与数据稀疏度并不一定成正比,例如,对于S6即“舒适性”,由表1可以看出,特征降维后约简率是最高的,但稀疏度却不是降低最多的,其原因可能会将稀疏度低但区分能力差的特征约简掉(例如,“车身外形”),而保留稀疏度较高但区分能力好的特征(例如,“座椅舒适性”)。
(2) 三个实验的纯度和F值,如表3所示。

表3 Exp1-Exp3中六种非完备信息系统的聚类纯度和F1值
由表3可以看出以下三点。
① Exp1和Exp3的聚类纯度和F值均高于Exp2,说明经过特征降维,可以提高评价对象的聚类性能。
② 通过对评价对象聚类,可以得到和普通用户认知基本一致的结果。例如,在“安全性”评价指标下聚类结果为“好”的车系,它们分别为,“宝马3系”、“宝马7系”、“宝马X5”、“本田奥德赛”、“本田雅阁”、“奥迪A6L”、“奇瑞A3”、“上海通用君威”、“一汽宝来”、“一汽丰田锐志”、“一汽丰田威驰”、“一汽大众高尔夫”、“一汽大众速腾”。说明在对没有先验类别的评价对象进行评价时,采用聚类方法,可以得到其相应的等级类别。
③ Exp1和Exp3的实验结果相比,利用LSA特征降维在有些性能方面的评价对象聚类结果会比本文提出的方法略好些,但LSA特征降维可使特征空间发生变化,导致其特征无法解释。
6 总结与展望
本文从句子层面出发对评价对象进行汇总,构成产品性能方面的评论句子集,利用聚类方法对句子级中评价对象进行聚类,得到在各性能方面的评价对象聚类等级。为了提高评价对象的聚类效果,利用数据的类别区分能力,应用基于差别矩阵的非完备信息系统特征约简技术在降低了数据的冗余度和数据的稀疏度的同时,提高了K-Means聚类运行效率。例如,从“操控性”性能方面的非完备信息系统的实验结果中可以看出,通过降维,运行时间比降维前减少了41.38%,稀疏度降低了15.69%,聚类的纯度和F值都均有所提高。
从具体实验过程中发现,虽然本文特征降维方法在一定程度上可以减少数据的冗余和数据的稀疏度,但数据的缺失却来源于初始抽取的特征,而这些特征仅依赖与已建立的本体知识库。因此,下一步应对动态的特征抽取方法进行深入的研究,以获得更为符合本项研究需求的动态特征。
[1] B.Liu. Sentiment analysis and subjectivity[M]. Handbook of Natural Language Processing, Second Edition. 2010.
[2] B.Pang, L.Lee, S.Vaithyanathan. Thumbs up? Sentiment classification using machine learning techniques[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2002:79-86
[3] D.Turney Peter, L.Littman Michael. Measuring praise and criticism: inference of semantic orientation from association[J], ACM Transactions on Information Systems, 2003,21(4): 315-346.
[4] B.Pang, L.Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales[C]//Proceedings of the Association for Computational Linguistics (ACL), 2005:115-124.
[5] A.M.Popescu, O.Etzioni. Extracting product features and opinions from reviews[C]//Proceedings of the Human Language Technology Conference and the Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP).2005.
[6] X.Ding, B.Liu, P.S.Yu. A holistic lexicon-based approach to opinion mining[C]//Proceedings of the Conference on Web Search and Web Data Mining (WSDM).2008.
[7] M.Hu, B.Liu. Mining and summarizing customer reviews[C]//Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2004:168-177.
[8] 张文修,吴伟志,梁吉业,等. 粗糙集理论与方法[M]. 北京:科学出版社. 2001:206-213.
[9] 冯淑芳,王素格. 面向观点挖掘的汽车本体知识库的构建[J]. 计算机应用与软件, 2011,28(5):45-47.
[10] 王素格,杨安娜,李德玉. 基于汉语情感词表的句子情感倾向分类研究[J]. 计算机工程与应用,2009,45(24):153-155,161
[11] L.Polanyi, A.Zaenen. Contextual lexical valence shifters[C]//Proceedings of the AAAI Spring Symposium on Exploring Attitude and Affect in Text. 2004.
[12] 王加阳,高灿. 改进的基于差别矩阵的属性约简算法[J]. 计算机工程,2009,35(3): 66-67, 73.
[13] 刘远超,王晓龙,徐志明,等. 文档聚类综述[J]. 中文信息学报, 2006,20(3):55-62.
猜你喜欢
车主之友(2022年4期)2022-08-27
哈尔滨轴承(2022年1期)2022-05-23
世界科学技术-中医药现代化(2021年8期)2021-12-21
海峡姐妹(2019年12期)2020-01-14
电子制作(2018年11期)2018-08-04
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
消费导刊(2017年20期)2018-01-03
智能系统学报(2017年3期)2017-08-01
现代计算机(2016年11期)2016-02-28
