
采用数据挖掘的自动化推荐技术的研究
2012-06-29 06:29:18陈庆章汤仲喆裴玉洁
中文信息学报 2012年4期
陈庆章, 汤仲喆,王 凯,姚 敏,裴玉洁
(浙江工业大学 计算机科学与技术学院, 浙江 杭州 310023)
1 绪论
随着网络中信息量的迅速增长,信息种类也日趋繁多,用户通过互联网要获得自己感兴趣的资料需要花费越来越多的时间。由此催生了信息推荐系统。信息推荐系统的基本作用是依据用户曾经的访问记录,分析用户的喜好,然后当用户登录网上应用系统时,推荐适合用户喜好的资料给用户,供用户选择。从而节省用户检索信息的时间。
鉴于推荐系统(Recommender System)[1-2]能满足用户个性化的需求,节省用户搜寻信息的时间,同时可以帮用户及时获得最新与自己喜好相关的信息,它已被广泛的应用于电子商务网站[3-7]中。
1.1 网上推荐系统研究现状
网上推荐系统的主要推荐技术可分为: 非个性化的推荐技术(Non-Personalized Recommendation)、基于属性的推荐技术(Attribute-based Recommendation)、物品关联式推荐技术 (Item-to-Item Correlation)和人物关联式推荐技术(People-to-People Correlation)。推荐技术的主要推荐方式分为基于内容的过滤方式(Content-Based Filtering)和合作过滤方式(Collaborative Filtering)。基于内容的过滤是利用信息与用户兴趣喜好的相似性来过滤信息。其优点是简单、有效,但是只能推荐用户以前看过或类似的信息,不能发掘新的用户感兴趣的信息。合作过滤方式是基于其他用户的选择将信息推荐给用户,其优点是能为读者发现新的感兴趣的信息,但也存在着许多问题,如早期评估者问题,稀疏问题和新近的项目的推荐问题等。已经有很多学者对推荐系统进行了研究,国内的推荐系统做的比较成功的网站有豆瓣、当当网、淘宝网和京东商城等。国外的典型研究成果有: 1998年Sarwar B.等人研究的GroupLens系统[6];1997年L. Terveen等人提出的PHOAKS系统[8]。
本论文研究的推荐系统采用个性化的推荐机制。首先应用人工神经网络技术产生用户群组,再利用数据挖掘技术从现成的网络交易数据库的交易数据中,挖掘出用户与项目之间以及项目与项目之间的关联法则,由此得出信息推荐规则,然后根据用户的输入信息,判断用户类型,最后返回推荐结果。其中,用户聚类采用人工神经网络技术的ART(Adaptive Resonance Theory)算法实现,国外学者对ART聚类算法的应用研究情况有: Massey, L.[9]提出运用ART聚类算法进行文档分类。2009年Bhupesh Gour和Sudhir Sharma等人[10]提出了将ART聚类算法运用到指纹识别系统。国内学者对ART聚类算法的应用研究情况有: 西安电子科技大学白琳[11]提出了基于ART聚类的入侵检测算法来解决网络安全问题。中国医科大学白英龙[12]和李春涛提出一种基于ART聚类算法的患者个性特征聚类模型。
1.2 现有ART算法的不足
目前被广泛用来进行用户聚类的ART算法主要存在着以下两方面的不足。
1. 属性向量“同或”状态的考虑问题

i=1,…,p
(1)
这种常规的相似度的计算,只考虑了“1”的作用,并未考虑外权向量中“0”的作用。但在实际运用中,0和1分别表示两种状态,在判断中都是有用的信息,是同等重要的。因此,这种方法有明显的不足之处。为解决这种不足,文中设计了一种新的相似度计算方法,同时考虑了“0”和“1”的状态,看Wt[i][j*]和x[i]对应位置上相同状态的个数,即Wt[i][j*]与x[i] “同或”值的个数。这种方法能够很准确地考虑两个向量中“同或”的状态,而不存在孰轻孰重的问题。
2. 输入属性的权重问题
在ART算法中应用的输入模式是多个属性的集合。并且这些属性均被转换成二进制数据进行处理。每个属性所占的位数都有可能影响到聚类的结果。因此,当一个属性的输入向量所占的位数值越大时,这个属性对聚类的结果影响便越大。从广义的角度来看,每个属性的重要性可能是不同的。为了处理在聚类过程中属性重要性的问题,ART算法也将进行相应的改进来调整输入属性的权重,以便得到更为合理和灵活的输出结果。
2 推荐机制总体框架

图1 在线自动化推荐机制的框架
关于在线自动推荐机制的框架如图1所示。这一框架结构依赖于运用ART神经网络技术预处理用户的个人资料,通过分析用户的个性化属性信息,分类所有在线用户,得出用户的类型信息,应用数据挖掘技术处理历史交易数据和用户类型,找出用户与选择的项目之间以及项目与项目之间的关联规则,并将其存入知识数据库。当一个用户在线发起一个服务请求时,系统会通过识别用户的类型信息找出适合该类型用户的相关规则,挖掘出用户的兴趣度信息,并将个性化的推荐信息展现给用户。该自动推荐机制的处理流程由两个阶段组成,即预处理阶段和在线阶段。
2.1 预处理阶段的设计
预处理阶段是分析用户信息,包括用户的属性和历史交易数据。由于从数据库提取的资料可能存有格式不相容的问题,因此必须做适当的处理。图2描述了预处理阶段的操作流程,处理步骤为: 步骤1选择相关用户数据,包括用户属性和历史交易数据信息;步骤2设计ART分类网络;步骤3输入实验值,得出分类结果;步骤4应用Apriori算法进行数据挖掘,整合ART分类结果和历史交易数据,计算出用户类型和项目之间,以及项目与项目之间的关系;步骤5创建关联规则知识库: 将数据挖掘的结果以规则的形式储存于知识库中。

图2 自动化推荐系统的预处理流程
2.2 在线阶段的设计
根据预处理过程,推荐的知识被储存在知识库中。只要用户在线输入所需的项目,ARS就会自动处理(图3)。处理流程如下: (1)ART根据用户的属性将用户进行归类;(2)系统根据用户的类型和所需的项目读取知识库;(3)结合关联规则,提取用于推荐的相关项目。
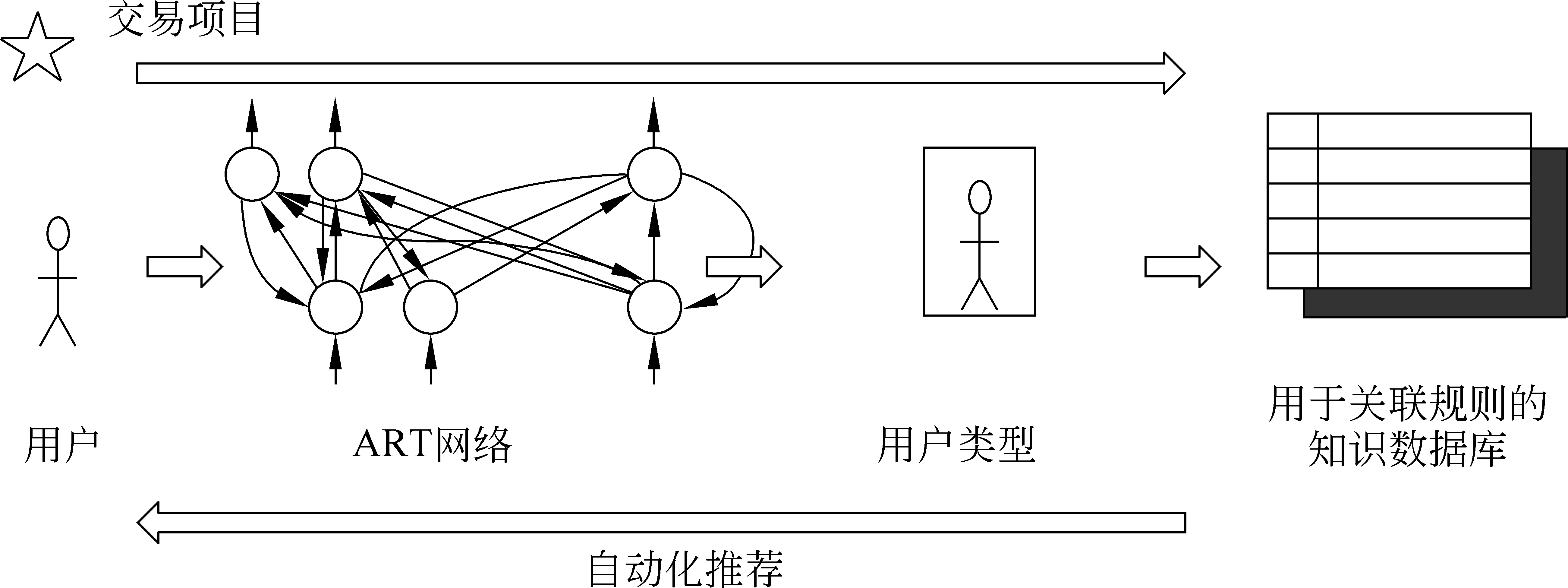
图3 自动化推荐系统的在线处理流程
ARS通过网络界面将项目推荐给用户。其中被推荐项目的数量由它们与关联规则的匹配情况决定。
2.3 应用ART网络进行聚类的设计
ART技术将用户划分为合适的聚类[13]。ART网络的结构有三个主要部件: 输入层、输出层和网络连接层。


(2)

(3)
(4)
Step 8执行警戒测试。(设r为警戒值,且r∈{0,1})如果Vj*小于预设值r,那么这个样品与输出类是不太相关的,接着进行下一个输出点的比较,转入步骤9。否则进入步骤10。Step 9测试是否存在另一个相似的输出集。(设Icount表示为已被使用的输出集个数,初始值为0.)如果Icount < Nout,计算出输入向量与剩余输出集的下一个最大匹配度net[j],令Icount = Icount+1,net[j*]=0, 转入步骤6. 否则,如果不存在其他的输出集用于测试,那么: (1)生成新的类,令Nout = Nout+1, 并创建新的连接权重。
(2) 设置输出值。如果j=j*, 那么Y[j]=1,(Y[j]表示输出向量,1≤i≤P)否则Y[j]=0;(3) 转入步骤4(输入一个新的向量X);Step 10如果Vj* >r,即境界测试通过,那么(1) 调整权重值
(2) 设置输出值: 如果j=j*, 那么Y[j]=1, 否则Y[j]=0;Step 11如果没有新的聚类生成且正好完成一个循环,则输出聚类结果。否则转入步骤4输入新向量X。
2.4 改进后的ART算法(MART)
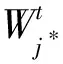

(7)
Mt[i]为输入属性的权重,即第i个节点重要性,其中Mt[i]∈R+。
新算法MART(Modified ART)的执行步骤与原算法类似,只是需要首先设置每一个节点(属性)的重要性,即Mt[i]。根据相似的用户属性,利用MART算法形成用户分组。这个结果可用于下一个挖掘过程中。
2.5 生成强关联规则
首先由Apriori算法得出频繁项集,再根据获得频繁项集产生强关联规则。其中可能产生的法则是X⟹Y,依此我们可以计算当X发生时,也发生Y的信任度,若是到达设定的最低信任度(Minimum Confidence Level),则此强关联规则就成立。而信任度的计算方法是:confidence(X⟹Y)=P(Y|X)=support(X∪Y)/support(X),其中X∩Y=φ具体过程为: 设每一个频繁项集由li表示,X是这个频繁项集的子集,其中(li-X)∩X=φ是指交易记录中包含项目X的次数,support(li)是指交易记录中包含li的次数,那么X⟹(li-X)的信任度为support(li)/support(X),若它的值大于或等于设定的最低信任度,则为强关联规则。以此类推,直到生成所有的强关联规则,即用户类型和项目之间以及项目与项目之间的推荐规则,并将它们存入知识库,用于之后系统的在线推荐阶段。
3 在线自动化推荐机制在图书推荐中的应用
3.1 实验环境
本实验虚拟了30个学生和49本图书,它们都是随机生成的,用于模拟图书馆的用户借阅记录。在试验中,我们选取了信息管理专业和计算机应用技术专业,作为该机制的研究对象。随机生成了120条历史借阅总记录,其中信息管理专业有63条记录,计算机应用技术专业有57条记录。该实例应用一共分为图书推荐预处理阶段和在线图书推荐阶段两部分。
3.2 图书推荐预处理阶段
(1) 设计ART网络的输入模式
为了应用本研究机制,我们需要先设计代表学生借阅习惯的输入向量。学生属性的二进制表示形式,即ART网络的输入模式定义如表1所示。

表1 ART网络的输入模式定义
定义好学生属性值之后,下一步就是将学生属性转换成二进制。输入模式(二进制向量)经过MART网络进行聚类处理,拥有相似图书借阅习惯的学生将会被自动划分到相同的聚类。这里我们将MART网络的警戒值分别设为0.1到0.9,各属性节点的权重值设为Mt[i]=[1,3,1,1,1,1],即“专业”在各个属性中占有更重要的地位,实验结果如表2 所示。
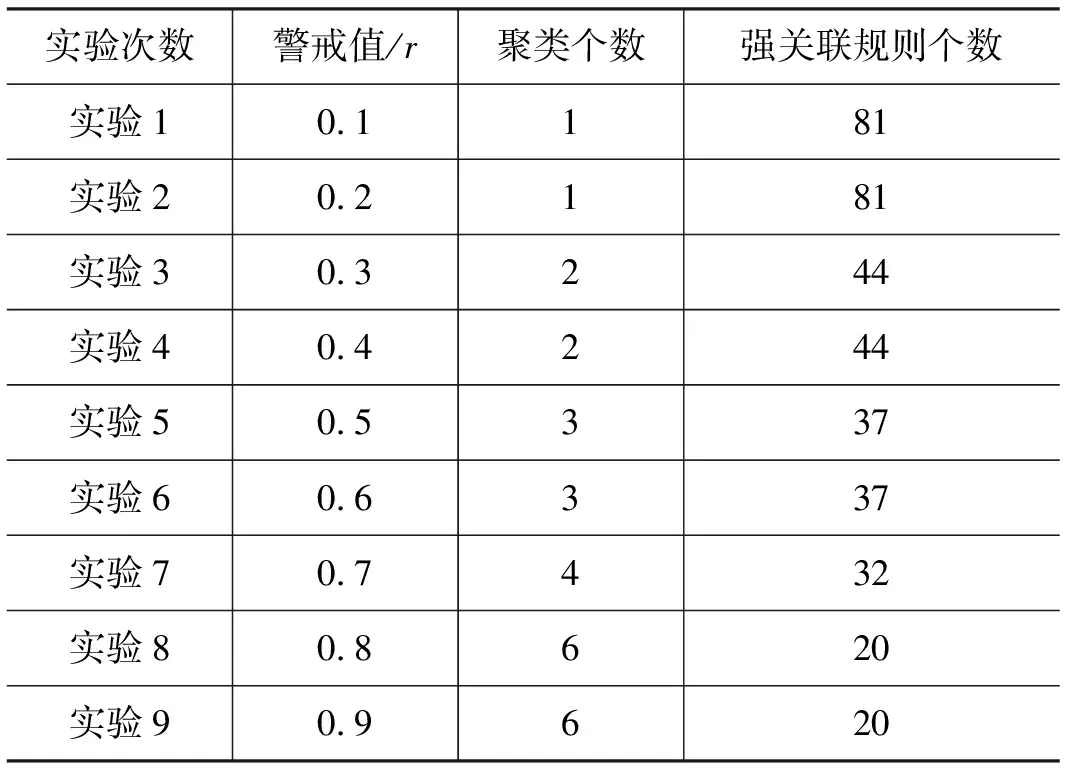
表2 不同警戒值下的实验结果
(2) 挖掘出关联规则并放入知识库中
通过MART网络得到聚类结果之后,将用户的类型信息和图书借阅记录一起输入到知识库中。Apriori算法通过调整支持度和信任度, 挖掘出学生用户类型和图书之间,以及图书与图书之间的关联规则, 生成强关联规则并将其存入知识库,图4给出了在最小支持度设为2,最小信任度设为0.5下的生成的关联规则。
3.2 在线图书推荐阶段
在ART网络生成学生聚类以及知识库信息建立之后,ARS的在线阶段就可以实现了。当一个学生使用在线ARS查找图书的时候,ARS将根据学生的属性或其输入的关键字判断用户类型,参考知识库中用户类型与图书之间以及图书与图书之间的关联规则,将与该类型用户相关联的图书推荐给该用户。
结合本实例应用中的例子,如图5所示,当一个学生在查询图书名含有“Tcp”的图书时,将会看到自动化推荐系统除了将含有“Tcp”的图书显示出来以外,还推荐了其他两本图书“解析极限编程”以及“D make me think”。
4 结论
本研究结合人工神经网络技术和数据挖掘技术,展示了一个个性化的自动化推荐机制。针对属性向量“同或”状态的考虑问题和属性的权重问题,对经典的ART算法进行优化,得到MART算法。并创建了一个以用户为导向的图书推荐系统,该系统首先运用MART算法产生用户聚类,由此得出每个用户的类型,再使用Apriori算法挖掘出用户类型与图书之间,以及图书与图书之间的强关联规则,即图书推荐规则,最后根据在线用户输入信息或用户类型信息,将适当的相关项目或信息推荐给用户。该图书推荐机制所具有的优势有: (1) 社群特征。运用ART 网络聚类用户社群,进而推荐适合每个社群的不同的图书信息; (2) 关联特征。利用数据挖掘中的Apriori 算法可发掘出用户社群与图书之间,以及图书与图书之间的强关联规则; (3) 用户分群效率高。当ART 网路聚类完毕后,在线系统能够将适当的信息推荐给用户,因此非常适合网络的动态变化和快速反应的环境。

图4 关联规则

图5 推荐结果界面
[1] Sarwar, B., Karypis, G., Konstan, J. et al. Analysis of Recommendation Algorithms for E-commerce [C]//ACM Conference on Electronic Commerce, 2000: 158-167.
[2] Yu, P. S.. Data Mining and Personalization Technologies [C]//Proceedings of the 6th International Conference on Database Systems for Advanced Applications, 1999: 6-13.
[3] AltaVista. http://www.altavista.digital.com, 2002[DB/OL].
[4] Amazon. http://www.amazon.com, 2002[DB/OL].
[5] Hill, W.C., Stead, L., Rosenstein, M., et al. Recommending and evaluating choices in a virtual community of use[C]//Proceedings of CHI’95, 1995: 194-201.
[6] Konstan, J., Miller, B., Maltz, D., et al. Group-Lens Applying Collaborative Filtering to Usenet News[C]//Proceedings of Communications of ACM, 1997, 40 (3): 77-87.
[7] Shardanand, U., Maes, P.. Social Information Filtering: Algorithms for Automating ‘Word of Mouth’ [C]//Proceedings of the Computer-Human Interaction Conference (CHI’95), 1995.
[8] Editmax. http://www.editmax.net/n1229c15.aspx, 2009[DB/OL].
[9] Louis Massey. On the quality of ART1 text clustering [J]. Neural Networks, 2003: 771-778.
[10] Bhupesh Gour, T. K. Bandopadhyaya, Sudhir Sharma. High Quality Cluster Generation of Feature Points of Fingerprint Using Neutral Network [J]. EuroJournals Publishing, 2009: 13-18.
[11] 白琳. 基于神经计算和进化网络的入侵检测[D]. 西安电子科技大学,2005.
[12] 白英龙,李春涛. 一种患者个性特征聚类模型的设计[J]. 中国全科医学,2007,10(23):2022-2023.
[13] 郑丽英.基于trie的关联规则发现算法[N].兰州理工大学学报,2004,30(5): 90-92.
猜你喜欢
当代陕西(2019年15期)2019-09-02 01:52:00
制造技术与机床(2019年6期)2019-06-25 10:17:46
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电子测试(2017年15期)2017-12-18 07:19:27
读者(2017年5期)2017-02-15 18:04:18
中国交通信息化(2016年9期)2016-06-06 07:42:23
智能系统学报(2015年4期)2015-12-27 09:38:39
图书馆研究(2015年5期)2015-12-07 04:05:48
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
