
文本处理中的MapReduce技术
2012-06-29 06:15李锐,王斌
中文信息学报 2012年4期
李 锐,王 斌
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院 研究生院,北京 100190)
1 引言
计算机诞生于20世纪40年代,从那时起,文本就起着非常重要的作用。文本是信息的主要载体之一,发展到信息“爆炸”的今天,文本处理越来越多地应用在超大规模的数据集上。传统的一些单机方法难以应付和处理T级别、P级别的海量数据,主要原因如下: 第一,从计算方法上来看,一些算法使用的是迭代的计算方法,以数据为代价来换取正确率和精确度的提升,例如,EM算法和一些用于机器学习采样或近似推断的方法等;第二,从模型方面来看,目前很多应用都基于统计模型,如统计语言模型(Statistical Language Model)、话题模型(Topic Model)等,而这些模型对数据量的要求也越来越大;第三,从真实的数据来看,网络上的文本规模也不断增长,网页数目每时每秒都在更新。即便是对学术界,对大数据量处理要求也越来越高,特别是超大数据集ClueWeb09*http://boston.lti.cs.cmu.edu/Data/clueweb09/等的发布,推动研究者更加认真地思考大规模数据的处理方案[1]。
一些出色的研究机构和业界在分布式的大背景下,提出了很多不同的方案来解决这个问题,都各有其优缺点: 并行数据库是一个发展很成熟的技术,拥有很多成功的商业实现: Teradata、Netezza、DataAllegro(Microsoft)、ParAccel、Greenplum、Aster、Vertica和DB2等[2]。但不足在于数据的读入花费的时间很长,不擅长半结构化数据或非结构化数据的处理, 架设和调优难度较大。PRAM(Parallel Random Access Machine)假设有无限容量的共享存储器,有多个功能相同的处理器,任意时刻可以访问共享存储单元。它的优点在于结构简单,便于分析优化;缺点在于无限容量的存储器目前并不存在,全局访存通常也比预想的慢。MPI是一个消息传递函数库的标准说明,吸取了众多消息传递系统的优点,是目前国际上最流行的并行编程环境之一,尤其是分布式的并行计算机和工作站网络以及机群的一种编程范例。MPI具有许多优点: 具有可移植性和易用性;有完备的异步通信功能;有正式和详细的精确定义。但也存在一些不足之处,例如,需要大量缓存(特别是大规模计算情况下)、异构计算编程困难、容错机制不强等。
网络上新数据的特点是半结构化数据增多,资源也具有异构性,NoSQL的兴起也说明了这一点。大量灵活的临时文本,使得并行数据库等传统方案的缺点逐渐地暴露了出来。因此产生了一些比较新的解决方案,例如,微软的Dryad[3]和Facebook的Cassandra*http://cassandra.apache.org/等。其中一个近几年提出的,很有代表性的工作是Google提出的MapReduce[4-5]。Map-Reduce设计初衷是采用普通的机器而无需超高性能的服务器,来分布式并行处理大规模的数据。由于它的形式简单,实现方便,得到了广泛的认可和使用。目前Google的集群上每天有100 000多Map-Reduce的jobs在执行。而Hadoop作为MapReduce的开源实现的典范,它也在Yahoo!之外的一些公司得到了广泛使用和研究。在Hadoop 2010大会上,Facebook对他们的“数据高速公路(Data Freeway)”,淘宝对他们的“云梯”做了报告,都在使用大规模的集群来做MapReduce运算,每天数据的吞吐量惊人。关于MapReduce具体的优缺点我们将在后面的篇幅介绍到。
本文后续内容组织如下: 第二节对MapReduce进行简单的介绍,并指出它的优缺点、主要思想和工作流程,还对一些容易混淆的相关术语做了解释;第三节整理和分析了MapReduce在文本处理各个方面的一些应用;第四节介绍MapReduce性能相关的工作和一些改进模型;第五节对本文进行总结和展望。
2 MapReduce介绍
MapReduce是一个用于大规模数据处理的编程模型和规范,它采用了分而治之的思想,基本形式有map和reduce两个处理阶段: 主要思路是将大规模数据处理任务分为很多子任务,并将子任务分配给若干个分布式的机器来并行完成批处理作业。其中map阶段是将原始的输入(一般是key/value对)转换成中间结果;而reduce阶段则将之前产生的中间结果合并,排序与输出。
MapReduce并非就分为map和reduce操作这么简单,一方面它其实有更详细的操作划分,例如,combine,shuffle和sort等;另一方面它为了实现大规模数据的并行和分布式处理做了精巧的封装。整个架构帮助使用者完成了很多棘手的工作,解决了一些诸如数据分割,时序安排,数据和代码的协同定位,进程同步通讯,容错和失效处理,负载均衡等问题[6],并且使得这些功能对开发者透明: 开发者只需要实现map和reduce等接口,不需要关注底层系统级的问题,就可以完成分布式集群上并行程序的开发。它也存在一些缺点: 启动消耗高,每次启动集群需要遍访网络中所有节点;磁盘随机访问效率低,MapReduce的分布式文件系统是顺序读取,按块存取的文件系统;同步机制是最棘手的问题,执行MapReduce任务时不支持全局数据的共享。在单个的MapReduce的作业中,只有shuffle和sort阶段会在集群范围内同步(也就是中间的键值对从mappers传递到reducers的时候)。除此之外,mappers和reducers独立运行,没有其他机制用来交互。但大规模数据背景下,这些缺点与应用相关,跟其优势相比是可以忍受的,而且可以通过各种优化方式来缓解或消除[1,6]。
2.1 相关术语
为了理解方便,下面列出有关MapReduce的文献中几个常用名词。
MapReduce: MapReduce可以看作三种不同但相关的概念,一可以看作是编程模型,二可以看作是运行框架,三可以看作是编程模型和运行框架的软件实现[6]。
Hadoop: Hadoop*http://hadoop.apache.org/是MapReduce的其中一个开源实现。它与其他的开源实现相比较为成熟,也得到了广泛的研究和使用,例如,Yahoo!、Facebook、Adobe和IBM等。Hadoop本身是java实现的,但通过其管道技术,可以调用其他语言编写的程序,如C++、Python、Perl等。
Google File System[4]: MapReduce使用的分布式文件系统,简称GFS。设计有一至数台机器来管理数据和分配任务,按一定的原则把任务分配给集群来进行并行计算。还负责一些数据存储工作,做了比较高层的抽象封装,提供了便利的数据访问和储存的API,为上层应用提供服务,例如,BigTable,HyperTable等。
HDFS: Hadoop的分布式文件系统。
虽然MapReduce最初是由Google提出的,但是由于未开放源码,所以之后的很多工作都基于Hadoop。目前Hadoop还分出了Hadoop Common,Chukwa,HBase,HDFS,Hive,MapReduce,Pig, ZooKeeper几个子项目进行开发,吸引了国内外同行的关注。
2.2 MapReduce工作流程
把一个MapReduce程序应用到一个数据集上,即是指一个作业(job)。作业一般由几个乃至成百上千个任务(task)组成。MapReduce分配任务的主控机器称为master,执行任务的机器称为worker(也可以将核的多线程,或者多核,多处理器或者集群看作是各个workers),在Hadoop里分别称为master和slave。从存储的角度来说又分为NameNode和DataNode。NameNode记录了分布式的文件块存放位置与状态等信息,而DataNode则负责存放真正的数据,一般情况下也是task的执行者。
在MapReduce默认设置下,文件按块存储在分布式文件系统上(其他系统参见2.3节),基本的工作流程: ①当一个作业被提交之后,根据文件块在分布式系统的分布情况,作业被分成若干个子任务task,交由很多mappers(执行map任务的worker)来处理。一般会把任务交给数据所在机器,或者同机架内的机器,提高处理速度,这也就是所谓的“代码找数据”的模式。②每个mappers执行在不同的文件块上,根据map函数执行程序,完成map阶段的功能。这个阶段是大规模并行执行的阶段;③map 完成后,框架会有一个shuffle和sort阶段,对mappers产生的数据进行分发和排序处理,以提供给下一阶段有序的数据,从而提高reduce效率;④reduce阶段,将之前的中间数据汇总,根据reduce函数合并输出[4-5]。以上整个过程如图1所示。
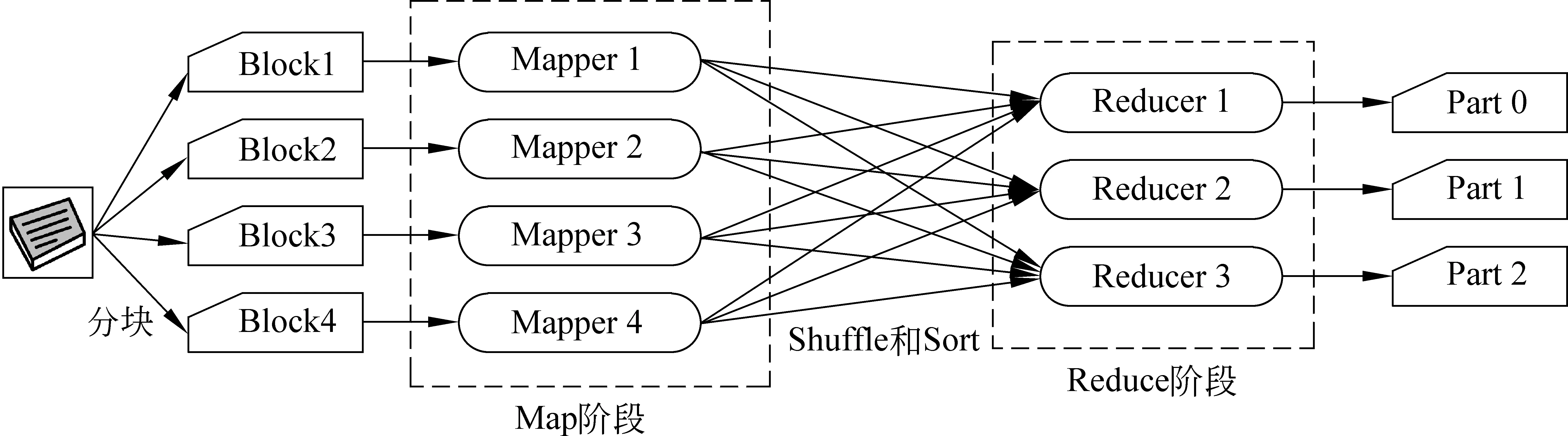
图1 MapReduce基本工作流程
我们看到整个流程中,用户仅实现map和reduce方法就可以保证架构运行。也就是只有②④阶段中使用到的两个函数需要用户指定,其他阶段由框架来完成。每个阶段,用户也可以实现自己的方法来重写和扩展自定义的功能,例如,分块阶段,用户可以自定义分块方法来取代默认分块方法,还可以对文件最后的存放形式进行调配。
2.3 MapReduce适合处理的问题
在信息检索领域很重要的一个问题: 搜索引擎要实现对Web网页的检索,后台需要对网络数据抓取, 然后建立索引。一般的方法是用专门的采集器把抓取的网页放进数据库,之后这些数据仅仅使用一次来建立倒排索引,索引后就丢弃抓来的网页,进行下一次抓取。此时数据库的录入操作在数据量很大的情况下将会很慢,而且采集数据只使用一次,因此效率比较低[5]。
传统的方法对此类数据的处理不擅长,特别是当数据仅使用一两次的时候,数据库并不实用。而MapReduce解决此类问题尤为出色,它省去了将数据全部读入的过程,直接处理抓下来的数据。因为读取数据进入并行数据库的时间很可能会远大于MapReduce对数据的处理时间。这在MapReduce的原作者Jeffery Dean 2010年的文献[5]里有更加详细的阐述。
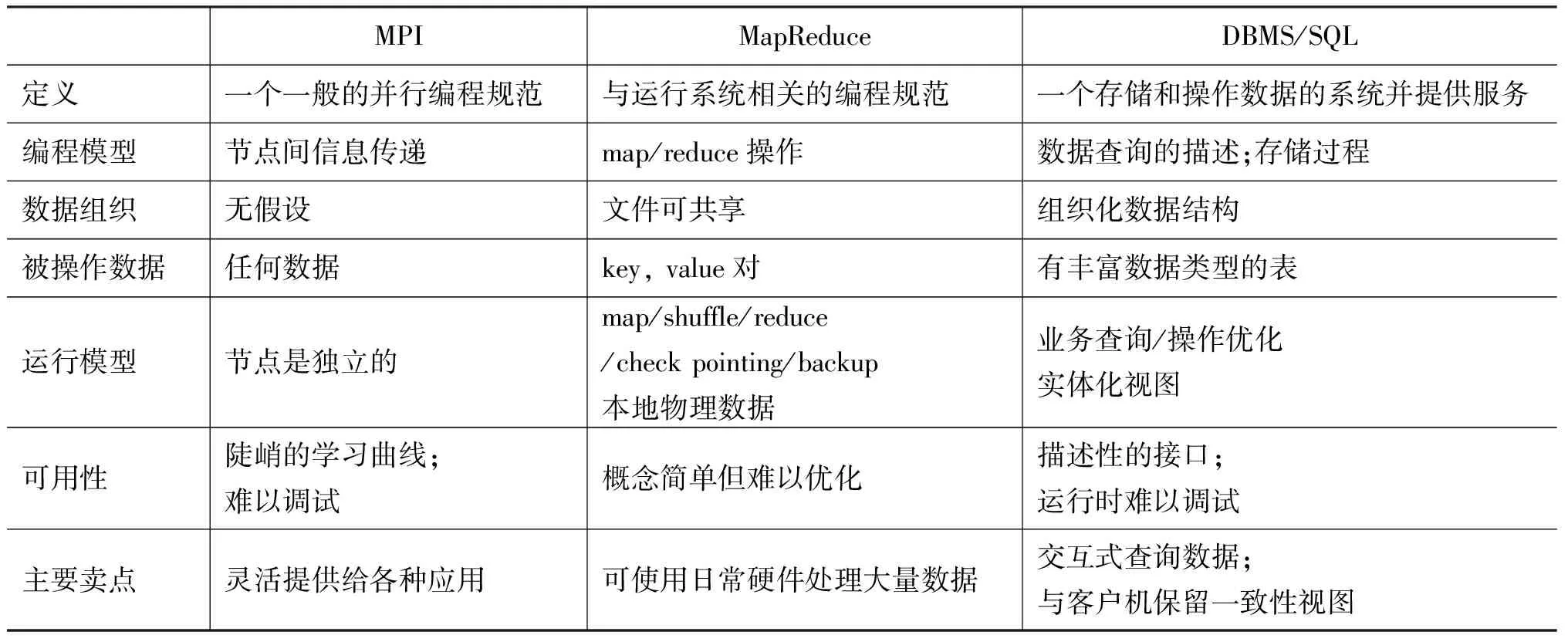
表1 MPI,MapReduce,SQL的对比
MapReduce从设计本身来说就非常适合处理。 一、规模大而逻辑上操作简单的数据。譬如一些大数据量的任务,很容易分为操作相同的子任务或者子模块;二、数据本身就存放在分布式的集群之上。譬如一些检索系统的日志,日志格式本身就已经按日期存放,分好了块;还有网页反向链接的建立。这种情况下,数据的输出也可以不需要合并,因为下一步也是MapReduce做;三、批处理的很少需要人工干预的工作。MapReduce的实质也还是将工作的并行化,因此一般说来,并行性较好的任务就比较适合使用MapReduce来处理。
通过扩展,MapReduce可以处理多种不同系统里存储的数据。终端用户可以写简单的reader和writer的接口实现与扩展MapReduce,从而支持新的存储系统。例如,分布式系统GFS,数据库查询结果集,BigTable数据和结构化数据B-tree等都可以作为数据来源直接操作[5]。Dean本人也分析了MPI,MapReduce,SQL的不同特点,为求表达Dean的原意,在此直接翻译后引用过来,如表1所示。
Michael StoneBraker等人在抨击过MapReduce是“巨大的倒退”之后,在文献[2]里也总结了MapReduce适合处理的问题: 抽取、转换和录入与读取“只读一次”的数据;复杂的数据分析;处理半结构化数据;快速分析有噪声的数据等。认为并行数据库很多方面很成熟,存在着明显的优势。MapReduce应该作为并行数据库的有益补充,而非竞争对手。正因为MapReduce与并行数据库各有优缺点,适合于不同的应用,所以像HadoopDB这样的混合型数据库也渐渐问世。
3 MapReduce与文本处理
MapReduce的特点,决定了它很适合在文本处理领域做各种应用。Jeffery Dean在2010年初的论文[5]里提到,当前Google开发的许多系统中都使用了批量的MapReduce作业来加快处理效率。这些作业主要包括Google的搜索,Google Earth和Google Maps等。而在学术界,关于MapReduce的研究更是层出不穷。下面从文本检索、自然语言处理和通用方法三个主要方面,来阐述一下MapReduce的应用情况。
3.1 文本检索
中国互联网信息中心(CNNIC)2010年度的《中国互联网络发展状况统计报告》指出,“搜索引擎使用率达到81.9%,用户规模达到3.75亿,成为网民第一大应用。”由此看来,文本检索的重要性也是越来越高。目前对文本的检索方案大体都包含三个阶段: 文本数据的采集、对文本建立索引和提供检索服务,而在这些阶段MapReduce作为有效的并行分布式的手段,也颇有应用。
3.1.1 抓取
在文档集的来源方面,ClueWeb09文档集包含10亿网页,10种语言(25TB),由卡耐基梅隆大学2009年初抓取的。除了类似的正规发布的大规模数据集,可以直接获取渠道之外,很多Web网页的信息需要自主采集来获得,对需要最新数据的搜索引擎更是如此。因此抓取方面也提出了分布式采集的需求。目前普遍认为抓取的算法并不难,关键在于抓取的调度。而抓取的调度又与很多因素相关: 搜索引擎的后台,数据存放的组织结构,网页的贡献度,网页更新时间等。著名的开源社区软件Nutch*http://nutch.apache.org/,从它较早的版本里开始,就全部使用了MapReduce的方式编程,底层系统使用的是Hadoop,其中不仅包含了分布式的采集代码,还包括了搭建搜索引擎所必须的索引、检索(Lucene)等一系列操作的实现。所以Nutch源码本身也是学习MapReduce编程的一个很好的资料。
3.1.2 索引
索引是文本检索里相当重要的一个操作,由于内存的限制,原先内存式建立索引的方法,面对Web规模的数据量已经不再可用。一方面当数据量继续增大的时候,数据大都存储在分布式的集群上。如果拥有大量的用户,同时又需要亚秒级响应时间,需求超越了单机处理的能力。合理的解决办法是通过大量机器分布式检索,这使得以各种方式分开建立索引成为必需。因此早在MapReduce出现之前就有分块索引、动态索引等方法[6]。分布式检索有两种主要分块策略: 按文档分块和按词项分块。具体实现方法也是多种多样,面对不同的权衡各自需要不同的检索策略。一些研究表明,文档分块策略占优势。
另一方面从索引建立的主要任务看到: 词条化,归一化,建立倒排表,都是逻辑上比较简单的批处理操作。分布式索引本身就放在分布式系统上,也可以为后续的分布式工作提供方便,因此索引很适合采用MapReduce来实现。目前使用MapReduce对本地和Web网页建立索引是MapReduce的应用里比较热门的一个研究课题,在实际中也有很高的应用价值。
在索引的优化方面, MapReduce适用有效,所以有不少文献都有提及。Dean和Ghemawat最初的MapReduce论文[4]里提到的索引算法产生了太多的中间数据,这点可以通过对算法的一些优化来提高索引速度,如单遍扫描(single-pass)索引算法。后续的一些工作也印证了这点,如Terrier信息检索系统就使用了该单遍扫描索引算法。McCreadie对单遍扫描索引算法进行了改进,基于Hadoop的实现使它得以使用MapReduce框架,并取得了很好的效果[7]。此后有工作对简单的分布索引策略和MapReduce架构下对TREC数据集的索引建立做了比较,后者有明显优势[8]。这可能的原因是前者访问数据存储中心时,速度受到了影响,而后者针对数据来分配任务改善了这一点。
在这里,值得一提的是马里兰大学云计算中心的Jimmy Lin等人做了很多相关研究。如MapReduce框架下建立索引的几种方法比较[9],为Hadoop做了一个叫Cloud9*http://www.umiacs.umd.edu/~jimmylin/cloud9/docs/的用于研究和教学的MapReduce库,还基于这个库开发了一个Ivory*http://www.umiacs.umd.edu/~jimmylin/ivory/docs/index.html工具包。还有工作使用Hadoop为RDF数据建立了分布式的索引,做了索引方式的比较,分析了不同结构下的性能,将MapReduce在语义搜索方面的应用做了一些尝试。回到索引建立来说,除了Google的索引采用了MapReduce之外,其他很多的索引建立与索引压缩方法都已经有了MapReduce的实现,不难看出这个方向上将会有长足的发展。尤其现在微博等短而快的新形式的文本出现,对这些文本来说,易用而有效MapReduce可能会发挥它的作用。
3.1.3 检索
在这里将检索和索引分开来讲,是因为一般认为MapReduce不适用于做实时检索[1]: MapReduce是将大规模数据先分割,然后任务交由每个mappers处理,而每个mapper是个长时间批处理的过程。这与临时突发的小规模实时检索意愿相悖;而且分布式文件系统(DFS)的设计也使得客户机对其随机访问效率很低。以MapReduce和Hadoop来说,客户机访问文件系统需要先跟master(Hadoop里的name node)交互,得到真实文件的存放位置和偏移,然后客户机再与集群中的对应机器(Hadoop里的data node)通讯来得到数据,而且数据分了块的话很可能处于不同的机器上。实时检索对响应速度的要求比较高,因此以当前的情况来看,在分布式系统之上做实时检索是不太合适的。
举例说明,一个简化了的检索问题: 我们需要搜索查询词对应的记录表,系统遍历这些记录表来计算查询文档得分,然后返回Top-K结果。其中,搜索记录需要随机访问磁盘(因为记录太大,不放在内存),并且这个操作需要多次的网络交换,从而造成延迟。所以关键问题在于分布式系统随机访问效率低。
目前的分布式索引检索系统有Doug Cutting的Bailey,Katta*http://katta.sourceforge.net/(一个可用的管理Lucene索引的系统)和惠普实验室的分布式Lucene等。而使用MapReduce处理上述问题的典型方法是维护一个额外的框架专门用来支持实时检索,然后复制每个分区索引到对应的分区服务器,如Katta。但有两个缺点: 一是需要保留和维护两个不同的框架,一个用于建立索引,一个用于实时查询;二是双框架增加了网络的负担,因为需要在网络上传输大量索引。这种情况下,前面提到的Ivory作者持有不同观点,认为HDFS是可行的。为了解决以上两点问题,Ivory只使用了单个框架,对直接从HDFS读取记录做了尝试,实验也取得了不错的效果。一个可能的原因是机架内访问速度与本地硬盘差距不大,另一个可能原因是高层应用的设计屏蔽了底层检索的延时,如cache等[1]。
Google自己也针对MapReduce在检索方面的缺点提出了Percolator[10],一种专门用来为Web搜索服务的系统。搭建与GFS和BigTable之上,擅长于以增量方式来处理小文件,也算是对现有Google系统的一个补充。
3.2 自然语言处理
自然语言处理也存在海量数据的问题,同文本检索一样,自然语言处理也有相当多的MapReduce比较成型的应用。分词、标注、句法分析等的Map-Reduce应用大都也融入于机器翻译的各种实现系统之中。NLTK就是自然语言处理的一个工具包,框架中也使用了MapReduce,实现方面采用的Hadoop与Python的结合。
3.2.1 词义消歧、语义标注和词性标注
在自然语言的理解方面,除了有词语对齐工作采用MapReduce实现之外;词义消歧、语义标注、词性标注也是热点难题,在信息检索,机器翻译等领域都有很高的应用价值。词义消歧需要好的词义标注语料库来进行训练,这直接关系到最终的效果,最初的方法是采用人工标注。但人工标注也存在一些问题: 不同的人工标注结果可能不同,还需要做其他工作来对该结果进行评估;而且人工标注比较耗费时间和人力,极大数据量的情况下就不那么切实可行;还有些数据集是动态的,使用人工实时标注也不可行。
面对这些问题,部分研究转向了使用自动或半自动的方式来标注。一种比较好的自动语义标注工具是建立在不同的机器学习算法上的,需要训练集;另一种方法是采用自然语言处理,信息检索或者信息抽取方法,使用的是基于模式(pattern)的解决方案。由于算法的复杂度较高,很多研究做的实验规模并不大,而基于模式的半自动标注工具On-Tea[11],被原作者扩展到了MapReduce框架里,以利用MapReduce的优势来处理大规模文本数据。
对语料库的加工还包括词性标注,词性标注一般有基于规则库的与基于统计的标注算法,其中基于统计的HMM标注算法,使用训练语料库来计算在给定的上下文中某一单词具有某一标记的概率。文献[12]给出了一个非参数的隐马尔科夫模型,并尝试了两种非参数先验,也使用了MapReduce的实现。
3.2.2 统计机器翻译
在自然语言生成方面,机器翻译无疑是重头戏。统计机器翻译的质量,很大程度上取决于训练数据的规模。除Google翻译自己使用了MapReduce架构外,一些研究单位和研究者也紧跟步伐。如Christopher Dyer在基于MapReduce做统计机器翻译的工作,在文献[13]里提到,使用基于短语的统计机器翻译系统,Moses工具包,用500万句子对来训练模型,需要两天多的时间。如果想缩短这个时间,一方面需要购买更好的硬件,另一方面还要开发软件。如果使用MPI,开发人员还需要处理伸缩性、容错、时序等问题。因此它们使用MapReduce实现了一个基于短语的翻译模型和两个词语对其模型,其中也用到了最大似然和EM算法。有其他的类似工具包的文献[14]、开源工具包[15]、正准备使用MapReduce实现的工具包[16]。因此可以说在统计机器翻译方面,MapReduce的应用是比较多而且成功的。
3.3 通用方法
上文介绍了MapReduce在文本检索和自然语言处理方面的一些应用,本节在通用的方法上,更底层的方面介绍MapReduce的应用情况。
3.3.1 文档相似性
文档相似性是文档处理中比较基础的一个工作。文档相似性也可以看作是文档的“距离”,在数据挖掘、机器学习和模式识别等领域是比较重要的概念。并且在信息检索领域也为分类聚类、查询—文档相关度计算、相关文档的评分和排名等提供了依据[17]。
MapReduce的特性决定了它很适合文档相似性计算的工作。这是因为文档相似性很多都基于文档的两两对比,这些两两的文档对很容易被分割成MapReduce的子任务;而且每对文档对的相似度计算常常不需要全局的信息。MapReduce框架可以分解内积(向量空间模型)或其他相关度的计算,使之变成简单的乘法和加法阶段。每步向量分解的结果可以在shuffle和sort阶段分发排序,减少了冗余计算。分布式系统可以采用单遍扫描的算法,而不是频繁的随机访问来计算相似度。这种处理方法也极大地提高了之后建立索引的效率[9,18]。
文档相似性的计算很容易扩展到文档操作的各个方面。有一些工作在MapReduce框架下实现文档对比的基础上,或对文档进行重复检测,或直接消除网络上的重复文档[19],使这些传统问题又有了新的实现思路。复旦大学一篇2010年SIGIR的论文对文档局部重复检测做了研究[20]。与以往的文档重复检测不同,他们的工作将重复检测定位于更细粒度的句子级别,使用了三步MapReduce工作(jobs): 首先建立倒排索引,然后提取出句子特征,建立句子重复矩阵,最终将句子重复检测过程转换成了矩阵的对角线发现的过程。这种方式还可以得到重复句子及对应重复位置,并通过实验得出了约四个特征可以很好地表示一句话的结论。
3.3.2 分类聚类
文本分类和聚类做为对文本信息进行有效组织的重要手段,有着多方面的应用,如文档集合整理、多文档自动文摘、信息推荐、信息检索等。分类聚类也是机器学习的主要任务和方法,其中很多算法虽然效果很好,但因为复杂度较高,在实际应用当中一直少有建树。而MapReduce的出现无疑为它们的应用提供了很好的支撑。实际上很多研究者已经迫不及待地研究并实现了相当多的分类聚类算法,例如,K-means,SVM等。
这里不得不提到比较有名的Mahout*http://mahout.apache.org/,一个包含了很多算法的MapReduce库[21]。采用MapReduce框架来实现机器学习算法的并行,不仅完成了很多分类聚类的算法,还有一些很常用的算法,包括有: 局部加权回归(LWLR),K-means,逻辑回归(LR),简单贝叶斯,支持向量机(SVM),独立成分分析(ICA),主成分分析(PCA),高斯判别式分析(GDA),期望最大化算法(EM),反向传播(NN)等。此外还有工作在GPU上使用MapReduce架构,实现了SVM算法的训练(比较流行的算法SMO等)和分类,极大地提高了性能[22]。作者的另一篇文章里提到了自己实现的一个代码产生框架,用来为GPU上的应用开发者提供便利[23]。
除了传统的聚类方法之外,双聚类或者称为联合聚类(biclustering或co-clustering),是一种数据挖掘技术,允许矩阵的行和列同时聚类。一些研究者将MapReduce用于双聚类中,提出了一个分布式双聚类的框架,介绍了分布式数据预处理和双聚类的实现方法,使用Hadoop开发一个开源的实现: DisCo,能有效的处理和分析超大规模(几百T)数据集[24]。mahout论文里也指出: 任何算法,只要满足统计查询模型(Statistical Query Model)[25],都可以使用MapReduce框架来实现[21]。
3.3.3 EM算法
使用MapReduce实现一般会参考以下几点。算法的易分块性,操作数据集的大小,算法的可并行性,是否需要全局同步。本节提到的EM算法是一系列迭代优化算法,用来学习不完整数据的概率分布[26],但需要在训练集上迭代计算,因此开销大。在模式识别,机器学习等领域非常重要。EM算法可以与MapReduce无缝的结合。
(1) mappers在map阶段独立并行的训练每个分区的数据,计算每个分区的先验概率;Reducers收集需要的信息,再加和,解决M步骤需要的优化问题;然后,模型参数在MapReduce执行期间是静态的,可以方便的被每个mappers和其他数据操作调用;
(2) 使用EM算法的模型(如HMM)通常采用独立性假设,有很高的并行性;
(3) EM算法迭代只需要更新参数,然后下一步job使用相同的框架,可能连数据格式都不需要改变。
因此使用MapReduce可以很好地解决EM的瓶颈问题,类似的学习算法很适合采用MapReduce实现。Jimmy Lin在他的新书里用了一章,对很多迭代算法如何应用MapReduce都做了阐述和用例: 并行的宽度优先查找、Page Rank和HMM等,有兴趣的读者可参照文献[6]。
3.3.4 统计语言模型
统计语言模型,对自然语言的统计和结构方面的内在规律建模,已经在语音识别、机器翻译、信息检索等多方面有了长足的发展。Das等人提出了一个并行的概率潜在语义分析(pLSA)的EM算法,就使用了MapReduce架构[27]。学术界近些年流行的一些概率图模型,优化算法也都有了并行的研究,包括并行化的LDA,HDP等[28]。隐含狄利克雷分配(LDA)是公认的效果很好的话题模型之一,但其缺点在于计算复杂度也比较高,因此很多工作使用了MapReduce来实现并行的LDA,如[29]以社区推荐和文档摘要应用为例,在MPI和MapReduce上分别实现了并行的LDA(PLDA),并将MPI上的实现源码公开。类似的工作见文献[30],除了PLDA外还有并行的SVM(PSVM),PSC等其他实现。还有工作使用tag-LDA做tag推荐,其中tag-LDA用来对文档、词和tag来建模[31]。以上工作都只提到了并行的算法,并未对MapReduce的具体实现细节做详细阐述,其中文献[29]和[31]均采用NIPS07上AD-LDA的方法。详细一点的统计语言模型综述可以参见文献[32]。
3.3.5 其他
除了上述算法和模型,一些更底层的,很多领域可通用的数学物理方法也都可采用MapReduce方案来实现,如WWW 2010上的文章,有关于矩阵分解[33](可用于特征选择,协同推荐等),最大覆盖[34]等通用的一些方法。还有工作以边为中心,实现了一系列的图算法,包括: 找图中的三角形/四边形,找Truss(一种图的结构),基于重心的聚类,找联通子图等[35]。
4 MapReduce性能研究和模型改进
微软的Dryad[3]也使用了分布式的架构,但开放的资料少,因此相关研究也很少。而MapReduce系统已经有多种架构上的实现,如Cell B.E.[36], MPI[37], GPUs[38],以及多核处理器等。对于不同领域的应用,还有印第安纳大学的CGL-MapReduce[39],用于生物信息学方面的CloudBurst[40]等,还有上文提到过的格拉斯哥大学的Terrier[41]也增加了MapReduce实现。
4.1 性能研究与评测
大量实现系统的涌现也使得研究者开始对性能方面进行一些研究和探讨。有些工作与数据库对比,对MapReduce性能做了评估。得出的结果不尽相同,也有工作认为传统的数据库更加高效[42],但总体来说MapReduce的效果也是明显的[43-45]。这一部分原因可能是因为他们工作的平台不同,对MapReduce的实现和优化也不同。在细节方面,有比较新的工作对MapReduce在数据压缩方面进行评测,强调了压缩在MapReduce执行效率上的重要性[46]。但因为map阶段需要对数据(按行)进行解析,此时加压缩会有较大损耗。因此总体来说,压缩提升的效果不如并行数据库那样好。
大部分的对MapReduce实现系统的性能探讨和评测都是基于算法速度指标的,因为MapReduce与传统的数据处理方法不同,所以原先的评测系统并不适用。很多系统都用一些自己的方法进行评测,目前相对而言比较全面的评测系统是Yahoo!的评测系统YCSB,提出了一个新型的云服务的评测平台,扩展性好。对Cassandra,HBase,PNUTS和MySQL做过多方面的评测[47]。
4.2 模型改进
Google与Yahoo!的工程师因为MapReduce和Hadoop颇受赞誉。得益于他们,大规模处理有了相对较低的门槛,有不少研究开始从各个方面关注对模型的改进。MapReduce是一个大的框架,针对不同的数据还需采取更细化的方案。实际上模型改进的工作比较多,但不是本文的重点,因此在这里只介绍几个有代表性的工作。
模型的改进大体来说有两方面: 第一方面是基于一些特定的应用场景,对基本的MapReduce架构进行完善和改进使之可用。Hung-chih Yang等人提出的Map-Reduce-Merge[48],在map和reduce阶段之后加入merge阶段,以增加对关系数据的操作和支持。后续研究和使用又优化了半连接操作,减少了磁盘间的通讯[49]。其他一些类似的模型改进还有SQL/MapReduce[50],Mrpso[51]等。另外有工作改进MapReduce,以支持在线增量式的数据收集和即时查询[52]。第二方面是对MapReduce本身的扩展,与场景无关。文献[53]认为数据或者处理速度有齐夫分布现象,由该现象产生的滞后者(stragglers)会极大的降低MapReduce的性能,对此研究了应对策略。
一个完整的框架实现需要考虑系统的安全: Airavat[54],对MapReduce增加集成了分散的信息流控制(DIFC)模型,对使用者的数据的保密性和安全性提供了保证。现有的一些MapReduce系统也或多或少的包含了安全机制,但主攻这方面的研究工作还未成型,因为很多中小集群是与外网隔离或半隔离来处理数据的,安全机制并不是最重要的问题。
5 总结
MapReduce做为一个新的模型,而框架里用到的很多东西并不新,以至于受到数据库界的一些抨击[42]。但MapReduce是第一次把这些点放在了一起,有出色的容错性,使用在大规模的实际问题和新特点数据上,这个规模是以前无法预见的,这也正是它的贡献所在。MapReduce有很多自身的优点,分布式并行的方式使对大规模数据的处理便利化,封装和抽象也使一些任务简单化。目前它做到了既使得应用开发人员不需关注系统级的实现细节,而又能使他们对大规模计算的容错性有个了解,为P级规模数据集的算法实现铺好了道路。也一定程度上激发了研究人员对分布式计算或称云计算的热情。
将MapReduce应用于适合的场景非常关键: 某些复杂的图问题,图分解的本身可能又是另外一个大的问题;再者数据量比较小情况下,MapReduce的大部分时间花在任务的建立与worker间的信息交换上,效率会很低。可以说,MapReduce还处于发展阶段,关于MapReduce的很多应用领域还有待开发,现有的一些方法也并不十分完善,学术界与工业界均有可以研究和探寻的地方。
总之,以目前的情况看来,MapReduce的应用将会越来越广泛,在计算机界和互联网的各个方面,它都将会起到愈加重要的作用。还有不少有关 MapReduce 和Hadoop的文献,是用于很多美国高校计算机教学的,这点也反映了国外的教育机构对MapReduce的重视程度。对文本处理领域来说,不管是否使用MapReduce架构,大规模数据的高效处理已是必须面对的问题,也是未来的一个研究热点。对包括MapReduce在内的各个分布式框架的研究和使用也仍是很关键的一个课题,具有重大的理论价值和现实意义。
[1] J. Lin, D. Metzler, T. Elsayed, et al. Of Ivory and Smurfs: Loxodontan MapReduce Experiments for Web Search[C]//Proceedings of TREC, 2010.
[2] Michael, Daniel Abadi, David J. DeWitt, et al. MapReduce and Parallel DBMSs: Friends or Foes[J] Communications of the ACM, 2010, 53(1).
[3] Michael Isard, Mihai Budiu, Yuan Yu, et al. Dryad: distributed data-parallel programs from sequential building blocks[C]//Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems, Lisbon, Portugal, 2007.
[4] J. Dean, S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM, 2008, 51 (1): 107-113.
[5] Jeffrey Dean, Sanjay Ghemawat. MapReduce: a flexible data processing tool[J]. Communications of the ACM, January 2010, 53(1).
[6] Jimmy Lin, Chris Dyer. Data-Intensive Text Processing with MapReduce[M]. 2010.
[7] R. M. C. McCreadie, C. Macdonald, I. Ounis. On single-pass indexing with MapReduce[C]//Proceedings of 32nd SIGIR, 2009: 742-743.
[8] R. McCreadie, C. Mcdonald, I. Ounis. Comparing Distributed Indexing: To MapReduce or Not?[C]//Proceedings of LSDS-IR, 2009, CEUR Workshop Proceedings, 80: 41-48.
[9] Jimmy Lin. Brute force and indexed approaches to pairwise document similarity comparisons with Map-Reduce[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA: 2009.
[10] Daniel Peng, Frank Dabek. Large-scale Incremental Processing Using Distributed Transactions and Notifications[C]//Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation, 2010.
[11] Michal Laclavik, Martin Seleng, Ladislav Hluchy. Towards Large Scale Semantic Annotation Built on MapReduce Architecture[C]//Proceedings of ICCS 2008, M. Bubak et al. (Eds.), 2008. Part III, LNCS 5103: 331-338.
[12] Jurgen Van Gael, Andreas Vlachos, Zoubin Ghahramani, et al. The infinite HMM for unsupervised PoS tagging[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2009.
[13] Christopher Dyer, Aaron Cordova, Alex Mont, et al. Fast, easy, and cheap: construction of statistical machine translation models with MapReduce[C]//Proceedings of the 3rd Workshop on Statistical Machine Translation, Columbus, Ohio, 2008: 199-207.
[14] Ashish Venugopal, Andreas Zollmann. Grammar based statistical MT on Hadoop: An end-to-end toolkit for large scale PSCFG based MT[J]. The Prague Bulletin of Mathematical Linguistics. 2009, 91:67-78.
[15] Qin Gao, Stephan Vogel. Training Phrase-Based Machine Translation Models on the Cloud: Open Source Machine Translation Toolkit Chaski[J]. The Prague Bulletin of Mathematical Linguistics. 2010,93: 37-46.
[16] João Gra a, Kuzman Ganchev, Ben Taskar. PostCAT-Posterior Constrained Alignment Toolkit[J]. The Prague Bulletin of Mathematical Linguistics. 2009,91: 27-36.
[17] Christopher D. Manning, Prabhakar Raghavan, Hinrich Schutze,王斌(译). 信息检索导论[M]. 北京: 人民邮电出版社, 2010.
[18] Tamer Elsayed, Jimmy Lin, Douglas W. Oard. Pairwise document similarity in large collections with MapReduce[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies. Columbus, Ohio: 2008.
[19] Zhang Yuanfeng, Dong Shoubin, Zhang Ling, et al. Algorithm of Parallelized Elimination of Duplicated Web Pages Based on Map/Reduce[J]. Journal of Guangxi Normal University, 2007, 02.
[20] Qi Zhang, Yue Zhang, Haomin Yu, et al. Efficient partial-duplicate detection based on sequence matching[C]//Proceeding of the 33rd international ACM SIGIR conference on research and development in information retrieval, 2010: 675-682.
[21] C. Chu, S. Kim, Y. A. Lin, et al. Map-reduce for machine learning on multicore[C]//Proceedings of NIPS 19, 2007.
[22] Bryan Catanzaro, Narayanan Sundaram, Kurt Keutzer. Fast support vector machine training and classification on graphics processors[C]//Proceedings of the 25th international conference on machine learning, Helsinki, Finland, 2008: 104-111.
[23] B. Catanzaro, N. Sundaram, K. Keutzer. A map reduce framework for programming graphics processors[C]//Proceedings of Workshop on Software Tools for MultiCore Systems, 2008.
[24] Papadimitriou, S., Sun, J. Disco: Distributed co-clustering with map-reduce[C]//Proceedings of the IEEE International Conference on Data Mining (ICDM), 2008.
[25] M. Kearns. Efficient noise-tolerant learning from statistical queries[J]. Journal of the ACM, 1999: 392-401.
[26] Arthur P. Dempster, Nan M. Laird, Donald B. Rubin. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society, 1977, Series B (Methodological), 39(1): 1-38.
[27] A. Das, M. Datar, A. Garg, et al. Google news personalization: Scalable online collaborative filtering[C]//Proceedings of the 16th International Conference on World Wide Web, New York, 2007: 271-280.
[28] David Newman, Arthur Asuncion, Padhraic Smyth, et al. Distributed Algorithms for Topic Models[J]. Journal of Machine Learning Research, 2009, 10: 1801-1828.
[29] Yi Wang, Hongjie Bai, Matt Stanton, et la. PLDA: Parallel Latent Dirichlet Allocation for Large-Scale Applications[C]//Procceedings of AAIM, 2009, 5564: 301-314.
[30] Edward Y. Chang, Hongjie Bai, Kaihua Zhu. Parallel algorithms for mining large-scale rich-media data[C]//Proceedings of the 17th ACM international conference on Multimedia, 2009.
[31] Xiance Si, Maosong Sun. Tag-lda for scalable real-time tag recommendation[J]. Journal of Computational Information Systems, 2008.
[32] ChengXiang Zhai. Statistical Language Models for Information Retrieval[M]. Morgan & Claypool Publishers, 2008.
[33] Chao Liu, Hung-chih Yang, Jinliang Fan, et al. Distributed nonnegative matrix factorization for web-scale dyadic data analysis on mapreduce[C]//Proceedings of the 19th international conference on World Wide Web, 2010: 681-690.
[34] Flavio Chierichetti, Ravi Kumar, Andrew Tomkins. Max-cover in map-reduce[C]//Proceedings of the 19th international conference on World Wide Web, 2010: 231-240.
[35] J. Cohen. Graph twiddling in a MapReduce world[J]. Computing in Science and Engineering, 2009, 11(4): 29-41.
[36] de Kruijf, M, Sankaralingam, K. MapReduce for the Cell Broadband Engine Architecture[J]. IBM Journal of Research and Development, 2009, 53: 1-10.
[37] Torsten Hoefler, Andrew Lumsdaine, Jack Dongarra. Towards Efficient MapReduce Using MPI[J]. Lecture Notes in Computer Science, 2009, 5759: 240-249.
[38] Bingsheng He, Wenbin Fang, Qiong Luo, et al. Mars: a MapReduce framework on graphics processors[C]//Proceedings of the 17th international conference on parallel architectures and compilation techniques, Toronto, Ontario, Canada, 2008.
[39] Jaliya Ekanayake, Shrideep Pallickara, Geoffrey Fox. MapReduce for Data Intensive Scientific Analyses[C]//Proceedings of the 2008 4th IEEE International Conference on eScience, 2008: 277-284.
[40] Michael C. Schatz. CloudBurst[J]. Bioinformatics, 2009: 25(11): 1363-1369.
[41] R. McCreadie, C. Macdonald, I. Ounis, et al.. University of Glasgow at TREC 2009: Experiments with Terrier[C]//Proceedings of the 18th Text Retrieval Conference, Maryland: Gaithersburg, 2009.
[42] Andrew Pavlo, Erik Paulson, Alexander Rasin, et al. A comparison of approaches to large-scale data analysis[C]//Proceedings of the 35th SIGMOD International Conference on Management of Data, Providence, Rhode Island, USA, 2009.
[43] Jiang, BC Ooi, L Shi, et al. The Performance of MapReduce: An Indepth Study[C]//Proceedings of the VLDB Endowment, 2010.
[44] Colby Ranger, Ramanan Raghuraman, Arun Penmetsa, et al. Evaluating MapReduce for Multi-core and Multiprocessor Systems[C]//Proceedings of the 2007 IEEE 13th International Symposium on High Performance Computer Architecture, 2007: 13-24.
[45] Feuerlicht, G. Database Trends and Directions: Current Challenges and Opportunities[C]//Proceedings of DATESO 2010,tědrotín-Plazy, 2010: 163-174.
[46] Chen Y., Ganapathi A., Katz R.. To compress or not to compress-compute vs. io tradeoffs for mapreduce energy efficiency[R]. Electrical Engineering and Computer Sciences University of California at Berkeley, UC Berkeley, 2010.
[47] B. Cooper, A. Silberstein, E. Tam, et al. Benchmarking Cloud Serving Systems with YCSB[C]//Proceedings of the 1st ACM Symposium on Cloud Computing, 2010: 143-154.
[48] Hung-chih Yang, Ali Dasdan, Ruey-Lung Hsiao, et al. Map-reduce-merge: simplified relational data processing on large clusters[C]//Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 2007.
[49] Mohamad Al Hajj Hassan, Mostafa Bamha. Semi-join computation on distributed file systems using map-reduce-merge model[C]//Proceedings of the 25th Symposium On Applied Computing. ACM, 2010.
[50] E. Friedman, P. M. Pawlowski, J. Cieslewicz. SQL/MapReduce: A Practical Approach to Self-describing, Polymorphic, and Parallelizable User-defined Functions[C]//PVLDB, 2009, 2(2): 1402-1413.
[51] Andrew W. McNabb, Christopher K, et al. MRPSO: MapReduce particle swarm optimization[C]//Proceedings of the 9th annual conference on genetic and evolutionary computation, London, England, 2007.
[52] Tyson Condie, Neil Conway, Peter Alvaro. Online aggregation and continuous query support in MapReduce[C]//Proceedings of the 2010 International Conference on Management of Data, 2010: 1115-1118.
[53] J. Lin. The Curse of Zipf and Limits to Parallelization: A Look at the Stragglers Problem in MapReduce[C]//Proceedings of LSDS-IR, 2009, 80: 57-62.
[54] I. Roy, H. Ramadan, S. Setty, et al. Airavat: Security and Privacy for MapReduce[C]//Proceedings of NSDI, 2010.
[55] Jimmy Lin. Scalable language processing algorithms for the masses: a case study in computing word co-occurrence matrices with MapReduce[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, Hawaii, 2008.
[56] Rob Pike, Sean Dorward, Robert Griesemer, et al. Interpreting the data: Parallel analysis with Sawzall[J]. Scientific Programming, 2005, 13(4): 277-298.
[57] Laclavík, M.-eleng, M.-Ciglan, et al. Ontea: Platform for Pattern Based Automated Semantic Annotation[J]. Computing and Informatics, 2009,28(4): 555-579.
[58] J. Urbani, S. Kotoulas, E. Oren, et al. Scalable distributed reasoning using mapreduce[C]//Proceedings of the International Semantic Web Conference (ISWC), 2009.
[59] Y. Chen, L. Keys, R. Katz. Towards energy efficient MapReduce[J]. Technical Report UCB/EECS-2009-109, UC Berkeley, 2009.
[60] M. Zaharia, A. Konwinski, A.D. Joseph, et al. Improving MapReduce Performance in Heterogeneous Environments[C]//Proceedings of San Diego, CA: Proc. OSDI, 2008: 29-42.
[61] W Zhao, H Ma, Q He. Parallel K-Means Clustering Based on MapReduce[J]. Lecture Notes in Computer Science, 2009, 5931: 674-679.
[62] Bacchiani M, Beaufays F, Schalkwyk J, et al. Deploying GOOG-411: Early Lessons in Data, Measurement, and Testing[C]//Proceedings of Acoustics, Speech and Signal Processing, ICASSP 2008: 5260-5263.
猜你喜欢
客联(2022年3期)2022-05-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
中国新闻周刊(2021年26期)2021-07-27
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
电脑爱好者(2017年7期)2017-05-06
燕山大学学报(2015年4期)2015-12-25
雷达与对抗(2015年3期)2015-12-09
