
基于电子商务用户行为的同义词识别
2012-06-29 05:53张书娟董喜双
中文信息学报 2012年3期
张书娟,董喜双,关 毅
(哈尔滨工业大学,黑龙江 哈尔滨, 150001)
1 引言
随着互联网的发展,电子商务逐步发展起来。对于电子商务网站的站内搜索引擎而言,应该在准确理解买方意图的基础上,尽可能多的检索出相关商品,所以需要对查询进行扩展。要准确扩展查询,同义词表是必须的也是最基础的资源。目前国内还不具备电子商务领域的同义词典,而手工构建又费时费力,所以需要采用同义词自动识别的方法。
《牛津字典》对同义词的定义为:在用同一种语言表达的意义相同或者相近的两个词或者短语[1]。由定义可知,通常来讲同义词和近义词并不做严格的区分。而电子商务中不但需要做严格区分,而且要求意义完全相同。电子商务中同义词定义为对同一事物(同一概念)的不同表达形式,即在商品检索和商品描述中可以互相替换的词或者短语[2]。同义词具体表现为两个或者多个词语、短语,电子商务领域中的多为名词、名词短语、日常用语、网络用语等。
在对大量的数据进行研究后,我们把电子商务领域中同义词分为六大类。
(1) 英文—中文名称 这类同义词主要是对同一个品牌的中文和英文两种表达,例如,Nestle-雀巢,Adidas-阿迪达斯。
(2) 学名与俗名 多指一个事物的书面用语和非正式用语。例如,圣女果—小西红柿,鳖—甲鱼。
(3) 全称与简称 指概念的原名称和简化形式。例如,美特斯邦威—美邦,中国旅行社—中旅。
(4) 新称与旧称 由概念现在的称呼方法和古代或者近代称呼方法不同而引起。例如,自行车—脚踏车,硅—矽。
(5) 同音同义词 这类词一部分由对同一英文词翻译用词差异引起,另一部分由高频使用的错别字引起,若许多人习惯性使用错别字搜索,则此错别字也不可忽略。例如,雪佛兰—雪福兰,瑜伽—瑜珈。
(6) 传统同义词 指两词都比较常用且指同一事物,且不归入以上类别的词。例如,储物柜—收纳柜,挡板—隔板。
电子商务中同义词特点如下。
(1) 新词多 随着科学技术的迅猛发展和新消费潮流的涌现,国内外的品牌和商品可谓日新月异,另一方面人类在不断地创造新词,互联网用词尤其明显。所以,同义词对中亦有大量的新词存在。例如,Mintpie-尼派,Tablet PC-平板电脑,五分裤—五裤。
(2) 错别字多 错别字已成为一种普遍社会现象,出版物,电视上,网络上,都大量存在。有些错别字被大量使用,以至于我们不可以忽略它的存在。如此,一个词的错误拼写就与正确拼写构成同义词。例如,瑜伽—瑜珈,耐克—奈克。
(3) 定义严格 每个产品都有一系列与之相似的产品,他们的名称也相似,另外上下位关系的事物名称亦相似,但是他们不是指向同一事物,所以不为同义词。例如,黑木耳—秋木耳,木耳—黑木耳。
本文在研究电子商务中卖方用户和买方用户行为特点的基础之上,提出了基于用户行为的同义词自动识别方法。首先根据用户行为特点获取候选集,进而提取两词的字面特征以及标题、查询、点击等用户行为特征,然后借助GBDT模型判断是否同义。本文结构组织如下:第二节介绍国内外相关研究;第三节介绍基于用户行为的同义词识别方法;第四节分析实验结果;第五节做总结和展望。
2 相关研究
目前国内外对同义词自动识别的研究,根据所使用资源可分为以下五类。
2.1 基于字面相似度
这种方法是根据两个词汇中相同字的个数来计算相似度。文献[3]根据词汇之间字面相似度将待归类词与被匹配词之间的聚类关系分为正确、不确定和无法判断三个级别,然后依赖专家对后两种情况进行判定,形成一种人机结合的同义词识别方法。文献[4]对上述方法进行了改进,根据汉语构词特点,引入重心后移,对词语中的每个语素根据其对主题表达的贡献进行加权处理,提高了准确率。
2.2 基于语义词典
这种方法借助现有语义词典或者自己构建语义词典来计算词汇相似度。文献[5]用自己建立的词素语义词典将待识别的词切分成多个词素,以计算两词汇相似度。文献[6]将《同义词词林》语义分类编码体系构成一棵树,通过计算树中结点距离得到词汇之间的相似度。文献[7]利用《知网》,在《知网》中每个词的语义由多个义原组成,将所有义原根据上下位关系构成一个树状层次体系,通过计算路径距离得到相似度,将两个词各自义原中相似度最大的作为两词的相似度。
2.3 基于词典释义
根据词典中词汇之间的相互注释关系,构造关系图,字典中的每个词都是图中的一个结点,词到它的每个注释都有一条边。将同义词的识别问题转化为互联网中超链接分析问题。文献[8]用HITS算法分析关系图,得到词汇之间相似度。文献[9]在PageRank算法的基础上提出ArcRank算法来计算词汇之间相似度。
2.4 基于大规模语料库
这种方法将词汇的上下文表示成空间向量。文献[10]将向量的余弦相似度作为两词的语义相似度。文献[11]在此基础上引入部分句法分析,只处理名词,在语料库中此名词的所有修饰词作为上下文,用Jaccard相似度来度量语义相似度。基于语料库方法所识别的同义词受语料库所属领域局限,且有数据稀疏的问题。
2.5 基于搜索引擎
这种方法借助搜索引擎的检索结果来统计词汇的出现次数,从一定程度上解决了统计的数据稀疏问题。文献[12]提出PIM-IR算法,通过计算互信息得到两词相似度。文献[13]对文献[12]的方法进行改进,提出了LC_IR算法,要求两词必须完全相邻,并且过滤搭配和修饰等噪声,提高了准确率。文献[14]则用Dice测度度量两词的相关性。
电子商务领域同义词与传统同义词定义的差异和新词较多的特点使得现有同义词自动识别方法的效果大打折扣。因此,本文在充分研究电子商务领域数据的基础上,根据用户行为特点获取候选集合,然后提取字面相似度、共现信息、上下文、用户行为等方面的特征,运用机器学习方法对候选集合中的词对进行判定。
3 基于电子商务用户行为的同义词识别
电子商务中用户行为包括卖方用户行为和买方用户行为。本文主要研究卖方用户行为中的标题编辑行为,包括用词特点、词与词之间的分割方式等方面和买方用户行为中的查询和点击行为,包括查询中词的个数、词与词之间的分割方式、所点击的商品标题等方面。根据卖方行为特点从商品标题中获取候选集,并根据买方行为特点从查询集合中获取候选集,抽取部分候选进行标注,然后提取字面特征和标题、查询、点击等用户行为特征,最后训练GBDT模型以判定所有候选同义词对。
3.1 候选集合获取
3.1.1 并列关系符号切分商品标题
研究发现卖方在编辑商品标题时,除了写入商品常用名称之外,还会将该商品的别称、简称、全称、俗语、常用错别字等扩展写入标题之中,以使更多的买方检索到。并且标题多用空格、“/”、“”等表示并列关系的符号(称之为并列关系符号)分割表义相同或相近的词。研究某电子商务网站3百万商品标题,发现72.4%的标题使用并列关系符号,因此我们用并列关系符号切分标题得到候选同义词对。
例如,对于商品标题“正品促销 拉杆包/拉杆箱/旅行包/拉杆旅行包/旅行箱 情侣搭配”,用并列关系符号切分得到拉杆包、拉杆箱、旅行包、拉杆旅行包、旅行箱五个词,两两组合行成候选词对。
3.1.2 基于SimRank思想聚合查询
SimRank由G.Jeh和J.Widom于2002年提出,基本思想是关联到相似事物的两个事物相似[15-16]。基于这一思想我们认为,点击到同一商品的所有查询相似。将点击到同一标题的所有查询聚合成查询集合,并从中获取候选同义词对。
研究某电子商务网站七天的查询日志(共2 000万查询)发现关键词个数为1或者2的查询占总查询的73.2%,而用空格分隔的查询占总查询的89.4%。也就是说,大部分买方搜索商品时,仅使用简短的1~2个词汇进行搜索,且习惯于用空格自然分割查询。所以我们在查询集合内,用空格切分每个查询,去掉相同词段,剩余词段两两组合为候选同义词对。
例如,title^A特价新款 拉杆箱 旅行箱 行李箱 密码箱 托运箱24寸^A 50012019
query^A旅行箱^A 1
query^A拉杆箱^A 1
query^A箱^A 3
query^A行李箱^A 1
标题数据格式:标记^A标题^A类目;查询数据格式:标记^A查询^A频率;^A为分隔符。
旅行箱、拉杆箱、箱、行李箱这四个词两两组合行成候选词对。
3.2 特征提取
对于机器学习的分类方法而言,最重要的是选择一系列能够区分各类别的特征。由上文示例可见候选集合中大多是词义相近的词对,所以仅根据简单特征很难区分两词是否同义。因此本文在考虑简单字面特征的基础之上,着重选择与用户行为相关的特征。经过实验,选择的特征主要包括以下四类。
(1) 字面特征
同义词是指向同一事物的两个不同的词语,故常常含有共同的语素,例如,连身裤和连体裤,跑步鞋和跑鞋,因此考虑其字面相似度。网络用语常出现错别字,如运动品牌“阿迪达斯”一词,很多人由于输入错误使用“啊迪达斯”,当很多人都习惯于如此使用时,我们就不可以忽略这个问题,因此考虑两词的读音相似度。
(1)
(2)
(3)
其中,Sim_charmin代表对较短词长的字面相似度,Sim_charmax代表对较长词长的字面相似度,Simdis代表读音相似度,same(w1,w2)代表在词w1,w2中相同字的个数,|wi|代表词长,Swi代表的wi读音,minDis(Sw1,Sw2)代表最小编辑距离。
(2) 标题特征
如果两个词同义,根据卖方书写标题的习惯,应该大量出现在同一标题中,且两者的前后顺序应该是随机的。因此计算在所有商品标题中,两词共现比例,互信息和互换比例。互换比例用一个词总出现在另一个词前的概率来度量,这个特征可以很好的区分将修饰关系和同义关系。
(4)
(5)

(6)
以上各量都是对商品标题而言的,CO_ratiotitle表示两词共现比例,C(wi)表示包含词wi的数目,C(w1w2)表示同时包含词w1和w2的数目。MItitle表示两词共现互信息,p(w1w2)表示两词共现频率,p(wi)表示词wi的频率。Front_ratiotitle表示两词互换比例,Cf(w1w2)表示w1在w2前面的数目,Cb(w1w2)表示w1在w2后面的数目。
(3) 查询特征
同样考虑在查询中两词的共现比例,互信息和互换比例(计算公式同title)。除此之外,还考虑每个词的上下文信息,即取这个词在查询中的前一个词和后一个词作为上下文,计算两词上下文的余弦相似度。
(7)
Simcos表示两词上下文向量的余弦相似度,V(wi)表示wi的上下文向量,|V(wi)|表示wi的上下文中词个数。
(4) 点击特征
如果w1出现在查询中,但没有出现在点击标题中,而w2却出现在点击标题中,这种情况下两词很可能同义。因此需要考虑一个词出现在查询中,而另一个词出现在点击标题中这种共现的比例,互信息和互换比例。同时也需要 考虑两个词都出现在标题中时,查询中只出现词w1与只出现词w2的比例。
Co_ratioclick
(8)
(9)

(10)
(11)
以上各量都是对商品标题而言的,Co_ratioclick表示两词共现比例,C(witwjq)表示词wi在点击标题中且wj在查询中的数目。MIclick表示两词共现互信息,p(witwjq)表示词wi在点击标题中且wj在查询中的频率,p(wi)表示词wi的频率。Front_ratioclick表示两词互换比例,Query_ratioclick表示两个词都出现在标题中时,查询中只出现词w1与只出现词w2的比例,cq(wi)表示查询中只出现wi的数目。
3.3 Gradient Boost Decision Tree模型
Gradient Boost Decision Tree(GBDT)模型是一种组合模型,它的基本思想是迭代的构建决策树,最后得到一个由M棵决策树组合而成的模型从而避免了单棵决策树过拟合的缺点[17]。
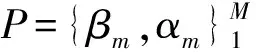
(12)
训练过程就是根据已知特征集合x和相关性分数集合y,用式(2)求参数集合P,即使得每个词对在模型F(x,P)下的损失函数L(y,F(x,P))最小。
(13)
将式(13)写成梯度下降的形式为式(14),表示将要得到的模型fm=βmh(x,αm)的参数使得fm的方向是之前所得模型Fm-1(x)的损失函数下降最快的方向。
(14)
对每个候选都计算偏导数gm(xi):
(15)
最终得到一个N维梯度下降方向向量:
(16)
使用最小二乘法得αm:
(17)
进而得到βm:
(18)
如此迭代M次最终得到参数集合P。
组合模型是多个简单模型的组合,但效果比单个复杂模型更好,这一优势使得越来越多的人青睐于组合模型。GBDT被广泛应用于分类、回归、排序等机器学习问题之中,表现出特有的优势[18-20]。
3.4 系统实现
基于电子商务用户行为的同义词识别系统结构如图1所示。首先根据电子商务中卖方编辑标题的特点用并列关系符号切分标题获取候选集合,并根据买方查询特点从点击了同一商品的所有查询集合中获取候选集合;然后从候选集合随机抽取一部分词对进行标注作为训练集和测试集,提取训练集特征并训练模型;最后提取测试集特征并应用上一步所得模型进行判定,得到判定结果。

图1 基于用户行为同义词识别系统结构图
4 实验与分析4.1 数据
本实验使用某电子商务网站280万条商品标题,和点击到这些标题的360万个查询。共得到150万候选同义词对,对其中3 900词对进行手工标注,对GBDT模型标注值为0或1,对SVM的标注值为-1或1。将标注数据均分为四份,轮流将其中三份用作训练集,一份用作测试集。使用上文特征集合构造特征,分别训练和测试,四次平均值作为模型的实验结果。GBDT模型的相似度取阈值为0.5,即大于等于此阈值为同义词,反之则不同义。
4.2 实验结果与分析
4.2.1 GBDT模型实验结果
依次加入字面、标题、查询、点击等特征进行实验,各个模型效果如表1和图2所示,相应的特征权重如表2所示。
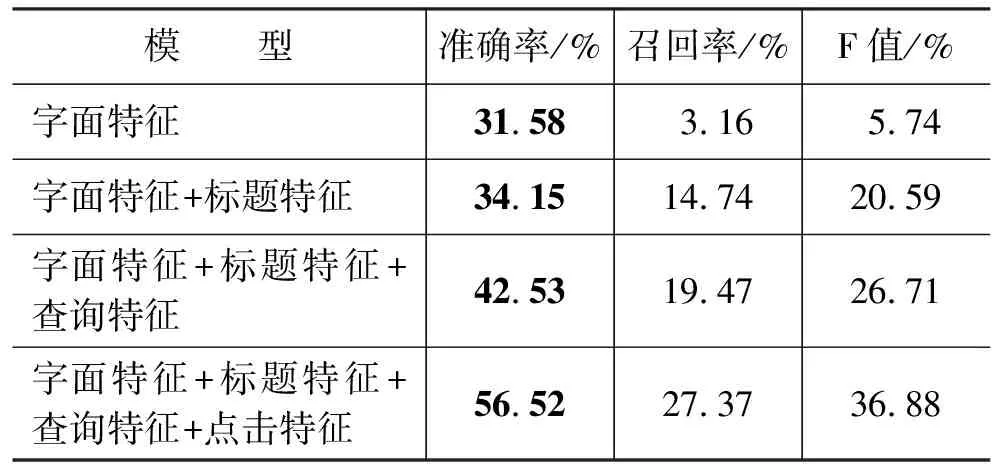
表1 GBDT模型实验结果

图2 特征逐渐增多时的效果提升图
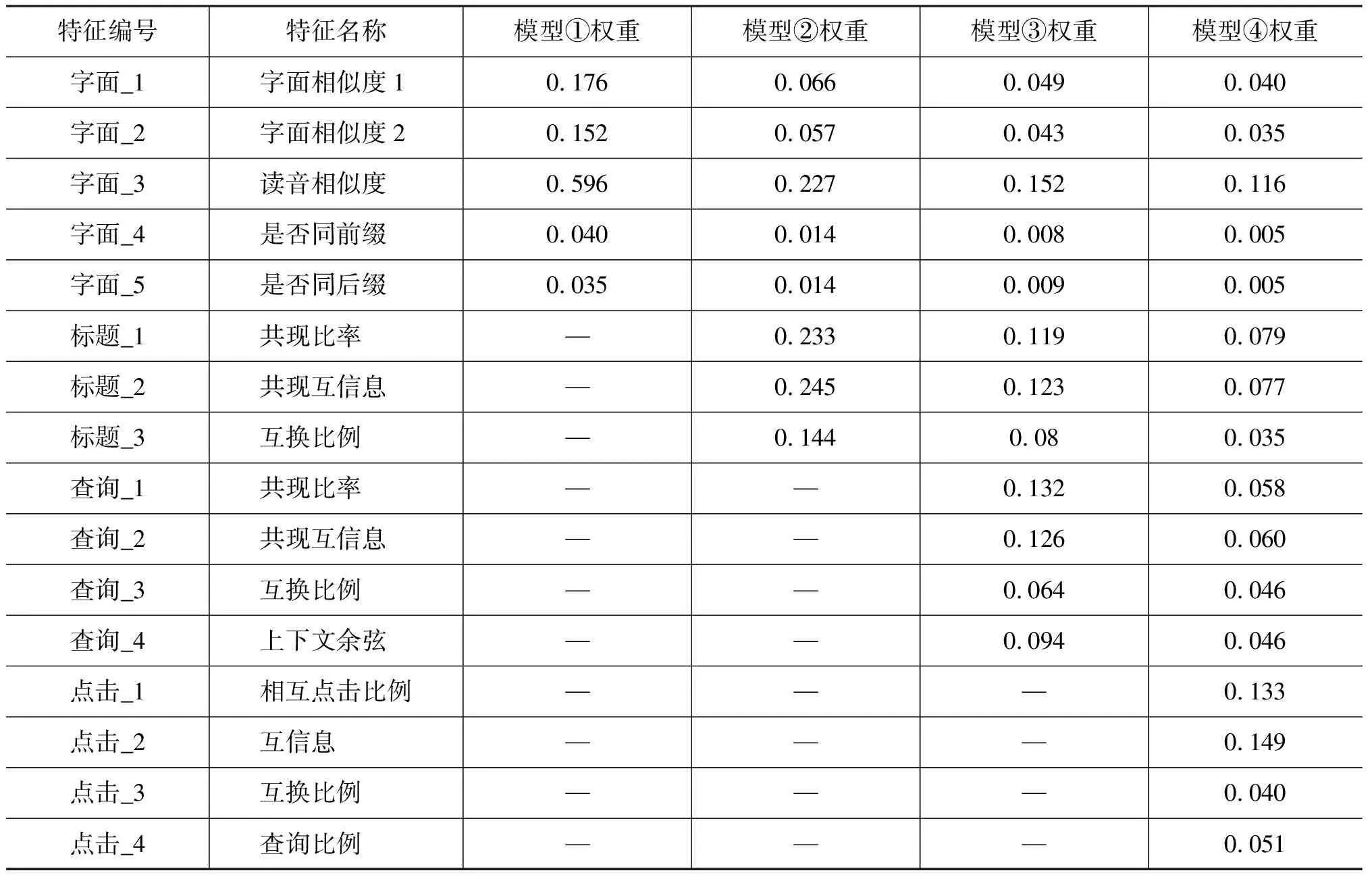
表2 特征权重变化表
从表1和图2可以看出,随着各类特征的加入,准确率、召回率和F值都有显著的提高。这说明电子商务领域同义词的识别问题,单纯从字面特征入手很难取得好的效果,同时说明我们选取的标题、查询、点击等用户行为特征可以有效提高电子商务领域同义词识别的精度。
从表2看出,当标题特征这一类用户行为特征加入的时候,标题特征所占总权重达到60%以上,进一步说明用户行为特征的重要度。当所有的特征都用来训练模型时,从权重列表可以得出,字面特征占比19.6%,标题特征占比19.1%,查询特征占比21%,点击特征占比37.3%。可知点击特征对结果有最大的贡献,从效果对比图2也可以看出,点击特征加入后,各项指标都有显著提高。
4.2.2 GBDT模型和SVM模型结果对比
四方面特征都加入时,两个模型对比试验如表3所示。
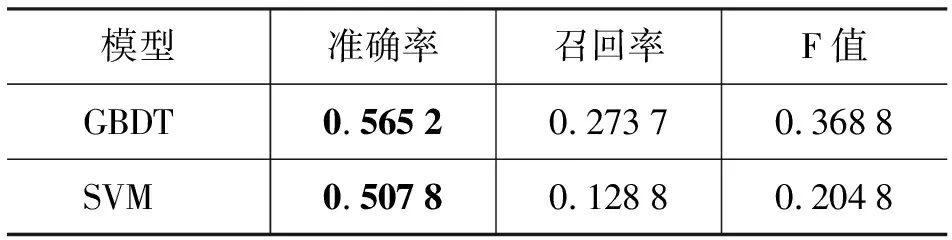
表3 两模型结果对比
两个模型都没有采用使得F值最高的参数,因为应用到电子商务检索中的同义词表必须是绝对准确的,这样才能有效地扩展查询,提高检索精度。另外,需要在此结果的基础上进行人工校验,出于对成本考虑,更侧重于准确率。
分析实验结果可知,影响准确率的因素主要是两词大量共现或互相点击,而不是同义词,例如,新娘—伴娘。影响召回的因素主要是数据稀疏导致特征得分低,例如,阿童木—铁臂阿童木。这些影响因素也是与电子商务领域用户用词特点和同义词特点紧密相关,可以说正是这些特点增加了同义词识别的难度。
5 总结和展望
本文在充分研究电子商务中用词特点的基础上,提出基于卖方用户行为和买方用户行为的同义词识别方法。通过并列关系符号切分商品标题和基于SimRank思想聚集查询两种方法获取侯选集合,获取字面特征及其标题、查询、点击等用户行为特征,采用GBDT模型对候选集合中的词进行判定。实验表明这种方法识别的准确率达到56.52%。下一步将继续深入挖掘标题、查询、点击等用户行为相关的特征,以期达到更好的效果。
[1] H. Coleridge,J.Murray,H.Sweet, et al. The Oxdord English Dictionary[M]. Oxford :Oxford University Press,2005.
[2] N. Kanhabua, K.Norvag. Determing time-based synonyms in searching document archives[C]// Proceedings of ECDL. 2010.
[3] 宋明亮. 汉语词汇字面相似性原理与后控制词表动态维护研究[J]. 情报学报, 1996, (4).
[4] 吴志强.经济信息检索后控制词表的研究[D].南京:南京农业大学,1999.
[5] 朱毅华. 智能搜索引擎中的同义词识别算法研究[D]. 南京:南京农业大学,2001.
[6] 穗志方,俞士汶. 主题概念规范化研究中的自然语言处理策略[C]// 第二届术语学、标准化与技术传播学术会议论文集.北京:科学出版社,1998:367-374.
[7] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
[8] Vincent D. Blondel, Pierre P. Senellart. Automatic extraction of synonyms in a dictionary[C]// Presented at the Text Mining Workshop.Arlington:2002.
[9] J. Jannink. Thesaurus entry extraction from an on-line dictionary[C]// Proceedings of Fusion’99,Sunnyvale CA:1999.
[10] Hsinchun Chen, Kevin J. Lynch. Automatic construction of networks of concepts characterizing document database[C]// Proceeding of IEEE Transactions on Systems, Man and Cybernetics. 1992,22(5):885-902.
[11] Gregory Grefenstette. Automatic thesaurus generation from raw text using knowledge-poor techniques[C]// Proceeding of Making Sense of Words. Ninth Annual Conference of the UW Centre for the New OED and text Research. 1993,9.
[12] Peter D. Turney. Mining the web for synonyms: PMI-IR versus LSA on TOEFL[C]// Proceeding of European Conference on Machine Learning. 2001:491-502.
[13] Derrick Higgins. Which statistic reflect semantics? Rethinking synonymy and word similarity[C]// Proceeding of International Conference on Linguistic Evidence. 2004.
[14] 刘华梅,侯汉清. 基于情报检索的汉语同义词识别初探[J].理论与探索.2005,28(4):373-375.
[15] Glen Jeh, Jennifer Widom. Simrank: a measure of structural-context similarity[C]// Proceeding ofKDD02: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, 2002:538-543.
[16] Ioannis Antonellis, Hector Garcia Molina , Chi Chao Chang. Simrank++: query rewriting through link analysis of the click graph[C]// Proceedings of VLDB Endowment, 2008:1(1).
[17] Jerome H. Friedman. Greedy function approximation: a gradient boosting machine[J]. Ann. Statist.,2001,29(5):1189 .
[18] Jing Bai, Fernando Diaz, Yi Chang, et al. Keke Chen: Cross-Market Model Adaptation with Pairwise Preference Data for Web Search Ranking[C]// Proceeding of COLING (Posters) 2010: 18-26.
[19] Zheng, Z, K.Chen, G. Sun, et al. A regression framework for learning ranking functions using relative relevance judgments[C]// Proceedings of the 30thannual international ACM SIGIR conference on Rsearch and development in information retrieval 2007:287-294.
[20] Bang Zhang, Getian Ye, Yang Wang, et al., Gunawan Herman: Finding shareable informative patterns and optimal coding matrix for multiclass boosting[C]// Proceeding of ICCV 2009: 56-63.
猜你喜欢
今日农业(2021年21期)2022-01-12
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
浙江大学学报(人文社会科学版)预印本(2020年6期)2020-11-16
学生导报·高中版(2019年4期)2019-09-10
中华胰腺病杂志(2019年4期)2019-08-29
阅读与作文(英语高中版)(2018年8期)2018-12-28
新高考·英语基础(高一)(2016年7期)2017-07-06
山东工业技术(2016年15期)2016-12-01
现代商贸工业(2016年35期)2016-04-09
