
基于统计方法的蒙古语依存句法分析模型
2012-06-29 05:53劳格劳华沙宝萨如拉
中文信息学报 2012年3期
斯·劳格劳,华沙宝,萨如拉
(内蒙古大学 蒙古学学院,内蒙古自治区 呼和浩特 010021)
1 引言
蒙古语文信息处理工作始于20世纪80年代,虽然起步较晚,但发展很快。经过30余年的努力,语料库、语法信息词典等基础性建设初具规模,编辑排版系统、办公软件等已实用化,各种蒙古文网络资源也正在稳步增长。从处理层面上看,初步完成了字、词处理阶段的基本任务,现已步入句处理阶段。目前,通过国家自然科学基金项目《现代蒙古语树库的构建》,正在进行树库资源的建设和自动句法分析研究。
纵观各种语言以往的句法标注及分析情况不难发现短语结构语法占据着主流地位,但近年来,依存语法由于其形式简洁、易于标注、便于应用等特点受到了研究人员的重视[1],并在英语、汉语、德语、捷克语等语言句法分析中得到了广泛应用,在应用的过程中依存语法本身也得到了发展和完善。CoNLL(Computational Natural Language Learning)国际会议从2006~2009年连续四次把依存句法分析的评测列入其共享任务[2-4],由此可以看出句法分析和标注采用依存语法是未来的研究热点和发展趋势。
2 基于统计的依存句法分析模型
句法分析的思想是能够根据某种语法G给出一个句子s的句法分析树t[5]。在很多情况下,对于一个句子会有超过一种句法分析树,我们用T表示一个句子所有可能的分析树。在统计句法分析中,建模的目的是寻找一种评价函数,用概率值的大小排列分析结果,并输出最有可能的结果。分析树t的概率表示为:

(1)
基于统计的句法分析模型把歧义的消解问题转化为一个最优化的过程,即计算每种分析结果的概率,找出一棵概率最大的分析树t*,该过程可以表示为:
t*=arg maxP(t|s)

(2)
随着机器学习方法的快速发展和数据资源的不断丰富,基于统计的依存句法分析也在不断地变化着,当前比较常见的建模方法有生成式依存模型和判别式依存模型。每种模式下也有多种不同的处理技术。本文采用了词汇依存概率模型,它属于一种生成式依存模型。
3 蒙古语词汇依存概率模型
句法分析实质上就是语法歧义的消解过程,而歧义消解是在多种信息的支撑下完成的。消歧所用的各类信息中,词汇本身最具区别能力,因为语言在词汇层面上很少出现歧义现象。但受树库规模限制,基于词汇的统计模型[6]在句法分析中的应用近几年才逐渐开始。
有限的词汇构成一个句子,可以表示为:
S={
其中,wi表示句中第i个词(1 ≤i≤n),fi表示词wi的形态特征,ti表示词wi的词类及子类标注信息。此时,我们可以把上述式(2)表示为:

(3)
为了计算P(t|
(4)
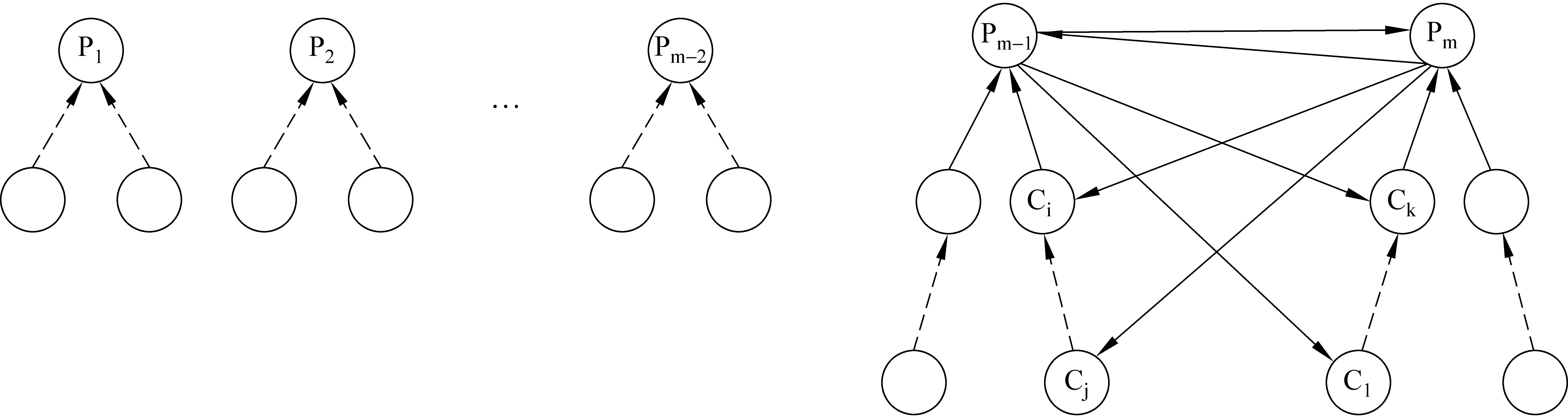
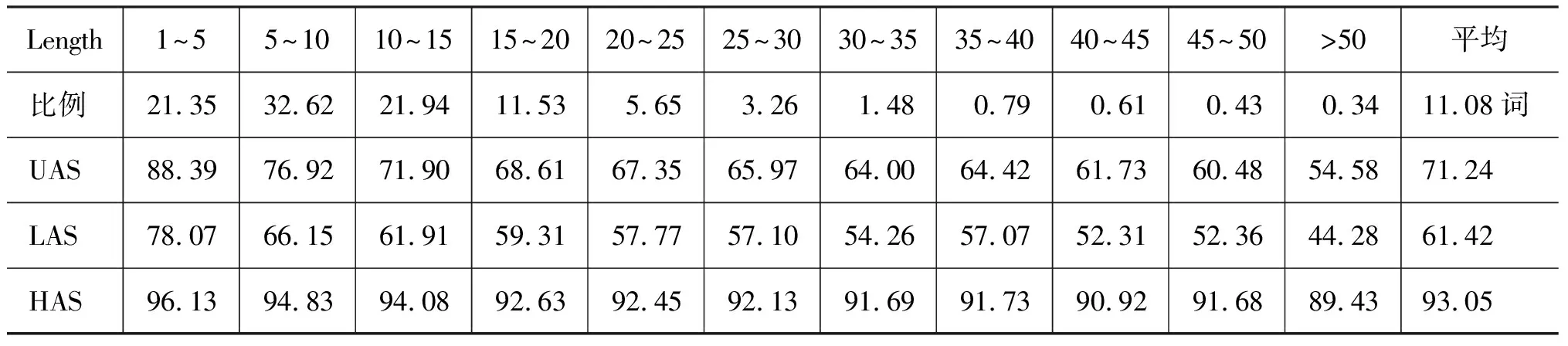
其中,Aij为两个词wi,wj(1≤i,j≤n;i 蒙古语具有丰富的形态变化,另外我们在机器词典中设置了词类和细分类特征,消歧算法可以采用词汇本身,也可以采用词类信息、子类信息、语义信息以及结构信息等。独立假设后,每一条依存弧的概率由两个端点wi和wj唯一确定。为了缓解树库资源规模不足导致的词汇信息数据稀疏问题,本文在利用词汇本身的基础上充分利用了支配词和从属词的词类特征、子类特征、形态变化特征(主要是格和动词形态变化)计算了每条弧的依存概率。另外,为了在一定程度上克服独立假设所带来的信息丢失问题,也考虑了前后词的词类特征。依存弧的概率由P1(Aij)=P(Aij|Wi,Wj)、P2(Aij)=P(Aij|CATi,CATj)、P3(Aij)=P(Aij|SUBCATi,SUBCATj)、P4(Aij)=P(Aij|CATi,MORPHi,CATj)、P5(Aij)=P(Aij|CATi,MORPHi,Wj)、P6(Aij)=P(Aij|Wi,CATj)、P7(Aij)=P(Aij|CATi-1,CATi,CATj,CATj+1)等七项构成。 除两个端点外,依存距离也是影响依存概率的重要因素,恰当的依存区间的划分方法能够提高整个句法分析的准确率。依存区间怎么划分没有固定方法,在句法分析过程中进行微调,根据分析器的表现最终确定。但总体上讲,划分的区间数目不宜过多,也不宜过少,划分多了产生数据稀疏问题,划分少了降低模型的描述能力。本文经过试验把依存区间Distance划分成了如下的三档: 式中,abs表示取绝对值,i,j分别表示两个端点的位置。本文在训练树库上进行统计,然后采用极大似然估计方法分别计算了P1至P7。Pk的计算公式为: (5) 式中,1≤k≤7,Ni,Nj分别表示支配词和从属词相关特征。(Ni,Nj)可以取{(Wi,Wj),(CATi,CATj),(SUBCATi,SUBCATj),(CATi,MORPHi,CATj),(CATi,MORPHi,Wj),(Wi,CATj),(CATi-1,CATi,CATj,CATj+1)}中的一个。Count(Aij,Ni,Nj)表示节点Ni,Nj之间存在依存弧Aij的次数,设其依存区间为Distance。Count(Ni,Nj)表示节点Ni,Nj以Distance距离出现的总次数,包括构成依存关系的和不构成依存关系的。我们用式(5)分别计算了上面列出的七种概率,计算结果存储在统计信息库中。在解码算法中,先从统计信息库查找概率值,然后进行插值平滑获得了依存概率P。 P=λ1P1+λ2P2+λ3P3+λ4P4+λ5P5+λ6P6 +λ7P7+λ8ξ (6) 其中,λ1+λ2+λ3+λ4+λ5+λ6+λ7+λ8=1,ξ=0.001。参数的初始值是按经验设置的,在试验过程中根据分析器的性能反馈进行了微调。λ1=λ4=0.2,λ5=0.15,λ2=λ3=λ6=λ7=0.1,λ8=0.05。 我们在已建立好的统计信息库和依存概率计算公式的基础上研制了一部基于统计的蒙古语句法分析器MParser。分析算法采用了一种基于分治的局部寻优策略[7]。其中,分治是指分两步分析句中的前焦型依存关系(支配词在前)和后焦型依存关系(支配词在后)。除特殊情形,蒙古语辅助关系和总括关系为前焦型依存关系,其余的依存关系为后焦型依存关系。具体分析时先标注前焦型依存关系,后标注后焦型依存关系。 标注前焦型依存关系时从句子末尾开始顺序读取词语节点, 并从位于当前节点左侧的节点中寻找能够构成前焦型辅助关系的词语节点,如果找到,则建立依存关系,否则读取下一个节点。从当前节点左边的节点中搜索满足条件的节点时为了缩小范围,算法把搜索限制在当前片段中,这就是局部寻优的含义。具有唯一核心词的连续出现的一段词语称为句法片段。一个片段可能是一个单词、短语、成分句或分句。两个片段通过之间的依存关系可以构成更大的片段。句法片段的左右边界或其中的一个边界通常可以通过标点、词类以及特定的词汇和结构信息来确定。在蒙古语句法片段的切分中,逗号、动词、连接词(包括联系动词)和语气词是主要标志信息。 分析后焦型依存关系时,依存关系是在两个相邻的子树(包括叶子节点)之间发生的。我们选两个特殊节点R和L。R位于右侧子树,并且离左侧子树根节点最近。L位于左侧子树,并且离右侧子树根节点最近。两棵子树之间的依存关系为下列情形之一(图1),要么左侧子树的根节点依存于R或R的祖先节点,要么右侧子树的根节点依存于L或L的祖先节点。算法中节点搜索被限制在R和L的祖先节点中,这也是局部选优的含义之一。当依存关系类型被确定为后焦型依存关系时,我们只需判断左侧子树与右侧子树中R或R的祖先节点相结合的可能性。 一个具有n个词的蒙古语句子经词切分和片段划分后变成如下形式: W1W2… Wi|| Wi+1Wi+2… Wk|| … || WmWm+1… Wn 其中,Wi表示词语,||表示片段切分。分析是从位于最右边的两个节点开始的,经过多步分析后一个句子变成如下形式(如图1所示)。 图1 分析算法示意图 图中,虚线表示两个端节点之间有n层节点,P1,P2,…,Pm-2,Pm-1,Pm分别表示各个子树的根节点,Ci,… ,Cj,Ck,… ,Cl表示两棵子树中与当前分析相关的子孙节点,这些节点均位于两棵子树的邻接面上,也就是说,在以Pm-1为根的子树中,这些子孙节点均为其父节点最右侧的孩子节点,在以Pm为根的子树中,这些子孙节点均为其父节点最左侧的孩子节点。下一步的分析将在Pm-1、Ci、… 、Cj和Pm、Ck、… 、Cl之间进行,如同图中的箭头所示。可能产生依存关系的节点组合有:Pm-1→Cl;Pm-1→Ck;Pm-1→Pm;Pm→Ci;Pm→Cj;Pm→Pm-1;那么到底哪两个节点之间产生依存关系,取决于两个节点之间的结合能力。计算每一组可能结合的概率,再按概率值进行排序,得分最高的一组建立依存关系,本次分析结束。经过上面的分析,Pm-1和Pm被合并为一棵树,合并后的树再与Pm-2合并。以此类推分析完所有子树为止。 (1) 词法分析:词法分析包括复合词识别、词类标注和构形附加成分的识别等三个任务。这个过程是通过蒙古语词法分析软件实现的[8]。在每个词语后面的花括弧里标注了词法信息。标注时分别用“/”和“;”隔开了同类和不同类信息。特别说明的是对主格没有标注形态信息。ENE{R/Rj} BAGVDAL-VN{N;Fc1} EMUN_E{0/0n/c1/c4} NIGE{M;Fm0} BUDUGUN{A/Ac}VDA{N} BVI{S/Sb} , TEGUN-U{R/Rj;Fc1} DEGER_E{0/0n/c0/c1} HEDUN{R/Ra/mRa} JAGVN{M/Fm0} VRAN=SIBAVHAI {N/Nn}0ND0RCV{V/Ve/Ve2;Fn1} BAYIN_A {V/Vz/Vz1;Fs2}. (2) 片段切分:按照定义将例句切分为“ENE BAGVDAL-VN EMUN_E NIGE BUDUGUN VDA BVI ,”和“TEGUN-UDEGER_E HEDUN JAGVN VRAN SIBAVHAI 0ND0RCV BAYIN_A.”两个片段。 实验表明,如果一个句子中只有前焦型依存关系或者只有后焦型依存关系,那么这个句子的分析难度会大大降低。真实文本中这种句子很少,但句法分析的某个阶段子树之间的依存关系可以变为纯前焦型或纯后焦型关系。为了达到这种目的,我们在句法分析算法中先标注了前焦型依存关系。分析时从句子或片段右端开始两两配对,如果两个节点的属性特征满足某条规则的条件,则其间建立依存关系。为了便于描述,我们用词语在句中的位置代替了词本身。分析过程如图2、3、4所示。 图2 前焦型依存关系标注 图3 后焦型依存关系标注 图4 片段合并后生成的依存树 实验数据采用了内蒙古大学蒙古语文研究所建设的中学蒙古语文依存树库MDTB(Mongolian Dependency Tree-Bank),该库共有461 240个词,31 722个句子,每个句子的平均长度为14.54个词。全部实验中,以第二册至第十一册为训练语料,包含26 737个句子,402 432个单词,平均句长为15.05个词。以第一册和第十二册为测试语料,包含4 985个句子,58 808个单词,平均句长为11.80个词。我们以无标记准确率(只有依存弧,没有类型标记,Unlabeled Annotation Score,UAS)、有标记准确率(有依存弧,也有类型标记,Labeled Annotation Score,LAS)和核心词的准确率(Head-word Annotation Score,HAS)为指标评测了MParser。 由于句子长度对句法分析的准确率影响很大,我们统计了测试集中句子的长度分布,并对不同词长的句子分别进行评测,下面是评测结果,如表1所示。 表1 MParser的评测结果 从实验结果看,核心词查准率非常高,这是因为蒙古语是核心词后置的语言,句中除一些辅助成分,核心词一般出现在句末。在蒙古语依存句法分析中,核心词一般为谓语动词,另外,充当谓语的其他词类也可以成为句子核心词。LAS比UAS低十个百分点左右,这是由同型结构引起的。例如,与格形式的名词有时充当状语,有时充当间接宾语,很难判断,但其依存对象的判断相对简单一些,因此UAS和LAS的分数出现了较大的差距。通过扩充训练语料可以提高LAS值。 [1] 刘海涛. 依存语法和机器翻译[J], 语言文字应用,1997,(3): 89-93. [3] Mihai Surdeanu, Richard Johansson, Adam Meyers,et al. The CoNLL-2008 Shared Task on Joint Parsing of Syntactic and Semantic Dependencies[C]//Proceedings of the Twelfth Conference on Computational Natural Language Learning (CoNLL 2008). Manchester, UK, August 16-17, 2008: 159-177. [4] Joakim Nivre, Johan Hall, Sandra Kübler, et al. The CoNLL-2007 Shared Task on Dependency Parsing[C]//Proceedings of the CoNLL Shared Task Session of EMNLP-CoNLL 2007. Prague, Czech Republic, June 28-30, 2007: 915-932. [5] Eisner, J.M.. Three new probabilistic models for dependency parsing: An exploration[C]//Proceedings of ACL-1996. University of California, Santa Cruz, California, USA, June 24- 27, 1996: 340-345. [6] M. Collins, Three Generative. Lexicalized Models for Statistical Parsing[C]//Proceedings of the 35th annual meeting of the association forcomputational linguistics, Madrid, Spain. July, 1997: 16-23. [7] 马金山,基于统计方法的汉语依存句法分析研究[D],哈尔滨:哈尔滨工业大学,2007. [8] S.Loglo, HuaShabao, Sarula. Research on Mongolian Lexical Analyzer Based on NFA[C]//Proceedings of 2010 IEEE International Conference on Intelligent Computing and Intelligent Systems (Volume 2), Xiamen, China, October 29-30, 2010: 240-245.4 依存概率计算

5 基于统计的依存句法分析
5.1 算法描述
5.2 算法示例




6 实验及分析
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
心理学报(2022年5期)2022-05-16
中文信息学报(2022年3期)2022-04-19
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(英语备考)(2019年10期)2019-12-16
现代交际(2019年17期)2019-11-13
记者观察(2019年14期)2019-11-08
草原歌声(2019年1期)2019-07-25
