
PCA算法在P2P加密流量识别中的研究与应用
2012-06-25 03:31罗丞,叶猛
电视技术 2012年3期
罗 丞,叶 猛
(武汉邮电科学研究院电信系,湖北 武汉 430074)
随着宽带互联网时代的到来,用户对信息实时性的需求越来越高,随之出现了基于P2P技术的宽带共享工具。这类工具给用户带来了高实时性的体验,但同时也给宽带运营商带来了监管困难的窘境,识别这些应用产生的流量是目前运营商关注的重点。因此,针对P2P应用流量的识别技术应运而生。
目前主流的应用层协议识别技术主要分为以下3类[1]:基于应用协议固有特征的识别技术,应用层网关识别技术和行为模式识别技术。
基于P2P技术的软件将网络上原本孤立的服务器资源及P2P资源整合在一起,这使得其信令交互部分特征较为明显,而数据下载部分由于加密导致特征模糊。传统的指纹匹配技术致力于从算法优化角度改进匹配速度,但是在面对特征更加模糊的加密流量时,必须综合多种特征从多维度来识别,多维度带来的直接问题就是算法的复杂度呈指数级上升,太多特征导致系统处理过慢,用户响应时间过长,严重影响系统使用,而如果能够以较少量的特征来识别流量就可以加快识别过程,提升用户使用感受。当所要分析的对象特征太多、维度太高时,可以尝试通过某些有损的降低维度算法来降低冗余维度,保留主要维度,使得所分析对象特征更显清晰[2]。
尽管P2P加密流量的特征有很多,但可以通过降维来获取有用的少量特征。在本文中,采用主成分分析(Principal Component Analysis,PCA)[3]来使得 P2P 加密流量的复杂特征降维,以降低多维匹配带来的复杂性。
1 PCA算法
1.1 PCA 算法原理
已知有n个d维数据样本x1,x2,x3,…,xn,指定其中一点Q(q1,q2,q3,…,qd),求在总的样本中与之距离最近的k个点。
计算步骤如下:
1)首先求散布矩阵(离散度矩阵)
先对n个样本的每一维数据进行处理,求出n个样本每一维对应的均值,即得d个均值m1,m2,m3,…,md。然后用每个样本点的每一维数据与相应维的均值作差,对于每一个样本点即得 xi1-m1,xi2-m2,xi3-m3,…,xid-md这d个数据(其中xi表示n个数据中下标为i对应的数据类),然后以这d个数据构造一个d行1列的矩阵,接着求其转置矩阵,原矩阵与转置矩阵相乘即得到一个d行d列的对称矩阵。最后将这n个对称矩阵进行矩阵加法运算即得到离散度矩阵。
2)得到离散度矩阵后,求出该矩阵的d个特征值及相应的特征向量,在求解特征值与特征向量时,由于由第一步知道,所求的离散度矩阵是对称矩阵,故可采用雅可比法求矩阵的特征值与特征向量,然后将其特征值按大小递减顺序进行排序。
3)取第一个,也就是最大特征值对应的特征向量e,作为后面投影操作参照向量。
4)将样本中的所有数据类,投影到特征向量e上,投影操作方法就是由数据类的d个数据构成的一个行向量与列特征向量e作矩阵乘法运算,故由此得到n个点的投影坐标t1,t2,t3,…,tn,将这n个投影坐标进行排序,然后求出所求点对应的投影坐标值。找到该坐标值后,以该点为中心,向两边展开搜索,直到找到k个临近数据类满足要求。
5)由于两个数据类之间的真实距离大于或等于投影距离,即d(x,Q)≥d(tx,tq),由于已经将所有点的投影点进行了排序操作,故以所求点Q对应的投影点tq为起始点向两端逐个搜索,找到k个数据类,然后将这些数据类与所求点之间的距离计算出来,对其进行排序操作(如按大小递减排序),则第一个为dmax,以后向两端每搜索一个点,就先计算数据类与所求点之间的投影距离,如果该距离小于dmax,则该数据类可能是要求的k临近点中的一个,之后需要计算它与所求点之间的真实距离,再与已经存放的k个数据类对应的距离进行比较,选择是插入还是舍弃。如果搜索到数据类的投影值与所求点对应的投影值之间距离大于dmax时,则搜索停止进行。
1.2 加密数据处理
上述算法过程结合到具体的数据包特征识别上,就是每个样本都是一个独立的以太网数据包,这些样本的维度就是数据包的相应特征,这些特征应该由包长度、端口号、上层协议类型、某些位置的字节值(变长,由于不同的P2P应用具有不同的通信结构,具体的字节特征应该根据不同的应用来确定,高维特性也就表现在这里)等构成。根据上述算法得到离散度矩阵C=A AT,A的每一行是一种特征差,A的列数就是数据包的个数。算法就是求矩阵C的特征向量。为了简单,只取其中部分的特征向量,这些特征向量对应于某些特征值,通常是前M个大的特征值。这样便得到了M个特征向量。接下来就是将每个包在这M个特征向量上作投影,得到一个M维的权重向量w=(w1,w2,…,wm),一个P2P流有多个包,于是将对应于这个P2P流的权重向量求平均作为这个流的权重向量。对于每个新来的包,先求得一个权重向量,与流库中每个流的权重向量作比较,如果小于某个阈值,则认为其属于已知P2P流,否则丢弃。
2 P2P加密流量识别方案
针对PCA对于高维数据的优势,在识别具体业务流量之前首先分析该业务的软件行为,通过抓包摸清楚该业务的更多详细特征,特征越多,识别精度越高。在此基础上应用PCA算法降维度,保留有用特征,提高系统识别实时性,从而达到兼顾实时性与识别率的较好状态。
2.1 软件行为分析
通过对P2P工作原理的研究,可以将P2P的通信数据按照其行为模式分为以下3类[4]:
第一类是初始化通信过程,该过程主要完成P2P用户入网注册、广告接收、信息同步等功能,其特点是服务端端口固定,载荷区特征明显。对于这部分数据采用“端口+流+特征”模式来识别,记为A模式。
第二类是P2S通信过程,该过程主要完成同种资源搜索、多点资源下载、本地资源上传等功能,其特点是服务端端口较为固定,载荷区数据加密但特征固定,请求包长度较固定。对于这部分数据采用“端口+流+特征+包长度”模式来识别,记为B模式。
第三类是P2P通信过程,该过程主要完成对点资源下载、本地资源上传等功能,其特点是服务端端口动态变化,载荷区数据加密但比特序列有规律。对于这部分数据采用“流+字节特征”模式来识别,记为C模式。
有了分类的数据,再有针对性地对不同的类别进行不同模式的抓包识别。为了对P2P流量进行有效的分析,定义以下术语:
1)流:用五元组来标识一个连接,即源IP、源port、目标IP、目标port、传输层协议[5]。一个数据包到来后先识别它是否属于已知流,如果属于即直接返回,这样可以节省大量的CPU资源。
2)字节特征:数据包载荷区字节的综合规律。这些规律需要人为的挖掘,通过对数据包的反复阅读和猜测来确定某种字节序列[6]。例如迅雷的P2P加密流量,其中有很大一部分数据包载荷区的前4 byte符合“0x**000000”的特征,“**”为非零值。
3)识别优先级:把识别规则按照一定顺序分配不同优先级,优先级高的先识别。这里把“流”列为最高优先级,其次是“端口”、“特征串”、“字节特征”、“包长度”。
2.2 代码实现
结合上述思想可以将程序分为4个模块[7]:
1)程序初始化模块
该模块主要实现读取配置文件(流库的权重参数)、启动其他模块线程的功能。
2)数据包采集模块
Libpcap是Unix下非常方便的数据包截获API,利用Libpcap函数库可以编写抓包模块,实现从服务器的指定网卡抓包[8]。首先定义网卡描述符,再通过pcap_open_live函数打开指定网卡并循环抓取线上的数据包。
3)数据包处理模块
抓取的数据包经过该模块的处理应该可以顺利地标示出属于P2P的流量。首先定义一系列表示TCP/IP协议栈各层包头的结构体,定义五元组结构体(即“流”结构体,再包含一些标识位),并声明一个“流”指针的容器,利用pcap_loop函数对每一个抓取到的数据包进行回调函数的处理,这里的回调函数可以定义并实现操作数据包的方法,根据识别优先级来对数据包进行层层过滤和分配。首先提取数据包的五元组信息,根据这些五元组找出其所属的流,查看此流是否已经存在,用一个泛型指针遍历“流”容器,如果此流已经存在并且已经进行了标识,则直接返回。否则,新建一个流,并且提取该包相关特征,依据PCA算法得到经过处理后的特征权重、再将该权重与已知流的权重作比较,以此来判断该包是否属于P2P通信。
4)统计输出模块
该模块每隔一段时间打印一次数据包处理结果,其中包括总抓包数目、已识别的包数目、识别率等信息。
3 实验步骤及结果分析
P2P应用包含范围很广,从下载到共享无所不包,鉴于文章篇幅有限不能完全包括,本次实验就P2P下载应用中具有代表性的迅雷工具作为实验对象,采集的样本数据为预先在真实环境下抓取的完整的迅雷下载包,所提取的多维特征为迅雷在未下载、BT下载、电驴下载这3种情况下的流特征(迅雷在未下载时为A模式,BT及电驴下载时为B+C混合模式),流库中保存的权重参数由上述3种情况下分别经过计算得出,例如迅雷在C模式下的某一种流,其前几个包的长度大概在40 byte左右,采用UDP(用17表示)传输,载荷区特征为0x32000000**(**为可变非零字段,经过计算的平均值为0x06,计算时转换为十进制),这些特征便可以标识为{40,11,50,0,0,0,6}的均值,再将几个样本对上述均值分别求差,并按照算法步骤逐步求解(注意求差过程中仅计算包长度等变量即可),最终可得到该种类型的P2P流的权重,将权重值记录在流库的配置文件中,这样便可以模拟真实环境下迅雷流量的识别,并且可以保证没有杂包。
实验服务器配置为CPU:Intel Xeon E55042 .0GHz×8(8核心),内存为16 Gbyte。
实验步骤如下:
1)在配置文件中配置网络信息,如抓包口配置为eth0;
2)打开编译好的程序文件,等待其初始化完毕;
3)利用服务器的发包软件对eth0口进行发包;
4)观察程序打印结果,生成数据文件并使用gnuplot绘图,分析实验数据。
图1所示为HTTP情况下的P2P加密流量权重图,图中每个点都代表一个流的权重,其中左起第一个点为配置的阈值权重,其他低于该点的代表能够识别出的流,高于该点的则为未识别的流。由图1可知HTTP方式下流量分布较为均匀。
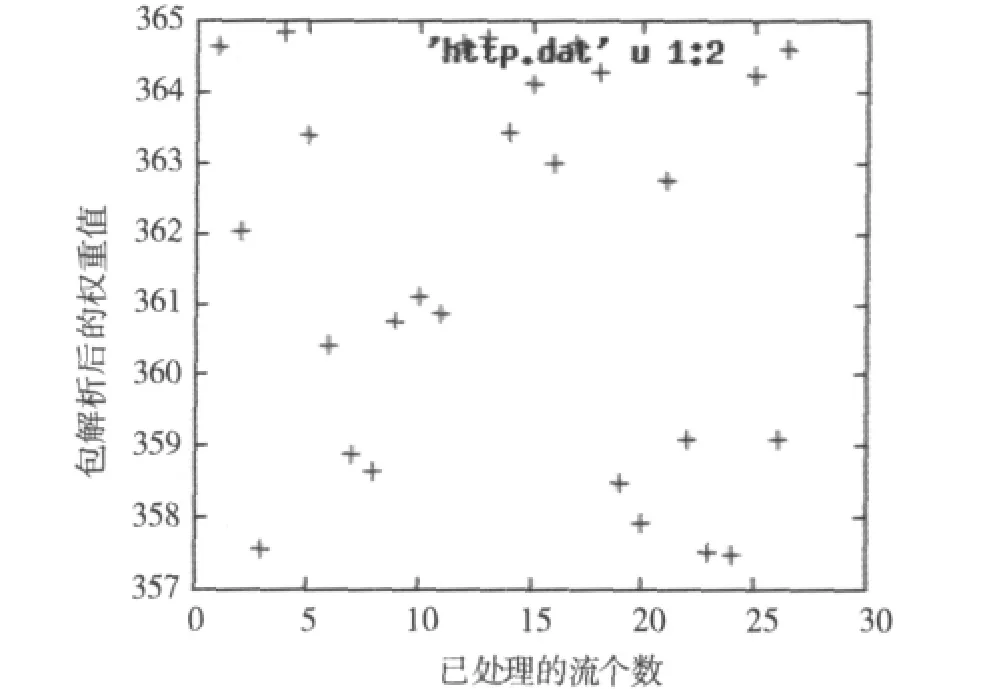
图1 HTTP方式下权重比较
图2所示为BT情况下的P2P加密流量权重图,解图方式同图1。图2中的数据显示出BT方式下权重的分布情况,可以看出流量分布比较密集,大都分布在阈值权重附近。
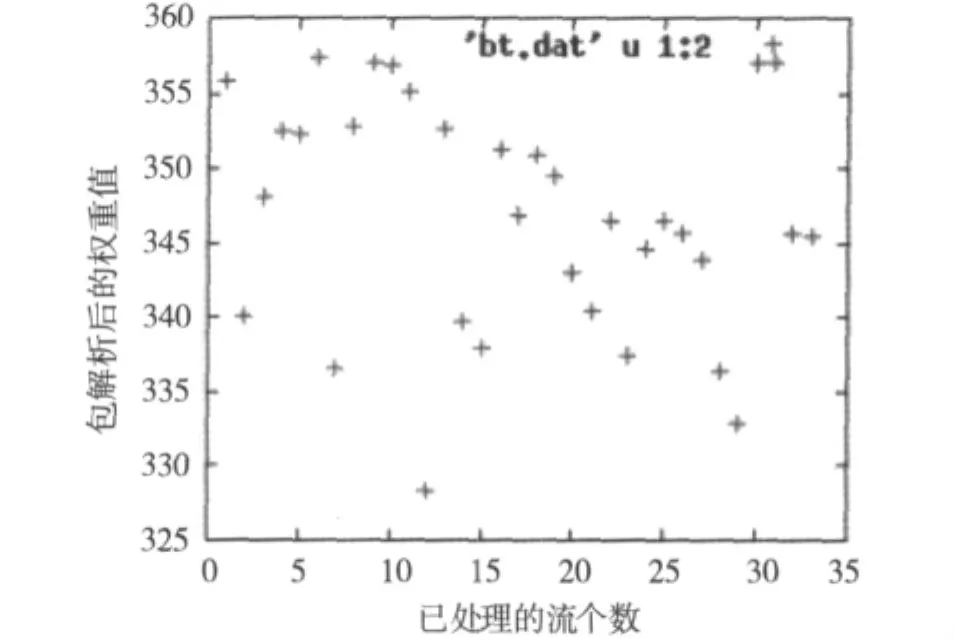
图2 BT方式下权重比较
如图3所示为EMLUE情况下的P2P加密流量权重图,解图方式同图1。由图3可以看出EMLUE情况下的流量分布也比较密集,这从侧面说明同种P2P类型的下载流量之间特征相似度较高。
上述实验中所发的包分别对应着迅雷在HTTP下载、BT下载、电驴下载的包,为了保证测试结果的普适性,上述3种模式的迅雷包分别在不同的计算机上抓取。表1所示为实验所得的具体识别率。
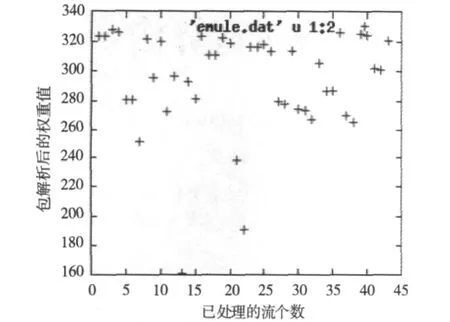
图3 Emule方式下权重比较
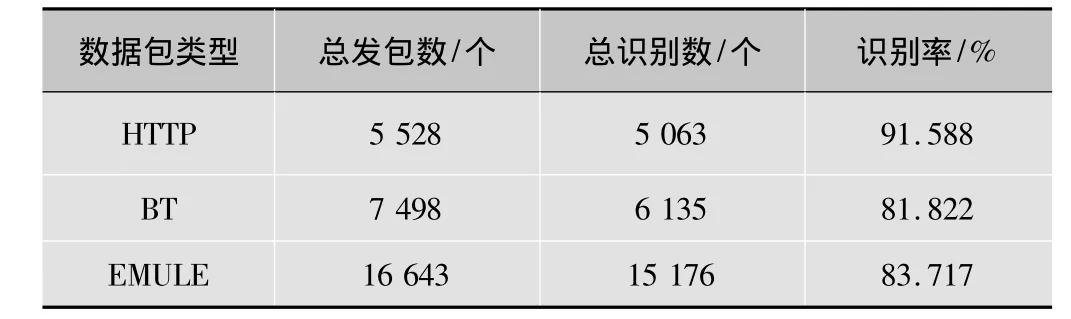
表1 3组不同模式的迅雷流量识别率对比
表中的数据显示迅雷流量在HTTP方式下识别率最高,其次是BT和电驴,未识别的流量中包含了少量的无规律加密数据以及无实际数据的杂包,这部分流量可以在后续工作中再作识别或剔除处理。综上所述,将PCA方法引入P2P流量识别的策略是可行的,并且是有效的。
为了与其他协议识别方法作出比较,如表2所示为从实时性、准确性、对加密流量的识别率这3个方面来考察特征串识别、PCA识别以及流行为特征识别3种方法的优劣。

表2 3组不同识别方法的优劣对比
相对于传统特征串识别来说,PCA算法可以适应更大规模特征而不损失效率,实时性很高;相对于不检测载荷的流量行为特征模型来说,PCA算法可以更加精确到识别定位哪一种业务在吞噬网络带宽,更有效地为运营商提供判断依据;而在加密流量识别上,PCA具备多特征识别的天然优势,更多的特征并不会对PCA产生很大影响。
4 小结
P2P流量的识别已经成为网络管理中的重要部分,本文利用Wireshark软件,采用逆向工程的方法,分析和研究了P2P的工作原理和通信过程,提取其通信过程中的流特征,但是P2P应用由于其流量加密的复杂性导致特征呈现高维型,而一般的特征串匹配算法都是从改进算法的角度来加快识别速度,本文尝试引入PCA算法,希望在不损失识别率的情况下对P2P流特征进行降维处理,减少需要处理的特征数,从而加快对P2P流量的识别。由于PCA一般在人脸识别和神经网络等领域应用较成熟[9],在网络流量识别方面尚没有成熟的使用模型,因此这一方法虽然可行,但还有很多工作有待进一步深入研究。
P2P共享技术发展的过程是一个不断规避检测的过程,这就给识别技术不断带来新的挑战,应用协议也在不断改进,其特征也在不断变化,因此流量识别方法也需要随之进行不断尝试和调整。
[1]王锋.IP业务识别与控制系统(DPI)的发展现状与思考[EB/OL].[2008-11-13].http://www.lmtw.com/tech/Using/200811/47956.html.
[2]王敏,李纯喜,陈常嘉.浅谈基于PCA的网络流量分析[J].微计算机信息,2006,22(6):94-95.
[3]张媛,张燕平.一种 PCA算法及其应用[J].微机发展,2005,15(2):67-68.
[4]蒋海明,张剑英,赵二涛,等.PPLive网络电视通信机制研究[J].电视技术,2009,33(12):61-63.
[5]陈亮,龚俭,徐选.基于特征串的应用层协议识别[J].计算机工程与应用,2006,24(4):16-19.
[6]殷晓丽,田端财.P2P流量识别技术分析[J].科技资讯,2009(8):16-17.
[7]胡文静,李明,刘锦高.基于LIBPCAP的网络流量实时采集与信息萃取[J].计算机应用研究,2006,1(6):236-238.
[8]MOORE A W,PAPAGIANNAKI K.Toward the accurate identification of network application[C]//Proc.PAM2005.Boston:MA,2005:41-54.
[9]浅谈 PCA 人脸识别[EB/OL].[2011-05-01].http://leen2010.blogbus.com/logs/124631640.html.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
计算机与数字工程(2022年3期)2022-04-07
保定学院学报(2022年2期)2022-04-07
电脑与电信(2021年9期)2021-12-21
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
网络安全和信息化(2018年4期)2018-11-09
许昌学院学报(2018年4期)2018-05-02
