
基于Lucene的校园网搜索引擎的设计与实现
2012-05-27 02:51吴建
湖南工程学院学报(自然科学版) 2012年2期
吴 建
(重庆邮电大学 数字图书馆技术部,重庆 400065)
0 引 言
随着局域网技术的发展,很多大学校园网内的信息量也迅速增加,仅仅依靠人工查询的方式在校园网查询所需要的信息不仅效率低下,而且费时费力.在互联网领域,文本信息的检索一直是大规模信息处理学科中的一个研究热点[1],也是网络多媒体信息处理领域的重要研究方向.随着对基于全文的文本搜索技术的不断探索,搜索引擎技术在信息处理的各个领域应用越来越广泛.目前,人们比较认可的搜索引擎像谷歌、百度、雅虎等商业搜索引擎虽然搜索功能强大,但同时也具有一些不足之处,如公平性[2]、竞价排名等.
同时,由于网络设计的限制很多商业搜索引擎并不能搜索到校园局域网中的一些信息,校园网已成为这些搜索引擎中的一个“盲点”,因此,本文对搜索引擎的原理和技术进行的深入分析,并在此基础上设计和实现了基于Lucene的校园网搜索引擎.Lucene[3]是一个开源的全文检索引擎工具包,它也是Apache软件基金会项目组的一个子项目.同时,由于Lucene在技术和架构方面的出色表现,某些商业软件也采用了Lucene作为其内部全文检索子系统的核心,Lucene为开发一个开源的局域网搜索引擎提供了技术可行性.
1 搜索引擎的实现原理
目前的搜索引擎主要是从互联网范围内搜索信息,几乎每个网民都会使用到搜索引擎来查询信息,搜索引擎已成为互联网上不可或缺的工具.
搜索引擎主要包括以下几个主要的模块:网络爬虫、索引器、检索器、用户接口[4].网络爬虫主要是以某种策略不断地在互联网上搜集和爬取信息;索引器将网络爬虫爬取的建立成索引文件;用户接口模块主要是提高人机交互功能,以方便用户使用;检索器是系统的核心模块,主要功能是根据检索条件在系统的索引库进行信息检索,并将搜索结果返回给用户,不同的搜索引擎的具体模块可能有不同的变化和扩展[5].
2 系统体系结构设计
根据对系统功能的分析,系统的运行流程主要包括信息爬取、建立索引库和信息搜索三部分,其结构如图1所示.
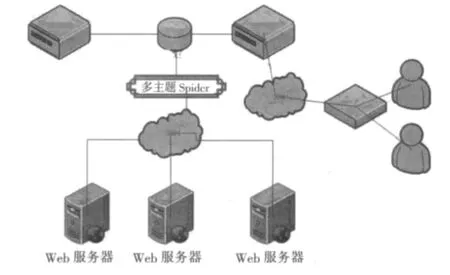
图1 系统体系结构图
在图1中,系统首先利用多主题Spider(网络爬虫)程序,从校园网上不断地爬取各种网页和文件数据,并将爬取的数据根据主题进行分类等处理.网络爬虫一般从初始URL开始,从当前的页面中通过链接抓取新的URL,以此不断地向 WWW发出页面访问请求,并将获取的网页和其他文件数据保存到文件库中.
建立索引就是由系统的索引器对文件库中的文件进行分析和过滤,提取有价值的数据信息,并将其写入到索引库中的索引文件中.当用户进行搜索时,由检索器到索引库中进行检索,并将检索结果进行相关性排序后返回给用户.
3 系统功能设计与实现
3.1 网页信息爬取
基于Internet的网络爬虫程序从URL种子队列开始爬取,不断从当前页面抽取新的URL放入待爬行队列,直到满足系统设计的广度或深度策略的停止条件[6].
本系统使用多主题网络爬虫获取网页信息,以便索引管理和用户进行分类检索,其工作流程如图2所示.

图2 基于Internet的主题网络爬虫工作流程
基于校园网的网络爬虫需要遵循一定的调度策略从URL队列中选择下一步要抓取的链接,同时对已抓取的文件记录作为反馈信息来指导后续的网页抓取任务.在本系统中,在爬取WEB信息时需要获取多个主题的信息,因此,在爬取的过程中,不需要过滤与主题无关的链接,而是根据爬取的主题对文件进行分类.
3.2 索引建立模块
一般情况下,网络爬虫会不断地从校园网内爬取大量的网页和其他数据,并保存在文件库中(包括html、php、jsp、asp、doc、txt、pdf、xml、xls等格式的文档),而且搜索引擎需要对这些原始数据信息进行处理后,才能为用户提供信息搜索服务.处理过程包括文件信息过滤、信息抽取、建立索引库、索引库优化等步骤.文件信息过滤主要是将各种文件中无价值的字符串过滤掉;信息抽取主要是从过滤后的文件信息中提取文件标题和其他感兴趣的信息;建立索引库就是将所提取到的信息写入到索引文件中,索引文件是一种由词典(Dictionary)和分块倒排列表(Posting lists)组成[7];索引优化主要是对索引文件进行优化,以提高系统的检索速度.
由于Lucene是以词为基础建立全文索引,因此,在建立索引之前必须进行中文分词,本系统采用中科院je-analysis-1.5.3工具包实现该功能.全文索引又称为倒排索引,它首先用正想索引来存储每个文档对应的单词列表,然后再建立倒排索引,并根据单词来索引文档编号.在本系统中,为了提高用户搜索的准确性,我们建立了多主题索引库.
下面以网页文件为例进行说明,其程序流程图如图3所示.

图3 网页信息建立索引的流程图
以上过程对应的主要代码如下:
//声明索引器
IndexWriter writer=null;
try{
//判断索引库是否为空,若不为空则以追加的方式添加新索引数据
boolean ExistFlag=SegmentsExist.se(Index-Dir);
//创建索引器,并设置参数
writer= new IndexWriter(IndexDir,new MMAnalyzer(),!ExistFlag,IndexWriter.Max-FieldLength.UNLIMITED);
//创建复合式索引
writer.setUseCompoundFile(true);
//判断文件编码方式
String encode=EncodeType.getType(Web-File);
//网页内容过滤
String WebCon = ReadWebFile.getCons(WebFile,encode);
//网页信息抽取
String WebCons[]=ReadWebFile.getCons(WebCon);
//利用索引器创建索引
Createindex(writer,IndexDir,WebCons);
//索引优化步骤
writer.optimize();
//关闭索引器
writer.close();
}catch(Exception e){
System.out.println(e.getClass()+“-message:”+e.getMessage());
}
}
3.3 信息检索与高亮显示
当用户输入关键字时,服务器端会对关键词进行预处理和中文分词,并生成最佳的检索式,然后利用Lucene的搜索功能到索引库中进行检索,并将检索结果返回到用户页面上.在这个过程中,系统需要对用户提交的关键词进行语义分析,根据分析结果到相匹配的主题索引库中进行信息检索,这样可以在很大程度上提高系统的检索准确性.
同时,系统会根据设置返回为每个搜索结果生成一段摘要,并根据用户所提交的关键词在搜索结果页面中进行高亮显示.
3.4 系统层次划分
考虑系统后期功能添加,数据库移植以及系统维护等,使用多层次设计模式,降低系统模块之间的耦合度.系统具体层次设计如图4所示.

图4 系统层次设计图
图4中,各个层次负责不同的功能.数据访问层封装所有的数据访问方式和操作方法.而业务层只调用数据访问层来获得数据,并按一定的业务关系来处理数据并返回.对于表示层中的网页则是调用业务逻辑层的对象的对应功能来实现功能.而层与层之间的数据传递和共享是通过构造实体类来存储信息.所有的层之间各司其职,将功能封装.在保持接口不变的情况下,任何一层的更改都不影响其他层.
在系统进一步功能添加时,可以就业务逻辑层进行对功能实现过程进行编码实现,在表示层添加对应功能页面即可完成.不需要修改原先所具有的功能模块.如果需要进行数据库更换或移植时,仅需要对数据访问层中的操作进行适当修改即可完成.
4 系统测试与分析
系统测试是针对整个产品系统进行的测试,目的是验证系统是否满足了需求规格的定义,找出与需求规格不相符合或与之矛盾的地方.本系统的主要功能包括网页搜索、资讯搜索、BBS搜索、文档搜索等功能.
当用户在首页上选择“全部”搜索标签并提交要搜索的关键词后,系统会为用户搜索相关的网页、文档等内容.系统运行效果如图5所示.
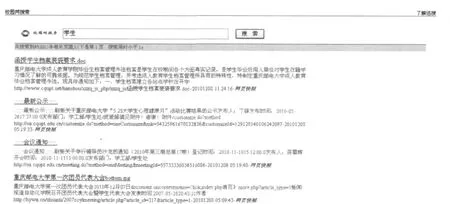
图5 全部网页搜索结果
当用户点击某一篇文章的标题时,浏览器将会在新的标签内打开该网页,如果搜索结果是一个文档时,在用户点击标题时系统将会提示用户是否下载该文档.
当用户在首页上选择“资讯”搜索标签并提交要搜索的关键词后,系统会为用户搜索相关的新闻网页.例如,当用户搜索与“新闻”相关的内容时,系统运行效果如图6所示.

图6 资讯搜索结果
当用户在首页上选择“文档”搜索标签并提交要搜索的关键词后,系统会为用户搜索相关的文档,主要包括.doc、.xls、.ppt、.pdf、.csv、.txt等类型的文档,并为用户提供下载链接.例如,当用户搜索与“计算机”相关的文档时,系统运行效果如图7所示.

图7 文档搜索结果
从以上运行效果图可以看出,本系统在校园网范围内可以较好地满足用户的搜索要求,并且系统具有良好的安全性和健壮性,具有一定推广价值.
5 结束语
基于Lucene的校园网搜索引擎在校园网环境中运行稳定,系统的容错性能较强,而且能满足大多数用户的搜索需求.同时,本系统在运行监控和均衡负载等方面还有较大的改进空间,本文的下一步工作是在系统中增加语音交互功能,用户可以通过语音来进行信息搜索,并对搜索结果进行语音播报,这样可进一步改善用户体验.
[1]邹燕飞,于成尊,赵 亮.基于Lucene的文本搜索引擎的设计和实现[J].计算机与现代化,2011,9(12):40-44.
[2]冯 斌.基于Lucene小型搜索引擎的研究与实现[D].武汉:武汉理工大学,2008.
[3]Apache Lucene,Apache Sol,Apache Lucene.NET etc[EB/OL].http ://ucene.apache.org/java/d ocs/index.html Apache Lucene,2011-03-01.
[4]薛建春.垂直搜索引擎中网络蜘蛛的设计与实现[D].北京:中国地质大学,2007.
[5]倪 晟,宁 洪.基于XML的搜索引擎相关度计算的改进[J].计算机工程与科学,2005,27(2):20-22.
[6]白 鹤,汤迪斌,王劲林.分布式多主题网络爬虫系统的研究与实现计[J].计算机工程,2009,35(19):13-16.
[7]郑榕增,林世平.基于Lucene的中文倒排索引技术的研究计算机技术与发展[J].2010,20(3):80-83.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
甘肃教育(2020年18期)2020-10-28
电子制作(2019年10期)2019-06-17
电子制作(2017年8期)2017-06-05
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
电子设计工程(2015年17期)2015-02-27
电子设计工程(2015年6期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
