
改进的HMM系统在英语语音合成中的研究
2012-05-15 08:08张雪英
太原理工大学学报 2012年1期
张雪英,陈 洁,孙 颖
(太原理工大学 信息工程学院,太原030024)
语音合成的目的是建立一个有讲话能力的计算机系统,以实现真正意义上的人机交互。基于大语料库的拼接合成方法[1]是近年来语音合成中的主流方法。其基本原理是根据输入文本分析得到的信息,从预先录制和标注好的语音库中挑选合适的单元,然后拼接得到最终的合成语音。虽然大语料库拼接合成系统保持了原始发音人的音质,但也存在不少缺陷,比如:合成语音的效果不够稳定,音库构建周期太长以及合成系统的可扩展性较差等,这些缺陷明显限制了它在多样化语音合成方面的应用。因此,近年来基于隐马尔可夫模型[2](HMM)的可训练语音合成方法被提出并逐渐得到应用。
基于HMM的语音合成系统对语音参数进行建模,然后利用音库数据进行自动训练,并最终形成一个相应的合成系统[3]。与现在大语料库拼接合成相比,其优势就在于可以在短时间内,基本不需要人工干预的情况下自动构建一个新的系统,而且整个训练过程基本上是不依赖于发音人、发音风格以及情感等因素。笔者研究了基于HMM的可训练语音合成方法,并将其原理应用到英语合成中。
1 基于HMM的可训练语音合成系统概述
图1是基于HMM的语音合成系统的基本框图,它包括训练和合成两个部分。在训练部分,首先,从语料库中提取谱参数和基频参数,然后利用上下文相关因素,对声道谱、基频和时长进行建模。本系统利用HTK进行训练。在合成部分,首先对输入的文本进行文本分析后,转化为与文本相关的标注序列,在此基础上,利用上下文相关HMM,通过HTS[4-5]构建句子 HMM,从而确定了各音素的合成参数,最后通过参数合成器[6]合成出语音。
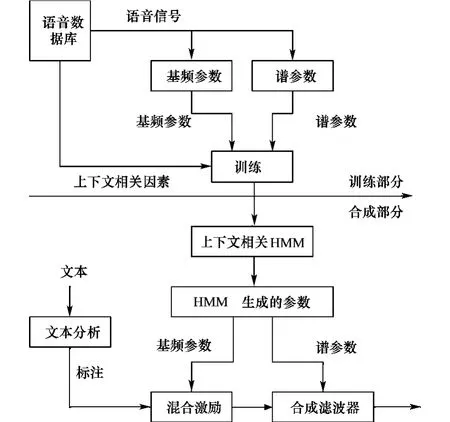
图1 基于HMM语音合成流程
2 英语语音标注
模型训练前有一个重要的部分就是对上下文属性集和用于决策树聚类的问题集进行设计[7],即根据先验知识来选择一些对声学参数(能量、基频和时长)有一定影响的上下文属性,并设计相应的问题集,以用于上下文相关模型。上下文属性与决策树设计的好坏会直接影响到最后合成语音的效果。因此,本文对英语的发音及语法特点进行了深入的研究,设计了与之对应的上下文属性集和问题集。
2.1 音节
音节是读音的基本单位,任何单词的读音,都是分解为一个个音节朗读。在英语中元音特别响亮,一个元音可构成一个音节,一个元音和一个或几个辅音音素结合也可以构成一个音节;辅音不响亮,不能构成音节。但英语辅音字母中有4个辅音[m],[n],[ng],[l]是响音,它们和辅音音素结合,也可构成音节。它们构成的音节往往出现在词尾,一般是非重读音节。
英语单词有一个音节的,两个音节的,多个音节的。只有一个音节的词叫单音节词,如:take拿;有两个音节的词叫双音节词,如ta'ble桌子;包含三个音节或三个音节以上的词叫多音节词,如pop'ula'tion 人口,congrat'ula'tion 祝贺。
2.2 音节划分的方法
英语中,元音是构成音节的主体,辅音是音节的分界线,相应的音节划分的规则如下:
1)两辅音之间不管有多少个元音,一般都是一个音节。如:bed床,bet打赌,seat坐位,beat毒打,beaut极好的,beau'ty 美。
2)两元音字母之间有一个辅音字母时,辅音字母归后一音节。如:stu'dent学生,la'bour劳动。
3)有两个辅音字母时,前一个辅音字母归前一音节,另一个归后一音节。如:let'ter 信,win'ter 冬天。
4)不能拆分的字母组合按字母组合划分音节。如:fa'ther父亲,tea'cher教师。
2.3 音节重读规则
音节按是否重读可以分为重读音节和非重读音节。重读音节是指在双音节或多音节词中的一个发音特别响亮的音节。欲使合成的语音能更好地被人耳所识别,进行音节划分时就必须考虑音节的重读问题[8-9]。
英语中,判断音节重读的规则如下:
1)单音节词多是重读音节。
2)双音节词的第一个音节通常是重读音节,但是:含有a-,be-,de-,re-,in-,ex-等前缀的双音节词往往是在第二个音节重读。
3)多音节词通常在倒数第三个音节重读,但是:词尾有-lc,-tion,-sion等后缀的词,在其前一个音节重读。
4)含有-tion、-sion、-ssion等字母组合时,重读音节为该字母组合前与之紧挨着的那个音节。
3 HMM可训练合成系统应用于英语合成的改进设计
3.1 语音标注
欲实现文本到语音的转换,必须对文本进行语音标注。首先需将文本内容按句断开;然后对每一句中的具有独立意义的词进行分隔;分隔出来的独立词再按音节进行划分,进行音节划分时一定要注意重读音节的位置;最后针对每一个音节进行音素切割,判断每个音节内所包含的音素。
3.2 上下文相关语法
上下文相关语法记录各声学模型合成单元的特征及其与相邻合成单元之间的联系。在训练阶段,建立决策树时应用此语法中所记录的各个信息与问题集进行对比,进行资料分群;在合成阶段,则可从决策树中取得适当的参数,产生平顺的合成语音。式(1)是针对英文语音合成系统设计的上下文相关语法的格式,其中各个符号的定义见表1。
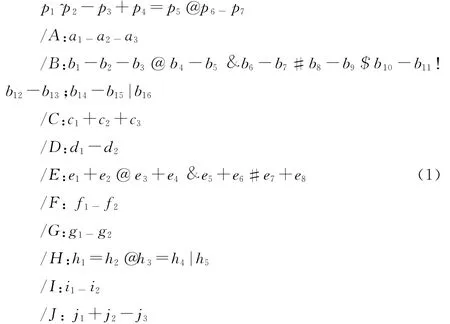
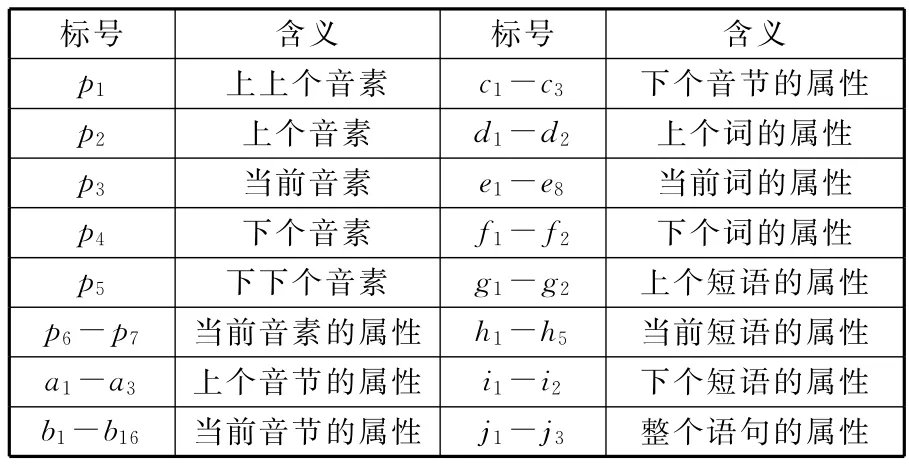
表1 上下文相关语法中各标号的含义
3.3 决策树问题集
决策树问题集记载了一系列资料分群规则,使得合成系统在建立决策树时,能依据问题集进行资料分群[10]。本合成系统中,主要考虑设计了合成单元相关、字相关以及词相关这三类问题。
1)合成单元相关。首先,考虑当前合成单元与前后各一个合成单元各是什么。然后考虑当前合成单元在字、词中的顺序(正序、倒序)。例:合成单元种类(以合成单元「a-i」为例):
L-a-i{a-i}//前一个合成单元是否为「a-i」?
C-a-i{a-i}//当前合成单元是否为「a-i」?
R-a-i{a-i}//后一个合成单元是否为「a-i」?
2)字相关。首先,考虑当前字及前后字中,各有几个合成单元。其次,考虑当前字在词中的顺序(正序、倒序)。
3)词相关。考虑当前词在句中的顺序(正序、倒序)。
4 实验结果及分析
根据上述设计改进,最终构造出可训练英语语音合成系统。通过对该系统所生成的语音进行大量主观辩听实验,证实了该系统能合成出流畅、清晰、易懂的英语语音。下面是利用本系统合成简短语句的实例,通过该系统合成语音:“Alice was tired”。
首先,分析该语句的结构,通过断句、断词以及音节划分,得出该语句的结构如表2所示。
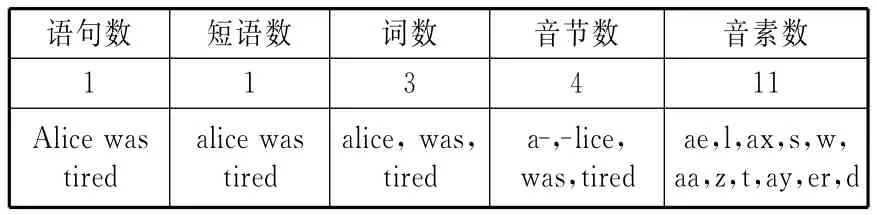
表2 语句“Alice was tired”的结构
然后,分析每个音节所包含的音素,并判断该音节是否重读,分析结果如表3所示。
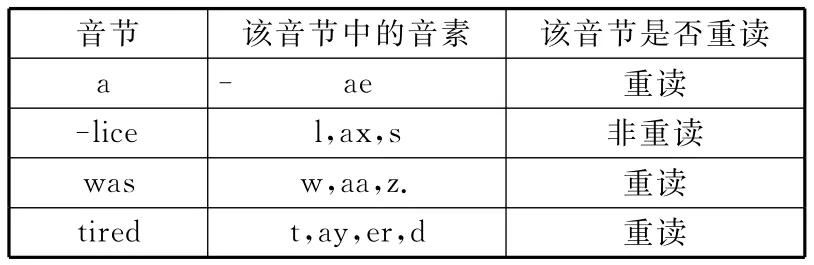
表3 语句“Alice was tired”音节分析
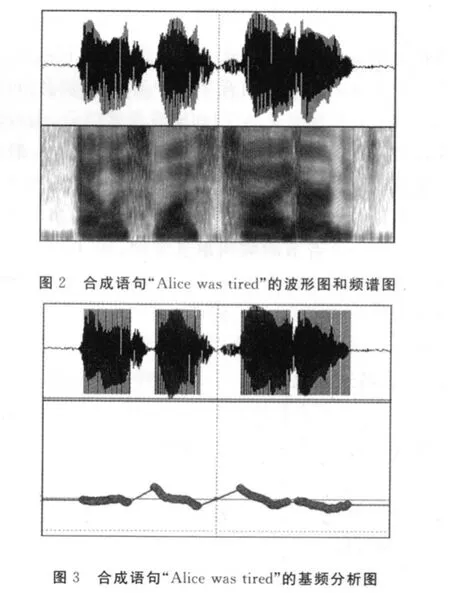
根据以上分析结果,结合上下文相关语法手工编写语句“Alice was tired”的语音标签文件alice.lab。然后,依据所设计的决策树问题集,最终通过本系统生成该语句的语音文件alice.wav。图2为所合成语句“Alice was tired”的波形图和语谱图,图3为该语句的基频分析图。由图中可以看出,语音波形较稳定,而且没有过高或过低的基频点,即基频分析图中没有基频奇异点,说明合成的语音平稳流畅。另外,通过主观辩听,证实所合成出的语音清晰易懂,较好地实现了本英语语音合成系统的基本要求。
5 结论与展望
笔者将改进的HMM可训练语音合成方法成功应用于英语语音合成。通过对HMM建模,并且基于英文语音特性设计上下文属性集以及用于模型聚类的问题集,提高了其建模和训练效果。实验结果证实,该系统能实现英语文本到语音的转换,并且转换结果良好。下一步的研究工作是以设计出更完善的英语韵律边界自动划分、准确的重音预测系统,并在此基础上设计出基于HMM可训练的英语语音合成系统的前端,最后构建出功能更加完整的基于HMM可训练的英语语音合成系统。
[1] CAMPBELL W N,BLACK A W.Prosody and the selection of source unit for concatenative synthesis[M].Springer Verlag:Progress in Spreech Synthesis,1996.
[2] RABINER L R.A tutorial on hidden Markov models and selected applications in speech recognition[J].Proceedings of the IEEE,1989,77(2):257-286.
[3] 冯志红,张连海,吴保民.基于 HMM 的英语文语转化系统 [J].信息工程大学学报,2008,9(1):31-35.
[4] Zen Heiga,Takashi,Nose,Yamagishi.The HMM-based speech synthesis system (HTS)version 2.0[C]∥Proc of ISCA Bonn Germany,Germany,2007:22-24.
[5] HUANG X,ACERO A .Recent improvements on Microsoft’s trainable text-to-speech system-whistler[C]∥Proc of ICASS,1997:959-963.
[6] 吴义坚.基于隐马尔科夫模型的语音合成技术研究[D].合肥:中国科学技术大学,2010.
[7] 王碧泉,陈祖荫.模式识别:理论、方法和应用[M].北京:地震出版社,1989:23-44.
[8] 朱维彬.支持重音合成的汉语语音合成系统[J].中文信息学报,2007,5(3):122-124.
[9] 邵艳波,韩纪庆.自然风格语言的汉语重音自动判别研究[J].声学学报,2006,1(3):203-205.
[10] 段全盛,康世胤.一种适合HMM汉语语音合成的建模单元挑选算法[C]∥第十届全国人机语音通讯学术会议论文集,2009:87-88.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27
考试与评价·八年级版(2021年4期)2021-08-14
作文周刊·小学一年级版(2021年32期)2021-01-04
考试与评价·八年级版(2020年3期)2020-11-02
考试与评价·八年级版(2020年6期)2020-11-02
山东交通科技(2020年2期)2020-08-13
作文周刊·小学一年级版(2018年36期)2018-01-03
电子制作(2017年20期)2017-04-26
老年世界(2017年2期)2017-03-16
