
决策树与回归技术在居民就诊影响因素中的应用研究*
2012-03-11 14:02刘海霞钟晓妮
中国卫生统计 2012年4期
刘海霞 王 玖 林 林 钟晓妮
两周就诊率是了解居民门诊卫生服务利用情况的一个重要指标,通过重庆西部扩点地区卫生服务调查资料,将决策树与回归技术结合应用到居民卫生服务利用领域,研究居民就诊情况的影响因素,为卫生服务决策提供参考。
资料与方法
1.资料来源
资料来源于国家第四次卫生服务调查——重庆西部扩点地区调查数据,根据全国第四次卫生服务调查方案的要求,采用分层多阶段整群随机抽样的方法,调查了11 570名居民,经统一培训调查员进行入户调查。
2.分析方法
用Epidata软件进行原始数据录入、整理及逻辑检错;应用SPSS17.0软件包,通过决策树和logistic回归分别对居民就诊的影响因素进行分析。
(1)决策树原理与算法
决策树(decision tree)是一种主要解决实际应用中分类问题的数据挖掘方法,通过训练样本集建立目标变量关于各输入变量的分类预测模型,全面实现输入变量和目标变量不同取值下的数据分组,进而用于对新数据对象的分类和预测〔1〕。一个决策树由一系列节点和分支组成,而节点和子节点之间形成分支,节点代表着决策过程中所考虑的属性,而不同属性值形成不同分支,在决策树的叶节点得到结论,且从根节点到叶节点的每一条路径对应着一条决策规则,当利用所建决策树对一个新数据对象进行分析时,决策树能够依据该数据输入变量的取值,推断出相应目标变量的分类或取值〔2〕。
目前比较流行的决策树算法主要有C4.5、CART、CHAID,这些算法主要是根据数据的特点建立相应的函数来尽可能地正确分类所有的观察〔1,3〕。其中,C4.5是目前最有影响力的算法,是 ID3的改进算法〔4〕,输入变量的类型可以是两分类、多分类名义型和区间型变量,目标变量可以是为两分类或多分类名义型;CART即classification and regression tree(分类与回归树),允许输入的变量类型可以为名义型、有序型,目标变量可以为名义型或区间型〔5〕;CHAID即Chi-squared automatic interaction detector(卡方自动交互探测),允许输入的变量类型可以为名义型、区间型,如果是有序型,则可以当做区间型变量处理,目标变量可以为两分类、多分类名义型、区间型和有序型变量〔6〕。
(2)非条件二分类logistic回归原理
logistic回归是一种处理目标变量为分类变量的非线性回归方法,按照反应变量的类型分为二分类logistic回归、有序多分类logistic回归和无序多分类logistic回归;按照研究设计类型分为条件与非条件logistic回归,条件logistic回归模型引入条件概率乘法定理构造对数似然函数,非条件logistic回归模型引入二项分布概率构造对数似然函数对参数进行估计。自变量可以是连续性变量、分类变量和等级变量,连续变量需离散化,分类变量则需要转化成哑变量〔7〕。
结 果
1.居民就诊基本情况
本次调查共3 970户11 570名居民,其中农村和城市各1 985户,分别为5 968、5 602名居民,男性占49.3%,女性占50.7%。居民合计两周就诊2 447人次,两周就诊率21.15%(城市为12.58%、农村为29.19%),男女就诊率分别为18.41%、23.84%,差异有统计学意义(P<0.05)。
2.居民就诊影响因素变量整理与赋值
将两周内是否就诊作为目标变量,可能影响患者就诊的性别、民族、年龄、婚姻状况、文化程度、职业类型、就业状况、医疗保险情况、居民类型、家庭人口数、家庭收入、自感病情和是否患慢病等因素作为自变量,构建决策树模型与logistic回归模型。其中,将家庭收入和年龄两个自变量进行离散化,家庭收入按四分位数间距分为低、中、高等收入,对缺失值进行最常频数或均数处理,具体赋值见表1。

表1 变量及其赋值表
3.居民就诊卫生服务利用的决策树与logistic回归分析
(1)决策树模型及变量重要性排序
根据数据特点选择CART树增长法,模型构建过程中进行树的修剪以自动控制树的过增长,并对各解释变量的重要性进行排序,树模型和变量重要性排序分别见图1和表2。从树模型可以看出,树的根节点为年龄,说明年龄是就诊最重要的因素,树状图的其他节点还包括自感病情、家庭收入、居民类型、职业类型和家庭人口数,共6层、13个节点,对应13条分类规则,以最右侧一条规则来看,在年龄为“4、5、6、7、8”,且自感病情为“1和3”时,患病居民选择就诊的可能性概率为98.1%,其他规则解释类似;而从筛选出变量的重要性来看,自感病情是居民选择就诊的最重要的因素,其次为年龄,解释变量的重要性大,说明增加该变量进入决策树时,整个系统不确定程度减少的多;而模型的错误分类率为0.174,具体是指被分错的例数占全部例数的比例。
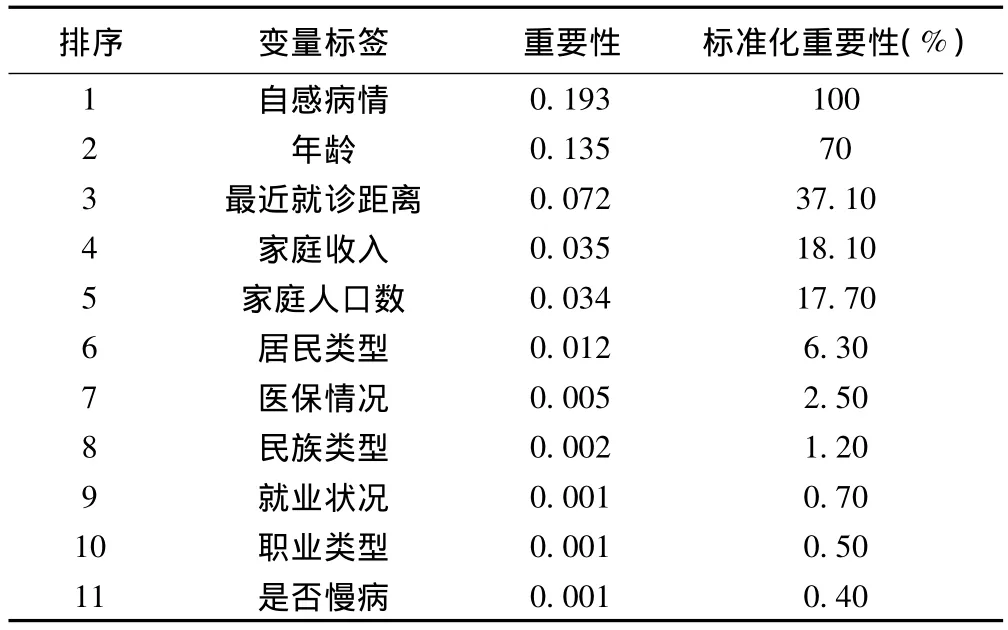
表2 就诊卫生服务利用各解释变量的重要性排序
(2)居民就诊的logistic回归模型
以是否就诊为目标变量,以表1中各变量为自变量,其中婚姻状况和职业类型为多分类无序变量,转化成哑变量,在0.05和0.1标准以及哑变量同进同出原则下进行变量的入选与剔除,模型粗无分类率为0.267,分析结果见表3。
(3)决策树与logistic回归模型分析结果显示,两模型筛选出的错误分类率,分别为0.174与0.267,决策树的错误分类率稍低,且筛选出的变量稍多,两模型前五位重要解释变量中都有年龄、家庭收入和居民类型三个变量,综合考虑,选择决策树模型作为最终模型来考察就诊的影响因素。
讨 论
根据两模型的比较,选择决策树模型多为居民就诊多因素分析的最终模型,CART树模型共6个层次、13个节点,根节点为年龄,说明年龄这个因素在众多输入变量中相对影响最大,此时与其竞争根节点还有自感病情、家庭收入、居民类型和医疗保险,变量“年龄”将树分为左右两枝,左枝终止,右枝又先后被变量“自感病情”、“家庭收入”、“居民类型”、“医疗保险”依次分割;从决策树的分支还可以看出,所选出的影响因素对不同人群的影响不同,以第三层的根节点“自感病情”为例来看,自感病情为“一般”的居民与自感病情“较轻”、“严重”的居民的影响因素不同,居民类型对自感病情一般的居民有影响,而对自感病情为较轻和严重的没有影响。因此,我们在制定卫生政策的时候,应根据不同人群的影响因素提出针对性的卫生政策,以不同的方式方法摸清不同人群的卫生服务、需求状况及其卫生服务供给状况,分析环境和资源,拟定卫生服务规划的目标与战略,提高卫生服务利用率,减少重复性和浪费性卫生活动,实现资源的合理优化配置。
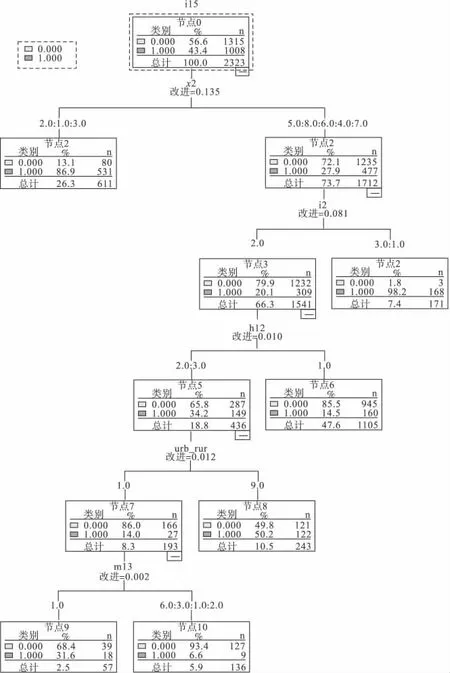
图1 居民就诊卫生服务利用CART树形图
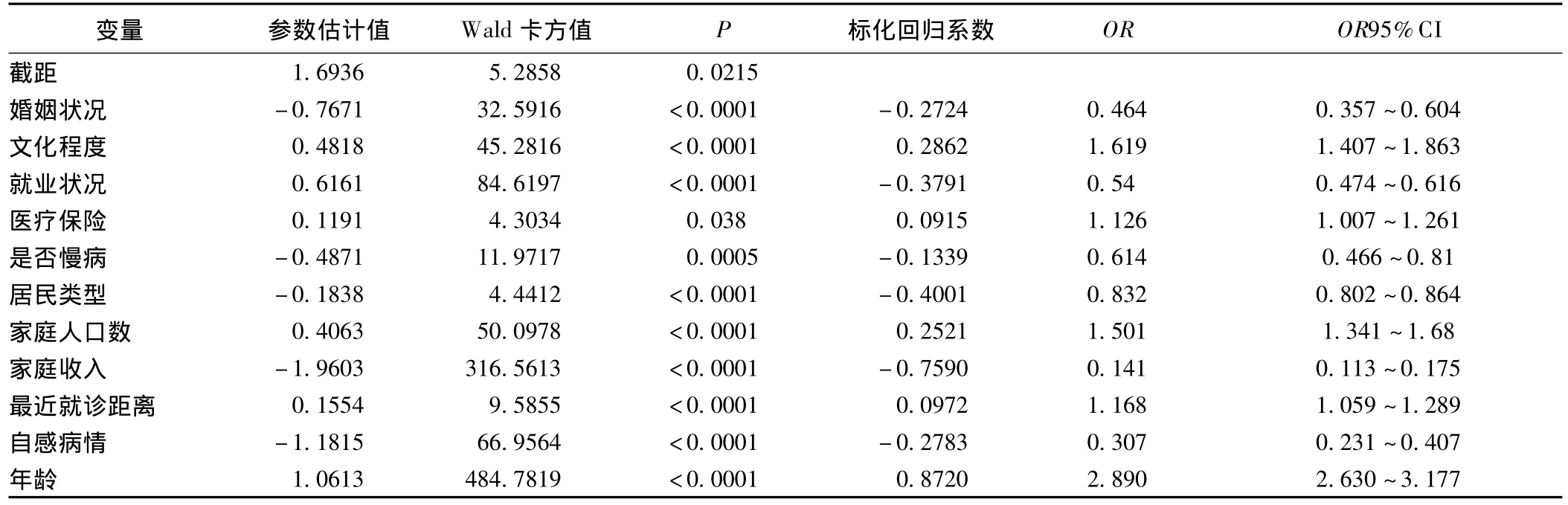
表3 民就诊因素的多元logistic逐步分析结果(只列出有统计学意义的因素)
重庆作为一个地域广阔、人口众多(贫困农村人口较多)、各区域社会经济发展不平衡的直辖市,由于各种因素的影响,卫生服务利用程度、服务水平和公平性有待提高。综合有四点,首先应提高居民的生活质量和收入水平,提高居民的健康意识和抵抗疾病风险的能力;其次,建立健全覆盖城乡居民的医疗保障体系,提高并稳定城乡三项基本医疗保险参保率,提高政策范围内的医保基金支付水平,以实现卫生服务的公平性;再次,低年龄组和高年龄组的两周患病率高,对卫生服务的需求较多,相应的就诊率就会高〔8〕,合理优化重庆地区的人口年龄结构,针对不同年龄人群的健康特点,重点发展一些特色科室;最后,针对不同居民类型的人群提出相应的卫生政策,根据城市与农村居民不同的就诊特点,提高基层医疗服务水平,完善乡村卫生服务一体化管理和提高城市社区卫生服务水平,提高城市居民医疗保险和农村地区新农合报销比例,满足不同居民的医疗服务需求,实现卫生服务的良好效益及其利用的公平性。
1.中国人民大学统计学系数据挖掘中心.数据挖掘中的决策树技术及其应用.统计与信息论坛,2002,2:4-10.
2.Quinlan JR.Induction of decision Tree.Machine Learning 1,1986:81-106.
3.但小容,陈轩恕,刘飞,等.数据挖掘中决策树分类算法的研究与改进.软件导刊,2009,9(8):41-43.
4.Quinlan JR.Induction of decision Tree.Machine Learning,1986,1(1):81-106.
5.Breiman L,Friedman JH,Qlshen RA,et al.Classification and regression trees:modern applied statistics with S-plus.2nd ed .California:Wadsworth international group,1984:6-9.
6.Jordan MI.Learning in graphical models.Cambridge(Massachusetts):MIT Press,1998:7-8.
7.徐天和、柳青、余松林,等.中国医学统计百科全书:多元统计分册第2版.人民卫生出版社,2004:195-201.
8.李鲁,卢祖洵,梁万年,等.社会医学.人民卫生出版社,2006:128-153.
猜你喜欢
中学生数理化(高中版.高考理化)(2021年11期)2022-01-18
学校教育研究(2021年10期)2021-07-08
电子制作(2018年16期)2018-09-26
中学物理·高中(2016年12期)2017-04-22
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
小天使·一年级语数英综合(2016年5期)2016-05-14
中小学实验与装备(2016年3期)2016-04-20
做人与处世(2015年8期)2015-06-24
郑州大学学报(医学版)(2015年1期)2015-02-27
