
边界检测在入侵模式分类与特征提取中的应用
2011-12-23 00:51金民锁
黑龙江科技大学学报 2011年2期
金民锁, 孙 遒, 朱 单
(黑龙江科技学院 信息网络中心,哈尔滨 150027)
边界检测在入侵模式分类与特征提取中的应用
金民锁, 孙 遒, 朱 单
(黑龙江科技学院 信息网络中心,哈尔滨 150027)
在检验知识较少的情况下,为有效提取网络数据特征,实现快速入侵检测,运用边界检测算法建立有限样本下自学习的理论框架和通用方法,通过特征提取来剔除对其后的入侵检测不具有鉴别信息的部分。实验数据分析表明,有效聚类的数量随着原始样本量的增加而缓慢增加,并趋于稳定。理论分析和仿真实验证明了该算法的有效性。
边界检测算法;入侵模式;特征提取
0 引 言
随着网络安全问题的日益突出,作为网络安全的第二道屏障,入侵检测技术成为网络安全体系不可或缺的部分。目前,免疫模型、神经网络及数据挖掘技术被大量应用于入侵信息特征提取和模式分类[1-6]。然而,来源于网络的数据庞大且只有部分具有代表性,若直接将其规格化后进行分析引擎的训练和其后的检测工作,必然会使得训练时间较长且检测速度低下。因而,需要有效地实现数据缩减。
边界检测算法[7]是一种建立在统计学习理论基础上的机器学习方法。其最大的特点是将各个聚类看作是相互独立的边界曲面分开的概率密度子空间,计算合并问题的全局最优解,这一点既克服了穷尽搜索的缺点又满足单调性。此外,其分类性能受原始样本质量影响相对较小,因而具有较好的学习泛化能力,即由有限的训练样本集合所得到分类结果仍然能够保证对独立的测试集进行分类且检测保持较小的误差。因此,笔者将边界检测算法应用于入侵模式分类中,获得了快速训练与检测的新方法。
1 入侵模式分类与特征提取
1.1 入侵模式分类
在理论上,通过网络发起的主动攻击性行为无论其隐蔽性多高都会在网络通信过程中有所体现,可以通过对网络的通信数据分析提取出攻击行为的特征,并将其作为判定网络中是否存在入侵的有利依据。对直接来自于网络的原始数据进行分析前要对数据进行适当处理,通常有两个过程。
首先是数据预处理。它是限制模式识别性能的重要因素,从原始数据包中抽取的数据向量维数将会极大影响检测的速度及精度。基本原则是,在不影响目标系统运行性能和实现安全检测目标的前提下,最多可以使用多少信息或者说最少需要多少信息源。目前,数据选择大部分是安全人员根据其对己有攻击方式分析基础上进行的。
其次是数据表述问题。为减小处理量先对原始数据进行形式化描述,剔除不敏感数据项,从而使进入网络的数据更有代表性。在文中,通过提取每个包的包头及负载中的信息作为执行分类的原始数据,以 TCP/IP协议的链路层为例,在该层次上提取源地址、目的地端口号、标识位 (SYN、F IN、RST等)、ACK序列数等作为输入项,数据整体上为一向量形式。
对来源于网络的数据规格化并分类后,可以直接依据分类的界面函数提取与选择有鉴别信息的坐标轴,从原始样本中提取出的模式在其上的投影即为具有鉴别信息的分量。在模式识别中,特征提取与选择的准则是在保持分类识别正确率的条件下,使特征空间维数尽量的小,并提取出对分类性能影响较大的所有特征矢量。
1.2 特征提取
在一个较完善的模式识别系统中,或者明显或者隐含的要有特征提取与选择的技术环节,通常其处于对象特征数据采集和分类识别两个环节之间,特征提取与选择方法的优劣极大的影响着分类器的设计和性能,它是模式识别的三大核心问题之一[8]。特征提取与选择的基本任务是研究如何从众多特征中求出那些对分类识别最为有效的特征,从而实现特征空间数据的压缩。在文献[9-10]中讨论了几种用于特征提取的智能技术,为客观的特征提取做了理论分析与测试。
分类识别的正确率取决于对象的表示、训练学习和分类识别算法,而特征的提取与选择问题则是对象表示的一个关键问题。从直观上可知,在特征空间中,如果同类模式分布比较密集且不同类的模式相距较远,分类识别就比较容易了,因此在提取特征时,要求所提取的特征对不同类的对象差别很大而同类对象差别较小,这将给分类带来很大的方便。但是由于某些原因,提取的特征似的模式没有显著地如上述那样分布,或者所得的特征过多。为了保证所要求的分类识别的准确率和节省资源,希望依据最少的特征达到所要求的分类识别准确率,因此,通常在得到实际对象的若干具体特征之后,再由这些原始特征产生出对分类识别最有效、数目最少的特征。这就是特征提取与选择的任务。在实现上述目标时,往往需要首先制定特征提取与选择的准则,也可以用类别判决函数作为准则,还可以构造出误判概率有关的判据来刻画特征对模式识别的贡献或者有效性[11]。
2 边界检测算法
2.1 原 理
决策边界的定义为:{(x)=t},它可以是直线、曲线、平面、超平面、曲面、超曲面等,决策界往往是无限的,但大多数情况下决策界中的一部分对分类有意义。
对于分类问题,边界检测算法根据区域中的样本计算该区域的决策曲面,由该曲面确定该区域中样本的类别,见图 1。这里主要讨论计算决策面和对样本分类的方法。边界检测算法很适用于致密聚类,其聚类原理为:致密聚类可以看作是N维空间内的高密度区域,区域之间通过稀疏区域分隔,因此可以对界限进行初始估计,然后迭代的将其向数据向量稀疏的区域移动。为方便描述,首先以有两个聚类为例。令g(χ,θ)是描述两个聚类(C-,C+)间的决策边界的函数,其中,θ为描述曲面的未知参数向量。如果对于特定的 x,有g(χ,θ)>0,那么 x属于第一个聚类,否则 x属于第二个聚类。因此定义判定函数P以使得当函数取最大值时将得到θ的局部最优值。P定义为
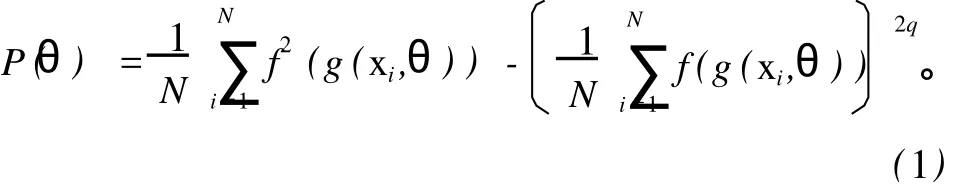
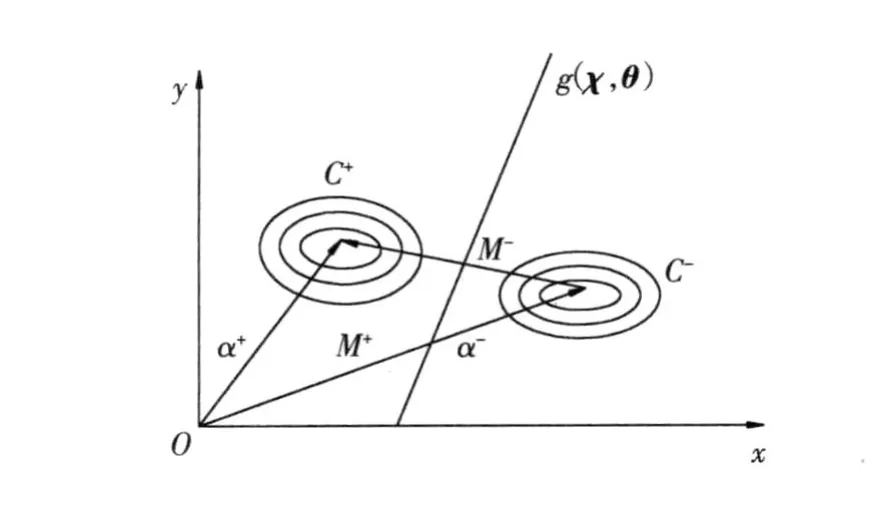
图1 决策边界Fig.1 Decision boundary
观察式(1)右端的两项可以看出其最大值均为1,同时因为f(x)≤1,所以有
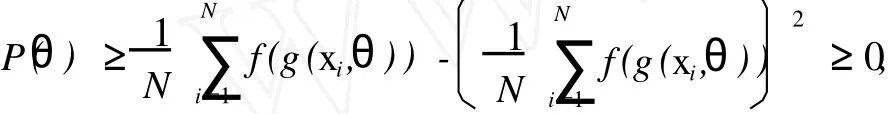
即有P(θ)取非负值。通过分析可以得出,当所有的输入样本都远离界限时,式(1)的第一项取极大值。在这种情况下有f2(g(xi,θ))→1,当输入样本位于边界的同一侧而且远离该边界时也有上述结论成立。式(1)右端的第二项就是为了克服上述限制,在第二项接近于1的情况下有P(θ)→0,也就是说函数取最小值。q的作用就是控制第二项在判定函数P(θ)的影响。在边界位于两个密集区域中间的情况下,第二项对P(θ)的影响较小,因为通过求和后,位于边界两边的样本所产生的作用几乎抵消。
整个算法的最终目的就是要确定θ,在当前情况下,对θ的调整是基于向量 x与决策边界间的欧氏距离。在此使用快速上升法来确定θ的最优值,令θj为向量θ的某一维坐标,得公式:
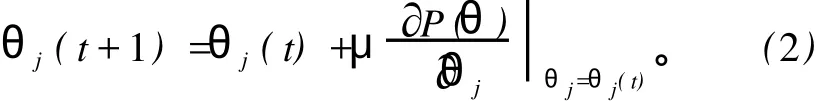
对于简单的情况,g(χ,θ)为一超平面,即有g(χ,θ)=wTx+w0,其中,θ=[ww0]T。具体的计算过程为:各参数选择初始值,用式(1)计算P(θ(0));接下来用式(1)和(2)迭代计算θ(t)和P(θ(t))直到
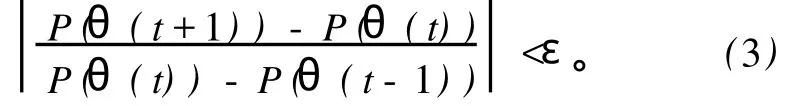
在输入样本中的隐含聚类多于两个的情况下,采用层次方法首先把输入样本分为两类,确定两类边界后在边界两边进行迭代继续细分。值得指出的是,式(3)中ε的取值应该慎重,其决定边界的分类性能。
2.2 分类性能
根据概率理论可知,对于一组样本若样本间相互独立分布则它们总体上可近似为一正态分布,为讨论方便仍以两类模式为基础分析。设C+、C-分别代表两类模式,因两类模式近似为正态分布所以可定义这两类之间的决策似然比Lij(x)的数学期望为

式(4)表明,误判概率随着两类模式中心的马氏距离的增加而减小,若两类模式距离足够大则误判概率可足够小。上述证明结果对选定式(3)中ε的值以改善聚类性能具有指导意义。
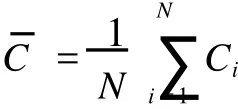
2.3 误分类风险估计与参数优化
由于从原始数据包中抽取的数据可能不能完全满足检测的需求,并且检测引擎也具有不精确性,所以需要设定某些判断规则来提高整个检测系统的性能,即如何减小由前期分类样本少及算法本身问题所造成分类不准确对匹配性能的影响。下面分析前期的分类性能对模式识别所造成的影响以指导参数调整。
设样本空间与模式空间分别为X与Y,为分类的需要在此定义Y={0,1},用 0及 1分别代表分类的匹配与不匹配。定义模式m的风险为:R(m)=P(m(x)≠y),根据 Hoeffding不等式[12],对于n个满足f(x)∈[a,b]随机变量 x1,…,xn,有
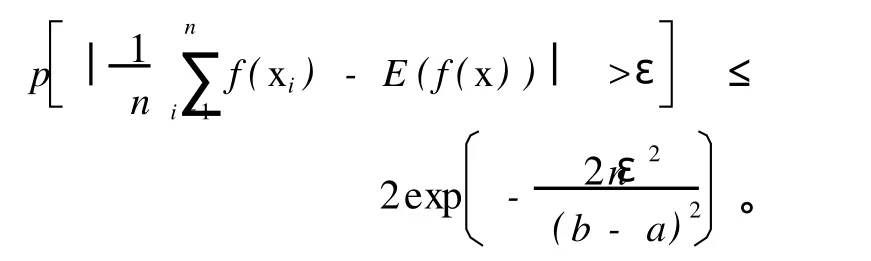
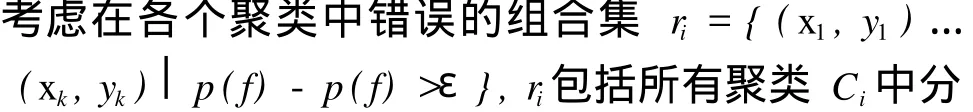

在式(5)中体现了分类错误风险与检测准确率δ和聚类数N的关系。因而在确定检测样本属于某个聚类Ci时,可以根据式(5)的结果来减小在该聚类中搜索匹配模式代价,即在合理的确定分类精度的情况下减小搜索的模式范围,如在kij取值在左右时分类精确率变化较为缓慢,在 90%左右,而且此时分类精度较为适合。从而通过调整δ来调整聚类数。
3 仿真及性能分析
与其后的检测过程相对应,在分类阶段对原始数据按协议结构也分层处理,由于应用层协议复杂多样且大量工作在于分组负载分析,因此在分类过程中只针对传输层、网络层及物理层。分类输入向量可形式化描述为 M={H,{t1…tn},{n1…nn}, {l1…ln}},其中,H为连接号;t为包头信息经过特征提取转换和降维处理后的传输层信息;n及l分为网络层及链路层信息。当传输层使用 TCP协议时,连接请求从发起的第一个数据包起到连接终止,所有传输分组具有相同H;当使用 UDP协议时,则任两个分组H都不同。
分类的初始信息来源于 DARPA99数据集,从中抽取出含有入侵行为的数据进行分类,在接下的测试中使用增量样本观察分类的速度及聚类数目,表 1给出了四组原始样本相同情况下分类情况和分类后的聚类情况。
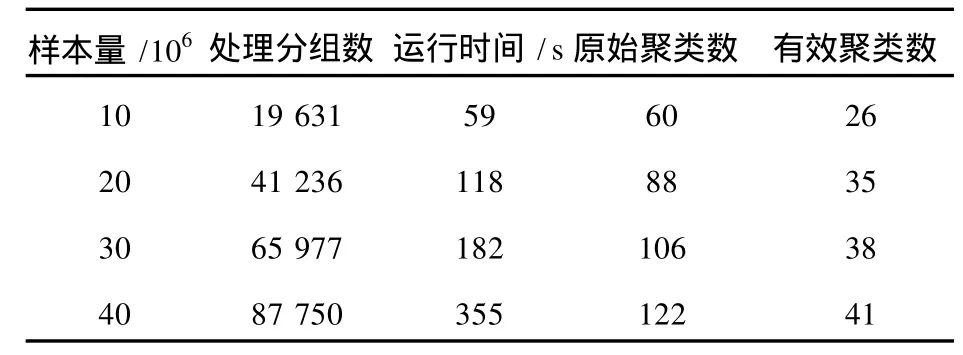
表 1 边界检测算法对原始样本数据分类性能Table 1 Classification performance of BDA
通过对分类后得到的聚类的分析,发现有相当的一部分聚类内样本数增长较慢,这些聚类是异常数据或不具备代表性的无意义数据,对分析没有意义,因此将其当作噪音剔除掉。在经过大量的数据分类后,发现有效聚类的数量随着原始样本量的增加而缓慢增加,有效聚类数稳定在 40个左右(表 1)。
4 结束语
目前,随着网络带宽的不断增加及网络攻击的复杂度上升,入侵检测系统的检测性能也急需提高。因此,笔者将边界检测算法应用到网络数据特征提取中。该算法可以从原始样本中获得具有代表性的聚类,根据得到的稳定聚类提取出代表性的特征,以便于进行入侵检测。仿真实验表明,该算法可以在先验知识不足的情况下,提高分类速度且不降低分类的性能,从而较好地解决小样本、非线性等实际分类问题。
[1] 邓清华,金 聪,张清国.一种网络蠕虫的动态传播模型[J].计算机工程与应用,2011,47(6):86-88,126.
[2] 王金水,张东站,施秀升,等.基于免疫系统和模糊逻辑的自适应网络入侵检测[J].心智与计算,2009,3(1):22-23.
[3] 卫 强,周晓沧.基于属性预扫描的不确定性函数依赖挖掘[J].清华大学学报:自然科学版,2009,49(6):905-906.
[4] 辛治运,顾 明.基于最小二乘支持向量机的复杂金融时间序列预测[J].清华大学学报:自然科学版,2008,48(7):1 147-1 149.
[5] 杨贤栋,叶少珍.基于内容的MR I脑肿瘤图像特征提取及检索方法[J].计算机应用,2009,29(z2):232-233.
[6] 王秀琴,夏洪洋.不变矩算法的改进与人耳识别技术[J].黑龙江科技学院学报,2008,18(1):51-53,57.
[7] THEODOR ID IS S,KOUTROUMBAS K.Pattern recognition[M]. Boston:ELSEVIER ACADEM IC PRESS,2004:89-90.
[8] 王金龙,王呈贵,吴启辉,等.Ad Hoc移动无线网络[M].北京:国防工业出版社,2004:56-57.
[9] WANG K,CRET U G,ST OLFO S J.Anomalous payload-basedwor m detection and signature generation[C]//Proceedings of the 8th International Symposium on Recent Advances in Intrusion Detection (RA ID).Washington,DC:Springer-Verlag Berlin Heidelberg, 2005:227-246.
[10] KRE IBI CH C,CROWCROFT J.Honeycomb creating intrusion detection signatures using honevpots[C]//Proceedingsof the SecondWorkshop on Hot Topics in Ne tworks(Hotnets II).Washington,DC: Springer-VerlagBerlin Heidelberg,2003:51-56.
[11] 邹 涛,孙宏伟,田新广,等.网络入侵检测系统中的数据缩减技术[J].国防科技大学学报,2003,25(6):16-20.
[12] ANTHONYM,BARTLETT P L.Neural network learning:theoretical foundations[M].London:Cambridge University Press, 2007:78-80.
[13] 黄光球,李 眩.基于记忆原理的网络入侵检测[J].河北工程大学学报:自然科学版,2008,25(1):42-44.
Application of boundary detection algorithm in invasion pattern classification and feature extraction
JIN M insuo,SUN Q iu,ZHU Dan(Infor mation Ne twork Center,Heilongjiang Institute of Science&Technology,Harbin 150027,China)
Adopting the boundary detection method can help the users achieve an effective extraction of the network data and a quick intruding detection in the lack of detective knowledge.It is helpful to establish a theoretical framework and develop a universalmethod of self-learning as to the lim ited samples with the boundary detection method,through feature extraction can get rid of the data without the distinguished features in the following intruding detection. Experimental data analysis shows that the number of effective clustering increases alongwith the increasing original samples and then levels off. Its validity has been demonstrated in the theoretical analysis and simulation experiments in this article.
boundary detection algorithm;invasion pattern;feature extraction
TP309;TP391
A
1671-0118(2011)02-0142-04
2011-01-11
黑龙江省教育厅科学技术研究项目(11551439)
金民锁(1977-),男,黑龙江省双鸭山人,工程师,硕士,研究方向:网络安全与计算算法,E-mail:jms9802@126.com。
(编辑王 冬)
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年19期)2018-11-14
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
自动化学报(2017年11期)2017-04-04
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
