
BETSY在自动作文评分中的原理与应用
2011-12-06 01:17:34唐进
当代外语研究 2011年1期
唐 进
(咸宁学院,湖北,咸宁,437100)
1. 概述
大规模的语言测试如TOEFL、CET机考等都要对应试者进行写作能力测试。不过,英语作文大规模人工阅卷存在耗费大量人力、物力的问题,阅卷员的评判也带有很强的主观性。随着计算机技术的飞速发展,自动作文评分(Automated Essay Scoring,AES)在国外已进入实际应用阶段(Kukich 2000:25)。国内自动作文评分的研究虽然起步较晚,但也越来越受到学者们的重视。万鹏杰(2005:11-13)利用电子软件评估系统对大学英语写作进行测试,探讨电子软件评估代替人工评估的可能性。陈潇潇和葛诗利(2008:78-83)等人对国外英语作文自动评分做了综述,初步介绍了PEG(Project Essay Grade)、IEA(Intelligent Essay Assessor)、E-rater(Electronic Essay Rater)、IntelliMetricTM、BETSY(Bayesian Essay Test Scoring sYstem)等自动评分系统的基本功能。梁茂成(2005)则把他利用220个样本的训练集得出的评分模型应用在120个样本的验证集上以进行可信度验证。
在国内外学者的研究中,我们发现BETSY系统能够整合许多自动作文评分系统(如PEG、LSA、E-rater和IntelliMetricTM等)的优点,而且应用广泛(文本篇幅可长可短)、容易操作、非统计学人员更容易理解(Lawrence & Tahung 2002:3-21)。因BETSY是开源软件,它还可以免费从Internet上下载①。本文具体分析该评分系统的工作原理,并采用实证方法验证该系统在英语作文自动评分中的应用效果。
2. BETSY的工作原理
BETSY是国外一款流行作文自动评分系统,由美国马里兰大学Lawrence M. Rudner博士为主研制。BETSY的核心原理是贝叶斯理论(Bayes’ Theorem),是建立在文本分类(Text Classification)基础上的自动作文评分系统。BETSY根据一个己标注的训练文档集合,找到文档特征和文档类别之间的关系模型,然后利用这种关系模型对新的文档进行类别判断,达到自动评分的目的。BETSY的核心技术由文本预处理(Text Preprocessing)、文本表征(Representation)、分类方法等几部分构成。下面,我们将分别进行说明。
2.1 文本预处理
BETSY要处理大量非结构化的自然语言文本数据,因此在对文档进行特征提取前,需要先对这些文本数据进行相应的预处理,这将直接影响文本分类的效率、准确度以及最终模式的有效性。因此,为减少文本特征表示中的数据干扰(data-noises),改善文档表征的质量,同时也为提高分类器的训练和分类效率,BETSY在特征使用前,通常需要对文档进行必要的自然语言预处理。预处理主要包括删去停用词(stop words)、提取词根(stemming)和特征选择(feature selection)等(古平2006:21)。
删去停用词是将英语中大量的介词、代词、形容词、副词等从特征集中去掉。BETSY停用词列表中有319个单词,研究者也可以自定义添加额外的停用词。提取词根是指将具有相同或相近形式的单词合并为一个语义单位的过程。提取词根的主要手段是将字尾的变化去除,例如将shopping替换为shop。BETSY采用波特算法(Porter’s stemming algorithm)进行取词,步骤包括:将词尾有元音的单词es、e、ed、y替换掉(如将agreed替换为agre),替换词尾tional、fulness、iveness为tion、ful、ive,替换词尾icate、iveness、alize为ic、ive、al,删除剩余的标准词尾,例如al、ance、er、ic等等,去除词尾的e,例如用becaus替换because等。这样能将绝大多数字母的变化型去除掉,减少数据储存的空间,并且能搜索出有用的信息。当然,波特算法所做的是技术处理,而不是语法规则的变换。本文预处理的特征选择是特征降维(feature dimension reduction)方法的一种,是指从一组已知特征集中按照某一准则选择出有很好区分特性的特征子集,或按照某一准则对特征的分类性能进行排序以用于分类器的优化设计(宋国杰等2003:1544-1545)。同时,必须先确定一个特征评价函数,并根据该函数计算每个特征得分(古平2006:21)。信息增益(information gain)是常见的特征评价函数之一(参见公式(1))。在公式中,对于特征f和文档ci,信息增益可以通过f在ci中出现和不出现的情况来计算f的信息量:
(1)IG(f)=∑P(ci)logP(ci)+
P(f)∑P(ci|f)logP(ci|f)+
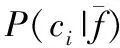
2.2 文本表征
在BETSY中,文本表征就是在给定的分类体系下,根据文本内容自动地确定文本关联的质量类别。或者说,这就是给定一篇英语作文,为了得到其文档表示,需要将作文中提取的有效特征合理地组织起来的过程。BETSY中文档表征的方法采用朴素贝叶斯分类器,这是一个基于类条件的独立性假设(朴素假设),即假设一个文档中任何两个特征词之间的出现与否是相互独立的(梁宏胜等2007:328)。其主要思想就是计算在给定一待分类文档的条件下其属于各个类别的条件概率,然后选择条件概率最高的那个类别为该文档所属的类别。BETSY采用两种文本表示模型:多元伯努利模型(Multivariate Bernoulli Model,MBM)和多项式模型(Multinomial Model,MM)。
多元伯努利模型是朴素贝叶斯方法最常用的实现模型之一,它使用0和1二值向量(Vector)来表示一个文档。即d={x1,…xn},xk=1就说明特征项(item)在文本中出现,反之特征项没有在文本中出现。无论文档中出现或未出现的特征项均被检测。在BETSY中,由于伯努利模型将文档看作多重独立的伯努利实验,对于给定的分类cj,文本di的条件概率见公式(2):
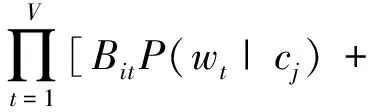
(1-Bit)(1-P(wt|cj))]
其中V表示文章中单词出现的特征,Bit∈(0,1),表示特征项t是否出现在文章i中。P(wt|cj)表示特征项wt出现在评分为cj的文章中的概率(在多元伯努利模型中至少要出现一次)。模型中用到的参数都要通过训练阶段,从训练数据中训练得到,通常取它们的最大或然估计(Maximum Likelihood Estimation)作为它们的估计值,见公式(3):
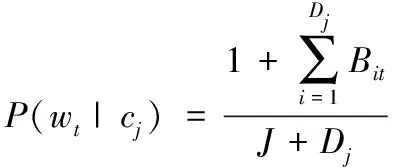
公式(3)中,Dj为训练文档集中分类cj的文档数,J为分数组数。为避免出现零概率,采用Laplace平滑技术进行调整。对于给定的分类cj,文章di的概率由公式(2)给出,并乘以先验概率,经标准化处理后得到较高的后验概率(posterior probability)。
多项式模型也常被称作Unigram语言模型。Unigram语言模型是N-gram的一种,当N=1时,成为Unigram模型,即词与词之间互相独立,完全没有上下文信息,反映的只是词频统计特性。Unigram语言模型假设词与词之间是相互独立的,一个词出现的概率与这个词前面的词不存在必然联系。换句话说,在多项式模型中,文档被看成是长度为m的单词序列,并且假定文档的长度与类别无关,考虑特征项在文档中出现的频率。并且,文档得分的概率di在给定类别的条件概率P(di|cj)可以由公式(4)计算得到:
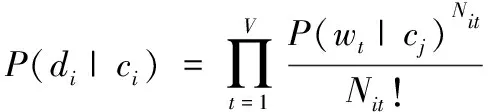
其中Nit是wt在文章中出现的次数,P(wt|cj)表示特征项wt出现在评分为cj的文章中的概率,从训练集的数据中计算得到公式(5):
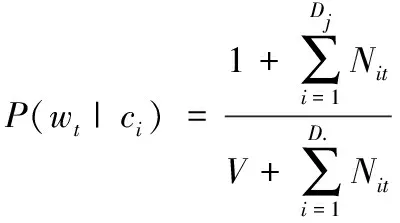
其中D为训练集中所有文档数。同样的道理,多项式模型在评判作文分数的时候,也只能使用频率非零的特征项。
在多变量伯努利模型中,文本中出现或未出现的特征项都需计算。在多项式模型中,只计算一篇文章中出现的特征项,每个特征项可以出现多次,并假定文档的长度与文档的分数无关。经过训练集的参数估计后,多项式模型在评估一篇新的文本时,速度要比多变量伯努利模型快(Lawrence & Tahung 2002:3-21)。
2.3 分类方法
BETSY采用基于贝叶斯定理的分类方法。这是根据贝叶斯理论计算概率的一种方法,即认为一个事件会不会发生取决于该事件在先验分布中已经发生过的次数。贝叶斯定理指出,对于事件X和Y,已知Y的概率时X发生的概率(用p{X|Y}表示)等于已知X的概率时Y发生的概率(用p{Y|X}表示)乘以X的概率(p{X}),再除以Y的概率(p{Y}),见公式(6):
(6) p{X|Y}=p{X}*p{Y|X}/p{Y}
因此,贝叶斯理论的应用有三个步骤:(1)已知类条件概率密度参数表达式和先验概率;(2)利用贝叶斯公式转换成后验概率;(3)根据后验概率大小进行决策分类。
贝叶斯理论在作文自动评分中的主要任务是根据大量的文本特征项对文本进行分类,一般分为三类或四类。Lawrence和Tahung(2002)的例子较为简单,他们将文本分为三类(好、中、差)。因此我们需要确定三个概率:第一,“好”的文本中特征项出现的概率;第二,“中”的文本中特征项出现的概率;以及第三,“差”的文本中特征项出现的概率。我们分别设Pi=(ui=1|A),Pi=(ui=1|R)和Pi=(ui=1|I);对于每一个特征i有不同的概率;A、R和I分别代表文本的分类“好”、“中”和“差”。同时,Lawrence和Tahung(2002:3-21)强调,确定条件概率需要1000个以上的样本量。
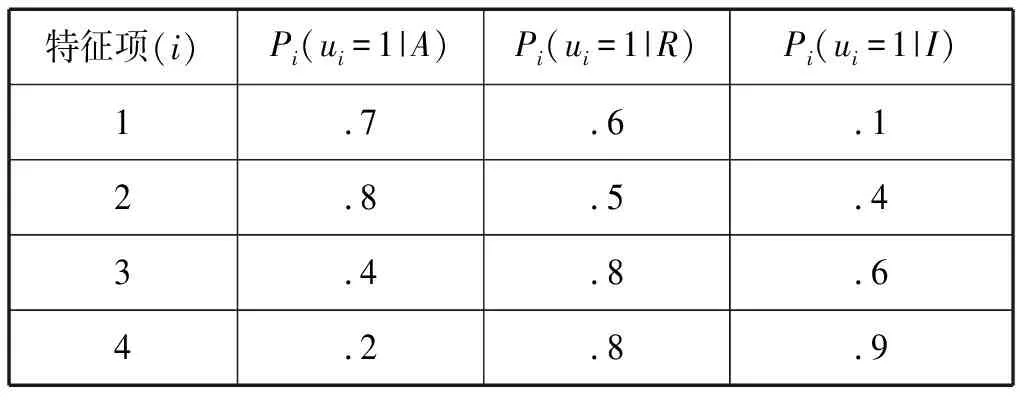
表1 假设特征项的条件概率②
在BETSY的官方网站上提供了一个4个特征项的例子(参见表1)。在这个例子中,假设文章包涵4个特征项,每个特征项按照“好”、“中”、“差”统计概率。观察表1中的特征项与相应的概率,很容易发现:“好”的文章包涵特征项1(.7)和2(.8);“中”的文章包涵特征项3(.8);而“差”的文章包涵特征项4(.9)。为对这篇文章进行评分分类,我们假设先验概率相同,即P(A)=P(R)=P(I)=.33。根据贝叶斯理论,即公式(6),得出这篇文章为“好”的概率为:P(A|ui=1)=P(ui=1|A)*P(A)/P(ui=1)=.7*.33=.233;“中”的概率为:P(R|ui=1)=P(ui=1|R)*P(R)=.6*.33=.200;“差”的概率为P(I|ui=1)=P(ui=1|I)*P(I)=.1*.33=.033。根据这些联合概率就可获得后验概率:P′(A)=.233/(.233+.200+.033)=.500;P′(R)=.200/(.233+.200+.033)=.429;P′(I)=.033/(.233+.200+.033)=.071。接着,我们用得到的后验概率作为新的先验概率,去验证下一个特征项,重复这一过程直到所有特征项被归类。表2就对这一重复过程进行了说明。
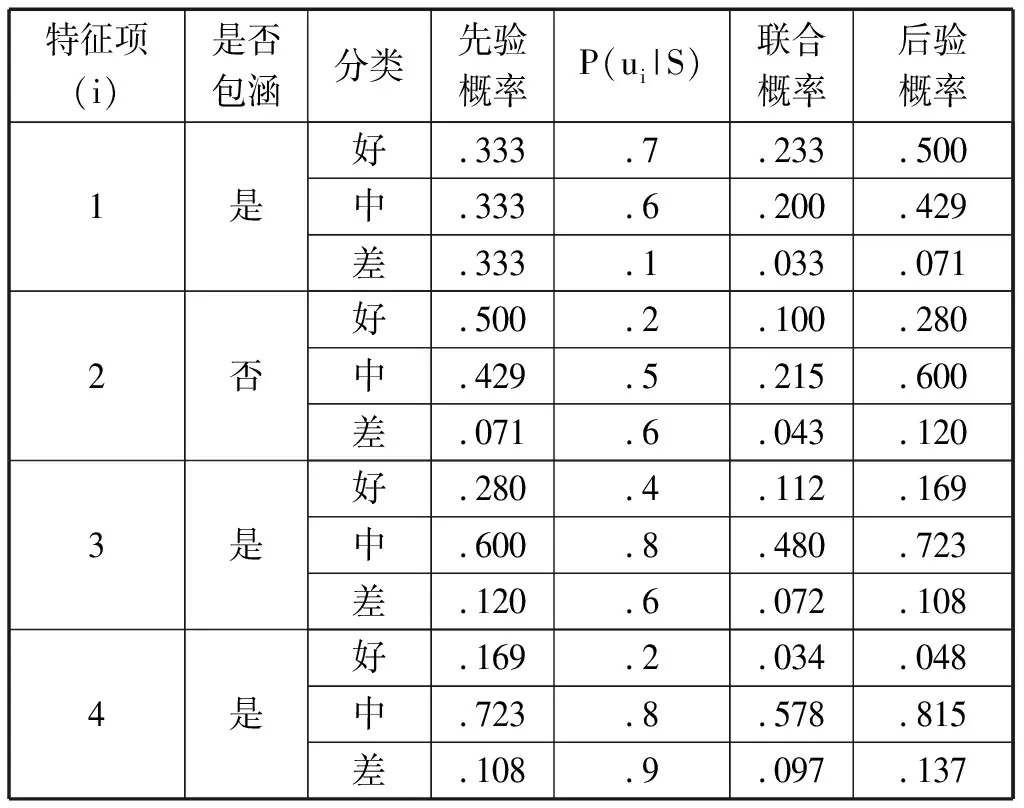
表2 文本分类③
进一步假设,一篇作文包涵了特征项1、3和4,P(ui|S)的值来自表1。由于假设规定本篇习作不包涵特征项2,因此对于特征项2,就有P(ui=0)=1-P(ui=1)。根据极大后验估计法(Maximum a posterior estimation),习作为“中”的概率为.815(表2),是最高的概率。也就是说,本篇习作的分类为“中”。BETSY就是采用这种算法对文本进行分类与评分。
3. BETSY在英语自动作文评分中的应用
下面,我们将采用实验方法验证BETSY在英语作文自动评分中的应用效果。在实验中,我们比较BETSY自动作文评分与人工评分的结果,并作相关统计学处理与分析。
首先收集写作样本。采用2009年12月全国大学英语四级考试写作试题“Create a Green Campus”作为数据收集工具。要求被试完成的习作字数在120左右,并要求紧扣题目。被试为1504名湖北某高校公共英语大学二年级学生。聘请两名大学英语教师对学生习作人工评分。为简化操作程序,习作只分为A、B、C、D四个等级,分别对应的分数为14分、11分、8分和5分,满分为15分。两位教师评分的一致率在86%以上。同时两位教师对评分有争议的样本进行磋商,最终给出这部分样本的平均分。综合各方面因素,在1504篇习作中,最终确定有效样本1187篇。其中987篇习作为训练集样本,200篇习作为验证集样本。
接下来采用版本号为1.03.55d.03.13的BETSY系统读取样本数据,并自动进行单词(words)和词对(word pairs)训练。在此过程中,BETSY会去掉每1000词中出现不足5次的单词,避免数据库过于庞大。同时,BETSY根据内建的英语停用词表标记停用词、采用波特算法进行取词根处理、特征降维等,使向量维数得到进一步降低。BETSY收集完足够信息后,实验分别采用多元伯努利模型和多项式模型对另外200篇习作的验证集进行自动评分,并对BETSY与人工评分的结果进行统计分析。表3是相关参数的描述统计结果。
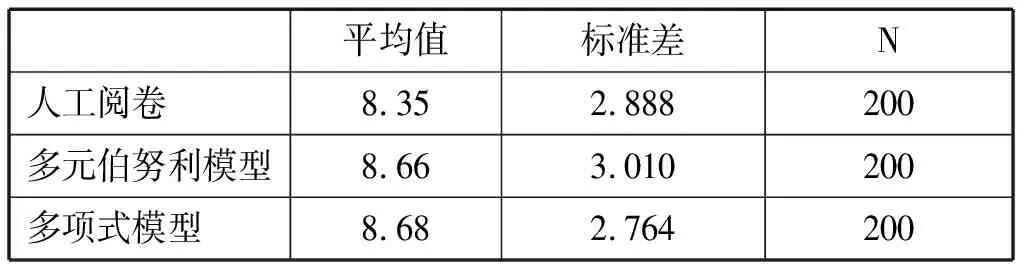
表3 描述统计
从表3的统计结果来看,人工阅卷、多元伯努利模型和多项式模型的均值、标准差差别并不大,但多元伯努利模型与多项式模型的平均得分都比人工评分高。
表4是对人工阅卷、多元伯努利模型和多项式模型结果所作的相关性分析。从表4可知,人工阅卷与多元伯努利模型之间、人工阅卷与多项式模型之间、多元伯努利模型与多项式之间存在显著相关(r人工阅卷-多元伯努利模型=.624,r人工阅卷-多项式模型=.611,r多元伯努利模型-多项式模型=.860,p<.01)。而且,人工阅卷与多元伯努利模型、多项式模型之间均为强相关。多元伯努利模型与多项式模型之间的相关系数达.860,两种模型均来源于朴素贝叶斯理论,在本次实验中的结果差别不大。
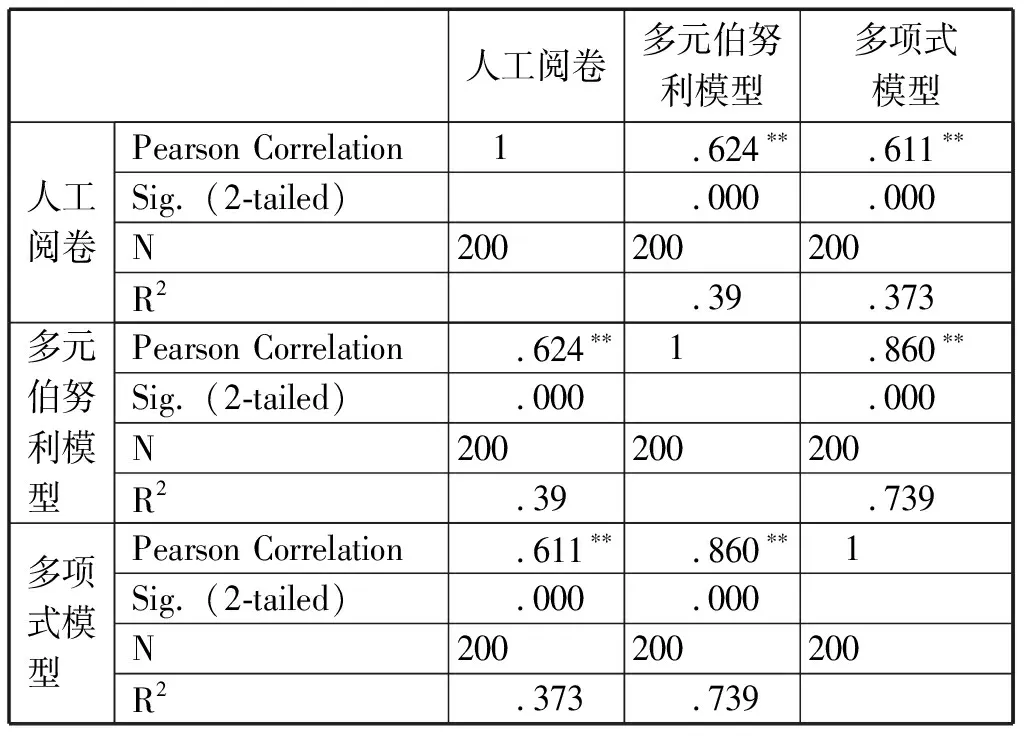
表4 相关性
注:**p<0.01。
以人工评分为x轴、以多元伯努利模型和多项式模型为y轴,分别画出人工评分与多元伯努利模型、人工评分与多项式模型的散点图(图1、图2);以多元伯努利模型为x轴,多项式模型为y轴画出多元伯努利模型与多项式模型之间的散点图(图3)。从图1-3可以看出,人工阅卷与多元伯努利模型之间、人工阅卷与多项式模型之间、多元伯努利模型与多项式模型之间均为线性正相关。
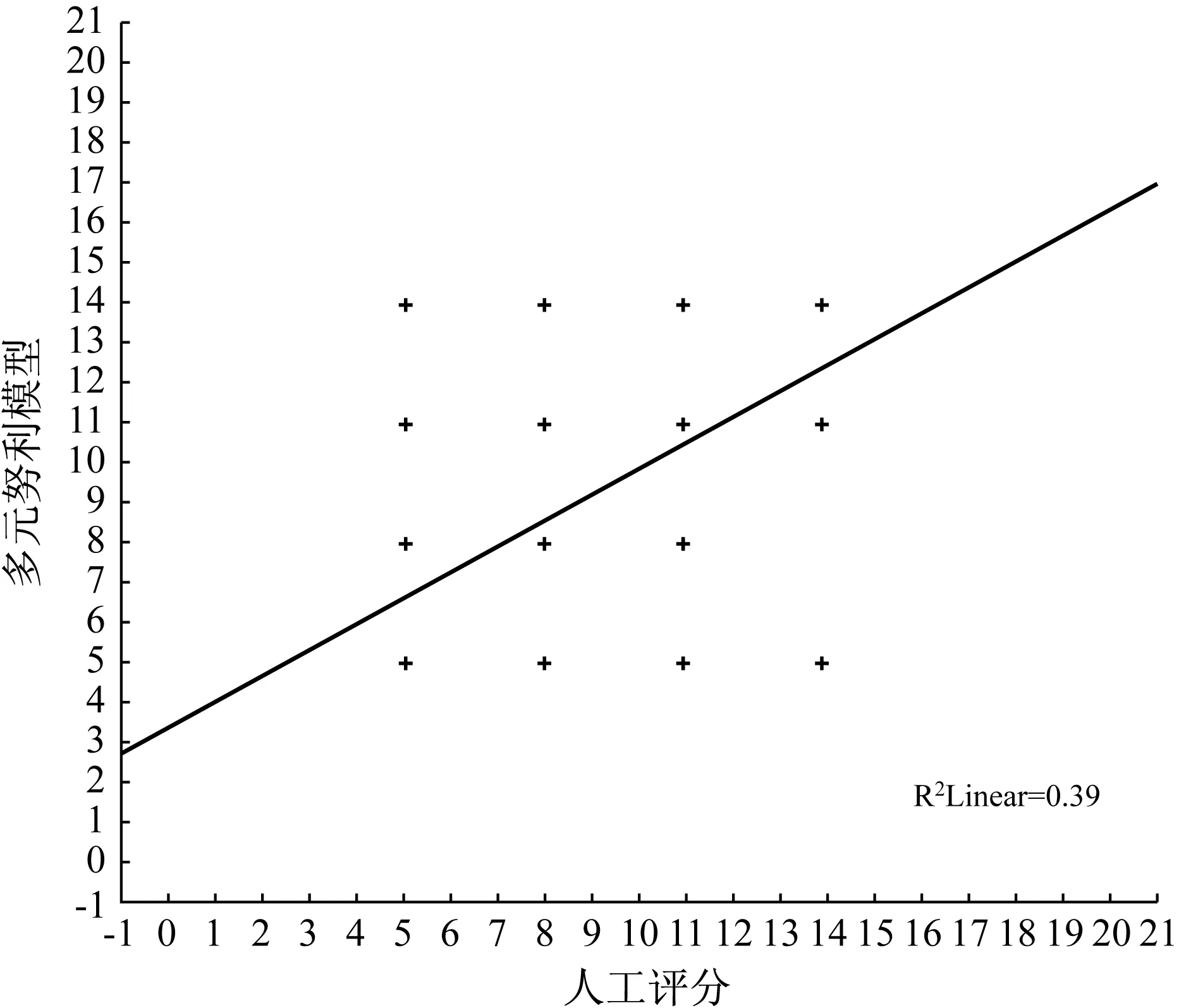
图1 人工评分与多元伯努利模型散点图
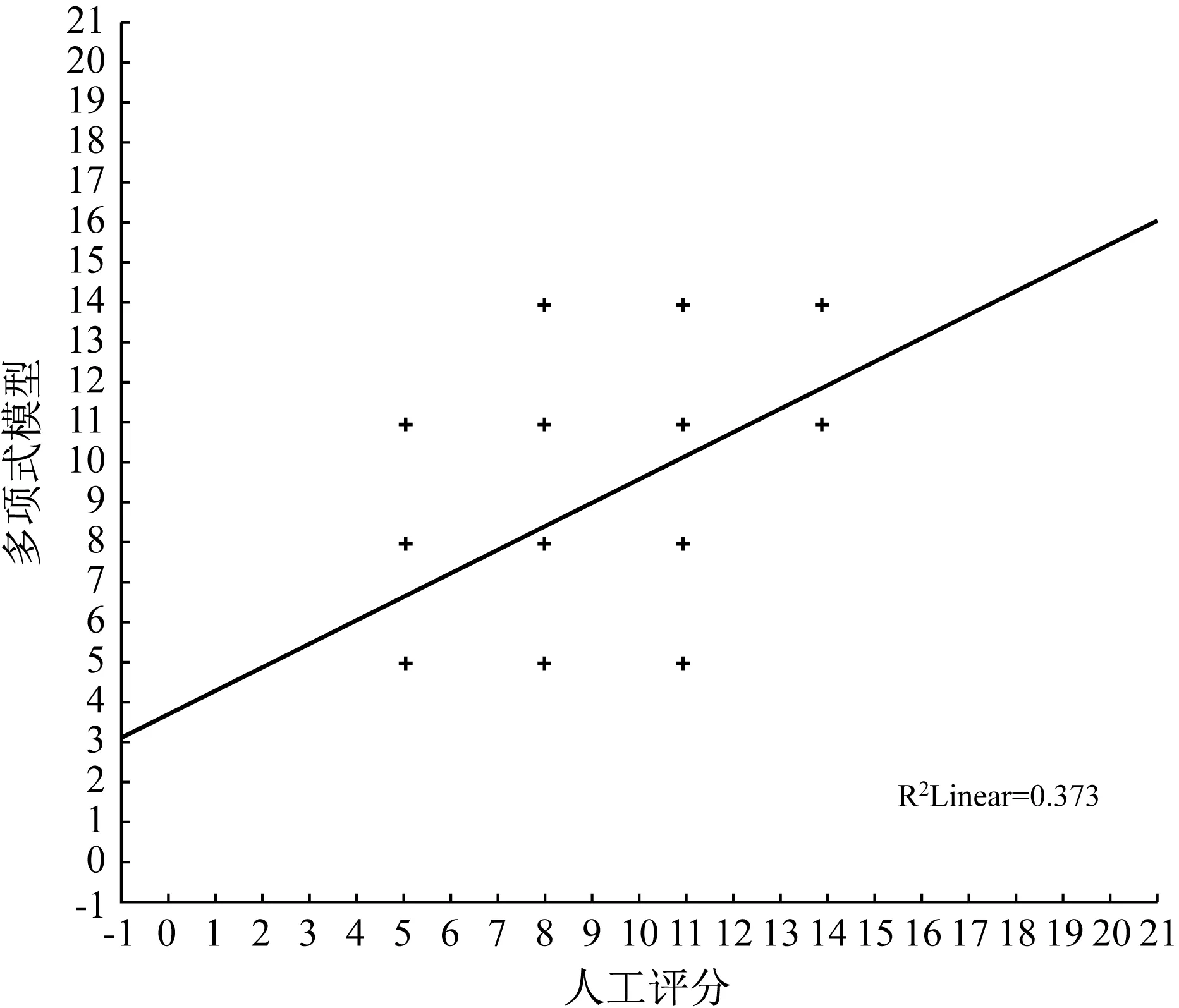
图2 人工评分与多项式模型散点图
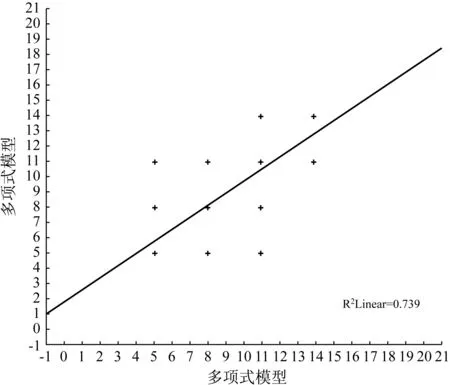
图3 多项式模型与多元伯努利模型散点图
重新观察样本数据,发现有部分数据(14组,占总数的7%)人工评分与BETSY自动评分差别较大(表5),相差等级在两个以上。根据整个实验流程,我们认为出现这种现象的主要原因有三个:第一,样本数据量不够。和其他自动作文评分软件相比,BETSY的样本量要求相对较小。较小的样本量也许会带来评分精度的降低,不过这需要进一步的研究才能确定。第二,BETSY系统本身存在一定的系统误差。例如,波特算法并非完美,部分字词无法正确地将词型、时态变化还原成原型(柯淑津2007);朴素贝叶斯模型也存在性能不稳定的问题等等(石志伟、吴功宜2004)。第三,BETSY内建的停用词列表中有319个词汇,这是一个通用停用词列表,并不包含中国英语学习者的语言特征。实验在设计过程中未考虑到要增删停用词列表以适合中国英语学习者特征,这也会影响到模型评分的精度。

表5 人工评分与BETSY之间的差异
综上所述,尽管实验中存在的一些问题尚需通过进一步的研究验证,但BETSY的评分结果与人工评分结果确存有较强的相关性,这也充分表明BETSY具备推广基础。当然,我们同时也期待下一个版本的BETSY系统能够进一步提高其评分的稳定性与准确性。
4. 结语
BETSY自动作文评分系统集多种自动作文平分系统的优点于一身。本文的实验结果也清楚地表明它与人工评分之间存在很强的相关性,可见BETSY系统具备一定的应用基础。
总体来看,虽然自动作文评分还面临着一些问题,但随着自然语言处理技术的不断发展,相信它们在中国的大规模实施为期不远。
附注:
① 见:http:∥echo.edres.org/betsy
② 见:http:∥echo.edres.org/betsy/bayesian_ov.htm
③ 见:http:∥echo.edres.org/betsy/bayesian_ov.htm
Kukich, K. 2000. Beyond Automated Essay Scoring [A]. In Marti A. Hearst (ed.). The debate on automated essay grading [J].IEEEIntelligentsystems(5): 25.
Lawrence M. Rudner & Tahung Liang. 2002. Automated essay scoring using Bayes’ Theorem [J].TheJournalofTechnology,LearningandAssessment(2): 3-21.
陈潇潇、葛诗利.2008.自动作文评分研究综述[J].解放军外国语学院学报(5):78-83.
古平.2006.基于贝叶斯模型的文档分类及相关技术研究[D].重庆大学博士学位论文.
柯淑津.2007.英文检索原型化处理[OL].http:∥www.cis.scu.edu.tw.
梁宏胜、徐建民、成岳鹏.2007.一种改进的朴素贝叶斯文本分类方法[J].河北大学学报(自然科学版)(3):328.
梁茂成、文秋芳.2007.国外作文自动评分系统评述起始[J].外语电化教学(5):18.
梁茂成.2005.中国学生英语作文自动评分模型的构建[D].南京大学博士学位论文.
石志伟、吴功宜.2004.改善朴素贝叶斯在文本分类中的稳定性[OL].http:∥www.intsci.ac.cn.
宋国杰、唐世渭、杨冬青、王腾蛟.2003.基于最大熵原理的空间特征选择方法[J].软件学报14(9):1544-1545.
万鹏杰.2005.电子软件评估系统测试大学英语写作的研究报告[J].外语电化教学(6):11-13.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
数理化解题研究(2017年4期)2017-05-04 04:07:54
信息安全研究(2016年4期)2016-12-01 06:06:54
发明与创新(2016年5期)2016-08-21 13:42:46
铁道通信信号(2016年6期)2016-06-01 12:10:20
课程教育研究·学法教法研究(2016年7期)2016-04-26 16:03:25
电子器件(2015年5期)2015-12-29 08:43:15
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
金陵科技学院学报(2014年1期)2014-03-15 03:29:00
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
