
基于弹性网格的西夏文字识别
2011-10-15 01:37门光福潘晨柳长青
中文信息学报 2011年5期
门光福,潘晨,柳长青
(1.宁夏大学数学计算机学院,宁夏银川750021;2.中国计量学院信息工程学院,浙江杭州310018)
1 引言
近年来西夏研究在国内外引起了广大学者的高度重视,也取得了很大进展,大批西夏古籍文献如《俄藏黑水城文献》、《中国藏西夏文献》、《英藏西夏文献》经整理被影印出版。目前,西夏文及西夏文献的研究仍停留在传统手工翻阅查找阶段,研究工作因此耗时费力,异常辛苦。计算机技术的迅猛发展无疑给西夏研究工作带来了契机,如何快速、准确地将这些文献资料转换为文本并为西夏文献建立文本数据库具有重要的研究与应用价值[1-2]。
当前国际上在西夏文字的计算机数字化方面的研究主要集中在日本、俄罗斯和中国台湾[3]。日本国立亚非语言文化研究所1996年制作了西夏文字库和排版系统,1997年中国学者李范文教授和日本学者中岛干起利用该排版系统合作出版了《电脑处理西夏文〈杂字〉研究》一书。该所副教授荒川懊太郎与俄罗斯西夏学专家克恰诺夫合作出版了《西夏文字典》。另外,值得一提的是国际合作中的国际敦煌项目[4]。1994年,旨在促进敦煌文物文献保护和研究以及数字化的敦煌国际合作项目组(简称IDP)正式成立,秘书处设在大英图书馆。IDP早期工作主要集中在修复、保护与编目等方面,近年来加快了数字化步伐,目前正朝着将包括西夏文献影印图像在内的敦煌及丝绸之路文物文献全部网络化的目标而努力。在国内,马希荣、柳长青[5-8]等从西夏文字识别的版面分析、二值化、倾斜检测、尺寸归一化及去噪等预处理技术到西夏文字的各种特征提取及西夏文字神经网络的识别等方面都做了一些研究。
西夏文献中的西夏文字多以刻板文字或手写体形式出现,与印刷体文字有很大的区别,存在大小不固定,整体或局部位置产生偏移等情形,这对识别过程及识别率会产生很大的影响。西夏文献中的西夏文字的识别可以借鉴手写体汉字识别的相关技术,但由于西夏文字笔画繁多,平均笔画数在25画左右,而且西夏文字之间具有很大的相似性,这无疑又增加了识别的难度。
近年来,大量的研究实验表明,方向特征是一种较好的手写体文字特征[9],弹性网格技术[10-14,20]可以提取字符图像的局部特征,能很好地区分相似字,容忍不同书写风格所引起的笔划位置不稳定、局部字形变形等变化,所以在手写体字符识别中得到广泛应用。本文将采用弹性网格对西夏文字进行网格划分,并提取笔画特征,然后对提取的笔画特征采用LDA方法进行降维处理,给出西夏文字识别的一种有效方法。
2 西夏文字弹性网格笔画特征提取
在对西夏文字提取笔画特征之前,首先采用大津方法[15]对西夏文字图像进行二值化处理,然后对二值化后的西夏文字图像采用形态学细化算法[16,21]进行细化。
尽管西夏文字结构复杂,但都是由直线段组成,而且这些直线段具有横、竖、撇、捺4个方向。西夏文字中的“横、竖、撇、捺”四种笔划的多少客观上来讲可以代表其特征,并且“横、竖、撇、捺”四种笔划分量的结构组合是不同的,因此将西夏文字进行“横、竖、撇、捺”四个方向分解后再提取统计特征,比起整体上提取特征来识别西夏文字更能反映西夏文字的组成结构,更具有区分性。具体的分解策略见图1。考虑黑像素的8个邻域,按如下方法确定4个方向分量:
(1)横分量:P1或 P5为黑像素;
(2)竖分量:P3或 P7为黑像素;
(3)撇分量:P2或 P6为黑像素;
(4)捺分量:P4或P8为黑像素。

图1 点P的八邻域
图2 给出了西夏文字分解的结果。
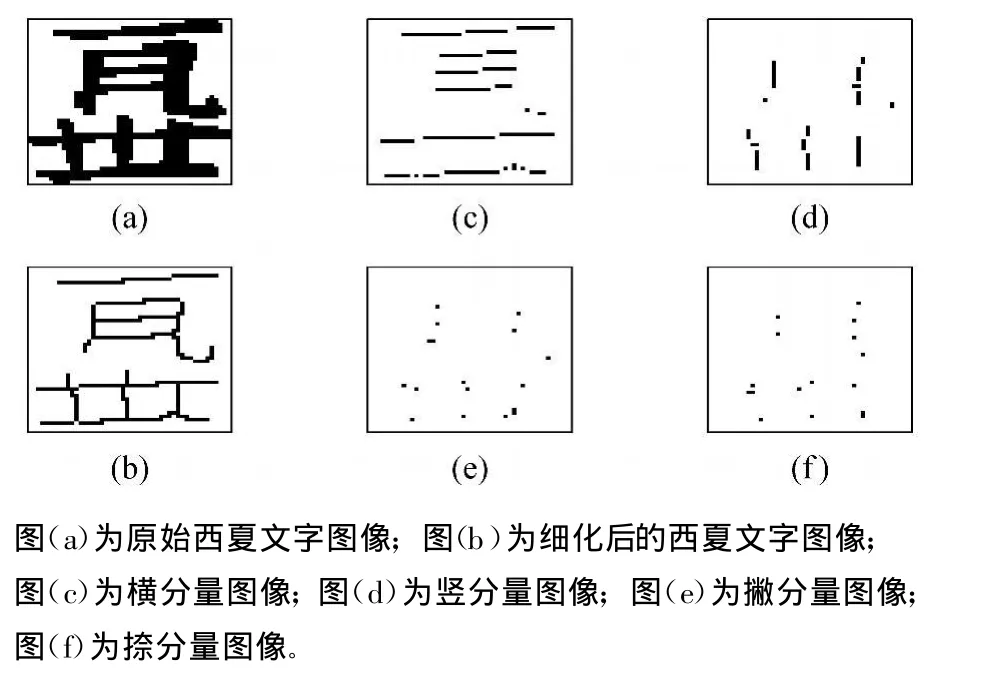
图2 西夏文字分解结果
弹性网格是一种根据文字图像的像素密度分布,用非均匀的网线划分文字的网格方法。将西夏文字如图2所示进行四种基本笔划方向分解后,构造弹性网格并作用于分解后的各西夏文字分量上,然后提取各分量在网格内像素点的概率分布特征。
设水平方向的网线数为N1,垂直方向的网线数为N2,当满足下面两式时,分别得到水平、垂直方向的非均匀网线Ii,Ij:

非均匀网线 Ii,Ij两两相交即构成弹性网格,选取不同的网线数可以得到不同的网格。当 N1=8,N2=6时,构造的全局8×6弹性网格如图 3所示。
假设得到的网格为B1,B2,…,Bn,西夏文字四个方向“横”、“竖”、“撇”、“捺”子图像为(x,y),则第i个子块内的方向统计特征如下:

图3 全局8×6弹性网格

3 LDA特征压缩
在第2部分中将西夏文字采用弹性网格划分,提取笔画方向特征后,得到的高维特征向量可以直接用距离方式度量,但由于基于高维特征空间内的算法时间复杂度和空间复杂度都大大增加,并且不容易估计参数值。所以为优化算法需要对特征空间进行降维处理。LDA方法是一种通用的提高类别分辨能力的线性变换,其优点是通过对可分性测度函数的优化,在变换后的低维特征空间内保留分类能力最强的一组特征[17-18]。本文选择将选用 LDA方法对提取的西夏文字笔画方向特征进行压缩。
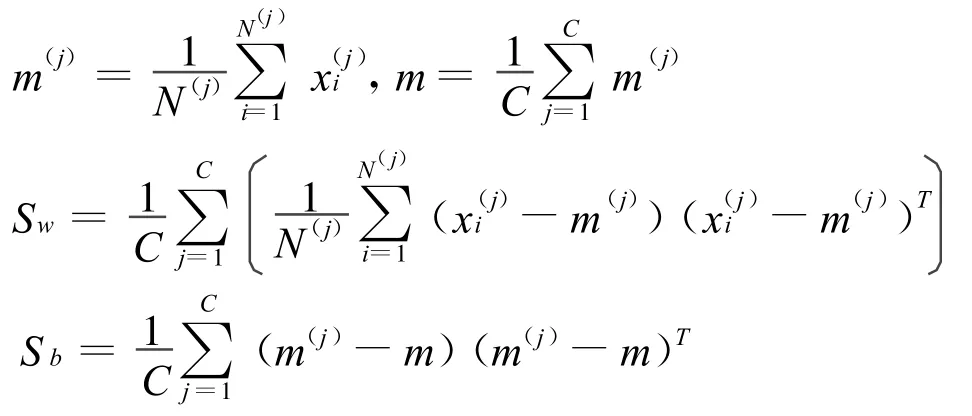
(3)设X为初始特征向量,通过Y=WTX变换得到压缩后特征向量Y。
4 实验
采用原宁夏大学计算中心夏汉字典第一区的前240个西夏文字的40套样本作为实验用西夏文字,每个西夏文字为48×48个像素。为检验各种识别方法的性能,实验中选取v重交叉验证法作为识别方法性能的衡量指标。用此方法把训练集划分成4个子集,每个子集包含10个样本,训练时用3个子集的样本训练,用剩下的1个子集的样本做测试得到1次识别率,依次对每个子集都做测试可得到4次识别率,取4次识别率的平均值作为识别方法性能的衡量指标。实验所采用的计算机的硬件配置为AMD Athlon Dual Core 4000+,内存为 2G DDR,硬盘为日立串口250G。软件环境为WindowsXP SP3下的matlab7.0。图4为实验中用到的部分西夏古籍文献中的西夏文字样本。

图4 实验所采用的部分西夏古籍中西夏文字样本
4.1 不同网格划分下识别率比较
本小节实验的目的是:讨论用笔画方向分解特征作为文字的特征,在欧式距离度量方式下,采用不同网格划分下的识别效果。实验数据如下:
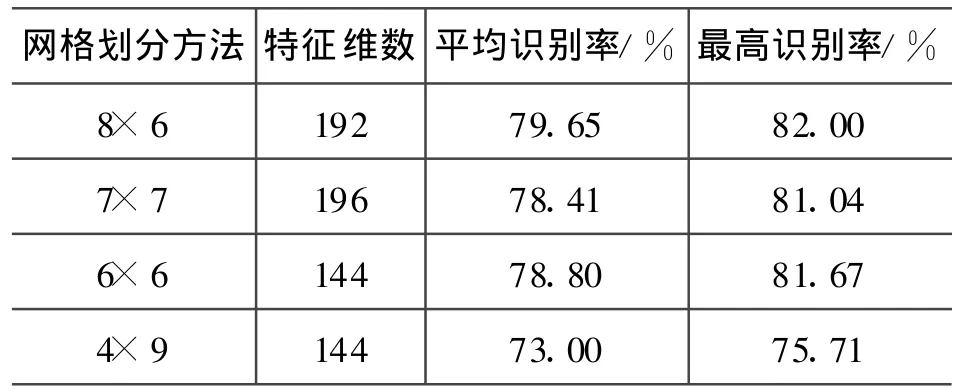
表1 不同网格划分方法下的识别率比较
由表1中的实验结果可以看出:使用全局8×6网格时的识别率最高。因此,在实际应用时可以选用全局8×6网格共192维特征作为西夏文字的识别特征。
4.2 LDA方法压缩特征的识别率比较
LDA方法可以有效压缩特征并提高识别率,其中维数d的选择对识别率有一定的影响。本实验选欧氏距离分类器,取4重交叉验证平均识别率,对提取的8×6弹性网格的笔画特征共192维原始特征采用LDA方法降维。图5给出了压缩维数d从20到190时的识别率变化趋势。
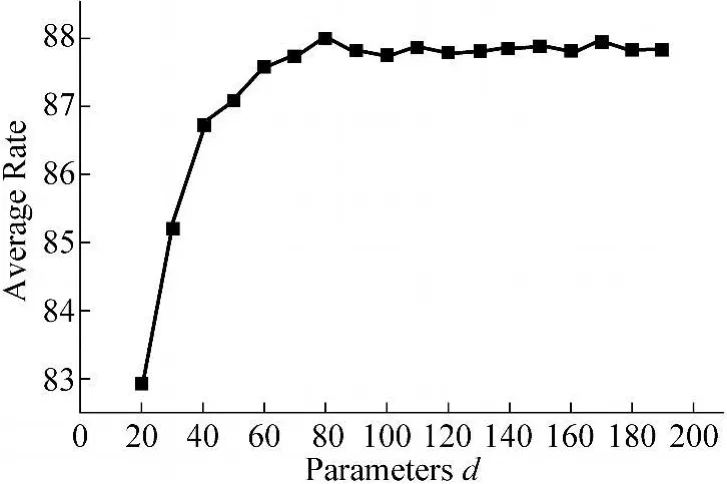
图5 不同参数d下的识别率
由图5可知,当压缩维数在80左右时识别率达到最大。高维时识别率略有下降,主要是由于分类器模型的符合程度、参数的估计误差等随着维数的增大而逐渐恶化所导致。
通过上面实验,选定维数d=80,采用不同距离度量方式下的识别率如表2所示。

表2 不同距离度量方式下LDA方法压缩特征前后的识别率比较
表2结果表明,使用LDA方法将特征从192维压缩到80维后,各种距离测度下的识别率都显著提高,该实验也说明了 LDA方法压缩西夏文字弹性网格笔画方向特征的有效性。
4.3 测试样本作为多候选字时的识别率分析
本实验主要讨论采用LDA方法压缩全局8×6弹性网格的笔画方向特征作为多个候选字的识别特征时的识别率比较,分类距离选用欧式距离,实验结果如表3和图6所示。从实验结果中可以看出,随着候选字个数的增加,识别率逐步提高。如果测试样本作为前15个候选字时,识别率可达到99.05%。因此,用该特征及分类方式作为样本的粗分类可以达到很高的准确率。

表3 前n个候选字的识别率
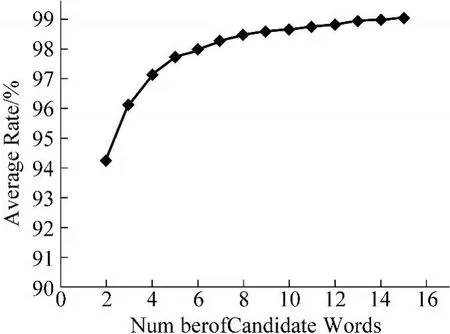
图6 多候选字识别率
5 结束语
本文基于弹性网格上笔画方向的特征分解和提取,采用LDA方法压缩特征对西夏文字进行分类识别研究。实验证明对于西夏文字这样一种相似度远远高于汉字的象形文字,本文所提方法能够有效的进行识别,识别率可达87.99%以上。本文的研究成果为以后的手写体西夏文字、西夏文献图片资料中的西夏文字的自动识别等的深入研究打下基础。
[1]柳长青.基于 Level Set方法的西夏字轮廓提取[J].中文信息学报,2009,23(4):71-75.
[2]李宇明.搭建中华宇符集大平台[J].中文信息学报,2003,17(2):1-6.
[3]史金波,陈育宁.中国藏西夏文献[M〕.甘肃:教煌文艺出版社,2005.
[4]刘扭,段慈明,王惠临,等.中医药古文献语料库设计与开发研究[J].中文信息学报,2005,22(4):24-0.
[5]马希荣,王行愚.西夏文字特征提取的研究[J].计算机工程与应用,2002,38(13):38-39.
[6]马希荣,王行愚.神经网络的西夏字识别技术研究[J].计算机工程与应用,2001,37(18):10-11.
[7]柳长青,杜建录.网络下的西夏文及西夏文献处理研究[J].宁夏社会科学,2008,(5):113-115.
[8]马希荣,柳长青,等.夏汉字处理及电子字典[M].北京:清华大学出版社,1999.
[9]刘伟,朱宁波,何浩智,等.弹性网格模糊特征的手写体汉字识别方法[J].中文信息学报,2007,21(3):117-121.
[10]陈章辉,黄小晖,陈鹏飞,等.基于双弹性网格的手写体汉字识别[J].计算机应用,2009,29(2):395:397.
[11]Lianwen Jin,Gang Wei.Handwritten Chinese Character Recognition with Directional Decomposition Cellular Features[J].Journal of Circuit,System and Computer,1998,8(4):517-524.
[12]S W Lee,J S Park.Nonlinear Shape Normalization M ethods for the Recognition of Large Set Handwritten Character[J].Pattern Recognition,1994,27(7):895-902.
[13]金连文,高学.几种手写体汉字网格方向特征提取方法的比较研究[J].计算机应用研究,2004,21(11):38-40.
[14]金连文.手写体汉字识别的研究[D].广州:华南理工大学,1996.
[15]Otsu.A Threshold Selection M ethod from Gray-Level Histogram[J].IEEE Trans on SMC-9,1979:62-66.
[16]杨淑莹.VC++图像处理程序设计[M].清华大学出版社,2003.
[17]Balakrishnama S,Ganapathiraju A,Picone J.Linear Discriminant Analysis for Signal Processing Problems.Southeastcon'99 Proceedings.IEEE 25-28,1999-04:78-81.
[18]姜铮铟,丁晓青.基于M QDF的英文OCR多模板分类器[J].计算机工程,2005,31(15):56-58.
[19]王华,丁晓青.多字体印刷藏文字符识别[J].中文信息学报,2003,17(6):47-52.
[20]金连文,徐秉铮.手写体汉字识别中的一种新的特征提取方法——弹性网格方向分解特征[J].电路与系统学报,1997,2(3):7-12.
[21]门光福.一种基于多级分类的西夏文字识别算法[J].高师理科学报,2010,30(4):44-47.
猜你喜欢
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
西夏学(2017年1期)2017-10-24
西夏学(2017年1期)2017-10-24
电脑知识与技术(2017年3期)2017-03-27
西夏学(2016年2期)2016-10-26
中国交通信息化(2016年2期)2016-06-06
