
基于数据挖掘的面向话题搜索引擎研究
2011-07-31 10:28张佳骥吴立德刘海娟
无线电通信技术 2011年5期
陈 勇,张佳骥,吴立德,刘海娟
(1.中国电子科技集团公司第五十四研究所,河北石家庄050081;2.复旦大学,上海 200433)
0 引言
目前,无论是在互联网上还是在机构内部,电子文本文档的数量都在快速地增加着。通常这些文档未经处理,杂乱地堆积在一起。这种原始状态大大降低了文档的可利用性,文档的信息价值无法实现。文本搜索引擎的作用就是帮助人们快速准确地找到符合其检索需求的相关文档。因此,文本搜索引擎技术是开发和利用现有文本文档的基础,有着很好的应用前景。
1 问题分析
目前,大多数文档检索技术都是以单个词为处理对象的[1,2]。这种技术有以下缺点。首先,从用户角度来讲,有时让用户仅仅使用几个关键词就把检索要求描述清楚是一件很困难的事情。检索需求的模糊不清必然会导致检索结果的混乱;其次,从关键词检索技术本身来讲,只要一个文档中出现了检索关键词,就认为此文档满足检索要求,这样的简单匹配方法常常会检索出很多非相关文档。
在文档表示技术方面,目前许多文档表示方法主要是基于向量空间模型(Vector Space Model)理论的[3,4]。向量空间模型理论也是以单个独立词为处理对象,并且假定词与词之间是相互独立的。首先从词汇表中选择若干词作为特征词,由这些特征词构成向量空间,然后把文档集合中的每一个文档表示为向量空间中的一个向量。基于向量表示就能够计算两两文档之间的相似度。向量空间模型理论是以词与词之间互不关联和相互独立为前提的。这一假设与实际情况并不相符,因为,在实际文本中词与词之间是相互关联的。
通过对目前检索和文档表示技术的分析,可以发现检索效果不佳主要有2个方面的原因。一方面,用户无法仅仅利用若干关键词就准确地描述出其检索要求,检索要求的不明确进而造成了检索结果的混乱;另一方面,向量空间模型认为词与词之间是相互独立的,因而只能基于单个词抽取文档特征,重要的上下文信息没有得以利用为文档表示服务。
2 解决方案
为了避免关键词在描述用户检索要求方面的局限性,使用示例文档作为用户表达检索要求的方式。一篇示例文档包含了比若干关键词丰富得多的信息,能够更全面地代表用户的检索要求。这样,就可以通过计算文档集合中各个文档与示例文档的相似度来找出相关文档,是否能够对文档进行准确表示直接影响着检索结果的好坏。利用向量空间模型对文档进行表示的缺点在于:在实际文本中,词与词通常是相互关联而不是独立的,正是词与词的各种搭配组合才使得语言能够表达各种各样的概念和丰富多彩的语义。另外,一个词的具体含义是由上下文中的一些关联词决定的,将词作为相互独立的个体来看待就忽略了词与词之间重要的关联关系,许多由词组表达的重要特征就无法被发现。
在此项研究中,提出了同时抽取单个词特征以及多词特征对文档进行表示的方法,这样就能够在多个层次上对文本进行分析,在多种精度上考察文档间的相似度。之所以有这样的考虑是因为,一方面,相对于独立的单个词而言,词组包含了词与词之间的关联信息,能够表达更详细、更具体的语义,这样就可以克服基于单个词方法的缺点;另一方面,与若干关键词相比,示例文档为抽取有意义的词组提供了可能。示例文档由句子组成,描述了一个完整的事件,因此能够从中抽取有意义的词组。
要想利用词组进行文档间的比较,就需要找出与文档主题紧密相关的词组。与文档主题紧密相关的词组在文档中会被反复提及,因此,会以较高的频率出现。
如何高效地找出这些频繁出现的词组是一个需要解决的技术难题。简单的穷尽算法显然无法解决这一问题。该项研究能够成功地解决这一问题,其技术突破点在于首次把数据挖掘技术[5]引入到文档搜索领域,借助挖掘算法大大提高了抽取文本特征的效率。为了利用数据挖掘算法,把一个文档看作是一个数据集,把一个句子看作是一个交易记录,把句子中的词看作一个项,利用数据挖掘算法找出频繁项目集,挖掘结果中的频繁项目集就是频繁词组。
文档相似度的计算是基于2个文档间发生匹配的词组进行的。从信息论的角度来讲,2个对象间的相似程度反映的是二者间共享的特点的多寡。常用的基于单个词计算2个文档相似程度的公式如式(1)所示:

在研究中,根据基于词组比较的特点设计了如式(2)所示的文档相似度计算公式。式(2)考虑了以下3点因素:
①匹配词组的长度。匹配词组的长度越长,比较的精度就越细,2个文档在高精度上的匹配要比在低精度上的匹配更有意义。因此,应被赋予更高的权值;
②相互匹配词组的数量。2个文档间相互匹配的词组越多,那么其相似度越高;
③相互匹配词组在2个文档中发生的频率。匹配词组在2个文档中发生的频率越高,2个文档越相似。
具体的文档相似度计算公式如下:

d1和d2表示相互比较的2篇文档;L代表最长的特征词组长度;wk是长度为k的特征词组的权重,通常特征精度越高,其权重越高;当匹配词出现在文档标题中或是人名、机构名和地名时,会给以额外权重;Pk为在长度为k特征词组上发生的匹配数量;和分别表示匹配特征词组在文档1和文档2中的频率;式中分母是文档1和文档2中长度为 k的特征词组频率之和。
3 示例文档检索
图1是一个示例文档检索系统流程图。

图1 示例文档检索系统
对于基于词组的处理方式,需要使用数据挖掘算法抽取文本中的重要词组特征。图的左半部分表示一个非实时的建模过程,主要是抽取各个文档的文本特征并进行聚类;图的右半部分表示一个实时的检索过程。图1中各个模块功能如下:
①分词处理:研究使用中文文本进行实验。中文不同于西方语言,词与词之间没有明显的间隔。因此,在对文本进行处理之前需要对中文文本进行分词处理,并为每个词添加词性标注;
②过滤停用词和非关键词:根据分词结果,把介词、助词以及一些非关键词删除。这些词通常与文档主题无关,删除它们不会影响系统性能,还可以减少运算时间;
③利用数据挖掘算法抽取特征词组:利用数据挖掘算法抽取各个文档的特征;
④聚类:利用聚类算法对文档进行聚类,将相似的文档聚在一起,这样可以提高检索阶段的执行效率;
⑤计算向量与各类的类中心距离:计算示例文档与各个类之间的距离,从而确定那些与示例文档最相近的类(相似类)。同时,排除那些与示例文档距离较远的类(非相似类)。这样在检索阶段就无需计算示例文档与非相似类中各个文档的距离,从而节省了时间;
⑥按相似度对相似类中的文档排序:计算示例文档与相似类中每一个文档之间的距离,并根据距离排序。
4 实验
实验是基于一个含有21 734个文档的文档集合进行的。该文档集合由基础文档和话题文档两部分组成:基础文档部分含有21 627个文档,这些文档来自网上数据库—慧科新闻。话题文档部分含有107个文档,它们分别属于24个话题,这些话题是从新闻网站的专题新闻获取的。这2部分文档都涉及了政治、社会和金融等方面的新闻。基础文档部分所含文档都是2004年及以前的新闻报道;24个话题中包含的文档都是2006年的新闻报道。每篇文档平均包含1 000个汉字。利用搜集到的24个话题进行检索实验。从某一话题中任选一篇新闻报道作为示例文档,看能否检索出此话题中的其他新闻报导。准确率、召回率定义如下:

表1列出了取检索结果前n(n=2,5,8,10)篇文档时的准确率。
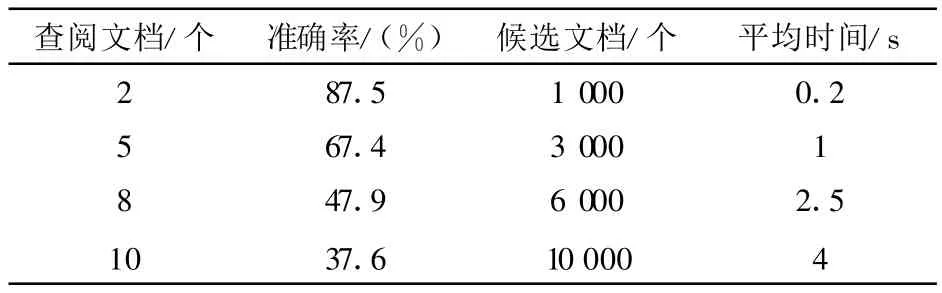
表1 检索准确率及检索时间
若n=话题所含新闻报道数,那么检索准确率为79.02%。当n=10时的召回率为84.67%。检索时间依需要与示例文档进行相似度计算的文档数量多少而变化,如表1所示。另外,发现文本中的命名实体在文本检索过程中可以发挥重要的作用。命名实体指的是文本中出现的人名、机构名、地名和时间。命名实体反映了事件的发生地点、时间以及涉及的人物和机构,这些都是构成事件的要素。因此,2个文档在这些词上发生的匹配要比在其他词上发生的匹配更能说明2个文档间存在共性。在算法中,通过给发生在命名实体上的匹配更多的权重的方法来强调命名实体的重要性。
5 结束语
研究提出的利用数据挖掘算法抽取文本的多层次特征技术,能够克服传统特征抽取方法无法抽取多层次特征的不足。这种算法易于实现,且运算速度快,可以应用于面向话题的文本检索。
[1]KENNETH L V,MOSES C M.Information retrieval in document spaces using clustering[M].Master's Thesis,Department ofInformaticsand Mathematical Modelling Technical University of Denmark,Auguest,2005.
[2]LIU Shuang,LIU Fang,YU Clement.An Effective Approach to Document Retrieval via Utilizing WordNet and Recognizing Phrases[C]//SIGIR'04,July 25 29,Sheffield,Yorkshire,UK,2004:266-272.
[3]ZAMIR O,ETZIONIO.Web DocumentClustering:A Feasibility Demonstration[C]∥Proceedings of the 19th International ACM SIGIR Conferenceon Research and Development in Information Retrieval(SIGIR98),1998:46-54.
[4]SALTON G,YANG C S,YU C T.A Theory of Term Importance in Automatic Text Analysis[J].JASIS,1975,26(1):33-44.
[5]HAN Jia-wei,MICHELINE KAMBER.Data Mining:Concepts and Techniques[M].San Fransisco:Morgan Kaufmann Publishers,2002.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
山东冶金(2019年1期)2019-03-30
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
信息安全研究(2016年4期)2016-12-01
高中生学习·高三版(2014年3期)2014-04-29
