
改进的BP神经网络及其在销量预测中的应用
2011-07-23 00:28:16毕建涛魏红芹
山东理工大学学报(自然科学版) 2011年6期
毕建涛,魏红芹
(东华大学旭日工商管理学院,上海200051)
销量预测在企业的经营运作中扮演着非常重要的角色.企业进行生产或提供服务的最终目的都是诱发消费者的购买行为,尽可能多的将产品销售出去.企业主要的市场营销活动以及决策制定,也是围绕着产品销售而开展的.作为企业经营决策的一个重要方面,如何及时而准确的做好销售预测是企业面对的一个难题.由于现代企业的市场营销环境日益动态复杂,一些随机性因素如产品季节性、消费偏好、市场促销活动等,会使得产品的销售量短时间内出现急剧波动.传统的数量经济学模型,如时间序列预测法和因果关系预测法,都要求时间序列具有稳定的变化趋势和统计趋势[1].这些预测模型由于受到变量个数的限制以及变量之间复杂关系的影响,在处理复杂的、具有随机性的时间序列时,暴露出很大的局限性.
另一方面,人工神经网络具有很强的并行处理能力以及非线性映射能力,在许多实际工程应用特别是预测领域取得了普遍的重视.然而,由于BP神经网络采用的是梯度下降训练算法,网络不可避免的存在收敛速度慢、学习率不稳定、容易受到噪声数据影响等不足.理论界的许多学者对BP神经网络的改进进行了研究,并提出了一系列的改进方法.例如,针对标准梯度下降算法的局限性,宿延吉等[5]提出了几种BP网络的改进算法,包括克服遗忘的BP算法,改变误差函数的BP算法、带有变周期权值修正的BP算法以及分级学习算法等.高海兵等[6]提出了基于连接结构优化的粒子群优化算法(SPSO)训练神经网络权重的同时训练其连接结构,删除冗余连接,提高网络的分类能力.Ruan Q和Wang Y Q[7]提出把主成分分析法和BP网络相结合,用于优化隐层神经元的个数以及BP网络训练的初始参数,并进行了实例研究.
针对标准BP算法的局限性,本文提出构造基于主成分分析方法的PSO-BP混合预测模型,分别从样本质量和初始权值两个方面对BP神经网络进行改进.首先利用主成分分析法对预测模型的输入样本进行降维去噪处理,将提取的主成分作为预测模型新的输入以简化BP网络结构;然后利用粒子群优化算法对BP神经网络的初始权值进行优化,以提高网络的预测精度;最后通过实例分析说明该模型的有效性.
1 研究方法的理论基础
1.1 主成分分析法
主成分分析法(Principal Components Analysis,PCA)是将指标转化为少数几个综合指标的一种多元统计方法.其基本思想是通过变量的相关关系矩阵内部结构的研究,找出能控制所有变量的少数随机变量,来描述多个不同变量之间的相关关系[8].当样本数据维数较多、结构复杂的时候,可以采用主成分分析的方法对样本数据进行预处理,来简化输入的样本数据并消除噪声数据的影响.
1.2 BP神经网络
人工神经网络(Artificial Neural Network,ANN)是一种模范动物神经网络行为特征,进行分布式并行信息处理的算法数学模型.BP神经网络是目前使用最为广泛的一种人工神经网络算法.BP算法由两部分组成:信息的正向传播和误差的反向传播.BP神经网络具有很强的自学习能力,网络根据输入输出信号,自适应的调节网络的连接权值W和阈值b.典型的BP神经网络包括输入层、隐含层和输出层,网络结构如图1所示.

图1 BP神经网络的拓扑结构
1.3 粒子群优化算法
PSO算法首先生成初始种群,即在解空间中随机初始化一群粒子的位置,每一个粒子代表优化问题的一个可行解,粒子的优劣由一个事先设定的适应度值来确定.每个粒子将在解空间中运动,并由一个速度决定其飞行方向和速率大小.然后通过逐代搜索找到最优解[9].
设第i个粒子在D维搜索空间中的位置为Xi=(xi1,xi2,…,xiD),速度Vi=(vi1,vi2,…,viD)T,其个体极值Pi=(Pi1,Pi2,…,PiD)T,种群的全局极值Pg=(Pg1,Pg2,…,PgD)T.粒子根据个体极值和全局极值更新自身的速度和位置,更新公式如下:
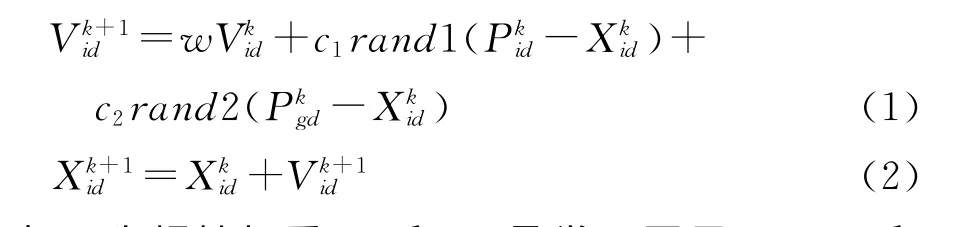
其中w为惯性权重,c1和c2是学习因子,rand1和rand2为分布于[0,1] 之间的随机数.同时为了防止粒子的盲目搜索,通常将粒子的位置和速度限制在[-Xmax,Xmax] 、[-Vmax,Vmax] 范围内.
2 基于主成分分析法的PSO-BP销量预测流程
基于PCA的PSO-BP销量预测模型的基本思想是:首先,利用主成分分析法对预测模型的输入样本进行降维去噪处理,将提取的主成分作为预测模型新的输入,然后再利用粒子群优化算法对BP神经网络的初始权值进行优化,将PSO算法的粒子最优解作为网络新的权值和阈值,最后利用充分训练后的BP网络对某产品的月销量进行预测仿真.
基于PCA的PSO-BP算法的预测流程及具体实现步骤如下:
第1步对初始样本数据进行预处理.由于初始的样本数据中,不同的输入变量之间数值大小以及量纲不同,因此在网络训练前需要对数据进行预处理,把所有数据都转化为[0,1] 范围内.函数形式如下所示:

其中,xmin为样本数据的最小值;xmax为样本数据的最大值.
第2步 对样本数据进行主成分分析.数据预处理之后,就可以对标准化数据矩阵进行主成分分析,求解样本系数矩阵R的特征方程|R-λIp|=0,计算特征根和特征向量,并且计算每个主成分的方差贡献率与累计方差贡献率,提取前m个较重要的主成分,然后将提取的主成分作为BP网络新的输入.
第3步 初始化BP神经网络的结构.初始化BP神经网络的结构包括设置网络的输入层、隐含层以及输出层的神经元个数,同时建立粒子与BP网络的权值和偏差的映射关系.对于产品销量预测问题,假定网络结构为M—N—1,输出节点为特定时刻t的产品销量.则搜索空间的维度维数n=(M+1)*N+(N+1).
第4步 惯性权重和学习因子的参数设置.惯性权重w体现的是粒子当前速度在多大程度上继承先前的速度,它将影响粒子的全局搜索能力和局部搜索能力.学习因子c1和c2代表将每个微粒推向Pid和Pgd位置的统计加速项的权重.
第5步 粒子位置和速度初始化.随机生成个个体,每个个体由两部分组成,第一部分为粒子的速度矩阵,第二部分代表粒子的位置矩阵.由于BP神经网络的权值与阈值一般初始化为[0,1] 之间的随机数,故将粒子群中每个粒子位置参数均取为[0,1] 之间的随机数,作为PSO算法的初始解集.
第6步 粒子适应度值的计算.粒子位置和速度初始化后,随机产生一个种群,计算每一个粒子的适应度值.以BP网络训练的均方误差函数E作为粒子的适应度评价函数,计算每一个粒子的适应度值.

其中:N为训练样本的个数,yreal为第i个样本的实际值,yi为第i个样本的预测值.最后算法迭代停止于适应度最低的粒子对应的位置,即为所求问题的最优解.
第7步寻找个体极值和全局极值.通过对每一次迭代中粒子适应度值进行比较,确定每个粒子的个体极值和全局最优极值.
若Present<Pbest,Pbest=Present,Pbest=xi;否则,Pbest不变;
若Present<gbest,gbest=Present,gbest=xi;否则,gbest不变;
其中,Present为当前粒子的适应度,Pbest为粒子的个体极值,gbest为全局最优值.
第8步更新每个粒子的速度和位置.在每一次迭代过程中,李子通过个体极值和全局极值更新自身的速度Vid和位置Xid,更新公式如下:
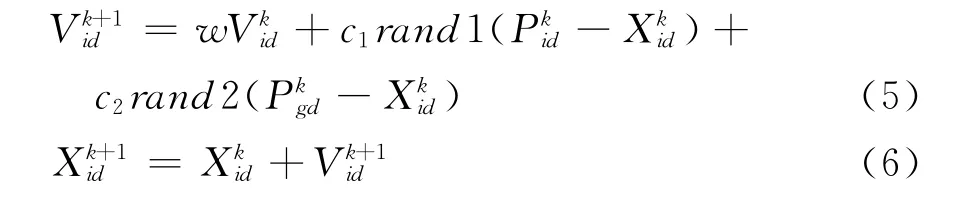
其中:w为惯性权重,c1、c2为加速度因子,r1、r2为分布于[0,1] 之间的随机数.
第9步 迭代停止控制.对迭代产生的种群进行评价,判断算法的训练误差是否达到期望误差或最大迭代次数.如果条件满足则转到步骤(10);否则,返回步骤(6)继续迭代.
第10步 最优解生成.算法停止迭代时,对应的值即为训练问题的最优解,即BP神经网络的权值与阈值.将上述最优解代入BP神经网络模型进行二次训练学习,最终形成产品销量的混合预测模型,就可以利用建立的混合预测模型进行销量预测.
基于PCA的PSO-BP的算法流程如图2所示.
3 实例分析
为了验证模型的有效性,本文以S品牌服装为例,选取2009年4月到2011年3月(共24个月)的月销售数据,构建基于PCA的PSO-BP销量预测模型,对该品牌的月销售时间序列进行预测,同时与标准BP网络的预测效果进行了比较.
3.1 主成分分析
由于影响服装产品销量的因素众多,本文选取了季节指数X1、产品的生命周期X2、促销价格折扣X3、节假日天数X4,广告活动投入X5、竞争对手的促销活动X6、社会消费品零售总额X7以及居民消费价格指数X8等8个因子作为自变量,利用SPSS软件对影响因素进行主成分分析.分析结果见表1.
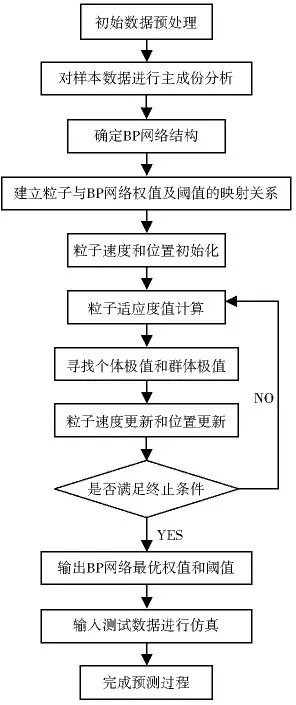
图2 基于PCA的PSO-BP的算法流程图

表1 主成分的特征值及总方差解释
从表1可以看出,原始数据经过主成分分析之后,特征根大于1的主成分有3个.其中第1主成分的特征根为6.468,方差贡献率为59.326.因此,按照主成分的选取标准,我们可以提取3个主成分,这3个主成分的累计解释方差贡献率达到88.344,能够较好的解释原始变量的信息.
表2表示的是旋转后的因子载荷矩阵分析结果.从表2可以看出,第一主成分主要与促销因素有关,促销价格折扣、促销活动天数、广告活动投入、竞争对手的促销活动对第1主成分的相关系数都大于0.8.第2主成分中产品需求的季节性和产品所处的生命周期相对其它因子贡献较大,由此可见,第2主成分主要考虑了产品因素.第3主成分则与宏观经济因素密切相关.
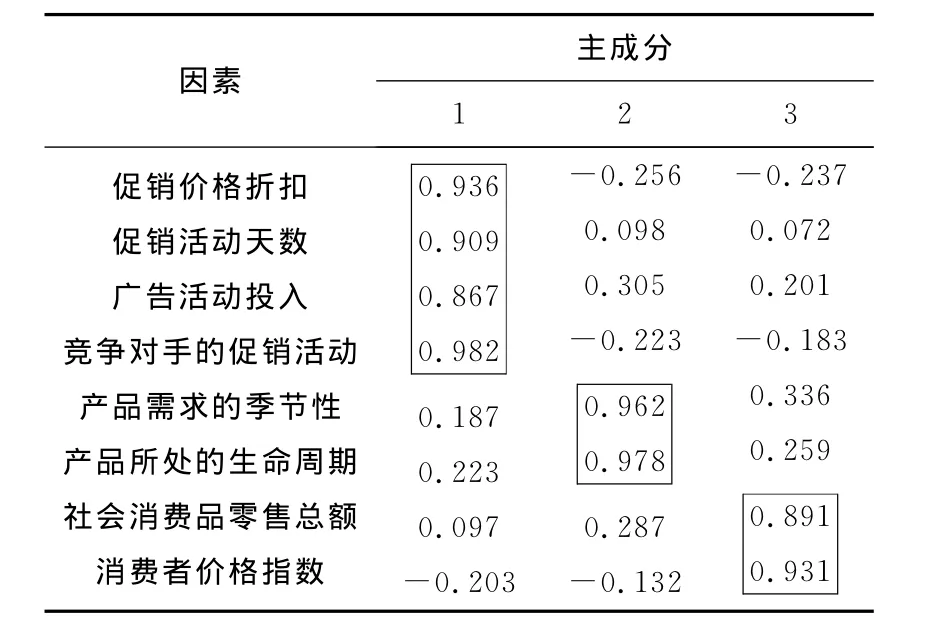
表2 旋转后的因子载荷矩阵
3.2 预测结果分析
影响因素的主成分提取完成之后,就可以以主成分的因子得分作为BP神经网络预测模型新的输入,对产品销量进行预测.为了验证模型的有效性,本文对S品牌服装2009年4月到2011年3月(共24个月)的月销售数据,进行了实例研究.同时将样本数据分为训练集和测试集.选取前18组数据作为训练集,以对网络进行充分训练;选取后6组数据作为测试集,用来检验模型的性能.
在利用Matlab软件进行仿真之前,需要对模型的相关参数进行设置.对于特定的预测问题,其输入节点和输出节点的个数也是确定的.设置隐含层的节点个数为5,输出节点数为1,即某一时刻促销产品销售量的预测值.BP网络隐含层采用tansig型激活函数,输出层采用purelin型激活函数.同时,对于PSO算法,采用0.9-0.4线性递减的惯性权重策略,学习因子c1=c2=2.粒子的最大速度Vmax取值为1,最大循环迭代次数Itermax=200.PSO算法最优适应度函数值的变化曲线如图3所示.
由图3可以看出,PSO算法适应度函数值fitness下降速度很快且较光滑.在迭代初期,适应度值急剧下降.经过90次循环迭代之后,PSO适应度值基本达到稳定状态.经过200次循环迭代以后,PSO算法适应度的全局最优解为3.452.由此可见,采用PSO优化后的BP神经网络的训练误差已经达到较理想的水平.
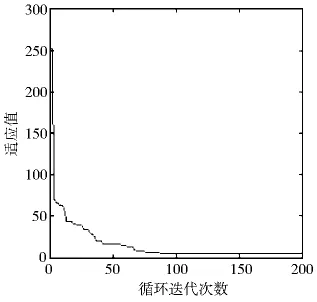
图3 适应度函数变化曲线

图4 模型预测结果
图4表示的是S品牌服装产品月销售量的预测结果.可见采用基于PCA的PSO-BP混合预测模型的预测值与实际值的拟合精度很高.其中2010年10月的预测值与实际值之间的绝对误差为1.2%,其余的网络预测误差都很小,绝对误差低于1%,预测效果较为理想.同时,为了验证模型的有效性,本文对标准的BP网络以及粒子群优化的BP网络的预测性能进行了对比分析.结果见表3.

表3 不同预测模型的性能比较
从表3可以看出,基于PCA的粒群优化BP网络具有更好的预测性能.在网络训练时间并未显著增加的情况下,PSO-BP网络的训练误差以及测试误差都较低,模型泛化能力更好,由此验证了模型的有效性.
4 结束语
针对影响产品销量的因素众多,并且影响因素之间相互作用等特点,本文提出把主成分分析法、BP神经网络以及粒子群优化算法相结合,构造混合预测模型对某品牌服装产品的月销售量进行预测.模型有几方面的优点:
1)通过主成分分析方法对影响产品销量的因素进行分析,消除了不同影响因素之间的多重共线性以及噪声数据的影响.然后,模型以提取的主成分作为网络新的输入,可以一定程度上简化BP网络隐层节点的个数,提高网络的泛化能力.
2)利用粒子群算法对BP网络的初始参数进行训练,将PSO算法优化后的参数作为BP网络的初始权值和阈值,从而一定程度上改善了梯度下降算法容易陷入局部极小值、预测精度低等缺点.
3)最后,利用建立的模型进行了实例研究,以验证模型的适用性以及性能的提高.
结果表明,基于PCA的PSO-BP混合预测方法具有较强的适用性,对于多影响因素的预测问题能够取得较好的预测效果.同时,模型也存在一定的不足和改进之处.例如,预测程序过于复杂,模型的稳定性还需要提高,模型的扩展性仍有待进一步研究和改进.
[1] 沈岳.基于时间序列马尔科夫链的服装销售预测[J] .丝绸,2009(11):32-34.
[2] 林俊,章兢.BP网络泛化性能的改善[J] .计算机与现代化,2001(3):1-5.
[3] 陆琼瑜,童学锋.BP算法改进的研究[J] .计算机工程与设计,2007,28(3):648-650.
[4] Ding S F,Jia W K,Su C Yet al.Neural network research progress and applications in forecast PCA approach to BP learning[J] .Lecture Notes in Computer Science,2008,5264:783-793.
[5] 宿延吉,张漫丽,秦汝增.神经网络BP算法的研究、实现及改进[J] .哈尔滨理工大学学报,1996,1(1):60-65.
[6] 高海兵,高亮,周驰,等.基于粒子群优化算法的神经网络训练方法[J] .电子学报,2004,32(9):1 572-1 574.
[7] Ruan Q,Wang Y Q.PCA approach to BP learning[J] .Journal of Fudan University(Natural Science),2005,44(2):318-322.
[8] 龙训建,钱鞠,梁川.基于主成分分析的BP神经网络及其在需水预测中的应用[J] .成都理工大学学报:自然科学版,2010,37(2):206-210.
[9] 秦毅男,廖晓辉,赵庆治.一种基于粒子群优化算法的神经网络训练方法[J] .河南师范大学学报:自然科学版,2007,35(3):169-171.
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
测控技术(2018年10期)2018-11-25 09:35:54
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
自动化学报(2017年7期)2017-04-18 13:41:02
中国塑料(2016年11期)2016-04-16 05:26:02
物理与工程(2014年4期)2014-02-27 11:23:08
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:42
教育与职业(2014年16期)2014-01-19 01:24:36
