
FP-Growth算法在中药数据挖掘中的应用
2011-07-09 13:31张博
湖南工程学院学报(自然科学版) 2011年3期
张 博
(亳州职业技术学院信息工程系,亳州236800)
数据挖掘就是从大型数据库的数据中提取人们感兴趣的知识.这些知识是隐含的、实现未知的潜在的有用信息,通过数据挖掘技术,用户可以从数据库中提取有用的知识、规律和深层次信息,同时还可以从不同角度观察和分析挖掘结果.
中药方剂是中国传统医学的重要组成部分,由于中药方剂主要是历代医生的手工汇总,其整体性、辩证性等特征过于抽象和定性化,无法像西方医学那样能够准确的定量.而将数据挖掘技术应用于中药方剂的配伍研究中,是把我国传统的中医药资源和现代信息技术相结合的重要途径.
亳州地处安徽北部,气候和土壤适宜中药材的生长,自古以来就有中药材种植和交易的历史,被誉为"中华药都".亳州是神医华佗的故里,得天独厚的中医药资源为中药方剂的研究提供了坚实的基础,同时也为本文进行中药方剂的数据挖掘工作提供了丰富的资源.
1 关联规则
在中医观点中,很多症状的诊断之间是存在着关联性.而在药方的搭配上,也同样存在着很多关联性.以关联规则为主要算法的数据挖掘,是分析中药关联性的有效方法.
数据关联是某种事物发生时其它事物会发生的一种联系,是数据库中存在的一类重要的可被发现的知识.而关联规则的数据挖掘是从大量的、有噪声的、模糊的实际数据中,抽取隐含在其中的、人们事先不知道的、但又潜在有用的关联信息和知识的过程.
Apriori算法是一种常见的挖掘布尔关联规则频繁项集的算法.其核心是基于两阶段频集思想的递推算法.该关联规则在分类上属于单维、单层、布尔关联规则.该算法的基本思想是:首先找出所有的频繁集,这些项集出现的频繁性至少和预定义的最小支持度一样.然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度.然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义.一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来.为了生成所有频集,使用了递推的方法.
Apriori算法易于实现,但在实际中存在有一些难以克服的缺陷:如对数据库的扫描次数过于频繁、会产生大量候选集合等,这样就使得Apriori算法的时间和空间复杂度过大.因此,在本文中,提出了基于FP-Growth算法的中药数据挖掘算法,并将算法应用在中药配方的关联度方面,进行了探讨.
2 FP-Growth算法
(1)FP-tree
在介绍FP-Growth方法之前,对FP-tree做如下定义:
①频繁模式树(Frequent Pattern tree)简称为FP-tree,是满足下列条件的一个树结构:它由一个根节点(值为null)、项前缀子树(作为子女)和一个频繁项头表组成.
②项前缀子树中的每个结点包括三个域:item_name、count和 node_link,其中:item_name 记录结点表示的项的标识;count记录到达该结点的子路径的事务数;node_link用于连接树中相同标识的下一个结点,如果不存在相同标识下一个结点,则值为“null” .
③为了方便树遍历,创建一个频繁项头表(frequent item header table),频繁项头表的表项包括一个频繁项标识域:item_name和一个指向树中具有该项标识的第一个频繁项结点的头指针:head of node_link.
(2)FP-Growth算法
FP-Growth算法使用一种紧缩的数据结构Fptree来存储查找频繁项目集所需要的全部信息.将提供频繁项目集的数据库压缩到FP-tree中,但保留项集关联信息;然后,将压缩后的数据库分成一组条件数据库,每个关联一个频繁项目集.这样避开了产生候选项集的步骤,极大的减少了数据交换和频繁匹配的开销,并且将数据库频繁模式的挖掘问题转化成挖掘FP-tree的问题.因此,在挖掘效率上FP-Growth算法明显优于Apriori算法,特别是在稠密数据库中,频繁项集的长度很大的情况下,FPGrowth算法的优势越明显.
其具体步骤如下:
①扫描事务数据库D一遍,得到频繁项的集合F和每个频繁项的支持度.把F按支持度递降排序,然后构造FP-tree
②挖掘FP-tree.由每个长度为1的频繁模式(初始后缀模式)开始,构造它的条件模式基,然后构造它的(条件)FP-tree,并递归地对该树进行挖掘.模式增长通过后缀模式与条件FP-tree产生的频繁模式连接实现.
③直到结果FP-tree为空,或者其只包含一个路径,这个路径可以生成所有子路径的组合,每个组合都是一个频繁模式.
一旦由数据库D中的事务找出频繁项集,就可以从它们中产生强关联规则(强关联规则满最小支持度和最小置信度).由于规则由频繁项集产生,每个规则自动地满足最小支持度,所以输出的规则是强关联规则.
3 基于FP-Growth算法的中药数据挖掘
方剂配伍的主要工作是提出适合中药方剂数据挖掘的算法,并将算法应用于数据挖掘模式的研究中.针对中药方剂的数据特点,提出改进的数据挖掘模式和算法,使用最大频繁关联模式对中药方剂进行研究,然后对药物配伍规律与药物药性结合起来进行数据挖掘的研究.
下面我们以中药方剂中的温中祛寒剂来说明通过FP-Growth算法发现中药的药性关联规则.
方剂学中的温中祛寒方剂主要有5个:理中汤、吴茱萸汤、大建中汤、小建中汤、缩脾饮,每个方剂的组成如下:理中汤(人参、白术、干姜、炙甘草);吴茱萸汤(吴茱萸、人参、大枣、生姜);大建中汤(川椒、干姜、人参、饴糖);小建中汤(酒芍药、桂枝、炙甘草、生姜、大枣、饴糖);缩脾饮(缩砂仁、煨草果、乌梅肉、葛根、白扁豆、炙甘草).
根据以上方剂的成分进行编码如下:人参为I1,白术为 I2,干姜为I3,炙甘草为I4,吴茱萸为I5,大枣为I6,生姜为I7,川椒为 I8,饴糖为 I9,酒芍药为I10,桂枝为I11,缩砂仁为 I12,煨草果为 I13,乌梅肉为I14,葛根为I15,白扁豆为I16.理中汤为事务T1,吴茱萸为事务T2,大建中汤为事务T3,小建中汤为事务T4,缩脾饮为事务T5.
接下来,建立温中祛寒剂的数据库如下:

表1 温中祛寒剂数据库
设最小支持度为2,得到符合条件的按照支持度排序的项集如下:
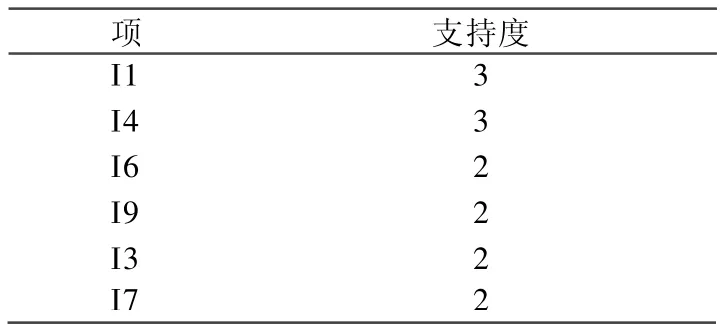
表2 支持度为2的项集
由频繁项集构建FP-tree,如图1所示:
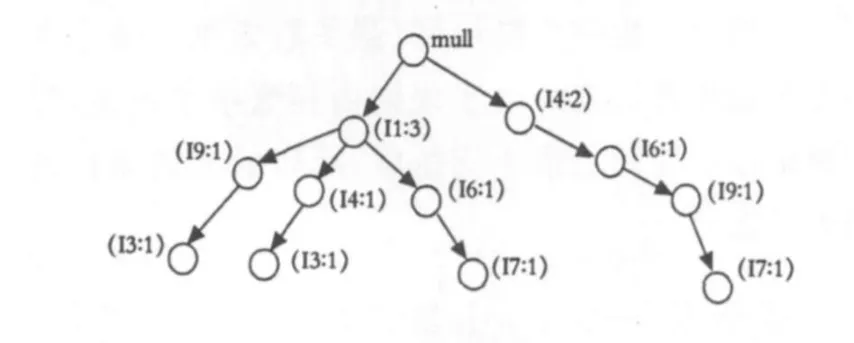
图1 根据温中驱寒剂建立的FP-tree
对FP-tree进行数据挖掘,可以得到方剂中的频繁模式:

表3 通过条件模式基挖掘
从表3的挖掘过程中,我们可以得到如下的中药组合关系:
①大枣、生姜;②人参、干姜;③人参、炙甘草;
这些组合还需要结合具体的中医治疗的实践来进一步验证和筛选,以达到最佳的药性组合.
4 总 结
由于方剂中的药物不仅关联,而且大量药物之间存在相互的药性作用,所以将数据挖掘技术应用在中药方剂配伍的研究上,具有很大的发展前景.本文中只是进行了小范围的数据样本的实验,在后期的工作中,会依靠已经建立的各专业中药数据库的资源,进一步扩大样本和方剂的范围,从而找到具有更好疗效的中药组合,为中药方剂的配伍提供可靠的研究依据.
[1]姚美村,袁月梅,艾 路,乔延江.数据挖掘及其在中医药现代化研究中的应用[J].北京中医药大学学报,2002,25(5):20-24.
[2]乔延江,李澎涛,苏刚强,肖培银,王永炎.中药(方剂)KDD研究开发的意义[J].北京中医药大学学报,1998,21(3):15-17.
[3]李 亚.中医名方配伍技巧[M].北京科学技术出版社,2003:45-47.
[4]谢 含.数据挖掘在中医药文献研究中的应用[J].中医药信息,2005,22(6):125-127.
[5]王瑞祥.基于FP-growth算法的中药关联程度分析[J].辽宁中医药大学学报,2007,9(4):7-8.
[6]刘闽碧.基于FP-growth算法的中药配方数据挖掘[J].医学信息,2009,22(12):2629-2630.
[7]顾红其.面向电子商务的WEB挖掘中关联算法的研究[D].苏州大学硕士论文,2009:25-29.
[8]高 明.关联规则挖掘算法的研究及其应用[D].山东师范大学硕士论文,2006.
猜你喜欢
电子制作(2021年14期)2021-08-21
中国民间疗法(2021年1期)2021-04-20
中国民间疗法(2020年22期)2021-01-07
天津科技大学学报(2018年4期)2018-08-22
中成药(2018年6期)2018-07-11
数学物理学报(2018年1期)2018-03-26
长春中医药大学学报(2017年1期)2017-04-16
电子设计工程(2014年12期)2014-02-27
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
