
基于遗传算法的聚焦爬虫搜索策略设计与研究
2011-06-29 06:14杨义先
成都信息工程大学学报 2011年5期
陈 悦, 陈 运, 杨义先, 胡 迪
(1.成都信息工程学院信息安全研究所,四川成都610225;2.北京邮电大学信息安全中心,北京100083)
1 引言
互联网上的网页数以亿计,并以指数级的速度增长。要从上亿的网页中快速、准确地找出想要的网页,对于通用搜索引擎来说是一项困难的任务。聚焦爬虫是专为查询某一领域或主题信息而出现的网页抓取工具。与通用网络爬虫不同,聚焦网络爬虫旨在抓取与某一特定主题内容相关的网页。因此,在搜索过程中无须追求最大覆盖率,对整个网络进行遍历,只需选择与主题相关的网页进行访问。所以,对于聚焦爬虫首要解决的问题是如何判断一个网页是否与主题相关,以及根据主题的相关度用怎样的搜索策略来爬取尽可能多的相关网页,并且保证较高的查全率和查准率。目前主要用的聚焦爬虫搜索策略有[1]:基于内容评价的搜索策略和基于链接结构评价的搜索策略。以上两种搜索策略虽各有优点,但也存在不少局限,一种好的搜索策略需要在有限的时间内,以较少的网络资源、存储资源和计算资源来获取较多的与主题相关的页面。所以,搜索策略应该在提高链接价值预测的准确性、降低计算的时空复杂性,以及增加网络爬虫的自适应性等方面有所发展,有所突破[2]。
2 遗传算法在聚焦爬虫中的应用
2.1 遗传算法简介
传统的遗传算法采用的都是固定的参数,由于遗传算法其本质是一种动态自适应的进化过程,固定的参数设置容易导致进化过程中最优个体的概率遗失而使算法收敛于局部最优,产生“早熟”现象。自适应遗传算法(Adaptive GA,AGA)中的交叉概率Pc和变异概率Pm会随着个体的适应度值自动的改变。当种群中各个体适应度值达到一致或趋于局部最优时,使Pc和Pm增加,而当种群的适应度值比较分散时,使Pc和Pm减少。同时,对于适应度值高于种群平均适应度值的个体,应该给予保护进入下一代继续繁殖,而对低于平均适应度值的个体应将其淘汰。因此,自适应遗传算法能够在保持种群多样性的同时,保证遗传算法的收敛性。
2.2 相关研究工作现状
遗传算法从问题的一组解开始搜索,而非单个解开始,搜索方向有多个,而非单个。较传统的单点、单方向搜索算法,遗传算法具有良好的并行性,而且搜索的覆盖面大,减少了陷入局部最优的风险,利于全局择优。因此,将遗传算法的思想应用于聚焦爬虫的搜索策略中吸引了不少国内外学者。文献[3]设计的客户端智能搜索引擎,在搜索过程中就利用了遗传算法的变异操作,将相关度高的网页作为新个体加入下一代群体,在一定程度上扩大了网页的搜索范围。文献[4]通过改进遗传算子提出的一种新的主题爬虫搜索策略,在合理选择种子集合时,不仅能扩大搜索范围,而且在抓取的网页中主题相关的网页数量多。文献[5]提出的一种结合内容评价和链接结构搜索策略的优点并利用小生境遗传算法进行全局寻优的搜索策略。通过改进遗传算子和小生境遗传算法,采用概率变迁规则和小生境淘汰运算引导搜索方向,在抓取主题相关网页时具有更高的查准率和查全率。以上搜索策略的特点及不足如表1所示。

表1
从上面的分析来看,在聚焦爬虫的搜索过程中引入遗传算法,利用它简单、高效、并行和全局寻优的特点,指导聚焦爬虫的搜索方向。将待搜索网页的URL作为遗传个体,通过交叉、变异、选择操作,采用概率的变迁规则,用适应度函数值来评估个体,然后将其作为新个体加入种群中,进入下一代遗传进化。采用的自适应遗传算法,通过Pc和Pm的自适应调整,对遗传算子进行了新的定义,具有更好的自适应性。
3 基于自适应遗传算法的聚焦爬虫方案设计
3.1 基于自适应遗传算法的聚焦爬虫设计思想
目前网络上的信息一般按照某个主题归为一类,这样,如一网页信息与某一主题相关,那么它所在的网站或者链接的网站也可能包含与该主题相关的信息。结合网页内容评价、Web链接结构以及自适应遗传算法的优点,设计出一种在保持种群多样性的同时通过自动调整Pc和Pm来保证遗传算法收敛性的聚焦爬虫。其基本思想是:通过自适应选择操作,选出适应度高的个体(URL)作为下一代种子,减少新种子的数量,缩小搜索范围;通过对优势个体采用较小的变异概率,对劣势个体采用较大的变异概率这样的变异操作来保证有足够新个体结构的同时遗传算法不变成随机搜索算法;通过在进化的不同时期采用不同的交叉概率对父代个体进行基因重组,来保证新个体产生的同时不破坏遗传算法的遗传模式。基于自适应遗传算法的聚焦爬虫以普通聚焦爬虫作为原型,在爬虫的搜索策略中运用自适应遗传算法,更好的指导爬虫的搜索路径。该爬虫设计的流程如图1所示。
3.2 主题相关度的判断
聚焦爬虫在其爬取网页的过程中需要根据一定的网页分析算法过滤掉与主题无关的链接,为了确定一个网页是否与主题相关,需要计算所查网页与搜索请求的相关度。采用概率检索模型[6]通过计算文档与查询相关的概率来表示网页的相关度。设有3个随机变量R、Q、D,相关度R,记我们估计特定文档D与查询Q相关的可能性为P(R|Q,D);查询 Q,它包含 s个词项(q1,q2,…,qs),其中 qi表示第i个查询词项;文档D,它包含 t个词项(w1,w2,…,wt),其中 wj表示第j个词项导致文档相关的估计概率,可以理解为它对估计整篇文档相关所作的“贡献”。在实际操作中假定词项在相关文档中的分布是相互独立的并且在非相关文档中的分布也是相互独立的,而相关的可能性是基于文档中出现的查询词项和未出现的查询词项。那么,每个词项的权重为:

图1 基于自适应遗传算法的聚焦爬虫流程图

在查询词项的权重计算中,通常还会考虑词项在文档中出现的频率,即词频 tf,词项在查询中出现的频率qtf,以及文档的长度dl等信息对相关度的影响[7]。最后采用泊松模型对文档相关度进行计算,计算公式为:

式中,N为文档集中文档的数量;n为文档集中包含词项t的文档数目;R为对于查询Q相关的文档数量;r为包含词项t的相关文档数目;tfij为文档i中词j的词频;qtfj为查询Q中词j的词频;dli为文档i中词的数量;|Q|为查询中词的数量;Δ为平均文档长度;k1,k2,k3,K为调节参数。
3.3 适应度函数的计算
种群中适应度函数的选取将直接决定优于种群平均适应度的个体和数目。在算法运行的初级阶段,群体中可能会出现一些适应度高的个体,随着遗传代数的增加,这些适应度高的个体及后代将成为群体中的大部分。这样,使得群体中的新个体减少,种群的多样性降低,遗传算法提前收敛到某个局部最优解,导致“早熟”现象。考虑网页的内容和链接结构两方面,在自适应遗传算法中选用网页及其父网页的相关度值来作为个体的适应度函数值。则个体适应度函数计算公式为:
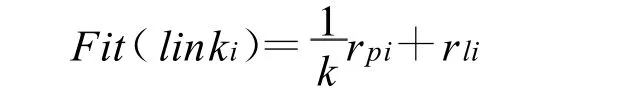
其中Fit(linki)是第i个URL对应的适应度值;rpi是linki对应的父网页的相关度值;rli是第i个URL对应相关度值;k是linki对应的父网页链接出的网页个数。
3.4 初始种子的选取
种子页面的选择将直接影响信息采集的质量以及采集工作的效率,为此,要求种子页面具有较高的主题相关度以及主题链接的中心度[8]。具体做法是:(1)用分类词库里面的主题词作为关键字在百度、谷歌等网站搜索获得可能相关的URL,取各自的Top100URL。(2)从排名网站Alexa、Ranking等获取相应主题的网页,取各自的Top100URL。(3)将通过以上方式获取到的URL汇总,从中选出n个与主题相关的URL作为种子页面。
3.5 遗传算子的设计
遗传算法的参数中交叉概率Pc和变异概率Pm的选择是影响遗传算法行为和性能的关键所在,直接影响算法的收敛性[9]。传统遗传算法的交叉概率和选择概率的参数是事先确定的,而这两个参数的选择对于优势个体的产生影响较大。因此,选择不当,容易出现局部最优解,产生“早熟”现象。自适应遗传算法中的Pc和Pm是随适应度值动态改变的。所以,根据具体的优化问题——聚焦爬虫的路径选择问题,重新设计了遗传算子,以便使聚焦爬虫爬取到更多的主题相关度高的网页。
3.5.1 选择算子的设计
选择操作模拟生物的“优胜劣汰”机制。在遗传算法中,以较大的概率将相关度高的URL作为下一代个体的种子页面,继续繁殖,而相关度低的URL则可能面临被淘汰的危险。对于集合S进行以下处理:(1)根据计算出的网页相关度值,选择相关度高于阈值r0的网页,淘汰低于阈值r0的网页;(2)根据网页的适应度值,分别对适应度值高于和低于平均适应度值的网页以不同的 Pc和Pm进行交叉和变异操作。(3)去除交叉、变异后的种群集合S中重复、无效以及已经查找过的URL。
3.5.2 交叉算子的设计
交叉操作在遗传算法中的作用是产生新的个体,以便出现新的基因模式。计算抓取网页的适应度值,按降序排序,对适应度值大于种群平均适应度值的URL以较大的Pc进行交叉操作,而对于适应度值小于种群平均适应度值的URL以较小的Pm进行交叉操作。选出前 n×Pc个URL作为交叉结果得到集合S1∪S2。交叉概率的调整通过以下公式实现:
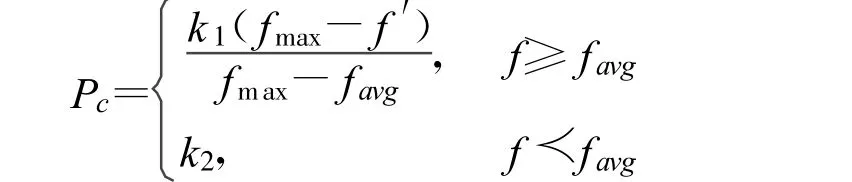
3.5.3 变异算子的设计
选择算子在种群中变化,选择的结果仍在种群中;交叉算子在包含种群的最小模式中变化,交叉的结果仍在这个模式中。因此,选择和交叉仅在一个“子空间”中搜索,而变异操作是在不断改变子空间,从而扩大了搜索范围。因此,在自适应遗传算法中,采用对适应度值大于种群平均适应度值的URL以较小Pm进行变异操作,对适应度值小于种群平均适应度值的URL以较大的Pm进行变异操作。最后选出m×Pm个URL作为变异结果得到集合S3∪S4。变异概率的调整通过以下公式实现:

式中,fmax为群体中最大的适应度值;favg为每代群体的平均适应度值;f′为要交叉的两个个体中较大的适应度值;f为要变异个体的适应度值;k1,k2,k3,k4为调整参数,选(0,1)区间的值。
4 实验设计及数据分析、对比
4.1 实验的设计
为了测试基于自适应遗传算法的聚焦爬虫的性能,将该爬虫爬取主题相关网页的结果与广度优先搜索策略(BFS)和最佳搜索策略(OPS)以及文献[4]的结果比较。试验中,初始种子URL设为30个,相关度阈值设为 r0=0.02。以“赌博”为主题,分别在谷歌和百度搜索相关网页,记录4种搜索策略抓取的网页。虽然抓取是以“赌博”为主题的,但抓取到的网页是否为赌博网站,并不能肯定,因此,对抓取到的网页用McAfee,Blue coat及Webfilter分类,分类结果以两个分类器相同的为准,3个分类器都不相同的或者未分类的网页人工检查,根据分类结果计算抓取网页的准确率。
4.2 实验结果分析、对比
实验记录了用4种搜索策略在谷歌、百度抓取到的相关网页数量,如图2所示。从图中可以看出,在搜索的开始阶段,AGA抓取到的相关网页数量不及OPS以及文献[4]的GA,但随着算法的推进,AGA抓取到的相关网页明显高于OPS以及BFS,略高于GA。说明自适应遗传算法通过遗传算子的调整,在聚集爬虫爬取网页的过程中具有更大的覆盖率,能够抓取到更多的相关网页,准确率较高。而在抓取到网页的相关度上,对抓取到的网页用分类器分类后,从图3可以看出,BFS和OPS抓取到的网页相关度随着搜索的深入开始降低,而AGA会在持续一段时间后开始降低,说明AGA能够抓取到更多的主题相关度高的网页。

图2 下载总页面数量与相关页面数量的关系

图3 平均相关度与页面数量的关系
5 结束语
爬虫以何种搜索策略对网页进行搜索是聚焦爬虫搜索相关网页数量以及质量的保证。文中采用的自适应遗传算法通过动态调整遗传算子,使聚焦爬虫具有较高的查准率和查全率。但是,按照主题关键字的方式来搜索网页,对于某些主题或者以图片为主的网页,并不能保证很好的结果。因此,结合领域本体对网页内容进行语义分析以此表示网页的相关度,再利用自适应遗传算法对网页进行搜索是下一步工作。
[1]欧阳柳波,李学勇.专业搜索引擎搜索策略综述[J].计算机工程,2004,8(7):32-33.
[2]刘世涛.简析搜索引擎中网络爬虫的搜索策略[J].阜阳师范学院学报,2006,23(9):59-62.
[3]Chengh.Chungym,Ramseym.An intelligent personal spider(agent)for dynamic Internet/Intranet marching[J].Decision Support Systems,1998,23(1):41-58.
[4]刘国靖,康丽,罗长寿.基于遗传箅法的主题爬虫策略[J].计算机应用,2007,27(12):173-174.
[5]曾广朴,范会联.基于遗传算法的聚焦爬虫搜索策略[J].计算机工程,2010,36(6):167-169.
[6]Fuhr,Norbert.Probabilistic models in information retrieval[J].The Computer Journal,1992,35(3):243-255.
[7]Robertson S,Walker S.Some simple effective approximations to the 2-Poisson model for probabilistic weighted retrieval[C].In Proceedings of the Seventeenth Annual International ACM SIGIRConference on Research and Development in Information Retrieval,1994,232-241.
[8]李春旺.Web信息主题采集技术研究[J].图书情报工作,2005,49(4):77-80.
[9]王小平,曹立明.遗传算法:理论、应用与软件实现[M].西安:西安交通大学出版社,2002:73-74.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
计算机仿真(2022年8期)2022-09-28
现代信息科技(2021年21期)2021-05-07
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
郑州大学学报(工学版)(2018年2期)2018-04-13
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
中国塑料(2016年11期)2016-04-16
电子测试(2015年18期)2016-01-14
