
维吾尔语广播新闻敏感词检索系统的研究
2011-06-28 06:36木合塔尔沙地克布合力齐姑丽瓦斯力
中文信息学报 2011年4期
木合塔尔·沙地克,李 晓,布合力齐姑丽·瓦斯力
(1. 中国科学院 新疆理化技术研究所,新疆 乌鲁木齐 830011;2. 中国科学院 研究生院,北京 100084;3. 新疆教育学院 数学与信息技术分院,新疆 乌鲁木齐 830043)
1 引言
截止到2004年,我国广播节目为1 789套,平均每日播出广播节目21 378小时,全天候地为我国13亿人口提供资讯信息和文化娱乐服务[1]。随着广播节目的增多,采用现代化的手段,对大量的广播节目进行快速高效的内容检索已经成为一项重要任务。维吾尔语广播新闻敏感词检索系统的基本原理是根据需要为系统设定若干敏感词,当广播新闻节目语音中出现所设定的敏感词的语音时,系统将把对应的语音段保存在存储设备中,以便进一步处理。不包含敏感词内容的语音段则不予处理。语音关键词识别(Speech Keyword Spotting)是实现维吾尔语敏感词检索的技术核心。
作为语音识别领域的一个重要研究方向,语音关键词识别技术是指从连续语音中检出和识别一组预先定义好的特定词和特定短语。它无需像连续语音识别(Continuous Speech Recognition,CSR)那样对连续语音的整体进行识别,而只需提取出语音段中的关键词信息。跟语音关键词识别相比,目前连续语音识别有资源耗费大,速度慢,抗噪能力不强等缺点,这是连续语音识别短期内难以突破的问题所在。因此在当前技术水平下,许多应用领域不适合连续语音识别,而要求语音关键词识别,这一系统的研究如能取得突破性进展,则将大大有助于拓宽维吾尔语语音识别系统的应用领域,而维吾尔语语音信息检索是一个有很好应用前景的领域。目前,国内外的语音关键词识别系统通常采用连续概率密度的隐马尔可夫模型(CHMM)或半连续的隐马尔可夫模型(SCHMM)作为声学模型。随着研究的逐渐深入和完善,语音关键词识别越来越趋向于借鉴大词汇量连续语音识别(LVCSR)的技术,诸多研究表明,实现语音关键词识别的最好手段就是连续语音识别技术[2]。
2 国内外现状
2.1 广播新闻语音识别的历史与现状
最早的针对广播新闻语音识别的研究开始于1995年[3]。1995年2月21日,美国国家标准技术局(NIST)在华盛顿组织了一次研讨会,商讨下一步DARPA(Defense Advanced Research Projects Agency)资助的连续语音识别评测项目。在这个研讨会上,卡内基梅隆大学的Roni Rosenfeld提出了不同的评测项目,即“Possibly Involving the use of ‘Real’ Transcription of CNN Broadcasts or general Broadcast Audio”。从那时起,语音识别的研究就渐渐地从朗读式语音的识别转移到了现实生活中“真实语音”(比如广播新闻语音或电话语音等)的识别上来。目前,国际上开展广播语音识别研究的单位包括: 卡内基梅隆大学(CMU)、剑桥大学(CU)、LIMSI(Laboratoire d’informatique pour la mécanique et les sciences de l’ingénieur)、IBM的Watson研究中心、SRI、BBN、ICSI(International Computer Science Institute)等。近些年,国内的中国科学院声学研究所、中国科学院自动化研究所、清华大学和北京大学等单位也开始了在这方面的研究工作。
在美国DARPA项目的资助下,从1995年到2003年,NIST先后组织了多次关于广播新闻语音识别的国际评测,这极大地推动了这方面研究的进展。从1995年至2003年间的5次HUB-4评测可以大致看出近些年来在广播新闻语音识别方面研究的发展过程,概括地说,包括以下几个方面的变化:
• 训练数据: 广播新闻语音的声学模型训练数据逐年增加,从几十个小时数据到上百个小时数据,这也带来了识别性能的相应提高,由此可以看出广播新闻语音数据对于这方面的研究的重要性;同时,当前针对汉语广播新闻语音的数据还是偏少,需要国内的研究者在这方面的努力和贡献。
• 技术和方法: 尽管用于广播新闻语音识别的大多数技术和方法与传统的大词汇量连续语音识别相比并没有本质的改变,依然是基于统计模型,但是一些具体的相关技术,比如自动分割、分类和聚类,声学模型自适应等,都针对广播新闻语音的特点进行了深入的研究;同时,也出现了将人工神经网络方法用于广播新闻语音识别中的系统。
• 性能: 随着针对广播新闻语音的声学模型训练数据的增加和相关技术方法的改进,广播新闻语音识别系统的词错误率逐年下降,词错误率从最初的27%下降到2003年的9.9%。
• 任务: 随着广播新闻语音识别研究工作的进展,研究的任务从最初单一的英语识别扩大到了后来的汉语、西班牙语以及阿拉伯语等语言的识别;识别模式从最初的不限时方式扩大到了后来的10倍实时和1倍实时等方式;识别结果也从最初的字错误率评价扩大到了后来的更具“可读性(Readability)”的元数据标注(Rich Transcription)等。
广播新闻语音识别通常包括语音的自动分割、分类和聚类,自动语音识别以及后续的自动标注等处理过程。下面,将简要分析一下语音自动分割、分类和聚类以及自动语音识别方面研究的技术现状。
在语音的自动分割、分类和聚类研究方面: BBN的Byblos系统首先用一个上下文无关(Context-independent, CI)而性别相关(Gender-dependent,GD)的音子解码器,把整个广播新闻语音分成一些小的语音片断,这些片断通过自动聚类算法得到各个不同说话人的语音数据用于下一步的自适应。性别相关而说话人无关(Speaker-independent, SI)的模型通过说话人自适应训练(Speaker Adapted Training, SAT)算法得到说话人相关(Speaker dependent,SD)的模型,用于二遍识别。实验结果表明,通过SAT自适应得到的SD模型的识别准确率比SI模型相对提高了10%。剑桥大学的Woodland等人在HTK中使用了更加复杂的前端预处理算法。首先把语音分成三大类: 宽带语音、窄带语音和音乐。在去掉了音乐后,用一个性别相关的音子识别器来定位静音点和说话人转折点,并通过一系列的平滑处理,得到了语音片断边界。这些语音片断先经过初始的分类后,然后对每个类别分布的均值应用最大似然线性回归(Maximum Likelihood Linear Regression, MLLR)自适应算法,得到的自适应后的模型用于第二遍的处理。卡内基梅隆大学的Sphinx-3系统采用了和剑桥大学的HTK类似的算法。
在自动语音识别研究方面,大多数主流系统采用的还是基于隐马尔可夫模型(HMM)的统计方法。针对于广播新闻语音识别的任务,这些系统有以下的特点: 1) 采用自适应技术来提高声学建模性能;2) 多遍的识别过程。这其中值得一提的一个是SPRACH(Speech Recognition Algorithms for Connectionist Hybrids)系统,该系统基于人工神经网络方法对声学模型进行建模,并用于大词汇量广播语音识别中。该系统是由ICSI、剑桥大学、谢菲尔德大学等单位共同开发的。相比于传统的基于HMM模型的语音识别系统,该系统最大的特点在于其直接利用人工神经网络模型估计公式(1)中定义的后验概率P(W|X),这样一来就可以采用一些更直接的方法进行置信度估计、发音建模和解码搜索等。
2.2 关键词识别研究现状
关键词识别技术的研究开始于20世纪70年代[4]。1973年,Bridle的文章揭开了关键词识别的序幕,但那时只是称“给定词”的识别,Christiansen 等的文章中有了“关键词”的叫法,他利用信号的LPC表示对连续语音中的关键词进行检测和定位,文章称该方法对4 个词和10个数字取得了很好的效果。真正的关键词识别研究是在20世纪80年代。Myers等人利用基于DTW 的局部最小算法对关键词识别和连接词识别进行了研究,但没有系统的实现。美国ITT(国际电话电报公司)国防通讯部的Higgins与Wohlford用模板连接的方法实现了KWS,并提出了填充词(Filler)模板(该模板由词表外词的语音训练而得)的概念,结果表明: 如果词表的显式知识没有那么重要的话,则使用词的填充模型就很重要了。此后AT&T BELL实验室Wilpon等实现了一个基于HMM的5个电话用语的、可以实用的KWS系统,标志着关键词识别研究的崛起。美国BBN系统和技术公司的Rohliced等也研究了非特定人KWS的连续HMM建模问题,同时给出了KWS系统的性能评价基准。到20世纪90年代,MIT的Lincoln实验室、CMU的计算科学学院、Dragon系统办公室以及日本的Toshiba公司等,也相继报告了他们的研究成果。
国内汉语关键词识别起步较晚,这主要是国内在80年代才开始语音识别技术的研究,关键词识别技术的发展离不开语音识别技术。90年代国内在大词汇量汉语关键词识别上的研究才大大兴起,中国科学院、清华大学、北京邮电大学、浙江大学等在这个领域都进行了深入研究,表现突出。由于在这个时期中国经济的发展,世界各国对汉语也越来越重视,很多国外公司在汉语的语音识别和关键词识别上都进行了大量的投入,并取得了较大的进展。
关键词识别系统中,置信度估计的研究在国外近几年来成为了一个热点,所以下面对国外置信度估计的研究方法进行分析和总结。置信度,是识别结果正确概率的一种量度,也可以认为是识别结果的可靠程度。现在大部分的语音识别系统都是基于后验概率P(W|X)进行识别的,即找到能够使P(W|X)最大的词序列:

(2)
根据贝叶斯定理,可以得到:
(3)
一般都假设P(X)是常数,所以P(X)通常被省略,所以根据公式(3)可以将公式(2)改写成:
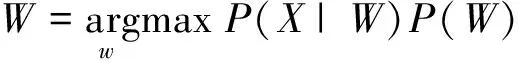
(4)
在实际应用中如果认为P(X)不一定是常数,那么公式(4)与贝叶斯定理得到的公式(2)是有区别的。但是往往P(X)都是很难准确得到的,这时就需要在公式(4)的基础上,进行各种各样的校正,使利用公式(4)得到的结果与利用公式(2)得到的结果尽可能一致。这样就引出了置信度定义的必要性。但如果进一步考虑,公式(2)所得到结果的可靠程度又是多少呢,这就引出了各种各样一般意义的置信度的估计方法。
近年来,国内的研究人员在关键词识别领域取得了一定的进展。其中,郑方提出了一个基于音节模型的汉语无限制语音流的关键词识别系统,利用分布的临界区域内落入的特征向量百分比进行拒识判别。张国亮在实现的关键词识别系统中提出了关键词的动态确认策略和上下文相关的语音确认方法。陈一宁实现了一个基于音节格的关键词检测系统,采用了帧归一化的后验概率模型作为置信度。严斌峰提出了主题指导的关键词检出策略,并采用了LPC 二次识别置信特征和联合得分的识别确认方法[5]。
2.3 维吾尔语语音识别的历史与现状
连续语音识别的研究虽然在汉语、英语等语料资源丰富的语言上发展很快,但是由于缺乏专业人才及完备的语料资源,目前维吾尔语这方面的研究工作刚刚起步。另外,由于维吾尔语有其本身的特点,不能简单地套用现有的连续语音识别的方法。近年来,有不少的维吾尔语识别研究,利用通用的语音识别软件HTK,采取与其他语言同样的方式尝试了语音识别。因为经济及技术等条件,准备的语料库一般不像其他语言那样规模庞大(英语语言一般用70~500小时的语音语料库来训练声学模型,7~10年的报刊杂志等文本语料库来训练语言模型)。虽然目前获得第一手语料较容易,但语料的手工标注等方面花钱费时困难大。因此,如何有效地利用有限的、容量最小的语料库,并保持较高的识别率,已经成为目前一个重要的研究工作[6]。
维吾尔语语音识别研究工作开始于20世纪90年代初。1990年8月至1994年6月期间,吾守尔·斯拉木在承担国家863计划智能机主体研究项目——维汉声、图、文一体化办公自动化系统中,采用独特的音节训练词识别方法和词汇扩充方法、语音信号的自适应自学习VQ方法、语音信号的分割和状态段分布HMM模型等技术,研制出1 200个识别音节、4万个识别词汇的联想式特定人维吾尔语音识别系统,其识别率达到95%[7]。2005年专门成立多语种语音信息处理研究室,开展了维吾尔语语音识别、语音合成的研发工作。
新疆大学、中国科学院新疆理化技术研究所、新疆师范大学等高校和科研机构,先后进行了很多维吾尔语语音识别与合成方面的技术研究,积累了一定的经验。然而,这些研究都是在高质量的实验条件下,采用标准发音的、仔细朗读的语音进行的。但是要真正完成一个能够处理自然语言识别系统,就现有的技术水平来说还是非常困难的。
3 系统的设计与实现
3.1 系统功能设计
敏感词检索系统由两个部分组成,即敏感词检出和语音确认(敏感词确认)。在敏感词检出过程中,训练得到的敏感词和Filler的模型作为参考模板,语音信号经过预处理和特征提取之后,通过帧同步Viterbi搜索算法与参考模板相比较,生成中间结果,即N-Best列表、词图或网格的假想命中。
在敏感词检索系统中,对识别中间结果的确认(也称拒识)是非常重要的,系统在识别阶段为了保证有比较高的正识率,常常给出尽可能多的候选,以便把正确的候选包含进来。所以,确认必须使用有效的方法,拒识那些错误的候选,以降低系统的误识率,同时也要保证正识率不受影响。
当广播新闻语音中包含有敏感词时,必须使它的分数得到提高,来增加它被检出的机会;反之当语音中不包含敏感词,使其分数受到抑制,来增加它被拒绝的机会。利用置信度可以对识别结果的可靠性进行假设检验,定位识别结果中的错误所在,提高系统的识别率和稳健性。图1为本系统所设计的敏感词检索系统的示意性结构图。语音输入后经过语音处理模块(包含敏感词检出部分)得到中间结果。这个中间结果可能是词网格,N-Best列表,或是其他方式的敏感词的假想命中。二次处理(即语音确认部分)对中间结果,利用各种各样的知识源和分类的方法进行置信度评估,最后输出敏感词的最终假设。总之,可以概括成两个部分: 识别部分和确认部分。
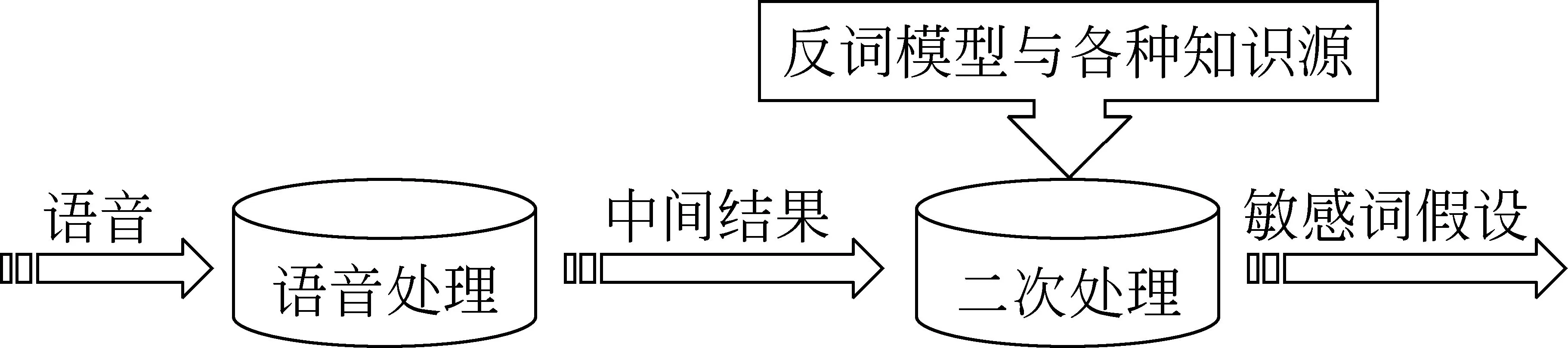
图1 关键词检出系统的示意性结构
3.1.1 语音处理模块
语音处理模块由如下四个子模块构成(如图2): 语音前端处理、语音特征提取、声学模型接口、敏感词检出解码器。
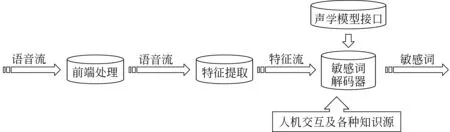
图2 语音处理模块结构示意图
其中,语音前端处理主要是利用语音信号时域或频域的自身特点和规律,对语音进行预处理。这些预处理有: 语音和非语音分离,降低噪音,性别判定或是其他辅助的处理,目的是为了提高识别的速度和正确率。本系统拟采取: 8KHz采样,16bit量化,帧长25ms,帧移10ms。
语音特征提取,是对前端处理过的信号进行一定的计算,得到只反映语音内容的特征。现在使用的特征提取方法主要有两类: MFCC和PLP。但是,这两种特征中实际上不仅仅只包含语音的内容信息,还包含说话人、声调、语气、口音等其他与语音识别关系不大的特征信息。一般情形下,识别中用到的特征提取方法应该和声学模型训练时用的特征提取方法一致,这样就保证了模型训练与解码器使用的特征是一致的。本系统拟采取: 分帧后的语音经过预加重、加汉明窗后提取得到12维MFCC参数。为了消除信道畸变采用倒谱均值减(Cepstrum Mean Subtraction,CMS)的方法;为了对含噪语音进行补偿采用一阶矢量泰勒级数(1st Vector Taylor Series,VTS-1)的方法。26维特征矢量由12维MFCC参数、12维一阶差分MFCC参数、1维归一化能量及1维一阶差分能量组成。
声学模型接口,负责获得特定语音特征在不同声学模型上的似然度。声学模型是离线训练构建的。本系统拟采取: 对扩展的敏感词集合建立HMM模型。使每一个敏感词分别对应一个HMM,模型的状态对应这个敏感词所包含的全部可能的词素。对应于该敏感词的一个观测样本,这些词素会按照一定的顺序出现,这样就形成了HMM中的状态序列,是实际中不可观测的。现实中,可以观测每个敏感词声信号的振幅。
为了建立上述对应关系,需要对该敏感词的一组观测样本进行学习,也就是进行HMM参数估计。学习了每个敏感词的参数后,就可以用于识别。也就是对任意的一组观测样本,找到最大可能产生该样本的模型作为该敏感词的代表。
关键词检出解码器,即搜索算法的实现部分,是语音处理模块的核心部分。负责根据特征流和声学模型给出最佳的识别结果。常用的搜索结构主要有两种。一种是基于Filler的搜索系统结构;另一种是基于无Filler的搜索系统结构。本系统拟采取基于Filler的搜索结构(如图3)。
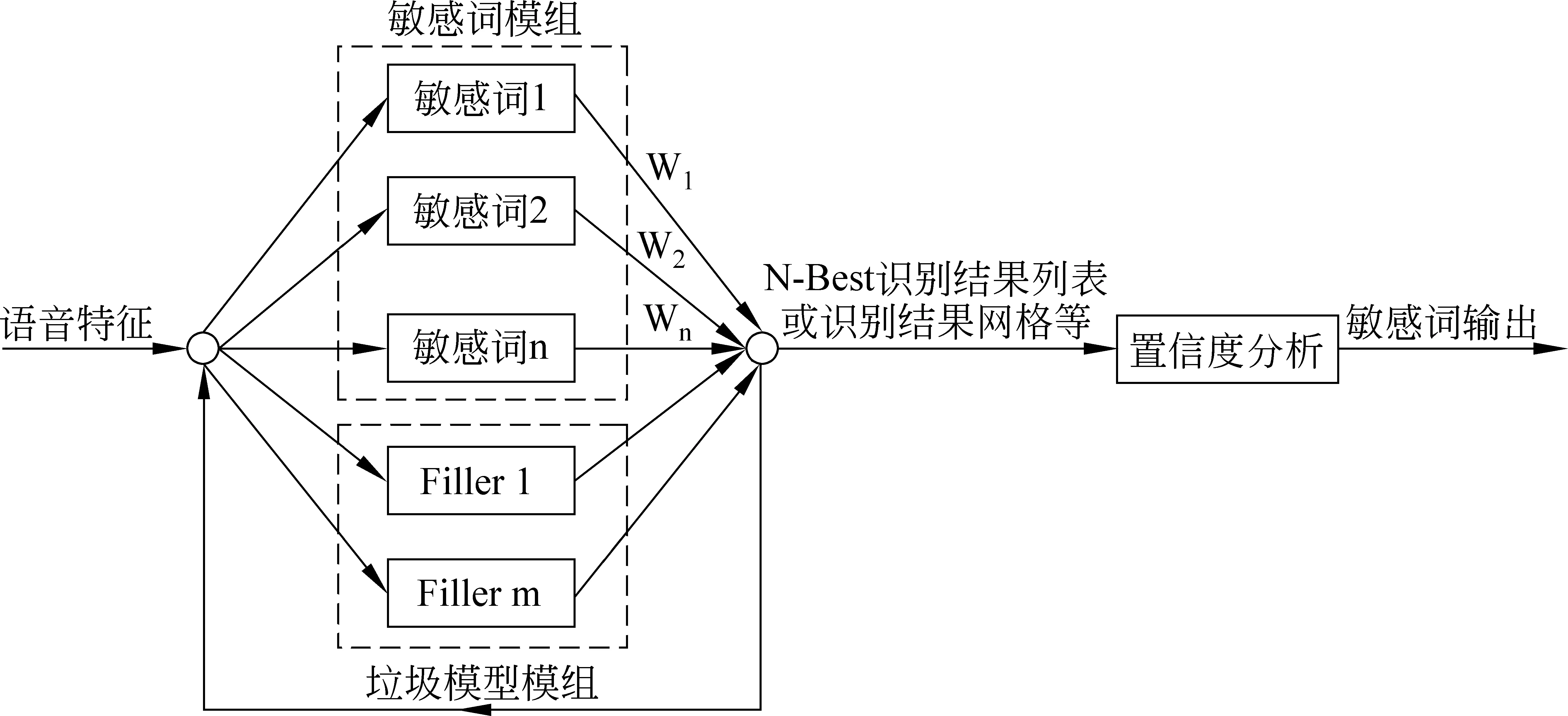
图3 基于Filler模型的搜索网络结构
基于Filler的搜索结构,搜索过程大致分成了两个部分。第一部分从本质上来说是一个连续语音的搜索。搜索的输入是语音特征,搜索的词表是所有敏感词加上所有Filler。搜索过程实际是对所有敏感词和Filler进行连续语音识别的过程。第二部分实际上是对第一部分搜索结果的一个确认过程。根据各种知识源计算所得中间结果的置信度,最终根据计算得到的置信度,对中间结果识别出的敏感词做出接受或拒绝的判断。基于Filler 的搜索结构,敏感词的搜索网络是提前生成的,识别耗费资源较少,易于在桌面和嵌入式应用中的优化处理。
基于无Filler的搜索结构,搜索过程大致分成了三个部分。第一部分是对语音基元的搜索。所谓语音基元就是搜索过程中得到结果的基本单位。在维吾尔语音中,一个词素由一至多个音节组成,一个音节由一至四个音素(一个元音和零至三个辅音,如: V, VC, CV, CVC, VCC, CVCC)组成。敏感词识别中,词素是一个很明显的标准语音基元。通过对输入语音中所有词素的连续解码,可以得到一个N-Best词素序列的列表。第二部分是根据敏感词表和上一步得到的词素序列列表,进行敏感词的搜索。这时由于纯声学搜索难免会出现大量的插入、删除和替代错误,所以需要定制专门的算法进行处理,然后得到敏感词的候选结果。第三部分是根据敏感词候选结果和其他知识源,对结果进行置信度分析,给出敏感词的最终识别结果。基于无Filler的搜索结构,往往是先将语音通过连续词素识别器后,得到词素的识别结果,然后再对这个结果利用敏感词词表进行处理。
3.1.2 二次处理模块
敏感词检出模块输出的中间结果在识别准确性上往往不能满足用户的需求。一方面,敏感词检出模块无法用大量模型精确描述所有语音,从而使误识的发生概率增大;另一方面,误识(特别是误警)带来的对语音的错误理解对系统的友好程度破坏很大,因此敏感词系统又希望把误警率降到尽可能低的程度。语音确认就是在误识存在的前提下仍然使系统尽量保证正常工作的一种手段。
本系统在帧同步Viterbi搜索算法的基础上,拟采取一种基于敏感词假设二次识别的置信度策略,对检出模块的中间结果进行语音确认。
Q={qt},(t=1,2,…,T)
其中,qt∈{{q11,q12,…,q1s1},{q21,q22,…,q2s2},…,{qv1,qv2,…,qvsv}}
s1,s2,…,sv分别为模型W1,W2,…,Wv的状态数。不妨设其中W1,W2,…,Wk为敏感词模型。如果搜索结果中有关键词模型出现,根据{qt}可以给出搜索结果中关键词起止位置tks和tke的假设。
对于O′={otks,…,otke},计算其对Wk的孤立词模型的匹配分类。其中Wk是用关键词的孤立词语料专门训练的孤立词模型,这样可以消除Viterbi模型训练过程中状态匹配不准确带来的模型缺陷。采用针对孤立词模型的Viterbi搜索算法计算O′对Wk的匹配分数,对结果按时间长度进行归一化,并以此结果作为置信度,即
敏感词识别系统中,词分为两类: 词表内的词和词表外的词。词表内的词(In-Vocabulary, INV),是敏感词表内的敏感词;词表外的词(Out-of-Vocabulary,OOV)则是敏感词表以外的词,即非敏感词。系统没有检测出敏感词表中出现的敏感词,这种错误称为漏报(False Rejection, FR);系统检测到的敏感词没有在敏感词表中出现,这种错误称为误警(False Alarm, FA)。
3.2 编程实现
本系统以MATLAB为开发平台,用HMM实现维吾尔语敏感词识别功能,从广播新闻语音文件中检出含有敏感词的语音段。
在此,将通过一个具体的例子来说明独立的敏感词识别过程,具体背景为: 利用HMM识别独立的10个敏感词,每个敏感词都有重复的10次发音。
(1) 信号预处理
将采集的语音信号分成长度为N的块,相邻块起点之间的间隔为ΔN。比如,长度为Ns=10 000的样本,取N=320,ΔN=80,则块的数目为T=1+[(Ns-N)/ ΔN]=122。这样,观测时间可以表示为t={1,2,…,T}。
(2) 特征提取
对观测信号来说,可以有很多不同的特征,包括时域和频域的。在语音识别中,常用的方法是利用线性预测编码(LPC)对语音信号进行特征分析。我们先进行LPC分析,再将LPC系数转化为倒谱系数。记LPC分析的阶次为M,倒谱系数的数目为Q,为了增加动态信息,将Q个倒谱系数的差也作为特征参数,因此特征参数的长度为2×Q。实际应用时,对每一块的语音信号都进行同样的处理,这样可以得到特征向量序列{y1,y2,…,yT}。
特征提取的过程可以用下面的函数实现:
function y=hmmfeatures(s,N,deltaN,M,Q)
Ns=length(s); %信号长度
T=1+fix((Ns-N)/deltaN); %块的数目
a=zeros(Q,1);
gamma=zeros(Q,1);
gamma_w=zeros(Q,T);
win_gamma=1+(Q/2)*sin(pi/Q*(1:Q)′); %计算倒谱的窗函数
for t=1:T
idx=(deltaN*(t-1)+1):(deltaN*(t-1)+N);
sw=s(idx).*hamming(N);
[rs,eta]=xcorr(sw,M,′biased′);
%基于Levinson-Durbin递归的LPC分析
[a(1:M),xi,kappa]=durbin(rs(M+1:2*M+1),M);
%倒谱系数
gamma(1)=a(1);
for i=2:Q
gamma(i)=a(i)+(1:i-1)*(gamma(1:i-1).*a(i-1:-1:1))/i;
end
%加权的倒谱序列
gamma_w(:,t)=gamma.*win_gamma;
end
%倒谱序列的差
delta_gamma_w=gradient(gamma_w);
%特征向量
y=[gamma_w;delta_gamma_w];
(3) 矢量量化
矢量量化是一种重要的信号压缩方法。其过程是: 将语音信号波形的k个样点的每一帧,或有k个参数的每一参数帧,构成k维空间中的一个矢量,然后对矢量进行量化。量化时,将k维无限空间划分为M个区域边界,然后将输入矢量与这些边界进行比较,并被量化为“距离”最小的区域边界的中心矢量值。矢量量化器的设计就是从大量信号样本中训练出好的码书(Code Book),从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量,实现最大可能的平均信噪比。
为了应用离散概率密度型的HMM,需要对上述观测的特征向量进行矢量量化,它的作用是产生一个包含K个可能的观测向量的码本。这样,通过特征提取过程,从每个敏感词的一次发音的信号中可以得到观测序列{y1,y2,…,yT};再通过矢量量化,产生离散的观测序列{y1,y2,…,yT}。其中,每个yt可能取1≤k≤K之间的整数(对应码本中的索引)。可以利用K-均值(K-means)聚类方法进行矢量量化。
矢量量化的过程可以用如下的函数实现:
function [Yc,c,errlog]=kmeans(Y,K,maxiter)
[M,N]=size(Y);
if(K>M)
error(′More centroids than data vectors.′)
end
errlog=zeros(maxiter,1); %每次迭代误差的对数值
%初始聚类中心
perm=randperm(M);
Yc=Y(perm(1:K),:);
d2y=(ones(K,1)*sum((Y.^2)′))′;
for i=1:maxiter
%保留旧聚类中心,以判断是否迭代终止
Yc_old=Yc;
%Y与Yc行之间的Euclidean距离的平方
d2=d2y+ones(M,1)*sum((Yc.^2)′)-2*Y*Yc′;
%分配Y中的每一个向量到最近的中心
[errvals,c]=min(d2′);
%调整聚类中心
for k=1:K
if (sum(c==k)>0)
Yc(k,:)=sum(Y(c==k,:))/sum(c==k);
end
end
errlog(i)=sum(errvals);
fprintf(1,′...Iteration %4d...Error %11.6f ′,i,errlog(i));
%判断终止条件
if (max(max(abs(Yc-Yc_old)))<10*eps)
errlog=errlog(1:i);
return
end
end
(4) 模型训练
接下来就可以利用这些码本对HMM进行训练,下面以某一敏感词的训练为例进行说明,其他敏感词的训练类似。
其实现的MATLAB程序代码如下:
clear all;
%读取某一敏感词的语音信号
load ti46
data=ti46.case(27:36);
L=length(data);
%信号预处理参数
N=320;
deltaN=80;
M=12;
Q=12;
%矢量量化参数
K=10;
maxiter=500;
%HMM模型初始化参数
%状态数
states=5;
%HMM模型训练
estA=zeros(5,5,L);
estB=zeros(5,10,L);
%提取特征
for i=1:L
%初始状态转移概率矩阵
A0=rand(states,states);
A0=A0./repmat(sum(A0),states,1);
B0=rand(K,states);
B0=(B0./repmat(sum(B0),K,1))′;
for j=1:l
xdata=load(data{l}{i});
%特征提取
y=hmmfeatures(xdata,N,deltaN,M,Q);
%矢量量化
[yc,c,errlog]=kmeans(y,K,maxiter);
%训练: 隐马尔可夫模型参数的极大似然估计
[A0,B0]=hmmtrain(c,A0,B0);
end
estA(:,:,i)=A0;
estB(:,:,i)=B0;
end
(5) 语音识别
训练完以后,就可以利用这些HMM对给定的语音信号进行识别。
for i=1:10
%计算给定观测序列的概率
[pStats,logp]=hmmdecode(c,estA(:,:,i),estB(:,:,i));
p(i)=logp;
end
%概率大小
p
概率最大的HMM模型对应的敏感词就是识别的结果。
4 结束语
研发本系统有以下三个有利条件: (1)由于维吾尔语敏感词数量不多,本系统语音语料库容量很小。(2)由于广播新闻中的发音较为标准规范,在识别中避免了说话人发音上的不规范,这有利于语音识别系统性能的提高。(3)由于选择词素为识别基元,易于识别基元端点检测。
但是,维吾尔语属于阿尔泰语系突厥语族,是黏着性语言,同一词干利用丰富的词缀可产生超大词汇。维吾尔语发音时有若干音素拼接而成,在元音和谐、辅音结合等方面有自己独特的规律。这会对识别基元端点检测带来一定的难题。
[1] 崔朝阳,王建纲.广播电视语音识别现状与应用策略[J].计算机工程与应用,2007,43(23):181-183.
[2] 林茜,欧建林,蔡骏. 基于Microsoft Speech SDK的语音关键词检出系统的设计和实现[J].心智与计算, 2007,1(4):433-441.
[3] 黄松芳.广播新闻语音的自动标注和检索[D].北京大学:信息科学技术学院智能科学系,2005.
[4] 蒋鑫.基于Julian的语音关键词识别系统[DB/OL].[2009.2.13].中国科技论文在线.
[5] 刘建.可定制关键词识别系统的研究与实现[D].清华大学:计算机科学与技术系,2004.
[6] 伊·达瓦,匂坂芳典,中村哲.语料资源缺乏的连续语音识别方法的研究[J].自动化学报,2010,36(4):550-557.
[7] 那斯尔江·吐尔逊,吾守尔·斯拉木.基于隐马尔可夫模型的维吾尔语连续语音识别系统[J].计算机应用,2009,29(7):2009-2011.
[8] Muhetaer Shadike,LI Xiao,Buheliqiguli Wasili:Large Vocabulary Continuous Speech Recognition:Basic research of Trigram Language Model[C]//Yang Li.ICMCE (2010).Chengdu: IEEE Press.2010:753-757.
[9] Muhetaer Shadike,LI Xiao,Buheliqiguli Wasili:Large Vocabulary Continuous Speech Recognition:Basic research of Acoustic Model[C]//CSIE 2011.Changchun.IEEE Press.2011.
[10] Muhetaer Shadike,LI Xiao,Buheliqiguli Wasili:Large Vocabulary Continuous Speech Recognition:Basic research of Front-end Processor[C]//NCIS’11.Guilin.IEEE Press.2011.
[11] Muhetaer Shadike,LI Xiao,Buheliqiguli Wasili:Large Vocabulary Continuous Speech Recognition:Basic research of Decoder[C]//ISNN2011.Guilin.Springer’s LNCS Press.2011: 594-600.
[12] 张德丰,许华兴,王旭宝,等.MATLAB概率与数理统计分析[M].北京:机械工业出版社,2010:319-332.
[13] 武健,郑方,吴文虎,方棣棠.基于音调的特征提取在非特定人语音识别中的运用[C]//NCCIIIA:第三届全国计算机智能接口与智能应用学术会议.1997:93-97.
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
机电产品开发与创新(2020年2期)2020-05-07
中国民族博览(2019年10期)2019-11-29
电子制作(2018年10期)2018-08-04
计算机应用(2018年5期)2018-07-25
北京广播电视报(2017年36期)2018-02-28
北京广播电视报(2017年25期)2018-02-23
自动化学报(2017年4期)2017-06-15
语言与翻译(2015年1期)2015-07-18
