
藏文语义本体中的上下位关系模式匹配算法
2011-06-28 06:27邱莉榕赵小兵
中文信息学报 2011年4期
邱莉榕,翁 彧,赵小兵
(1. 中央民族大学 信息工程学院,北京 100081;2. 国家语言资源监测与研究中心 少数民族分中心,北京 100081)
1 前言
藏文显示技术、藏文编码技术以及藏文输入技术得到了较好的解决[1]。藏文信息处理在字处理、词和短语处理方面已经陆续取得了相对突破,句处理阶段的攻关已经开始。在句处理阶段,句法知识、语义知识、语用知识的基础理论研究是亟待解决的关键性问题。
词典中定义的概念本身并没有二义性,它能唯一地、准确地指向现实世界中的实体或对象。但在句处理中,句中的概念是由词表示的。例如概念词“木马”在下面三个句子中至少可以表示三种概念:
(1) 木马是一种玩具。
(2) 木马是一种运动器械。
(3) 木马是一种病毒。
因此所谓概念二义性,就是由于一个概念词可以表示多个概念引起的。而藏语也会因为上下文语境的不同,其汉语有不同译文:
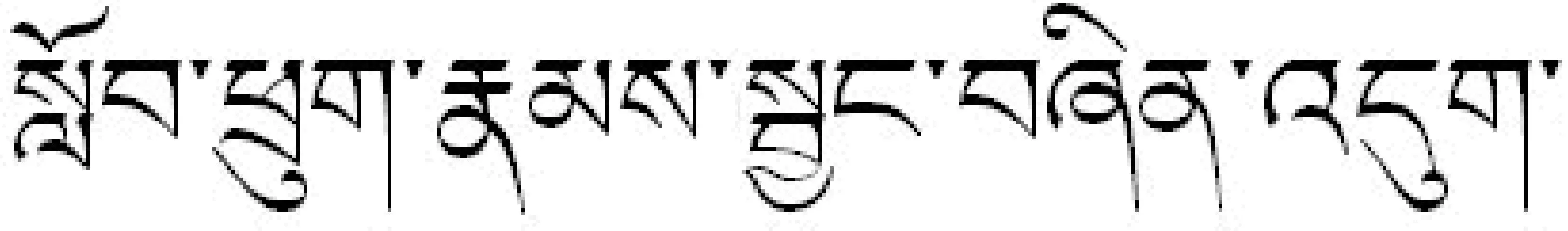
同学们正在学习。

圣人的如释迦牟尼。
语言文字本身存在的语义模糊性和歧义性增加了机器分析的难度。文字(对于计算机而言就是二进制数据)仅仅是传达语义的媒介,而语义的表达才是交流的核心和关键。
对具有某种知识水平的人来说,可以根据句子的语境理解概念要传达的明确语义。例如: 如果“木马”同“计算机”“程序”等词同时在文中出现的话,那么可以根据已有知识,得到此处的“木马”应该指“木马”病毒的可能性最大。
知网(HowNet)的作者董振东先生提出“自然语言处理系统最终需要更强大的知识库的支持”[2]。语义的核心是知识,语义本体就是共享概念模型显示的形式化规范说明[3],用于描述(特定领域的)知识。
我们可以创建计算机领域本体,如果这个领域本体中包含了“木马、计算机、程序”等概念,并定义了这些概念之间的关系,那么计算机在使用这个本体的时候,就相当于有了这些储备知识。
藏语的语义本体的创建研究在以下问题解决上,具有突出意义:
(1) 有助于扩大词典规模: 当前已经手工建立了许多词典用于自然语言处理,但是词典的容量毕竟是有限的,不可能包含所有的词,特别是未登录词。本体中的上下位关系定义了概念和概念之间的层次,基于这种上下位关系,可以获得更多语义新词。
(2) 支持进一步的高层(语义级、知识级)智能应用: 语义本体的最终目标是将杂乱无章的信息源转变为有序易用的知识源,通过语义本体的描述,可以整合浩如烟海且瞬息万变的信息,从中发现、选择和组织有用的信息和知识,传递给需要的人或需要的系统,从而支持进一步的高层(语义级、知识级)智能应用。
(3) 缓解民族语言数据稀疏问题: 虽然藏文是少数民族语言中使用人口较多的语言,但相对于汉语和英语来说,藏文语言资源相对匮乏,特别是带标注文本和双语对齐的文本稀少,这对藏文的信息处理带来不利影响。利用本体中词的语义关系,可以减少数据稀疏的影响,大大提高藏语信息处理精度。
本文首先介绍了藏文语义本体的创建过程,详细描述藏文语义本体创建的各个步骤。然后针对上下位这种基础的语义关系,提出了藏文上下位关系模式,以及基于这种模式的匹配算法。
2 相关工作
20世纪90年代初期,国际计算机界举行了多次关于本体的专题研讨会,本体成为包括知识工程、自然语言处理和知识表示在内的诸多人工智能研究团体的热门课题,其主要原因在于本体使人与人、人与机器、机器与机器之间的交流建立在共识知识的基础上。
目前中英文自然处理领域,已经有很多语义本体的研究成果,其中最突出的是WordNet和HowNet。
英文本体WordNet[4]的词汇包括名词、动词、形容词、副词和功能词。每个词(更确切地说是词的一条意项)是一个网络节点。节点之间通过“同义关系”、“反义关系”、“上位关系”、“下位关系”、“部分—整体关系”、“形态关系”等联系在一起。
中文本体HowNet[5]是揭示概念与概念之间以及概念所具有属性之间的关系为基本内容的常识知识库,从1996年研发至今,已有汉语词项96 744条,多家科研单位研发基于HowNet知识表示的信息处理技术。
在藏语的语义层面的研究中,一些工作对藏语句法行为的规律性进行了研究,有些研究者利用句法和语义信息将词划分成类别,从而更细致全面地反映各种类型藏语句式的语法结构框架,如句子的语序、词格标记和句法助词,并对藏语从句行为进行了分析[6]。多杰卓玛给出了基于框架的藏语词语语义研究[7],通过对框架进行结构信息的描述增加语义信息。龙从军研究了藏语名词语义关系,提出组织名词的基本单位是义类,联系名词与名词、名词与其他词之间的关系是语义关系[8]。
但目前,查新还没有查到藏文语义本体表示层面的藏文处理相关研究内容。基于语义的本体库在文本处理、信息抽取、基于文本的数据挖掘、自动翻译中都有广泛的应用,合适的本体库将成为文本自动处理中的一个重要环节。
3 本体创建过程
语义本体的创建是耗时耗力的艰苦工作,需要语言学家、知识工程师和信息处理人员合作完成。目前的语义本体的创建,有手工创建和自动生成两种策略。完全手工创建的本体一般规模较小,无法应付海量的知识源。自动策略一般采用有监督或无监督的机器学习技术从文本语料中自动获取概念和关系,人工干预程度较低。但自然语言处理的语义表达的复杂性和模糊性,完全的自动处理精度太低,处理结果的可用性很差。况且针对藏语来说,不同于英语和汉语具有大规模的标注语料和现有的语义词典,藏语语义本体建设可用的藏语资源很有限。
基于此,本文采用半自动本体创建策略,第一步,由知识工程师和语言专家手工建立上层本体,利用电子词典进行同义词扩充后,在多语言本体库(汉英语言创建的本体)中根据对应的上下位关系模式进行基于模式匹配的词汇扩充和翻译。第二步,根据本体概念和对应的上下位关系,在已标注语料或电子词典中查找近义词,并基于词汇语义相似度算法进行相似度从高到低的排序。知识工程师对排序结果进行修订,编辑本体。
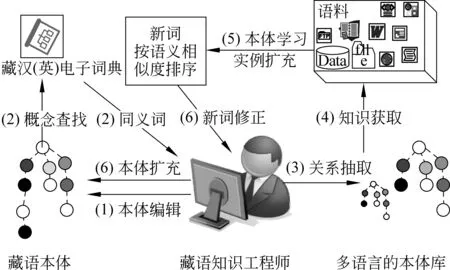
采用半自动本体创建策略,如图所示,分以下步骤展开:
(1) 由知识工程师和语言专家手工编辑建立基于HowNet的上位本体,并研究藏语上下位关系的模式表示方法;
(2) 上位本体中出现的概念,利用电子词典的释义,创建概念的同义词词汇集;
(3) 在多语言本体库(汉英语言创建的本体)中进行概念的上下位关系模式匹配,扩充本体概念层次;
(4) 本体概念和抽取的上下位关系模式匹配,在已标注语料或电子词典中查找近义词;
(5) 基于词汇语义相似度算法进行相似度从高到低的排序[9];
(6) 知识工程师对排序结果进行修订、编辑本体。
在整个本体创建过程中,上下位关系是确定本体中概念分层的语义因素。上下位关系的模式可以辅助进行概念扩充,也可以作为建立和维护本体的辅助工具,这在一定程度上降低了创建和维护本体的成本。
4 上下位模式及匹配算法
首先,我们借鉴刘磊博士的博士学位论文[10],给出上下位关系的定义。
定义1上下位关系, Hyponymy: 如果给定概念C1和C2,C1的同义集合为{C1,C1′, …},C2的同义集合为{C2,C2′, …},若C2的外延包含C1的外延,则认为C1和C2具有上下位关系,其中C1称为C2的下位概念(hyponym),C2称为C1的上位概念(hypernym),记作hr(C1,C2)。判断hr(C1,C2)是否成立的简单方法是看句子: “C1是一种/类/个C2”是否可以接受。
上下位关系模式学习主要包括三个问题:
1) 种子上下位关系的选取;
2) 模式的获取算法——模式自动生成器的构造问题;
3) 获取模式分类和评价。
4.1 上下位模式
(1) 单对单模式: 只提取一个下位概念C1和一个上位概念C2,组成一个上下位关系hr(C1,C2)。如:
【是一种】
{冰箱}C1【是一种】{电器}C2。
hr(冰箱,电器)
(2) 多对单模式: 多对单模式提取多个下位概念C1, C2, …, Cm和一个上位概念 Cm+1,组成一组上下位关系hr(C1, Cm+1), hr(C2, Cm+1), …, hr(Cm, Cm+1)。如:
.、..【等】.
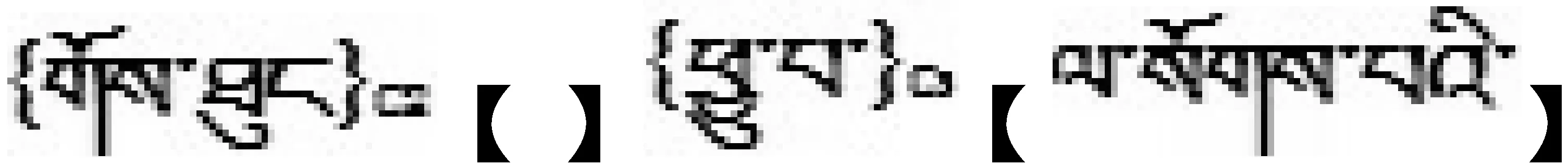
衣柜里面有{上衣}C1、{裤子}C2、{袍子}C3【等】很多{服装 }C4
hr(上衣,服装),hr(裤子,服装),hr(袍子,服装)
(3) 单对多模式: 单对多模式提取一个下位概念C1和多个上位概念C2, C3, …, Cm,组成一组上下位关系hr(C1, C2), hr(C1, C3), …, hr(C1, Cm)。如:
.【即是】..【又是】.
{扎西}C1【即是】{老师的一个好{学生}C2}【又是】妈妈的乖{儿子}C3
hr(扎西,学生),hr(扎西,儿子)
(4) 多对多模式: 多对多模式提取多个下位概念C1, C2, …, Cm和多个上位概念Cm+1, Cm+2, …, Cm+n,组成一组上下位关系hr(C1, Cm+1), hr(C2, Cm+1), …, hr(Cm, Cm+1), …, hr(C1, Cm+2), hr(C2, Cm+2), …, hr(Cm, Cm+2), …, hr(C1, Cm+n), hr(C2, Cm+n), …, hr(Cm, Cm+n)。如:

.<、>..【既是】..【又是】.

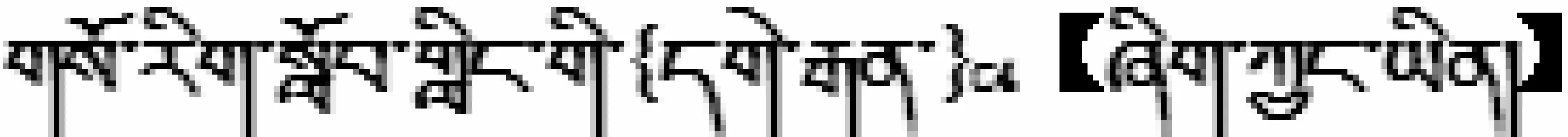
{卓玛}C1、{格桑}C2【既是】校医院的{大夫}C3【又是】医学院的{老师}C4
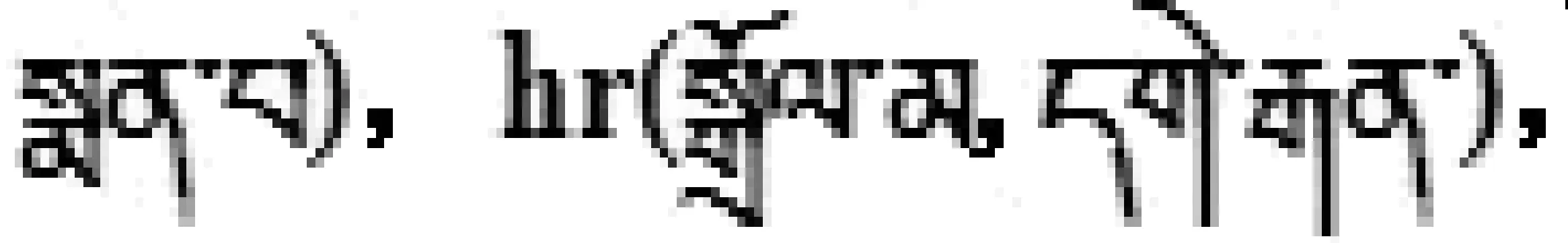
(5) 多层次模式: 多层次模式可以提取一组概念C1, C2, C3。使得hr(C1, C2),hr(C2, C3)多层上下位关系成立,如:
.【是所有】..【中】.
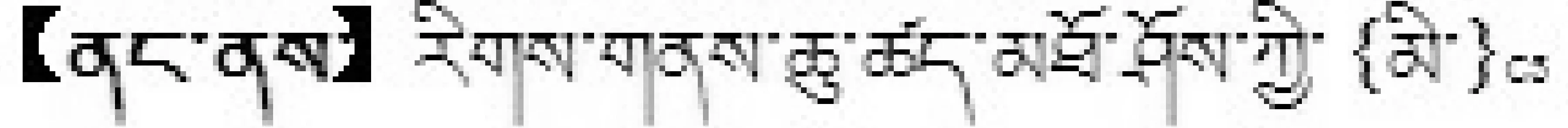
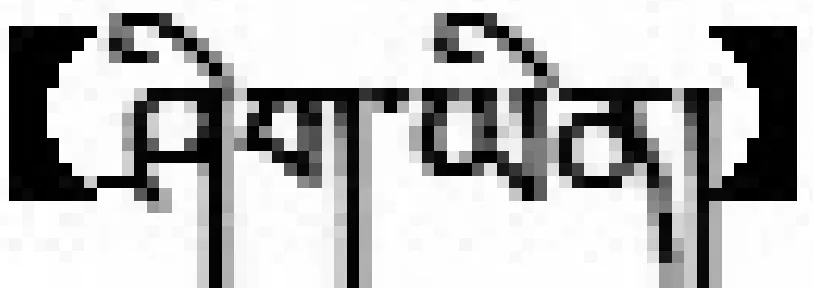
{次央}C1【是所有】{服务员}C2【中】文化程度最高的{人}C3

提取关系: hr(次央, 服务员),hr(服务员, 人)
4.2 模式匹配算法
模式匹配问题可以描述为: 上下位关系模式集合P={p1,p2, …,pm},语料库G,G中含有句子集合S={s1,s2, …,sn},对任意s∈S,若通过模式匹配算法得到p1,p2, …,pk(pi∈P,i=1, 2, …k)与s匹配,记作(s, {p1,p2, …,pk}),若不存在模式与s相匹配,则记作(s, ∅)。
模式匹配算法步骤如下:
上下位关系模式匹配算法
输入: 上下位关系模式集合P,语料库G,
输出: 模式匹配结果
Step 1: 预处理,将语料G分割转换为句子序列S={s1,s2, …,sn};
Step 2: 若S不为空,对每一个句子s∈S,执行Step3-Step5;
Step 3: 对s先进行分词处理;
Step 4: 在P中搜索s所满足的上下位关系模式,得到s所满足上下位关系模式p1,p2, …,pk(pi∈P,i=1, 2, …,k);
Step 5: 根据p1,p2, …,pk中每个模式的上位概念域和下位概念域属性提取对应的上位概念部分和下位概念部分;
Step 6: 输出所有匹配结果。
例句s:
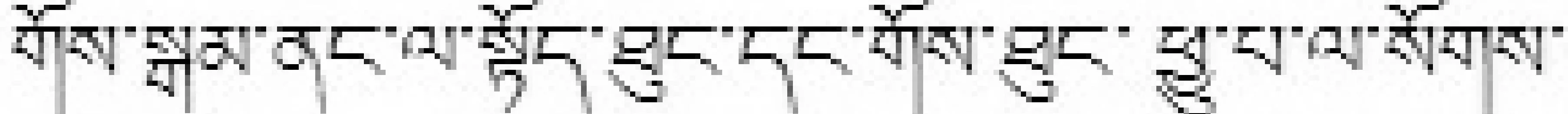

衣柜里面有上衣、裤子、袍子等很多服装。
模式p:
Defpattern 上下位关系模式 //定义一个多对一模式
{
基本模式:
.、..【等】.
下位概念域:
下位变量项: ,和
下位概念个数: 多个,和 单个
下位概念位置: 右,和 右
上位概念域:
上位变量项:
上位概念个数: 单个
上位概念位置: 右
}
模式匹配结果:
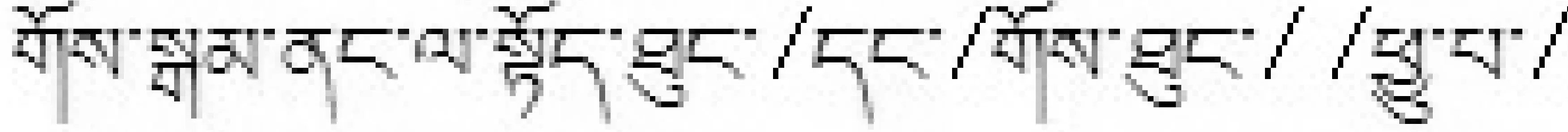
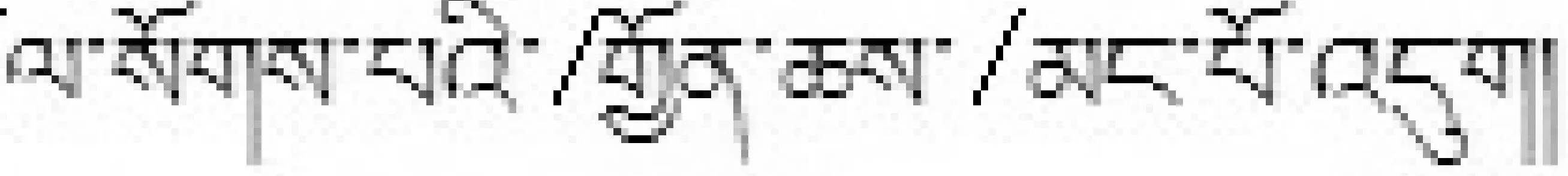
衣柜里面有/上衣/、/裤子/、/袍子/等很多服装。
提取上位概念部分和下位概念部分:
下位概念域 =衣柜里面有上衣、裤子
下位概念域 =袍子
上位概念域 =服装
候选上下位关系:
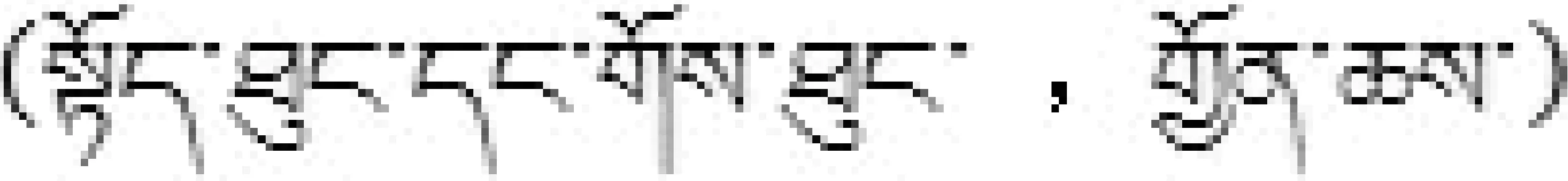
hr(上衣、裤子, 服装)
hr(袍子, 服装)
正确上下位关系:

hr(上衣,服装)
hr(裤子,服装)
hr(袍子,服装)
5 总结
语义本体是共享概念模型的显示的形式化规范说明,其目标是将杂乱无章的信息源转变为有序易用的知识源。目前语义本体还主要依赖于手工创建模式。上下位关系是一种基本的语义关系,常用于语义本体中概念的自动获取和验证。本文首先描述了藏语语义本体的创建方法,进而给出了藏文中的上下位关系模式以及模式匹配算法。
后续的工作包括用于上下位关系验证的概念空间构造方法研究、模式匹配验证算法、基于概念空间的上下位关系迭代概念学习算法等。
[1] 江荻,龙从军.藏文字符研究—字母、读音、编码、排序、图形、拉丁字母转写规则研究[M].北京: 社会科学文献出版社.2010.
[2] 董振东,董强,郝长伶.知网的理论发现[J].中文信息学报,2007,21(4): 3-9.
[3] R. Studer, V. R. Benjamins, and D. Fensel. Knowledge engineering: Principles and methods[J]. Data and Knowledge Engineering, 1998,25(1-2):161-197.
[4] WordNet[OL],http://wordnet.princeton.edu/wordnet/.
[5] HowNet[OL], http://www.keenage.com/.
[6] 江荻.现代藏语动词的句法语义分类及相关语法句式[J].中文信息学报,2006,20(1): 37-43.
[7] 龙从军,周学文.藏语名词语义关系研究. http://d.g.wanfangdata.com.cn/Conference_7143464.aspx.
[8] 多杰卓玛.藏语语义框架的理解与描述[J].西北民族大学学报,2009,30(74): 17-21.
[9] 刘群, 李素建. 基于《知网》的词汇语义相似度计算[C]//第三届汉语词汇语义学研讨会,中国台北, 2002.
[10] 刘磊,概念和上下位关系的获取理论和方法研究[D].中科院计算所博士论文,2007.
猜你喜欢
客联(2022年2期)2022-04-29
西藏研究(2021年1期)2021-06-09
布达拉(2020年3期)2020-04-13
电子制作(2019年13期)2020-01-14
西夏学(2019年1期)2019-02-10
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
西藏研究(2017年3期)2017-09-05
西藏大学学报(自然科学版)(2016年1期)2016-11-15
西藏研究(2016年5期)2016-06-15
