
基于栏目的藏文网页文本自动分类方法
2011-06-28 06:27胥桂仙向春丞赵小兵杨国胜
中文信息学报 2011年4期
胥桂仙,向春丞,翁 彧,赵小兵,杨国胜
(1. 中央民族大学 信息工程学院,北京 100081; 2. 国家语言资源监测与研究中心 少数民族语言分中心,北京 100081)
1 引 言
在一个多民族的国度,保护少数民族文化遗产是我们每个人的责任。自上世纪80年代开始,藏文走入了信息化时代。20多年来,我国的民族语言文字及现代科技工作者在藏文计算机信息处理方面做了大量的工作。才让加等人对藏文语料进行分词标注[1]并利用词性特征建立分类语料库[2],贾会强等人提出了基于规则的藏文文本分类方法[3]。藏文网页文本分类不仅对于帮助人们快速、准确获取所需信息及构建藏文语料库具有积极的意义,而且对于推动和发展藏文信息检索技术,保护少数民族语言文化也有重要作用。
文本分类的技术有很多。文献[4]中设计了一种基于统计与基于规则相结合的混合分类器系统,它需要一定规模的高质量语料库作为训练集。文献[5]提出了一种基于统计的二元分词文本分类方法,文献[6]中利用粗糙集优越的约简理论对文本进行了分类,它们都需要借助分词器对文本进行分词。由于藏文训练语料的收集需要大量人力、物力、财力,短期内不能完成,所以无法采用基于统计的文本分类算法,如:K近邻法(KNN)、决策树、支持向量机(SVM)[7]等经典分类方法。同时,基于规则的文本分类方法需要建设科学的、全面的藏文主题词表,其工作量大,分类时人工干预的成分多。
为此,本文提出了一种简单、快速且准确率理想的藏文网页文本分类方法,该方法不需要事先对抽取的藏文网页文本进行分词等复杂操作,而是结合现有的网页文本提取技术,利用正则表达式提取网页日期、网页栏目,并建立基于网页栏目词条的类别特征词表来对藏文网页文本进行分类。
2 分类方法的实现过程
2.1 建立藏文类别特征词表
我们构建了人文与社会科学类、自然科学类两个大类,前者包括政治类、法律类、历史类、社会类、经济类、艺术类、文学类、军事类、体育类、生活类、宗教类、文化宣传类12个类别,后者包括数理类、生化类、环境类、农林类、医药卫生类5个类别。类别命名参照了《国务院公文主题词表》的第一层主题词,类别的特征词则来源于待分类网站的网页栏目词条。由于一个网站符合要求的栏目词条是有限的,因此可以快速、准确地采集类别特征词,建立类别特征词表。例如有译成中文后的藏文栏目词组:“首页—>专栏—>格尔萨传”,那么仅可将词条“格尔萨传”加入预定义的“文学类”一类中。
为了实现类别特征词表能被快速顺序查找和动态扩充的功能,我们采用链表数组的方式来存储类别特征词表。定义用Tn来表示类别名称,其中n表示类别个数;tk表示其中的特征词,其中k表示该类别中的第几个特征词。那么类别特征词表的存储结构如图1所示。
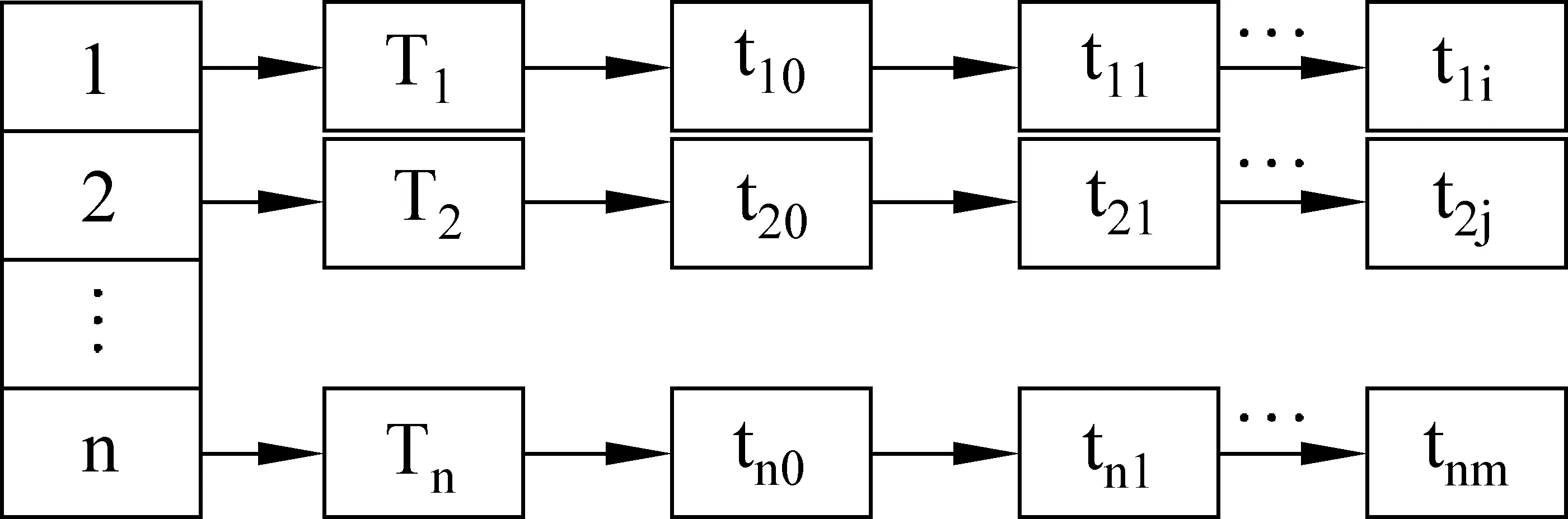
图1 类别特征词表存储结构图
类别T1及其特征词用一个链表来存储,该类别扩充的特征词加入链尾;n个类别链表由一个大小为n的数组管理。这样建立和存储的类别特征词表,可以保证随机顺序匹配速度快,特征词可以动态扩充,其个数及长度不限。
2.2 网页预处理
2.2.1 提取藏文网页正文发表日期
提取藏文网页正文发表日期以对该网页文本命名,对后期分类语料的使用和处理很有意义,如我们可能会要求按类别和时间对藏文文本语料库进行检索。
藏文网页文件的日期通常有如下两种格式:
(1)
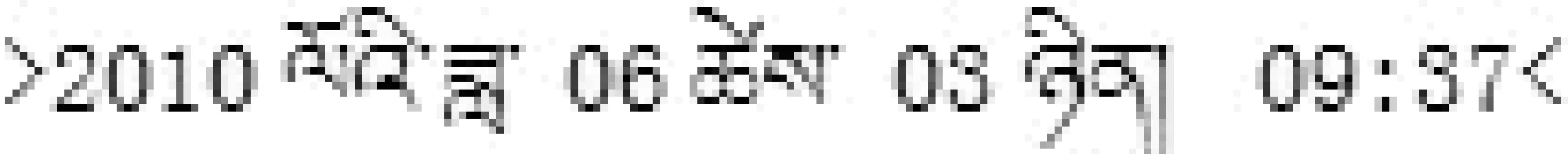
(2)
当然,某些网站的网页日期信息不在
(1)
(2) \d{4}(.{10,13})\d{2}(.{5,8})\d{2}
上述提取日期的正则表达式可合并为:(\d{4}-\d{2}-\d{2})|(\d{4}(.{10,13}) \d{2}(.{5,8})\d{2})
2.2.2 提取藏文网页文本内容
藏文网页主题内容的抽取可以借鉴国内外研究较多的一些方法,如基于混合特征的网页主题提取方法[8],依靠统计信息抽取网页正文[9], 利用HTML与文本的密度比进行文本识别与抽取[10],利用DOM树进行Web信息抽取等技术。本文利用了网页分块的信息提取方法[11],并结合正则表达式来抽取藏文网页文本内容。
2.2.3 提取网页栏目信息
对于含有栏目信息的藏文网页,系统采用正则表达式提取,下面以中国藏族网通网站为例,如有网页文档片段:
用于提取栏目信息的正则表达式为:
(1) “”;
(2) “>(\W+)<”;
2.3 基于栏目的网页文本分类
在提取时网页时间、网页正文文本及网页栏目后,我们将网页栏目按链接级数拆分为多级词条。基于栏目的网页分类算法流程图如图2所示。
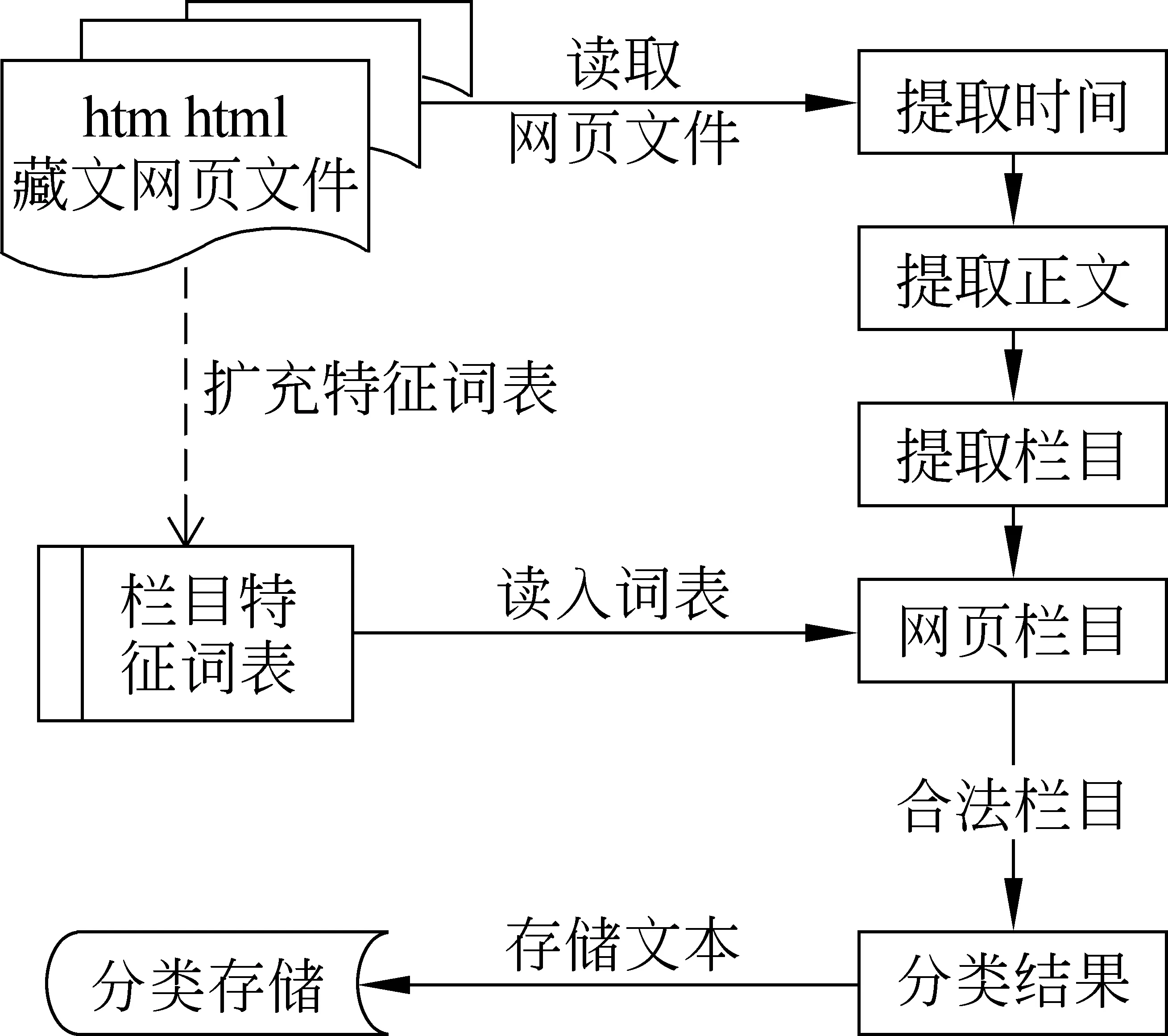
图2 藏文网页文本分类流程图
获取文本类别算法程序描述如下:
//将用“>>”连接的网页栏目词组进行拆分
eachColumn = fileColumn.split(">>");
//计算栏目词条个数
columnLength = eachColumn.length();
//对词条进行分级匹配
for i=0 to columnLength
//调用词条在类别词表中的匹配函数
resultCategory = match(eachColumn[i]);
if resultCategory == null
then
继续匹配;
else 返回类别名称;
我们将丢弃不能提取出日期、正文及栏目的网页,并对能提取这些信息的网页分为“栏目合法网页”和“栏目非法网页”两类。其中前者定义为:栏目词组中至少含有一个具有类别特征的词条的网页。栏目非法网页即栏目不能给出类别信息。例如下面给出了一个“栏目非法网页”的栏目词组:
首页 >>新闻 >>藏区新闻 >>西藏
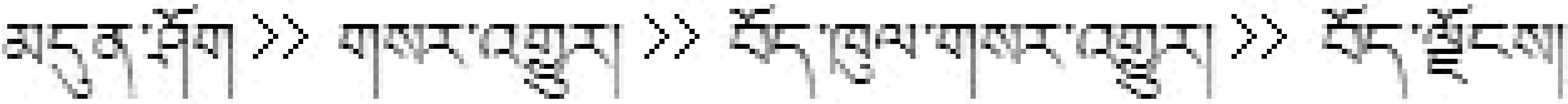
类似这类栏目中不含具有类别特征的词条,我们同样作丢弃处理。
3 实验结果及分析
基于栏目的藏文网页分类工具如图3所示。
图3 基于栏目的藏文网页分类工具截图
为了验证该分类方法的有效性,我们采集了2010年的中国藏族网通的绝大部分网页文件,文件格式为.htm,共1 842篇,作为该分类方法的实验语料。
实验结果统计如表1所示。(注:网页数量为0的类别未给出)
分类结果统计表显示该方法能成功分类1 842篇网页文件中的623篇,绝大多数未能分类的藏文网页均为“栏目非法网页”。对于分类结果的准确率统计,我们采取了随机采样的统计方法,即在各实验结果类别中随机抽取一定百分比的文本进行人工验证。统计结果表明,本文提出的藏文网页文本分类方法能将“栏目合法网页”完全正确地归于预定义类别中,分类准确率可达97%。
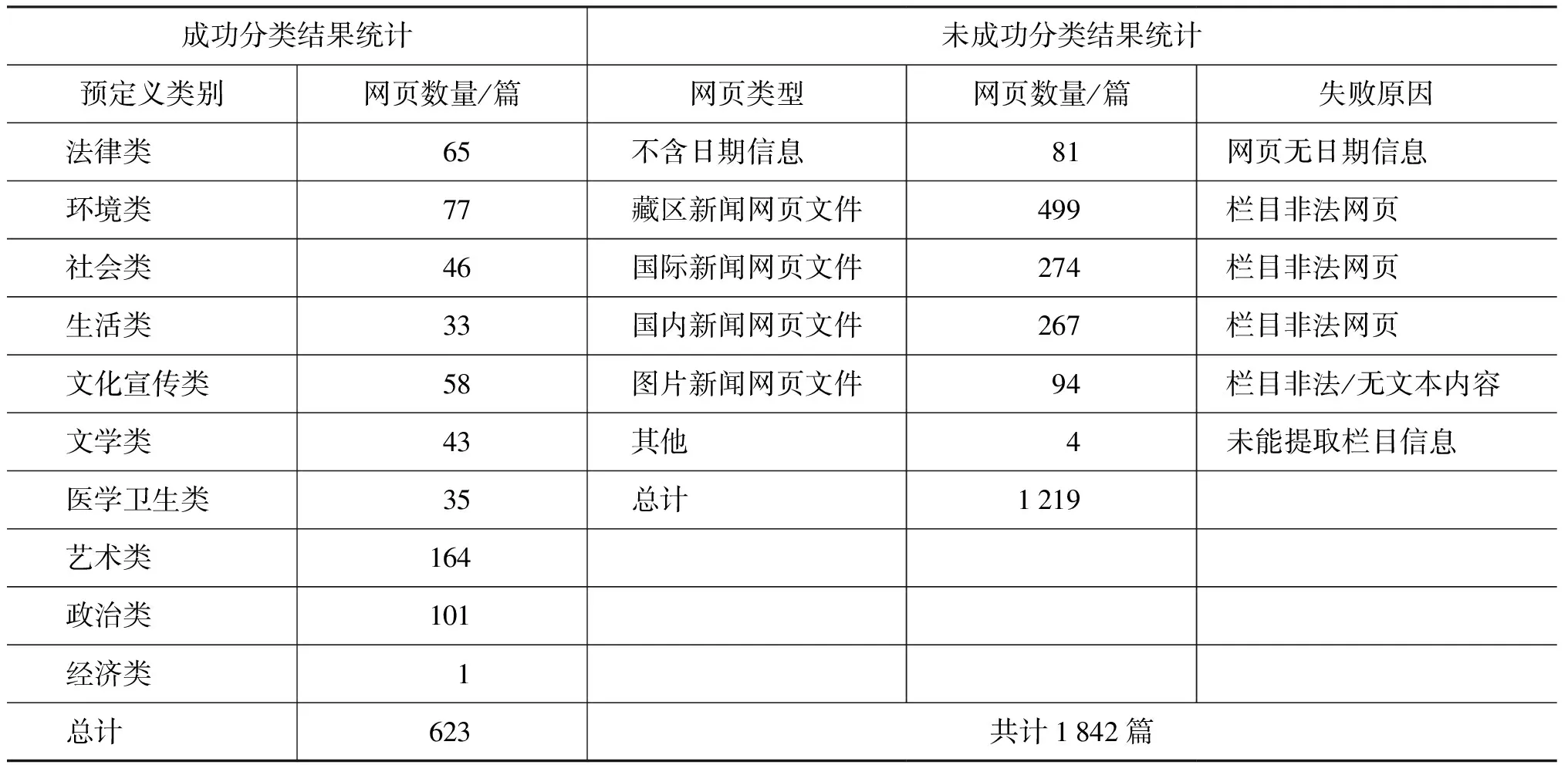
表1 分类结果统计表
4 结语
本文提出了一种基于栏目的藏文网页自动分类方法。实验表明,该方法能快速、准确地将大量藏文网页文本进行自动分类。这将为今后的基于统计和基于规则的藏文文本分类、构建藏文语料库提供高质量语料。
当然,该方法也有不足及需要进一步改进与优化的地方,主要包括以下三个方面:
(1) 不同的藏文网站有不同的网页栏目格式,制定统一的或者可扩充的栏目提取规则(集),才能保证该分类方法对其进行有效处理。
(2) 藏文网页文本的正确提取直接关系到最终文本语料的质量。对于没有栏目信息的藏文网页,需要进一步研究分类方法。
(3) 类别特征词表的存储结构需要根据特征词的数量作相应的优化或变换,以实现栏目特征词条的快速匹配,提高分类效率。
[1] 才让加.藏语语料库加工方法研究[J].计算机工程与应用,2011,47(6):138-139,146.
[2] 才让加,吉太加.藏语语料库的词性分类方法研究[J]. 青海师范大学学报(哲学社会科学版),2005,(4):112-114.
[3] 贾会强,李永宏.藏文文本分类器的设计与实现[J].科技向导,2010,(4)下:30-31.
[4] 李渝勤,孙丽华.基于规则的自动分类在文本分类中的应用[J].中文信息学报,2004,18(4):9-14.
[5] 黄科,马少平.基于统计分词的中文网页分类[J].中文信息学报,2002,16(6):25-31.
[6] 卢娇丽,郑家恒.基于粗糙集的文本分类方法研究[J].中文信息学报,2005,19(2):66-70.
[7] 许世明,武波,马翠,等.一种基于预分类的高效SVM中文网页分类器[J].计算机工程与应用,2010,46(1):125-128.
[8] 刘建,孙鹏,倪宏.面向分类的网页主题特征提取[J].计算机应用研究,2010,27(9):3399-3402.
[9] 孙承杰,关毅.基于统计的网页正文信息抽取方法的研究[J].中文信息学报,2004,18(5):17-22.
[10] 韩忠明,李文正,莫倩.有效HTML文本信息抽取方法的研究[J].计算机应用研究,2008,25(12): 3568-3571,3574.
[11] 黄玲,陈龙.基于网页分块的正文信息提取方法[J].计算机运用,2008,28:326-328.
猜你喜欢
西藏研究(2021年1期)2021-06-09
英语世界(2021年13期)2021-01-12
——三份医学英语词表比较分析
江西理工大学学报(2020年2期)2020-05-21
电脑知识与技术·经验技巧(2020年3期)2020-05-07
布达拉(2020年3期)2020-04-13
西藏大学学报(自然科学版)(2016年1期)2016-11-15
西藏大学学报(自然科学版)(2016年1期)2016-11-15
知识经济·中国直销(2016年5期)2016-11-07
图书馆建设(2012年3期)2012-10-23
对联(2011年20期)2011-09-19
