
NA样本情形下双参数指数分布族参数EB估计的渐近性讨论
2011-05-18 08:05刘荣玄范发明吴高翔
统计与决策 2011年13期
刘荣玄,范发明,吴高翔
(井冈山大学 数理学院,江西 吉安 343009)
0 引言
近几十年来,已有许多文献研究经验Bayes统计推断,这些研究文献中绝大多数都是在独立同分布的样本下进行的。然而在渗透性理论和可靠性理论等实际问题中,所获得的样本常常不是独立的,而是具有某种相关性,负相协(NA)和正相协(PA)样本就是两种常见的样本.关于估计问题,在许多情况下正误差(过高估计)和负误差(过低估计)所造成的损失相差很大,因此许多研究经验Bayes统计推断的文献采用了非对称损失函数,LINEX损失就是其中常用的一种。双参数指数分布应用很广,一些产品的寿命分布都可以用它来刻画,如汽车、飞机和水坝等寿命都服从这种分布。有关这些方面的研究有许多学者在不同的刊物上发表了文章,文献[1]讨论了在NA样本情形下刻度指数族参数的经验Bayes检验问题,文献[2]讨论了在NA样本情形下单边截断型分布族位置参数的经验Bayes估计,文献[3]讨论了在LINEX损失函数下单边截断型分布族参数的EB估计,文献[4]讨论了刻度指数族参数的经验Bayes估计的收敛速度,文献[5]讨论了线性指数分布参数的经验贝叶斯估计,文献[6]讨论了对称熵损失下指数分布参数的估计,文献[7]讨论了定数截尾数据缺失场合下双参数指数分布参数的贝叶斯估计。本文将在NA样本情形下,假设LINEX损失函数,研究双参数指数分布位置参数的EB估计,并证明所得到的估计是渐近最优的。
假设双参数指数分布为

其中α为位置参数,或称门限参数、保证时间参数,当α表示寿命、时间时,α自然是非负的;β>0为尺度参数。
为便于研究位置参数α的估计,不妨假设β为常数,于是对给定的α时,随机变量(r.v.)X的条件密度函数为

这里的,Ω 为参数空间 α∈Ω=(0,+∞)。
设 α 的先验分布为 H(α),属于先验分布族 F={H(α):E(eαβ-1)<∞,β>0},则 r.v.X 的边缘分布为


取损失函数为如下的LINEX函数,即

其中θ(x)为参数α的判决函数,c≠0,c为实数,是损失函数的尺度参数,可根据双参数指数分布的参数β的值确定c的取值,满足βc>1。于是参数α的Bayes估计为
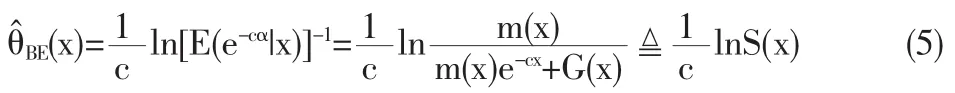

这里 E(x,α)表示对(X,α)的联合分布取期望。
从上式可知,如果参数α的先验分布是已知的,θ^BE(x)的Bayes 风险 R(θ^BE(x),H(α))可以计算出来,然而,通常 α 的先验分布 H(α)是不知道,按(5)式得不到θ^BE(x)的 Bayes估计。 也无法得到它的Bayes风险,但考虑到人们过去所做的工作一般都有记载,因此,下文将借用历史数据,采用概率密度核估计的办法,构造一个形如(5)式的参数α的EB估计θ^BE(x),以此估计量来近似代替Bayes估计θ^BE(x),并且可以证明这种代替在LINEX损失下其风险可任意接近 R(θ^BE(x),H(α))。收敛速度为
1 EB估计的构造
假设(X1,α1),(X2,α2),…(Xn,αn),(X,α)为一串具有相同分布的随机向量,X1,X2,…Xn,X,为同分布弱平稳NA随机变量序列,它们是可观测,有共同的边缘概率密度 m(x);X1,X2,…Xn为历史样本,X为当前样本,α1,α2,…αn和α为不可观测的,但有相同的先验分布 H(α)。 设 m(x)∈CS,M,x∈R1,其中 s≥2,为正整数,CS,M表示R1中的一族概率密度函数,其s阶导数存在,连续其绝对值不超过M。对NA样本序列的协方差结构假设为

下面利用历史样本和核函数定义m(x)的核估计。
设K(x)为Borel可测实值核函数,且满足

K(x)为有界的,除有限点集外是可微的,且微分有界;
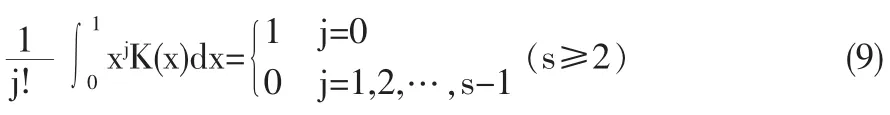
定义m(x)的核估计为

其中当n→∞时,hn→0,定义G(x)的估计为

令

其中0<v<1,它的取值视实际情况而定,根据上述估计,再定义参数α的EB估计

它的全面Bayes风险为

其中 E*表示对(X1,X2,…Xn,X,α)的联合分布求数学期望.以下证明这一EB估计的渐近性,说明在一定的条件下,用历史数据估计参数α是有效性的。
2 渐近性的证明
在证明EB估计的渐近性之前先证几个引理,并假设c1,c2,c3…为任意正常数,且在不同的地方可以代表不同的常数。
引理1 假设 a>0,b>0则有

证明:见文献[8]引理1。
引理2 在LINEX损失函数下有
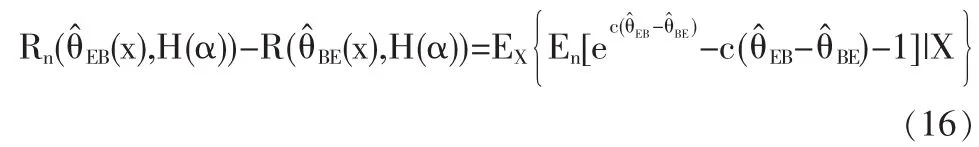
这里的 En 和 Ex 分别表示对随机变量(X1,X2,…,Xn)和X的分布求数学期望。
证明:见文献[8]引理2。
引理3 设Y,Y'分别为r.v,y,y'为实数,L>0,则对 0<γ<2有


证明:见文献 [9]引理3.1。
引理4设r.vX和Y为NA的,都有有限的方差,则对任何可微函数g1和g2总有

证明:见文献[10]引理1。
引理5 X1,X2,…Xn,…,为同分布弱平稳的NA随机变量序列,满足条件(7)式,m(x)∈CS,M,m(x)由(10)式给出,则当hn=n-1/(2s+4)时(s>1,为自然数),有
⑴式的证明:因为

将m(x+hny)在x处展成s+1项Taylor级数,再由m(x)∈CS,M可得

⑵式的证明:由(10)有

由K(x)的有界性得到
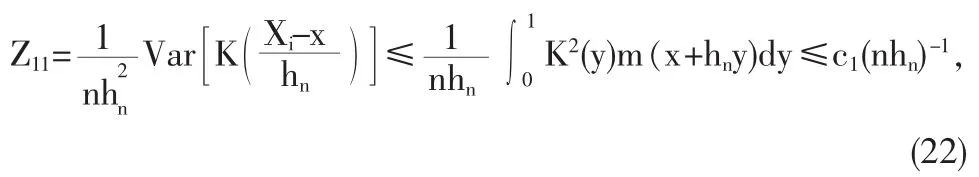
由K(x)的定义及引理4可得

再由(7)式成立和的弱平稳性得到

于是有

⑶式的证明:由C-R不等式和Jensen不等式以及(20)、(25)式得

引理6设X1,X2…Xn,…,为同分布弱平稳的NA随机变量序列,m(x)∈CS,M,βc>1,Gn(x)由(12)式给出,hn=n-1/(2s+4),则有

证明:由C-R不等式及Jensen不等式

由引理5得

所以

引理 7 如果 S(x)<∞ 则有 R(θ^BE(x),H(α))≤∞.
引理的结论很容易证明,证明(略)。
定理1设X1,X2,…Xn…,为同分布弱平稳的NA随机变量序列,s>1为任意给定自然数,0<γ<1为任意实数,假设(7)式成立,并满足下例条件
⑴m(x)∈CS,M;⑵βc>1;⑶E(eαβ-1)<∞
⑷Ex(S(x))η<∞,η>2

证明:根据引理1及引理2可得


于是有

当x∈Ω时有

由Hölder不等式和Markov不等式有


从而有


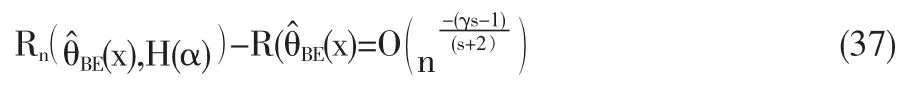
显然对于任意接近1的γ,只要定理中的条件成立,α的EB估计的收敛速度可任意接近于1[11]。
3 例子
下面的例子说明存在满足定理条件的先验分布。
如果参数α给定时,r.vX的条件概率密度由(2)式给出,设α 的先验分布为 α~U[a,b],b>a>0,这时有

因此对于任意的大于1的正整数s,m(x)∈CS,M。又因为

则不难验证定理中的条件全都成立。
[1]韦来生.刻度指数族参数的经验贝叶斯检验问题:NA样本情形[J].应用数学学报,2002,(3).
[2]许勇,师义民.NA样本情形下单边截断型分布族位置参数的经验Bayes估计[J].应用数学,2001,14(4).
[3]康会光,赵小山.Linex损失函数下单边截断型分布族参数的EB估计[J].应用数学,2001,14(3).
[4]王立春,韦来生.刻度指数族参数的经验Bayes估计的收敛速度[J].数学年刊,2002,(5).
[5]陈家清,刘次华.线性指数分布参数的经验贝叶斯估计[J].华中科技大学学报,2006,(10).
[6]孔令军,宋立新.对称熵损失下指数分布参数的估计[J].吉林大学自然科学学报,1998,(2).
[7]刘菡,刘次华.定数截尾数据缺失场合下双参数指数分布参数贝叶斯估计[J].武汉大学学报(理科版),2006,52(3).
[8]刘荣玄,张波.指数族刻度参数EB估计的渐近最优性[J].数理统计与管理,2010,29(5).
[9]赵林城.一类离散分布参数的经验贝叶斯估计的收敛速度[J].中国数学研究与评论,1981,(1).
[10]Wei,L.S.Convergence Rates of Empirical Bayes Estimation for a Rameterofone-sided Truncated Distribution[J].Annals of Math,1985,6A(2).
[11]陈希孺.高等数理统计[M].合肥:中国科学技术大学出版社,1999.
[12]Berger J O.统计决策论及Bayesr分析[M].贾乃光,吴喜之译.北京:中国统计出版社,1998.
猜你喜欢
法律方法(2021年4期)2021-03-16
青年生活(2019年21期)2019-10-21
成都信息工程大学学报(2019年3期)2019-09-25
火力与指挥控制(2017年7期)2017-08-28
科教导刊·电子版(2017年12期)2017-06-19
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年4期)2016-11-07
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
探测与控制学报(2015年4期)2015-12-15
